はじめに
普段はChainerでディープラーニングモデルを構築しているのですが、今回はTensorFlowに浮気してみます。
と言っても、TensorFlowでNNモデルを構築すると、結構複雑になりやすくて難しい。。。
というのは、そもそもTensorFlowはディープラーニング用のライブラリではなくて、数値計算ライブラリだから(トップページのAbout TensorFlowの一行目に書いてある)です。かなり汎用的に使える分、使いこなすのが難しく、うまく使うとディープラーニングもできるよ!って感じで。
なので、そこを良しなにやってくれるラッパーライブラリももちろんあります(Keras, TF-Slim)。
今回は、今年の4月にDeepMind社がリリースしたSonnetというTensorFlowのラッパーライブラリを(今更)使ってみます。
Sonnetはニューラルネットに特化したTensorFlowのライブラリです。
Sonnetの特徴として、ネットワークをModuleと呼ばれる再利用可能な複数のサブクラスで構成する、という点があります。層や関数をパーツごとにModuleで作っておき、全体のネットワークはそれらを再利用しながら組み合わせて構成することができます。
また、SonnetはTensorFlowのコードをミックスすることができるため、ある部分はSonnetで簡潔にコーディング、ある部分はTensorFlowでしっかり作り込む、なんてこともできます。研究目的で使う場合などは、実験的に作っている部分をTensorFlowで作り、その他の部分はSonnetで作って使い回す、なんてこともできるのでかなり柔軟に使えて良さげです。個人的にはここが一番嬉しい。
インストール
2017/12/1現在で、対応しているのはPython2.7/3.4/3.5/3.6だそうです。
TensorFlowとSonnetをpipでインストールします。
$ pip install tensorflow dm-sonnet
GPU環境では
$ pip install tensorflow-gpu dm-sonnet
ここで注意。pipでインストールするとき、pip install sonnetとしてしまうと、全然関係ないライブラリがインストールされるみたいです。。
dm-sonnetです。dm-をつけてください。
あと、GPU版のTensorFlowは、バージョン1.4.0だとPython3.6でインポートした時に
RuntimeWarning: compiletime version 3.5 of module 'tensorflow.python.framework.fast_tensor_util' does not match runtime version 3.6
という警告が出ます。
ここによると、待つか、警告を無視するか、バージョン1.3.0をインストールすれば良いみたいです。
インストールが完了したら、確認してみます。
import tensorflow as tf
import sonnet as snt
正しくインポートできたらOKです。
とりあえず試してみる
Module
Sonnetでは、ニューラルネットワークをModuleというサブクラスの集まりで定義し、これらのサブクラスは全てsonnet.AbstractModuleを継承しています。
Sonnetの中で定義されているAffine層sonnet.Linearや畳み込み層sonnet.Conv2D等も全てsonnet.AbstractModuleを継承しており、これらを組み合わせて全体のネットワークを構成することになります。
この辺りの仕組みはなんとなくChainerに近い気がします。LinkモジュールやChainモジュール複数繋げて1つのネットワークを構成するところとか。
モデル定義
MNISTを例題にモデルを構成してみます。すごく簡単なやつ。
以下のように書くことで、モデルを定義することができます。
import tensorflow as tf
import sonnet as snt
# 入力データを用意
train_data = get_training_data()
test_data = get_test_data()
# 層ごとに定義
conv1 = snt.Conv2D(output_channels=16, kernel_shape=3, stride=1, name='conv1')
bn1 = snt.BatchNorm(name='bn1')
conv2 = snt.Conv2D(output_channels=16, kernel_shape=3, stride=1, name='conv2')
bn2 = snt.BatchNorm(name='bn2')
bf = snt.BatchFlatten(name='bf')
l = snt.Linear(output_size=10, name='l')
# Sequentialで層を連結
mlp = snt.Sequential([conv1, tf.nn.relu, bn1, conv2, tf.nn.relu, bn2, bf, l, tf.nn.softmax])
# データをネットワークに通す
train_prediction = mlp(train_data)
test_prediction = mlp(test_data)
上記の他には、このようにネットワークを定義できます。
import tensorflow as tf
import sonnet as snt
# モデル定義
class MLP(snt.AbstractModule):
def __init__(self, output_size, nonlinearity=tf.relu, name='mlp'):
super(MLP, self).__init__(name=name)
self._output_size = output_size
self._nonlinearity = nonlinearity
