画像分類におけるタスクにおいて自分の所感ではCoAtNetが広範囲でSOTAであるように思う。
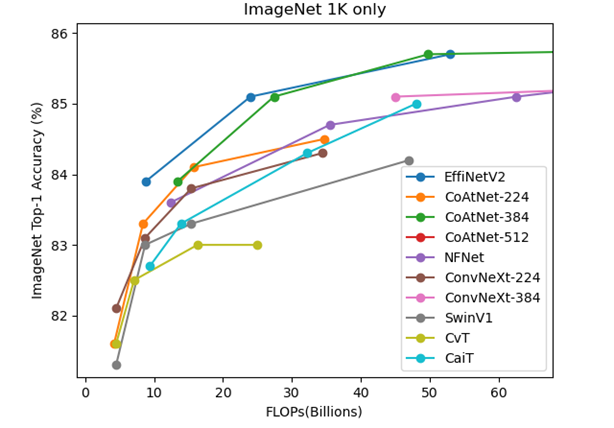
しかし、CoAtNet論文中の以下の図は既存モデルと差をつけるためか、非常に恣意的である。
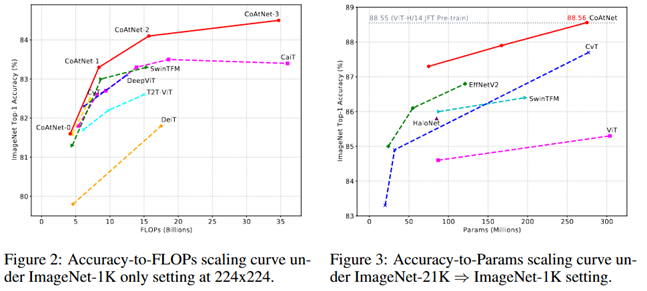
まず、左の図に関してだが解像度を224x224に固定する必然性はない。EfficientNetの論文を読めば効率よくモデルを大きくするにはモデルの入力の解像度を上げる操作をモデルの深さと幅を大きくするのと同時に行う必要がある。
また、右の図は横軸がFLOPsではなくパラメータ数を使っている。CoAtNetはこの図では512x512のものを採用してEfficientNetV2は384x384や480x480で小さいのでFLOPsで比較した場合よりも若干EfficientNetV2が不利になる。
とにかく、横軸FLOPsで比較するべきだし、入力解像度を制限せずに表示するべきだと思った。厳密にはFLOPsも実効速度と単純に比例はしてないのだが、パラメータ数は実効速度を全然反映していない。同じパラメータ数でも入力の解像度が異なれば演算量のFLOPsは異なるからである。
#事前学習データセット
ところで事前学習(pre-train)にImageNetよりも大きなデータセットを使う方が良くなる。
標準のImageNet以外に以下が存在する。
・ImageNet-21KやImageNet-22Kと呼ばれるデータセット。論文によってサイズが13M、14.2M、14.8Mと何故かばらつきがある。漸次増えて行っているのだろうか?
・ImageNet-22K-extはImageNet-22Kを拡張したデータセット。Swin Transformer V2の中にみられる。
・JFT-300Mと呼ばれるデータセット。300Mは画像の量。Noisy Student(2020)の論文では、JFTデータセットはunlabeled imagesとされていた。CoAtNetの論文中にもweakly labeled dataset (JFT)と呼ばれていてラベル付けの正確さはちょっと弱いのかもしれない。
・JFT-3Bと呼ばれるデータセット。ViTやらCoAtNetがSOTAを出してるがこのデータセットを使ったモデルは学習コストが非常に高い。
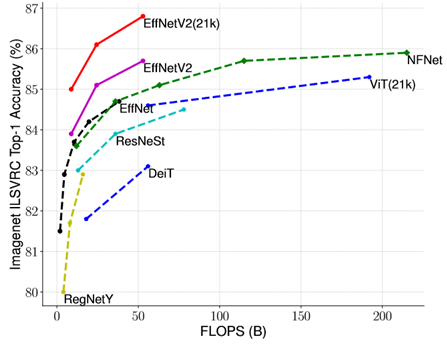
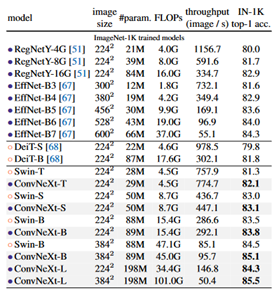
EfficientNetV2においてImageNet-21Kを使うだけで以下の様に同じモデル、同じ演算量でも精度が大きく変わる。このため事前学習のデータセットを混合してのモデルの精度比較は意味がない。
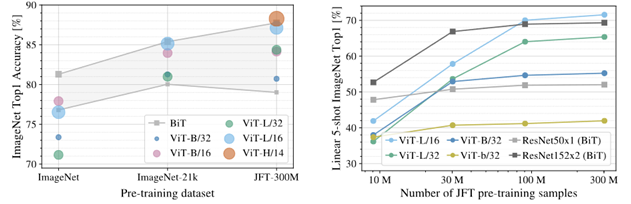
また、ViT等のTransformer系は事前学習データが大きくないと十分な性能を発揮できない事が示されている。
各種Data Augmentationや半教師学習や自己教師学習は大きいデータセットで学習できない場合において代替案として有利だが、そもそも大きいデータセットを使用すれば相対的に重要度が減るのかもしれない。
#ImageNet 1K only
