EmbeddingGemmaというオンデバイスな埋め込みモデルの話題が気になったので、DifyからEmbeddingGemmaを使ってみたいと思います。
ただAPI経由で使うとかは面白くないのでマイコンデバイス上で動かしたモデルを利用してみたいと思います。
EmbeddingGemmaとは
オンデバイス向けに設計された埋め込みモデルです。
メールとかそういった内容を外部の埋め込みモデルAPIを使わずにデバイス内でやれます。
EmbeddingGemmaをマイコンで動かしてDifyからアクセス
Hugging FaceのAPI経由で使うこともできますが、オンデバイス向けにって話なのでAPIで使うのはちょっと面白くない気がしています。
日本語だとEmbed=組み込みだしEmbed=埋め込みだしわけわからん感じだけどダブルミーニングなはず。
オンデバイス向けにって書いてるけどマイコンボードっていうよりGoogle的にはPixelの中で動かすなどを想定しているのかも。
ということでJetson Nanoが手持ち無沙汰で家に眠ってるのでここに入れて使ってみます。
利用に関してはDifyからアクセスします。
Jetson NanoにDifyをホスティングまではしてないのでクラウド版Difyからアクセスできるようにします。
使うまでの流れ
- STEP1. Jetson Nanoにollamaインストールしつつ、EmbeddingGemmaのインストール
- STEP2. Jetson Nanoのollamaに外部からアクセスできるようにする