# 学習パラメータ設定(_build()の内部で書くことも可)
with self._enter_variable_scope():
self._conv1 = snt.Conv2D(output_channels=16, kernel_shape=3, stride=1, name='conv1')
self._bn1 = snt.BatchNorm(name='bn1')
self._conv2 = snt.Conv2D(output_channels=16, kernel_shape=3, stride=1, name='conv2')
self._bn2 = snt.BatchNorm(name='bn2')
self._bf = snt.BatchFlatten(name='bf')
self._l = snt.Linear(output_size=self._output_size, name='l')
# 順伝播を記述(Chainerで言うところのforward(), __call__())
def _build(self, inputs, is_training):
cnv1 = self._conv1
h = self._nonlinearity(cnv1(inputs))
h = self._bn1(h, is_training=is_training)
cnv2 = self._conv2
h = self._nonlinearity(cnv2(h))
h = self._bn2(h, is_training=is_training)
h = self._bf(h)
l = self._l
outputs = tf.nn.softmax(l(h))
return outputs, h
# 入力データを用意
train_data = get_training_data()
test_data = get_test_data()
mlp = MLP(output_size=10, nonlinearity=tf.nn.relu)
# データをネットワークに通す
train_prediction = mlp(train_data)
test_prediction = mlp(test_data)
上の書き方では、sonnet.AbstractModuleを継承した新しいモジュールとしてネットワークを定義します。個人的にはこちらの方がわかりやすく、拡張性も高いので以後こちらの記法で進めることにします。
sonnet.AbstractModuleを継承してモジュールを作成する場合、必ず_build()メソッドを記述する必要があります。ここでモジュール内で行いたい計算を記述し、計算グラフを構築します。
MLPモジュールの内部で示すように、SonnetによるモジュールとTensorFlowの関数がミックスして記述してあります。基本的にはtf.nn.reluやtf.nn.softmaxなどの活性化関数やtf.nn.max_poolといったプーリング操作などの関数はTensorFlowの関数を用いて記述し、学習対象のパラメータを含むAffine層や畳み込み層はSonnetのサブモジュールを用いて記述する、といった感じです。もちろん、Sonnetのサブモジュールで記述されている部分をTensorFlowを用いて直書きしても問題ありません。
上記の例では、Sonnetのサブモジュールをコンストラクタ内で全て定義していましたが、以下のように_build()内に書くこともできます。
# モデル定義
class MLP(snt.AbstractModule):
def __init__(self, output_size, nonlinearity=tf.relu, name='mlp'):
super(MLP, self).__init__(name=name)
self._output_size = output_size
self._nonlinearity = nonlinearity
# 順伝播を記述
def _build(self, inputs, is_training):
conv1 = snt.Conv2D(output_channels=16, kernel_shape=3, stride=1, name='conv1')
h = self._nonlinearity(conv1(inputs))
h = snt.BatchNorm(name='bn1')(h, is_training=is_training)
conv2 = snt.Conv2D(output_channels=16, kernel_shape=3, stride=1, name='conv2')
h = self._nonlinearity(conv2(h))
h = snt.BatchNorm(name='bn2')(h, is_training=is_training)
h = snt.BatchFlatten(name='bf')(h)
l = snt.Linear(output_size=self._output_size, name='l')
outputs = tf.nn.softmax(l(h))
return outputs
コンストラクタ内でサブモジュールを記述する際には、with self._enter_variable_scope()の内部で書くことになります。
MNISTを学習してみる
上で定義したMLPを用いて、MNISTを学習してみます。
学習部分を記述する前に、データ供給用のモジュールを定義します。こちらのモジュールも、sonnet.AbstractModuleを継承して作成します。
# MNISTデータセット
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets
# データセットのインスタンス(class MNISTに mnist.train, mnist.validation, mnist.testをそれぞれ渡す)
mnist = read_data_sets('./MNIST_data', one_hot=True)