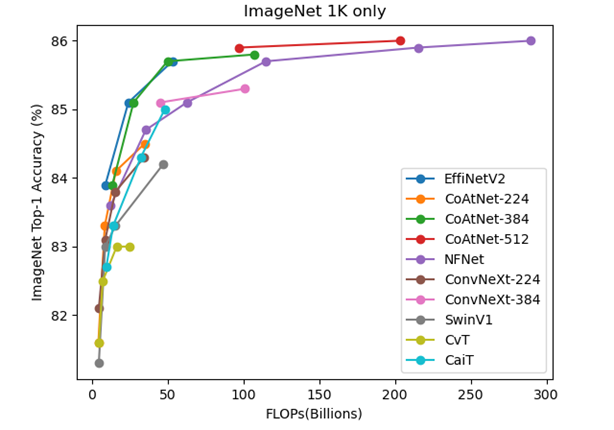
この図はCoAtNetの表から値を取り、ほかにConvNeXtのみ追加した。重要でない幾つかのモデルは省略した。CoAtNetが広い範囲でよいが、EfficientNetV2も遜色ないほど良い。ConvNeXtとNFNetは若干劣る。
#ImageNet 22K pre-train
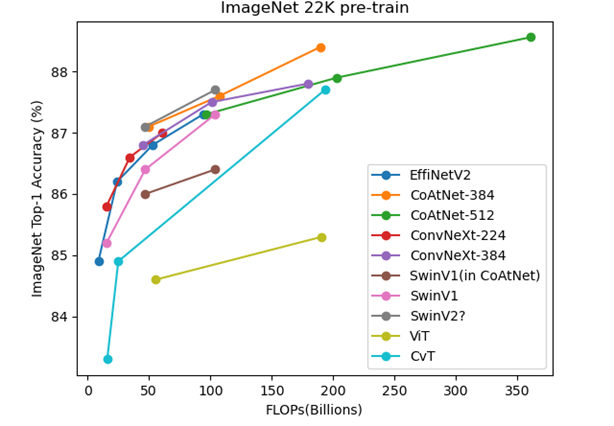
モデルの大きい領域ではCoAtNetの圧勝だが、50~100BではCoAtNet、EfficientNetV2、ConvNeXtは同程度に良い。またCoAtNetは50B以下の領域でモデルの結果がない。
SwinV2のFLOPsはSwinV1のFLOPsと同じかよく分からなかったがパラメータ数が同じなので等しいと仮定してプロットした。ただし、CoAtNetの論文中でのSwinV1の性能は何故か低い。
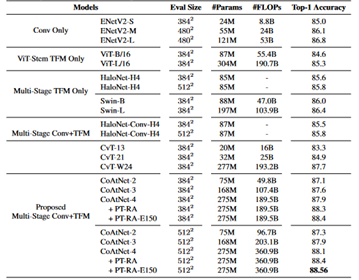

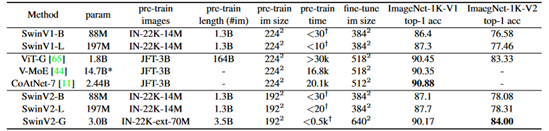
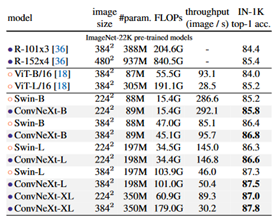
#JFT-300M pre-train
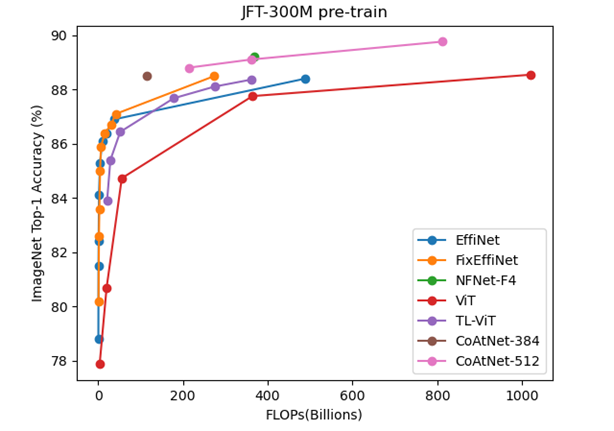
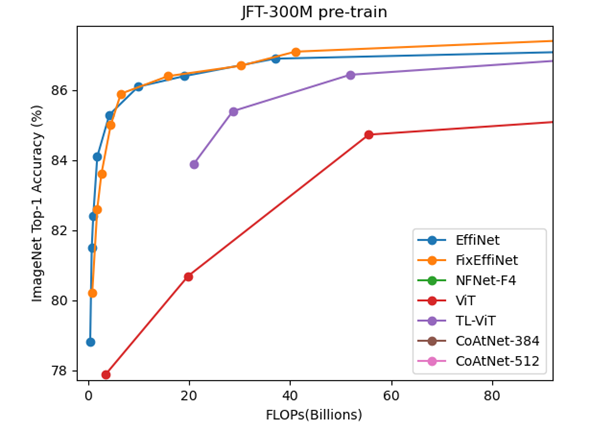
ここからプロット出来るモデルの数が少なくなる。
やはりCoAtNetが優秀だが100B以下の領域でのモデルの結果はない。
NFNetは非TransformerだがTransformer系と比較してもそれほど悪くはないように思える。
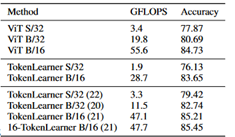
ViTやMLP-MixerもこのJFT-300Mで事前学習するモデルだが、論文中にFLOPsの記載がない。ViTはかろうじてほかの論文にFLOPsがあったので並べる事が出来た。

また、EfficientNetV2のJFT-300Mの結果は無く、EfficientNetのJFT-300Mの結果はFixEfficientNetの論文における結果を乗せた。とはいえこの値もNoisy Studentの論文からのように思う。
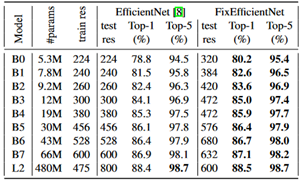
ところでEfficientNetL2やFixEfficientNetのFLOPsは記載がない。
そもそもEfficientNetL2はEfficientNetの論文中に登場しないが、Noisy Studentの論文に以下の記載があり、この設定の計算値からEfficientNetL2のFLOPsをB0の1250倍として487Bと見積もった。(厳密には層の深さや層の幅は整数値だから非常にアバウトな見積もり。参考のB7のFLOPsは正確には37Bだからおおよそあっているだろう)

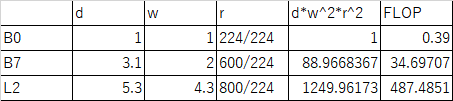
また、FixEfficientNetのFLOPsはEfficientNetのtest resの分解能比の2乗を掛けた。