- STEP3. Difyから利用
という感じです。
STEP1: EmbeddingGemmaのインストール
STEP1の方はollamaが対応してくれてるのですぐいけます
$ ollama pull embeddinggemma:latest
(v0.11.10未満の場合)ollamaのバージョンをあげる
ローカルでとりあえず試そうとしましたが...
$ curl -s http://localhost:11434/api/embed -H 'content-type: application/json' -d '{"model":"embeddinggemma:300m","input":["東 京の天気","寿司が食べたい"]}'
{"error":"this model does not support embeddings"}
と最初エラーになりました。
(ChatGPT談ですが)ollamaで/embedが利用できるのはv0.11.10以降らしいです。
$ ollama --version
ollama version is 0.11.4
確かに0.11.4なので古いですね。
バージョンアップします。
$ curl -fsSL https://ollama.com/install.sh | sh
再確認すると0.11.11になりました。
$ ollama --version
ollama version is 0.11.11
来ました
改めてローカルから試す
$ curl -s http://localhost:11434/api/embed -H 'content-type: application/json' -d '{"model":"embeddinggemma:300m","input":["東 京の天気","寿司が食べたい"]}'
{"model":"embeddinggemma:300m","embeddings":[[-0.17842108,-0.003002565,0.053567614,0.007768844,0.015386832,0.03235181,-0.020633992,0.01612448,0.028137116,-0.063197635,-0.004824459,-0.012347473,0.034683675,-0.015954712,0.10620198,0.034900498,0.037444353,-0.032316588,-0.
。。。
という感じでベクトル化に成功しました。
STEP2: ローカル(Jetson Nano)のollamaに外部からアクセスできるようにする
ここに関しては何個か記事にまとめてます。
Cloudflare Tunnelsを使ってJetson Nanoに直アクセスできるように
他の記事にまとめてますがCloudflare Tunnelsを使ってトンネリングさせます。
- (STEP2-0: 家にあるJetson Nanoを家の外からアクセスしたい)
これはやらなくてもいいけど外からアクセスできるようにしておくと便利