# データセットモジュール定義
class MNIST(snt.AbstractModule):
def __init__(self, mnist, batch_size, name='mnist'):
super(MNIST, self).__init__(name=name)
# データ数
self._num_examples = mnist.num_examples
# 画像(tf.constant)
self._images = tf.constant(mnist.images, dtype=tf.float32)
# ラベル(tf.constant)
self._labels = tf.constant(mnist.labels, dtype=tf.float32)
self._batch_size = batch_size
def _build(self):
# サンプラー(バッチ数)
indices = tf.random_uniform([self._batch_size], 0, self._num_examples, tf.int64)
x = tf.reshape(tf.gather(self._images, indices), (self._batch_size, 1, 28, 28))
y_ = tf.gather(self._labels, indices)
return x, y_
def cost(self, logits, target):
loss = -tf.reduce_sum(target * tf.log(logits))
return loss
def evaluation(self, logits, target):
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(target, 1))
acc = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return acc
このモジュールを用いてインスタンスを作成した時点でデータがセットされ、インスタンスが呼び出される度にバッチサイズ分のデータが供給される、という仕組みです。
注目すべき点は、学習する誤差関数と評価関数がデータセットモジュールに定義されていることです。Chainerのexampleなどでも、誤差関数と評価関数はNNモデルに対して定義されているのですが、本来、誤差関数/評価関数はNNモデルで決まるのではなく学習問題に対して決まるはずです。そのため、データセットと誤差関数/評価関数をまとめて定義するのが自然です。と、個人的に思います。
さて、ここまでで必要なモジュールの定義はできたので、全体の計算グラフを定義していきます。
# パラメータ設定
# TensorFlowと同じ
FLAGS = tf.flags.FLAGS
tf.flags.DEFINE_integer("num_training_iterations", 2000, "Number of iterations to train for.")
tf.flags.DEFINE_integer("report_interval", 50, "Iterations between reports (samples, valid loss).")
tf.flags.DEFINE_integer("batch_size", 64, "Batch size for training.")
tf.flags.DEFINE_integer("output_size", 10, "Size of MLP output layer.")
# データ供給用オブジェクトを作成
dataset_train = MNIST(mnist.train, batch_size=FLAGS.batch_size, name='mnist_train')
dataset_validation = MNIST(mnist.validation, batch_size=FLAGS.batch_size, name='mnist_validation')
dataset_test = MNIST(mnist.test, batch_size=FLAGS.batch_size, name='mnist_test')
# make MLP object
model = MLP(output_size=FLAGS.output_size, nonlinearity=tf.nn.relu)
# Build the training model and get the training loss.
# データ抽出
train_x, train_y_ = dataset_train()
# モデル順伝播
train_y, _ = model(train_x, True)
# loss計算
train_loss = dataset_train.cost(train_y, train_y_)
# lossをsummaryに保存(TensorBoard用)
tf.summary.scalar('loss', train_loss)
# Get the validation loss.
# データ抽出
validation_x, validation_y_ = dataset_validation()
# モデル順伝播
validation_y, _ = model(validation_x, False)
# loss計算
validation_loss = dataset_validation.evaluation(validation_y, validation_y_)
# validation accuracyをsummaryに保存(TensorBoard用)
tf.summary.scalar('validation_accuracy', validation_loss)
