はじめに
昨今、さまざまな生成AIの技術が台頭してきて、筆者は日々キャッチアップに奮闘しています。
全然追いつけていませんが、、、
そこで今回は「RAG」について勉強した内容をまとめてみました。
生成AI初学者の方達の参考になれば幸いです。
RAG(検索拡張生成)とは?
RAG(Retrieval-Augmented Generation)は、日本語で「検索拡張生成」と呼ばれます。
検索拡張生成??なんじゃそりゃ。
初めて聞いた時にそう思われる方は多いと思います。(筆者もその1人)
RAGとは一言で言うと
LLMが回答生成する前に外部の知識を参照し、その内容をプロンプトに含めることで回答精度を高める仕組みのことです。
この「知識」は主にベクトルデータベースから参照されます。
イメージ図
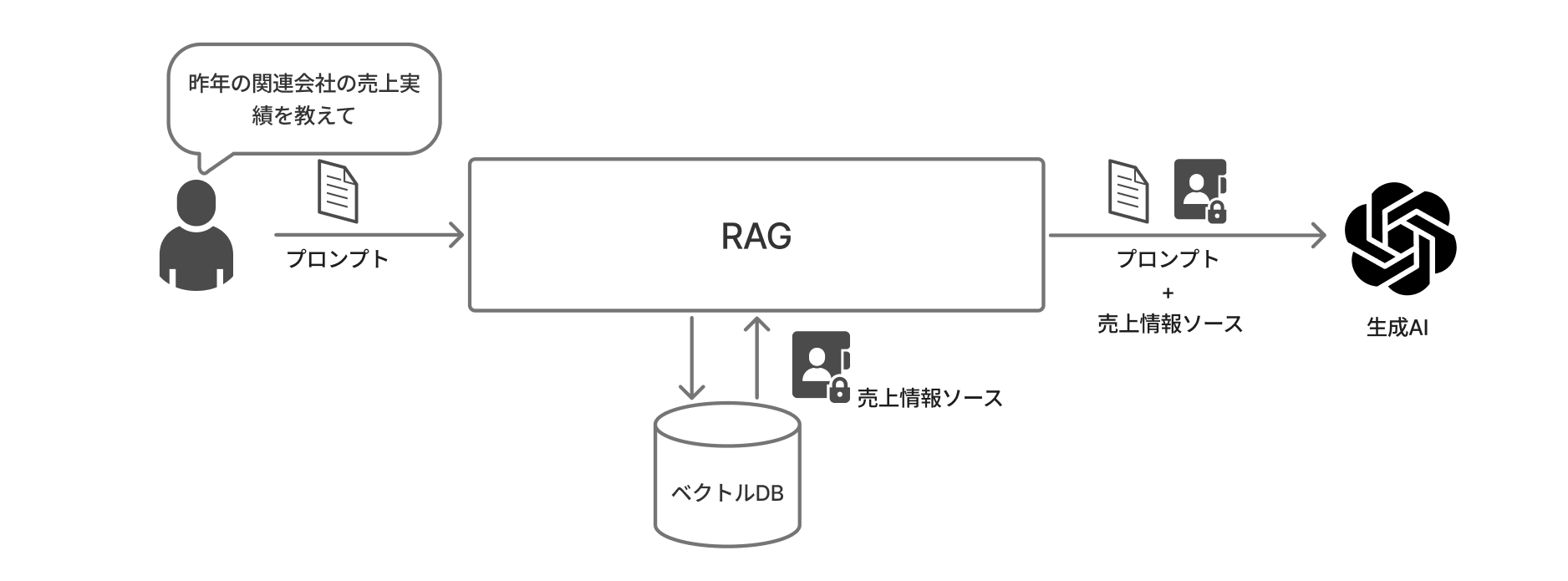
入力プロンプトの内容と類似性の高い内容をベクトルDBから取得し、プロンプトとセットでLLMに渡します。
そうすることで、質問内容がLLMのコンテキストウィンドウに収まりやすくなり、無駄なトークン消費、ハルシネーションリスクの削減を期待できます。
コンテキストウィンドウ
モデルが応答を生成する際に参照、記憶できるテキストやデータの量のこと。
ハルシネーション
生成AIがもっともらしい嘘を真実であるかのように出力する現象のこと。
データの意味を数値化する「埋め込み」
RAGを実現するために欠かせないのが 埋め込み(Embedding) です。
これは、テキストや画像をコンピュータが計算しやすい多次元の数値(ベクトル)に変換することを指します。
ベクトルデータベースにデータ登録する際には、登録したいデータをベクトル化する必要があります。
実装例
from openai import OpenAI
client = OpenAI()
# Function to get the vector embedding for a given text
def get_vector_embeddings(text):
response = client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
embeddings = [r.embedding for r in response.data]
return embeddings[0]
display = get_vector_embeddings("有馬記念")
# 埋め込みデータの個数取得
print(len(display))
# ベクトルデータ取得
print(display)
出力結果
1536
[-0.04045114293694496, -0.003843134269118309, -0.0005096892127767205
...中略...