FixEfficientNetがさもEfficientNetを改善したモデルのように思えたが、FLOPs軸でプロットするとEfficientNetとFixEfficientNetの差はあまりない事が分かる。
FixEfficientNetの良い所はL2で800の解像度を600に落としたぐらいである。
#JFT-3B pre-train
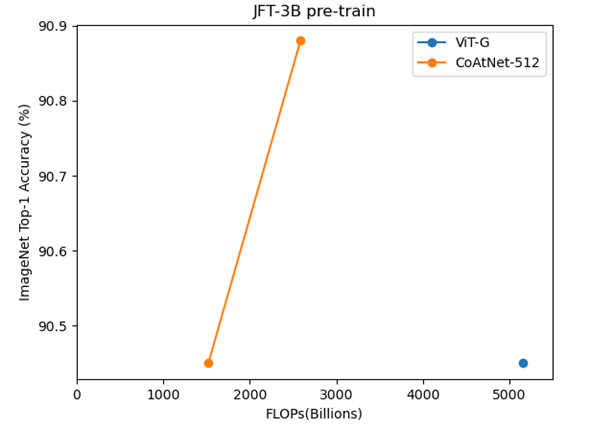
このデータセットで学習したモデルはほとんどない。
V-MoEはFLOPsが分からなくグラフに乗せれなかった。
おそらく非Transformer系ではJFT-3Bを事前学習しても精度が上がらないと思われるが、実行された例がないので不明である。それもそのはずで事前学習の実行時間はTPUv3でのべ20K日=2万日=54年以上かかるので、相当の計算資源のある人でない限りこの事前学習はできない。個人でやろうとすれば文字通り一生かかる。
(参考までにJFT-300MのNFNet-F4+の事前学習のTPUv3-core-daysは1.86k、JFT-300MのCoAtNet-4の事前学習でTPUv3-core-daysは0.95k)
(また、Meta Pseudo Labelsは、EfficientNet-L2モデルで90.2%を出しているが、TPUv3が2,048の11daysとあるのでJFT-3Bの事前学習期間とそう変わらない。事前学習データセットはJFT-300Mだけども)


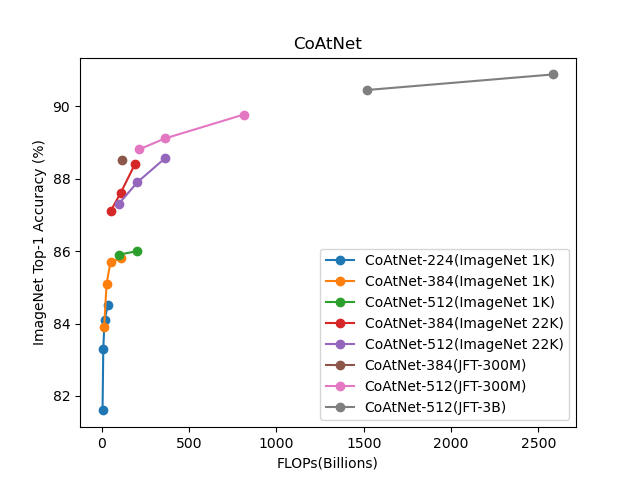
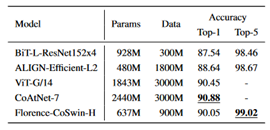
#CoAtNet
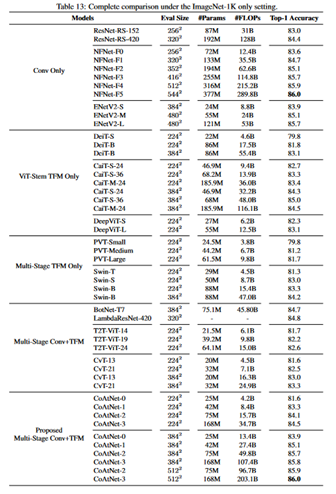
参考までにCoAtNetの結果を並べてみる。
同じモデルサイズでも事前学習のデータセットによって大きく精度が異なるのが分かる。
#まとめ
事前学習データセットの違いはかなり大きい。
俯瞰するとCoAtNetが優秀なように思うが、モデルサイズが小さい場所での結果がないので一部で比較はできない。JFT-3Bの事前学習に関しては、非Transformer系が不向きなのだと思われる。
JFT-300M未満の事前学習ではImageNet-22K-extを使ったSwinV2Gの90.17が性能が異様に高い。(JFT-300Mの結果すら超えている)。ただ、パラメータ数が3Bで、かなり巨大なモデルである。
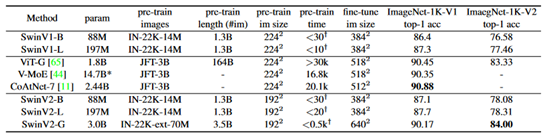
その他、300M以上3B未満の事前学習例ではALIGN-Efficient-L2、Florence-CoSwin-Hなどがある。
#コード
いらないだろうけれど、一応グラフを書くのに使ったコードを残しておく。
import matplotlib.pyplot as plt
plt.plot([8.8, 24, 53], [83.9, 85.1, 85.7], marker="o", label='EffiNetV2')
plt.plot([4.2, 8.4, 15.7, 34.7], [81.6, 83.3, 84.1, 84.5], marker="o", label='CoAtNet-224')
plt.plot([13.4, 27.4, 49.8, 107.4], [83.9, 85.1, 85.7, 85.8], marker="o", label='CoAtNet-384')