# Get the test loss.
# データ抽出
test_x, test_y_ = dataset_test()
# モデル順伝播
test_y, _ = model(test_x, False)
# loss計算
test_loss = dataset_test.evaluation(test_y, test_y_)
# test accuracyをsummaryに保存(TensorBoard用)
tf.summary.scalar('test_accuracy', test_loss)
# 中間層出力を取得(TensorBoard用)
_, features = model(tf.reshape(tf.constant(mnist.test.images, dtype=tf.float32), (-1, 1, 28, 28)), False)
# Set up optimizer.
train_step = tf.train.AdamOptimizer().minimize(train_loss)
モデルの学習部分は、TensorFlowと同様です。
# loggingレベルの設定
tf.logging.set_verbosity(tf.logging.INFO)
# training
# モデル保存先ディレクトリ(=TensorBoardの--logdir)
log_dir = 'test_sonnet/'
with tf.Session() as sess:
# パラメータ初期化
sess.run(tf.global_variables_initializer())
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter(log_dir, sess.graph)
# メインループ
for training_iteration in range(1, FLAGS.num_training_iterations + 1):
# with validation
if (training_iteration) % FLAGS.report_interval == 0:
# train, validationのloss計算、optimize
summary_, train_loss_v, validation_loss_v, _ = sess.run((merged, train_loss, validation_loss, train_step))
# logging
tf.logging.info("%d: Training loss %f. Validation accuracy %f.", training_iteration, train_loss_v, validation_loss_v)
writer.add_summary(summary_, training_iteration)
else:
summary_, train_loss_v, _ = sess.run((merged, train_loss, train_step))
writer.add_summary(summary_, training_iteration)
test_loss_v = sess.run(test_loss)
tf.logging.info("Test accuracy %f.", test_loss_v)
# 中間層出力を取得してembedding_varとして保存
feature = sess.run(features)
embedding_var = tf.Variable(tf.stack([tf.squeeze(x) for x in feature], axis=0), trainable=False, name='feature')
sess.run(tf.variables_initializer([embedding_var]))
# モデルを保存
saver = tf.train.Saver()
saver.save(sess, log_dir + "model.ckpt")
# TensorBoardの設定(PROJECTOR用)
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
embedding.tensor_name = embedding_var.name
# メタデータのファイル名
embedding.metadata_path = 'labels.tsv'
# sprite画像のファイル名
embedding.sprite.image_path = 'mnist_10k_sprite.png'
# sprite画像の画像サイズ
embedding.sprite.single_image_dim.extend([28, 28])
projector.visualize_embeddings(writer, config)
# label to TSV
import numpy as np
ls = np.argmax(mnist.test.labels, axis=1)
with open(log_dir + 'labels.tsv', 'w') as f:
f.write('number\tlabel\n')
for i, l in enumerate(ls):
f.write('{}\t{}\n'.format(i, l))
以上の内容を実際に実行すると、以下のような表示が得られます。
$ python test_Sonnet.py
Extracting ./MNIST_data/train-images-idx3-ubyte.gz
Extracting ./MNIST_data/train-labels-idx1-ubyte.gz
Extracting ./MNIST_data/t10k-images-idx3-ubyte.gz
Extracting ./MNIST_data/t10k-labels-idx1-ubyte.gz
2017-12-07 15:32:04.352577: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
2017-12-07 15:32:04.352602: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
2017-12-07 15:32:04.352607: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.
2017-12-07 15:32:04.352610: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
INFO:tensorflow:50: Training loss 50.490936. Validation accuracy 0.890625.
INFO:tensorflow:100: Training loss 34.959198. Validation accuracy 0.937500.
INFO:tensorflow:150: Training loss 23.428505. Validation accuracy 0.937500.
INFO:tensorflow:200: Training loss 16.100609. Validation accuracy 0.906250.
INFO:tensorflow:250: Training loss 12.280136. Validation accuracy 0.890625.
INFO:tensorflow:300: Training loss 8.765541. Validation accuracy 0.953125.
INFO:tensorflow:350: Training loss 7.346501. Validation accuracy 0.968750.
INFO:tensorflow:400: Training loss 8.775402. Validation accuracy 0.906250.