-0.01759224757552147, 0.003422629786655307, -0.009237308986485004]
解説:
上記実装では「有馬記念」と言う単語の埋め込み処理を行っています。
埋め込みにはOpenAIの標準モデル text-embedding-ada-002 を利用しています。
このモデルでは1つの単語や文章を1536次元の数値で表現します。
非常に高次元であることからより深く単語の意味や単語同士の関係性を捉えることが可能になっています。
上記の出力結果のうち1行目の「1536」というのが、埋め込み生成したベクトル値の数を表しています。
モデルが1536次元あるため、1536個ベクトル値を生成しています。
2行目〜4行目は実際のベクトル値です。(流石に1536個は多すぎるので一部抜粋して記載しています)
ベクトルデータベースとは?
データをベクトル形式で保存し管理するデータベースのことを指します。
従来のDBが「キーワードの一致」で検索するのに対し、ベクトルDBは「意味の近さ(類似性)」で検索するのが最大の特徴です。
ベクトルとは、高校生の時に数学で習った「大きさ」と「向き」を数値で表す、あのベクトルのことです。
ベクトルDBに保存されるベクトルデータは「大きさ」「向き」を併せ持つことから、高次元のデータを扱うことができ大量のデータを効率的に処理・検索することが可能になります。
入力内容と近い距離にあるデータ(類似性の高いデータ)を検索することが最大の特徴で、機械学習やデータ分析などあらゆる分野で利用されています。
ベクトルデータベース作成までの流れ
- チャンク化: 対象データの適切な長さに分割
- 埋め込み: チャンク化したデータのベクトル化
- ドキュメントローディング: ベクトル化したデータを変数に格納
- インデックス作成: インデックスを作成しベクトル配列を格納
- 永続化: 4を保存することでベクトルデータベース作成
ベクトルデータベースへのインデックス付与
テキストのチャンク化、埋め込み、ドキュメントローディングが完了したら、いよいよベクトルデータベースに保存します。
ただ、先述したように保存されるベクトルは高次元であり、大量のベクトルの中から類似したデータを取得するには大量の計算と時間を要することになります。
※text-embedding-ada-002だと1536次元
それを回避するための仕組みが、ここで紹介するインデックスというものです。
インデックスを付与することで類似検索を高速化できます。
インデックスとは簡単に言うと「特定のデータを高速に見つけるための『索引』のようなもの」です。
ここでは詳細は割愛しますが、詳しく知りたい方は以下のページとか見てみると良いかも。
インデックスとは?仕組みをわかりやすく解説
ベクトルの保存と検索にはFaiss(Facebook AI Similarity Search)ライブラリが使用できます。
RAGの実装:ドキュメント検索から回答まで
テキストのチャンク化、埋め込み、ドキュメントローディング、インデックスの内容を踏まえ、ベクトルDB作成、ベクトルDB検索の実装例を記載してみました。
実装例1:データ読み込みとベクトルDB構築
from email import message
import glob
from langchain_community.document_loaders import PDFMinerLoader
from langchain_text_splitters import CharacterTextSplitter
import numpy as np
import faiss
from openai import OpenAI
import os
from dotenv import load_dotenv
# PDFファイルを読み込む
# ここに対象ファイル(PDF)を設定してください。
pdf_files = glob.glob("sample.pdf")
for pdf_file in pdf_files:
loader = PDFMinerLoader(pdf_file)
data = loader.load()
# チャンク分割
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=100, separator="\n")
chunks = text_splitter.split_documents(data)
load_dotenv()
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 埋め込み処理
def get_vector_embeddings(text):
text = text.replace("\n", " ")
response = client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
embeddings = [r.embedding for r in response.data]
return embeddings[0]
# 埋め込みの作成
emb = [get_vector_embeddings(chunk.page_content) for chunk in chunks]
# ドキュメントローディング
vectors = np.array(emb)
# インデックス作成
index = faiss.IndexFlatL2(vectors.shape[1])
# インデックスへのデータ登録
index.add(vectors)
# データベース永続化
faiss.write_index(index, "★データベースを格納するパス★")
実装例2:ベクトルDB検索と回答生成1
# ベクトルDB検索
def vector_search(query_text, k=1):
query_vector = get_vector_embeddings(query_text)
distance, indices = index.search(np.array([query_vector]),k)
return [(chunks[i],float(dist)) for dist,
i in zip(distance[0], indices[0])]
# チャット応答
def search_and_chat(user_query, k=1):
search_results = vector_search(user_query,k)
prompt_with_context = f"""Context:{search_results}\
Answer the question: {user_query}"""
messages = [
{"role": "system","content":"ユーザからの質問に答えてください。回答する際は提供されたコンテキストのみを使用し、答えがわからない場合は「わかりません」と答えてください"},
{"role": "user", "content": prompt_with_context},
]
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
)
print(f"""Response:{response.choices[0].message.content}""")
# 検索クエリ
user_query = "Reduxの話は第何章を読みのが良いですか?"
search_and_chat(user_query)
最後に
RAGを活用することで、LLMは「知っていることだけで話す」状態から、「資料を見ながら正確に話す」状態へと進化します。
今回はローカルで動作するFaissを使いましたが、実務ではクラウド型の Pinecone や Chroma など、より大規模なデータに適したベクトルDBも多く存在します。
それらの記事はまたの機会に投稿したいと思います。
おまけ
応用編を書きました。よければこちら見ていってもらえると嬉しいです。
-
importとget_vector_embeddings()はベクトルDB保存と同様のものを利用します。 ↩