- STEP2-1: 家にあるJetson Nanoのollamaに外部のWebサービスからアクセスできるようにしたい
ローカルのollamaに対してDifyからアクセスするだけならこれでOK。
- STEP2-2: 家にあるJetson Nanoのollamaに外部のWebサービスからアクセスできるようにしてURLの固定化
ただ、STEP2-1の状態だとURLが毎回異なるのでDifyだとモデルプロバイダーの設定しなおしになったりと扱いにくいです。ということで固定化します。
ここまでの記事でhttps://ollma.hogehoge.comなどにアクセスすると埋め込みができるようになりました。
ollama-tunnelという名前でトンネリング

STEP3: Difyから利用
クラウド版のDifyから家にあるJetson Nanoの中にあるEmmbeddingGemmaを利用してみます。
モデルプロバイダー設定
モデルプロバイダーからOllamaを選択して設定します。
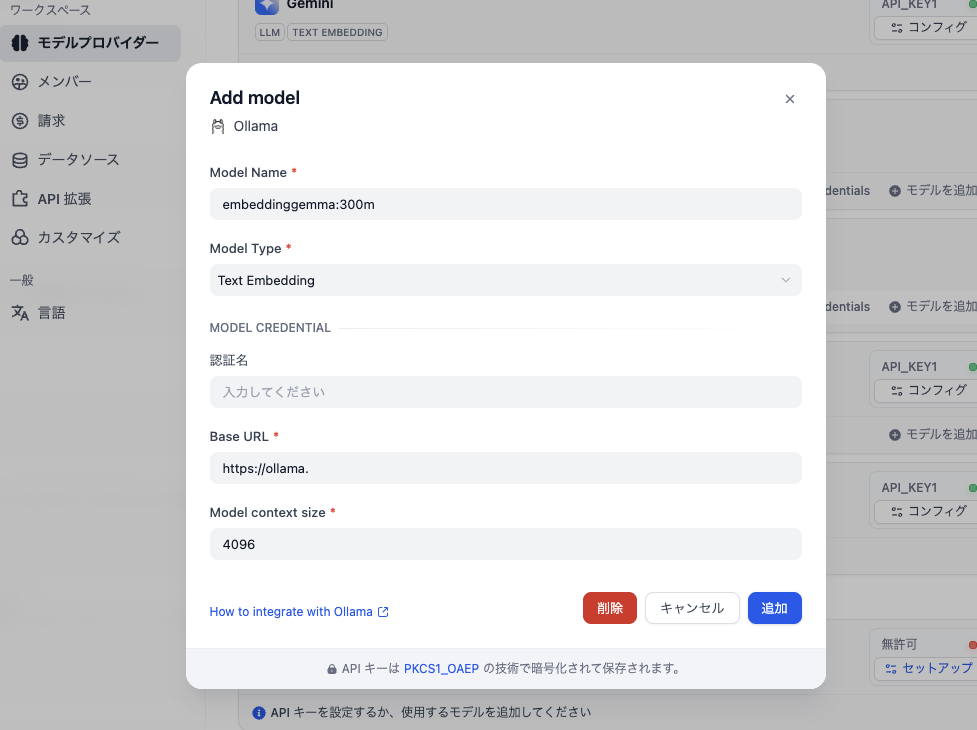
- Model Name:
embeddinggemma:300m - Model Type: Text Embedding
- Base URL:
https://ollma.hogehoge.comなどの外部アクセスできるようにしてあるURL
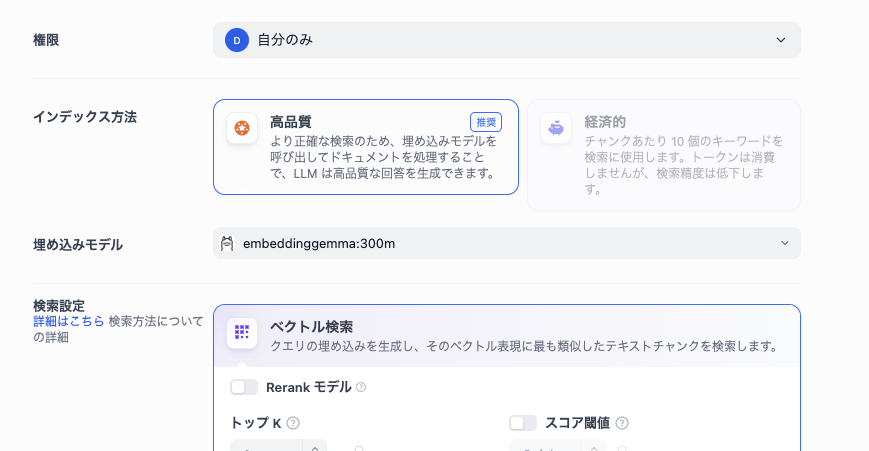
Difyで埋め込み