INFO:tensorflow:450: Training loss 11.957666. Validation accuracy 0.968750.
INFO:tensorflow:500: Training loss 7.145435. Validation accuracy 0.937500.
INFO:tensorflow:550: Training loss 10.333065. Validation accuracy 0.968750.
INFO:tensorflow:600: Training loss 4.118176. Validation accuracy 0.984375.
INFO:tensorflow:650: Training loss 5.646952. Validation accuracy 0.953125.
INFO:tensorflow:700: Training loss 10.595457. Validation accuracy 1.000000.
INFO:tensorflow:750: Training loss 6.184578. Validation accuracy 0.968750.
INFO:tensorflow:800: Training loss 4.745983. Validation accuracy 0.937500.
INFO:tensorflow:850: Training loss 7.256283. Validation accuracy 0.890625.
INFO:tensorflow:900: Training loss 5.420124. Validation accuracy 0.937500.
INFO:tensorflow:950: Training loss 6.620344. Validation accuracy 0.937500.
INFO:tensorflow:1000: Training loss 5.592537. Validation accuracy 0.953125.
INFO:tensorflow:1050: Training loss 1.911144. Validation accuracy 0.953125.
INFO:tensorflow:1100: Training loss 4.368665. Validation accuracy 0.953125.
INFO:tensorflow:1150: Training loss 3.458136. Validation accuracy 0.968750.
INFO:tensorflow:1200: Training loss 7.255634. Validation accuracy 0.968750.
INFO:tensorflow:1250: Training loss 2.520838. Validation accuracy 0.953125.
INFO:tensorflow:1300: Training loss 4.017866. Validation accuracy 0.953125.
INFO:tensorflow:1350: Training loss 9.276357. Validation accuracy 0.953125.
INFO:tensorflow:1400: Training loss 6.134557. Validation accuracy 0.968750.
INFO:tensorflow:1450: Training loss 1.248195. Validation accuracy 0.984375.
INFO:tensorflow:1500: Training loss 2.018519. Validation accuracy 0.984375.
INFO:tensorflow:1550: Training loss 16.740910. Validation accuracy 0.984375.
INFO:tensorflow:1600: Training loss 2.468229. Validation accuracy 0.953125.
INFO:tensorflow:1650: Training loss 3.996381. Validation accuracy 0.984375.
INFO:tensorflow:1700: Training loss 3.077335. Validation accuracy 1.000000.
INFO:tensorflow:1750: Training loss 4.533401. Validation accuracy 0.984375.
INFO:tensorflow:1800: Training loss 4.290820. Validation accuracy 0.968750.
INFO:tensorflow:1850: Training loss 7.975511. Validation accuracy 0.953125.
INFO:tensorflow:1900: Training loss 2.756756. Validation accuracy 0.984375.
INFO:tensorflow:1950: Training loss 3.272305. Validation accuracy 0.984375.
INFO:tensorflow:2000: Training loss 1.360340. Validation accuracy 0.984375.
INFO:tensorflow:Test accuracy 0.984375.