plt.plot([96.7, 203.1], [85.9, 86.0], marker="o", label='CoAtNet-512')
plt.plot([12.4, 35.5, 62.6, 114.8, 215.2, 289.8], [83.6, 84.7, 85.1, 85.7, 85.9, 86.0], marker="o", label='NFNet')
plt.plot([4.5, 8.7, 15.4, 34.4], [82.1, 83.1, 83.8, 84.3], marker="o", label='ConvNeXt-224')
plt.plot([45.0, 101.0], [85.1, 85.3], marker="o", label='ConvNeXt-384')
plt.plot([4.5, 8.7, 15.4, 47.0], [81.3, 83.0, 83.3, 84.2], marker="o", label='SwinV1')
plt.plot([4.5, 7.1, 16.3, 24.9], [81.6, 82.5, 83.0, 83.0], marker="o", label='CvT')
plt.plot([9.4, 13.9, 32.2, 48], [82.7, 83.3, 84.3, 85.0], marker="o", label='CaiT')
plt.title('ImageNet 1K only')
plt.xlabel('FLOPs(Billions)')
plt.ylabel('ImageNet Top-1 Accuracy (%)')
plt.legend()
plt.show()
plt.plot([8.8, 24, 53, 94], [84.9, 86.2, 86.8, 87.3], marker="o", label='EffiNetV2')
plt.plot([49.8, 107.4, 189.5], [87.1, 87.6, 88.4], marker="o", label='CoAtNet-384')
plt.plot([96.7, 203.1, 360.9], [87.3, 87.9, 88.56], marker="o", label='CoAtNet-512')
plt.plot([15.4, 34.4, 60.9], [85.8, 86.6, 87.0], marker="o", label='ConvNeXt-224')
plt.plot([45.1, 101.0, 179.0], [86.8, 87.5, 87.8], marker="o", label='ConvNeXt-384')
plt.plot([47.0, 103.9], [86.0, 86.4], marker="o", label='SwinV1(in CoAtNet)')
plt.plot([15.4, 47.0, 103.9], [85.2, 86.4, 87.3], marker="o", label='SwinV1')
plt.plot([47.0, 103.9], [87.1, 87.7], marker="o", label='SwinV2?')
plt.plot([55.4, 190.7], [84.6, 85.3], marker="o", label='ViT')