あとは通常通りでナレッジベースの項目から埋め込みモデルの選択に進み、embeddinggemma:300mを選択します。
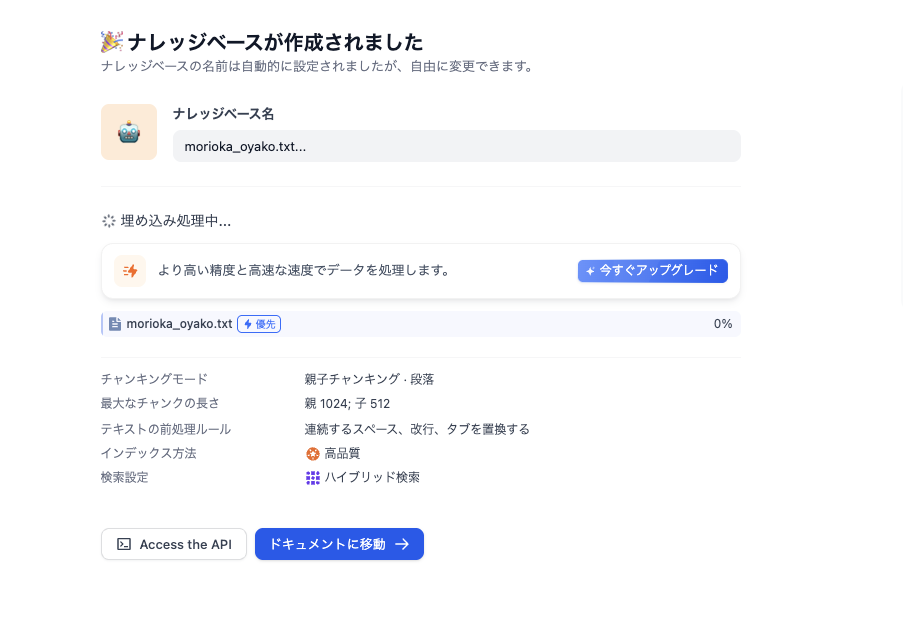
Jetson Nanoでやってるからってのもありますが、3分くらいかかりました。
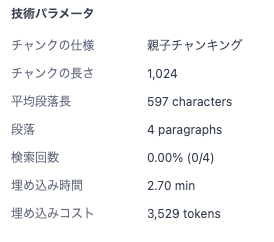
2.70minとのことです。
他の埋め込みモデルと比較
同様にGoogle系のgemini-embedding-exp-03-07と比較してみました。対象はどちらも盛岡の観光ナレッジのテキストファイルです。
単語数や文字数
gemini-embedding-exp-03-07で埋め込んだ時と単語数は2.4Kで同じ
と思ったら1文字ずれてました。ほぼ一緒といえば一緒。
-
embeddinggemma:300m- 埋め込みコスト: 3529トークン
- チャンクの文字数: 13 / 790 / 780 / 798
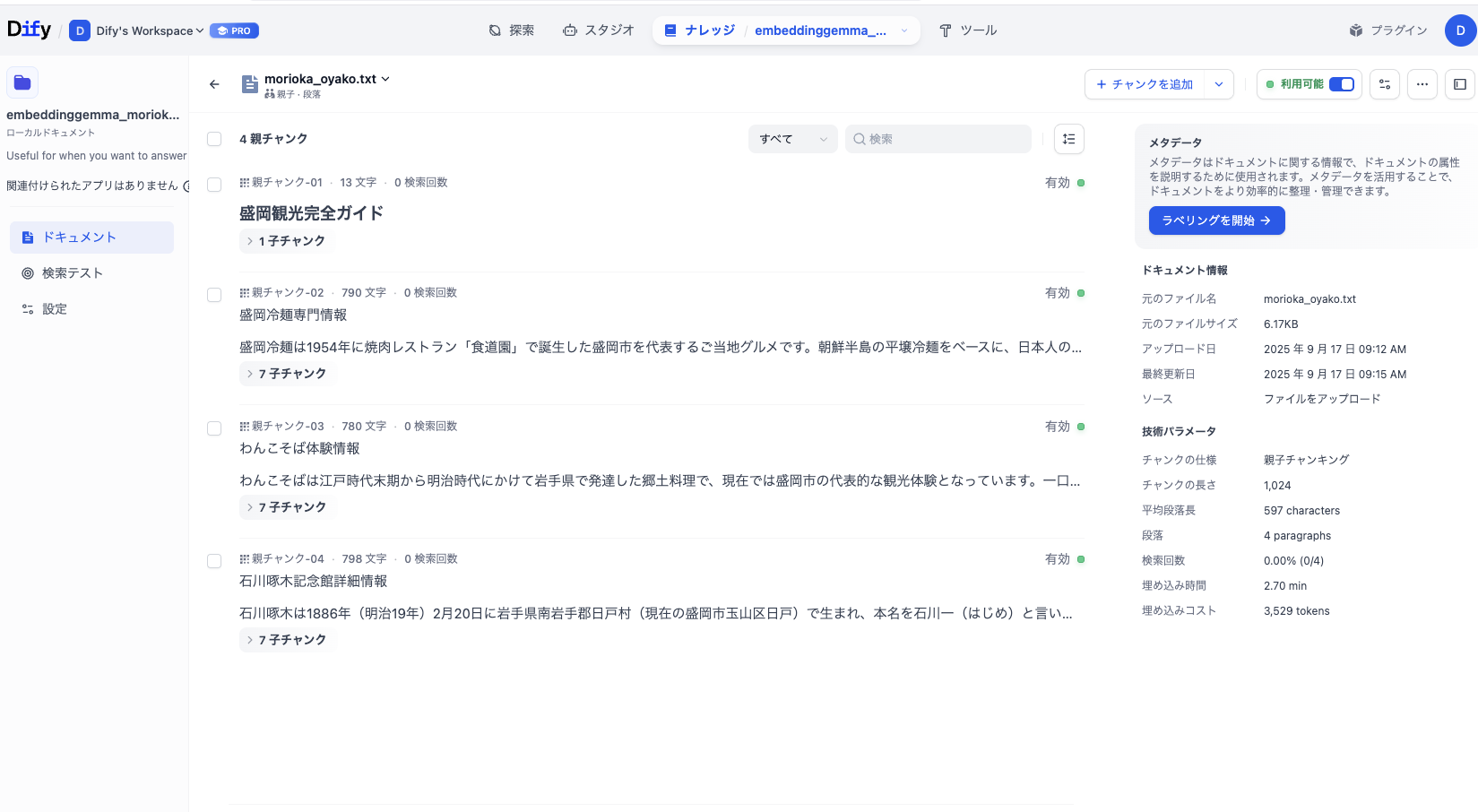
-
gemini-embedding-exp-03-07- 埋め込みコスト: 3530トークン
- チャンクの文字数: 13 / 791 / 781 / 799
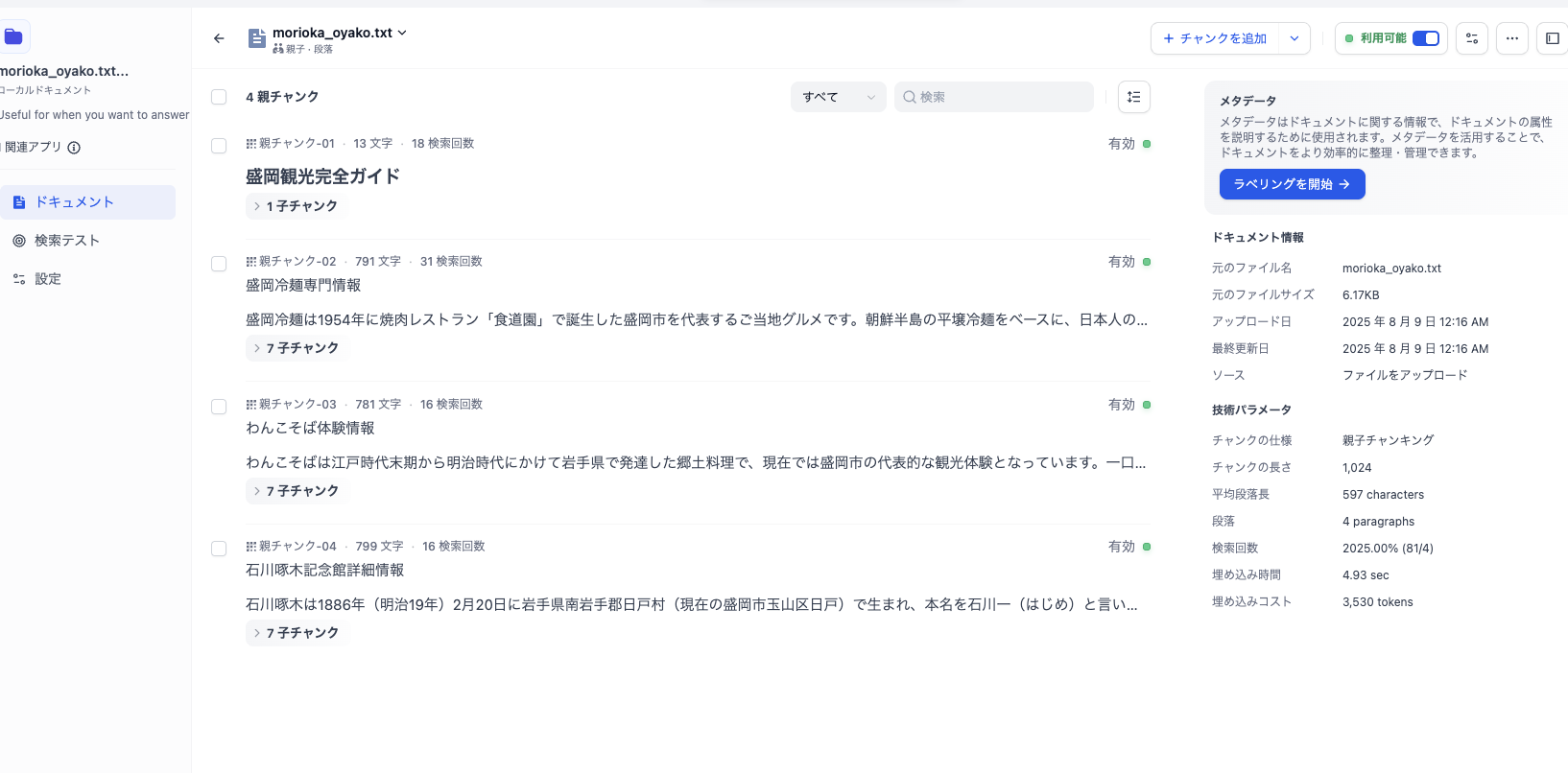
先頭のスペースがembeddinggemma:300mの方が削除されてました。
検索
"盛岡で冷麺を食べたい"と検索して試してみました。検索はどちらもリランクは使わずハイブリッドのウェイト設定。TopKは10に設定してます。
-
embeddinggemma:300m- 検索された親チャンク数2
- 検索された子チャンク数どれも1
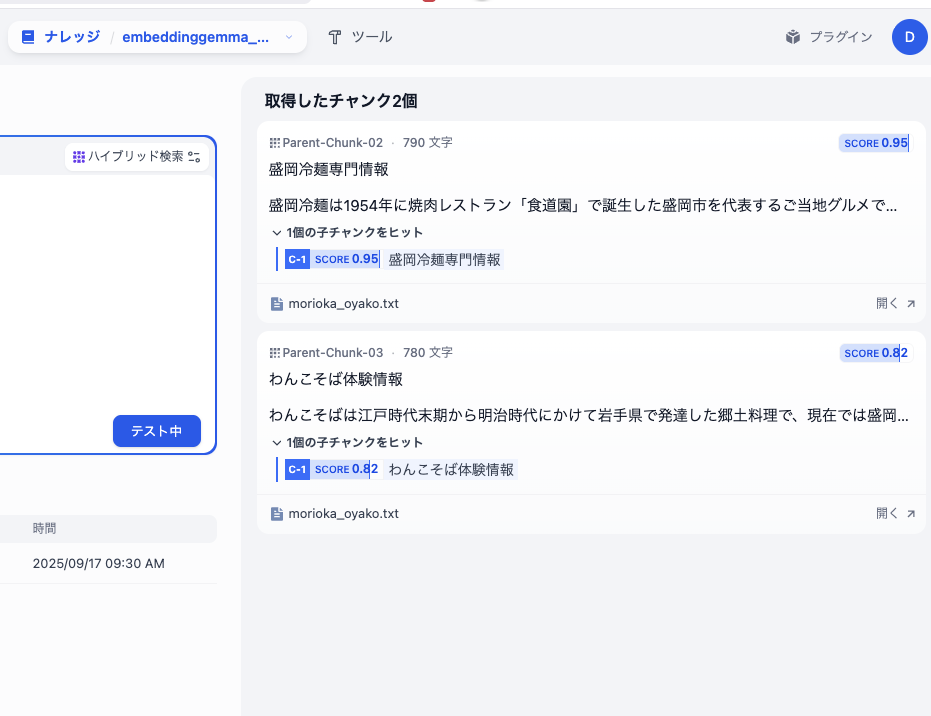
-
gemini-embedding-exp-03-07- 検索されたチャンク数4
- 検索された子チャンク数 1~5
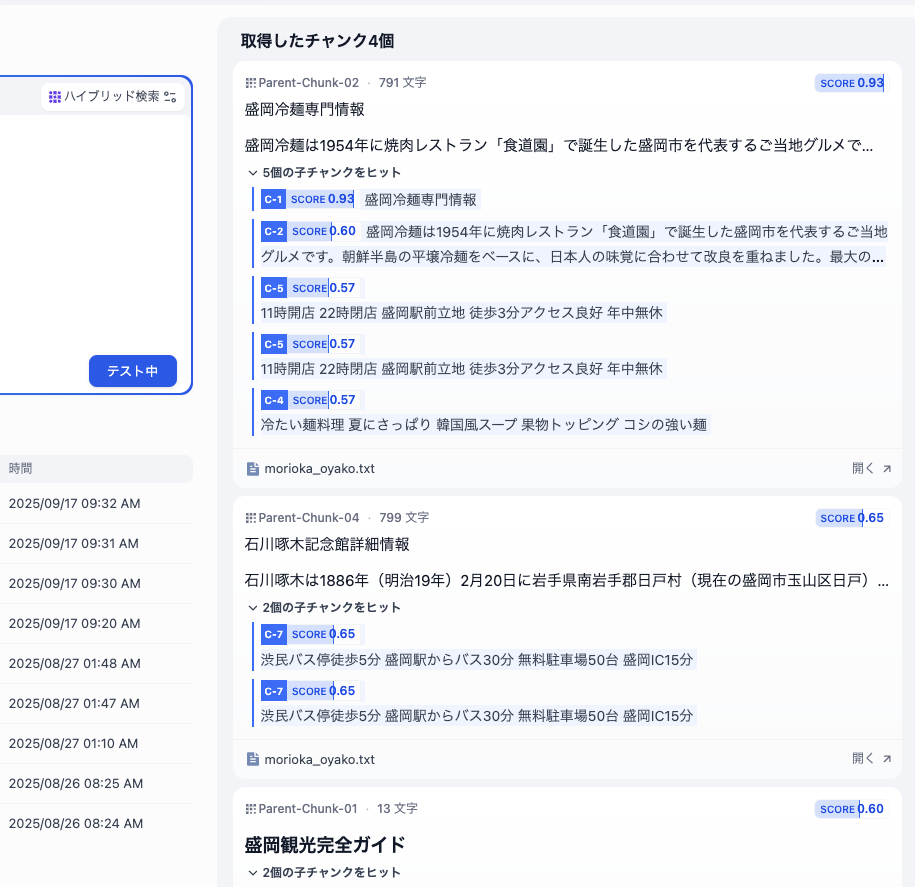
ということでgemini-embedding-exp-03-07のほうが広くチャンク検索されて、子チャンクも候補が多いですね。
embeddinggemma:300mでもこの知識テストだと良さそうな結果は出てるのですが冗長さを排除しているような気配を感じます。
デバイス上での検索を考えるとメモリ制約もあるのでこれくらいがちょうど良いような気もしますね
まとめ
Jetson NanoでEmbeddingGemmaを動かしてDifyから使ってみました。
埋め込みは事前処理なので処理スピードもあまり気にならず使えそうな印象でした。
ローカルで動くことによって社内情報のような機密情報をAPI経由で埋め込みしたくない、といったニーズなどに刺さりそうなのでこういったローカルLLMでの埋め込みは注目されていきそうですね。
無理にJetson Nanoで動かす必要はないので、ただ使うだけであればHugging FaceのAPIやどこかのクラウドサーバーにおいたollamaなどで動かすなどのほうが安定して使えると思います。