plt.plot([16, 25, 193.2], [83.3, 84.9, 87.7], marker="o", label='CvT')
plt.title('ImageNet 22K pre-train')
plt.xlabel('FLOPs(Billions)')
plt.ylabel('ImageNet Top-1 Accuracy (%)')
plt.legend()
plt.show()
plt.plot([0.39, 0.70, 1.0, 1.8, 4.2, 9.9, 19, 37, 487], [78.8, 81.5, 82.4, 84.1, 85.3, 86.1, 86.4, 86.9, 88.4], marker="o", label='EffiNet')
plt.plot([0.39*320**2/224**2, 0.70*384**2/240**2, 1.0*420**2/260**2, 1.8*472**2/300**2, 4.2*472**2/380**2, 9.9*576**2/456**2, 19*576**2/456**2, 37*632**2/600**2, 487*600**2/800**2], [80.2, 82.6, 83.6, 85.0, 85.9, 86.4, 86.7, 87.1, 88.5], marker="o", label='FixEffiNet')
plt.plot([367], [89.2], marker="o", label='NFNet-F4')
plt.plot([3.4, 19.8, 55.6, 364, 1021], [77.87, 80.69, 84.73, 87.76, 88.55], marker="o", label='ViT')
plt.plot([20.91, 28.66, 51.92, 178.1, 274.2, 361.6], [83.89, 85.40, 86.44, 87.68, 88.11, 88.37], marker="o", label='TL-ViT')
plt.plot([114], [88.52], marker="o", label='CoAtNet-384')
plt.plot([214, 361, 812], [88.81, 89.11, 89.77], marker="o", label='CoAtNet-512')
plt.title('JFT-300M pre-train')
plt.xlabel('FLOPs(Billions)')
plt.ylabel('ImageNet Top-1 Accuracy (%)')
plt.legend()
plt.show()
plt.plot([5160], [90.45], marker="o", label='ViT-G')
plt.plot([1521, 2586], [90.45, 90.88], marker="o", label='CoAtNet-512')
plt.title('JFT-3B pre-train')
plt.xlabel('FLOPs(Billions)')
plt.ylabel('ImageNet Top-1 Accuracy (%)')
plt.xlim(0, 5500)
plt.legend()
plt.show()