ついでにTensorBoard
TensorFlowを使っているのでせっかくだからTensorBoardを使って色々可視化してみます。
下ごしらえは上記のコード中にちょろちょろ書いていたのですが、今回表示するのは
- loss/validation accuracy/test accuracy曲線(SCALARS)
- ネットワークグラフ(GRAPHS)
- 特徴量可視化(PROJECTOR)
です。
学習実行後に
$ tensorboard --logdir test_sonnet/
でTensorBoardが起動します。--logdirはコード中に設定しているディレクトリです。
起動後にhttp://localhost:6006(ポートは設定ファイルで変更可能)にブラウザでアクセスすることで、色々見ることができます。
loss/accuracy曲線は以下のような感じです。
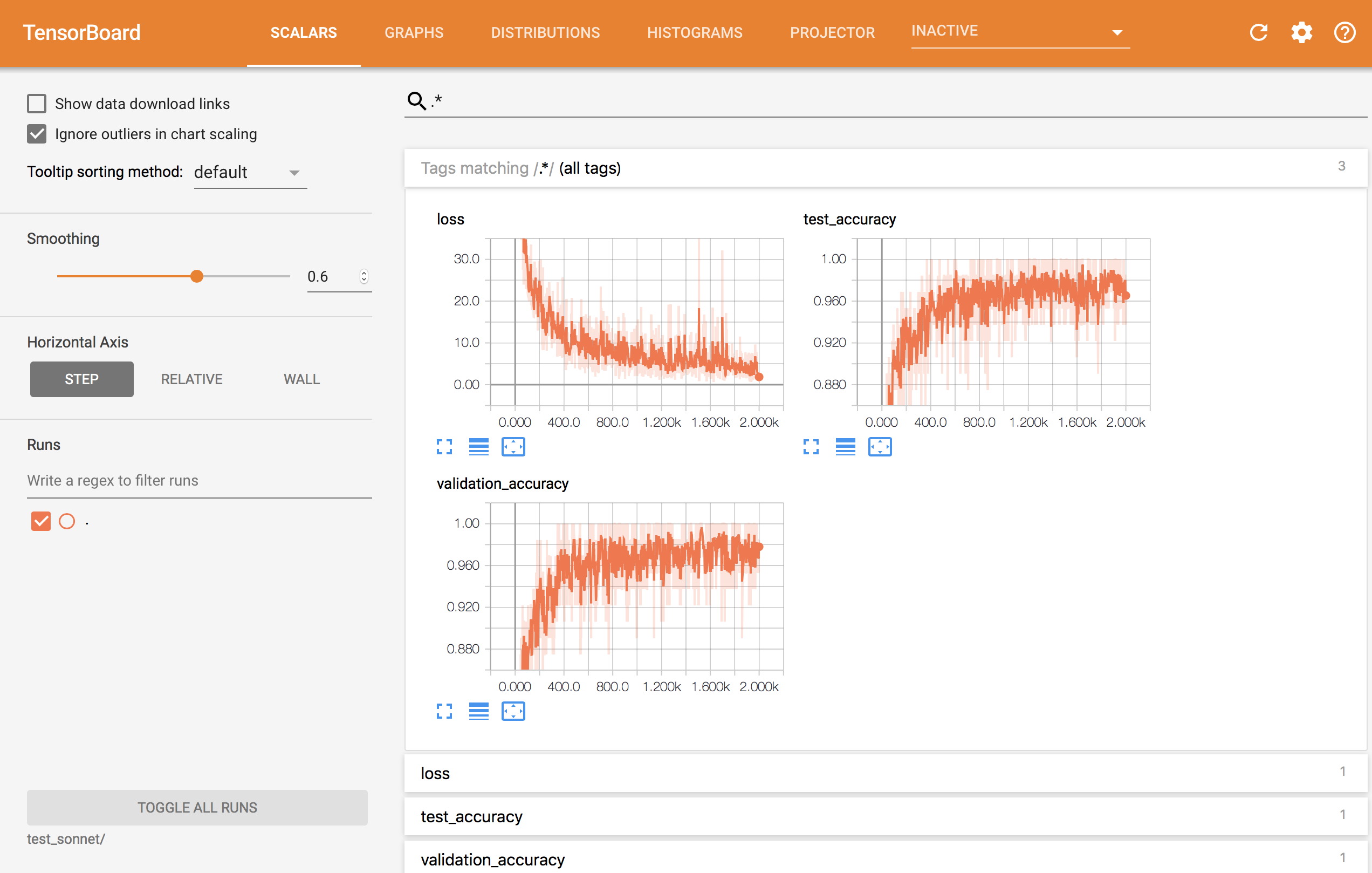
学習途中で表示することもでき、リアルタイムに学習の様子を確認することができます。
ネットワークグラフは以下のようになります。
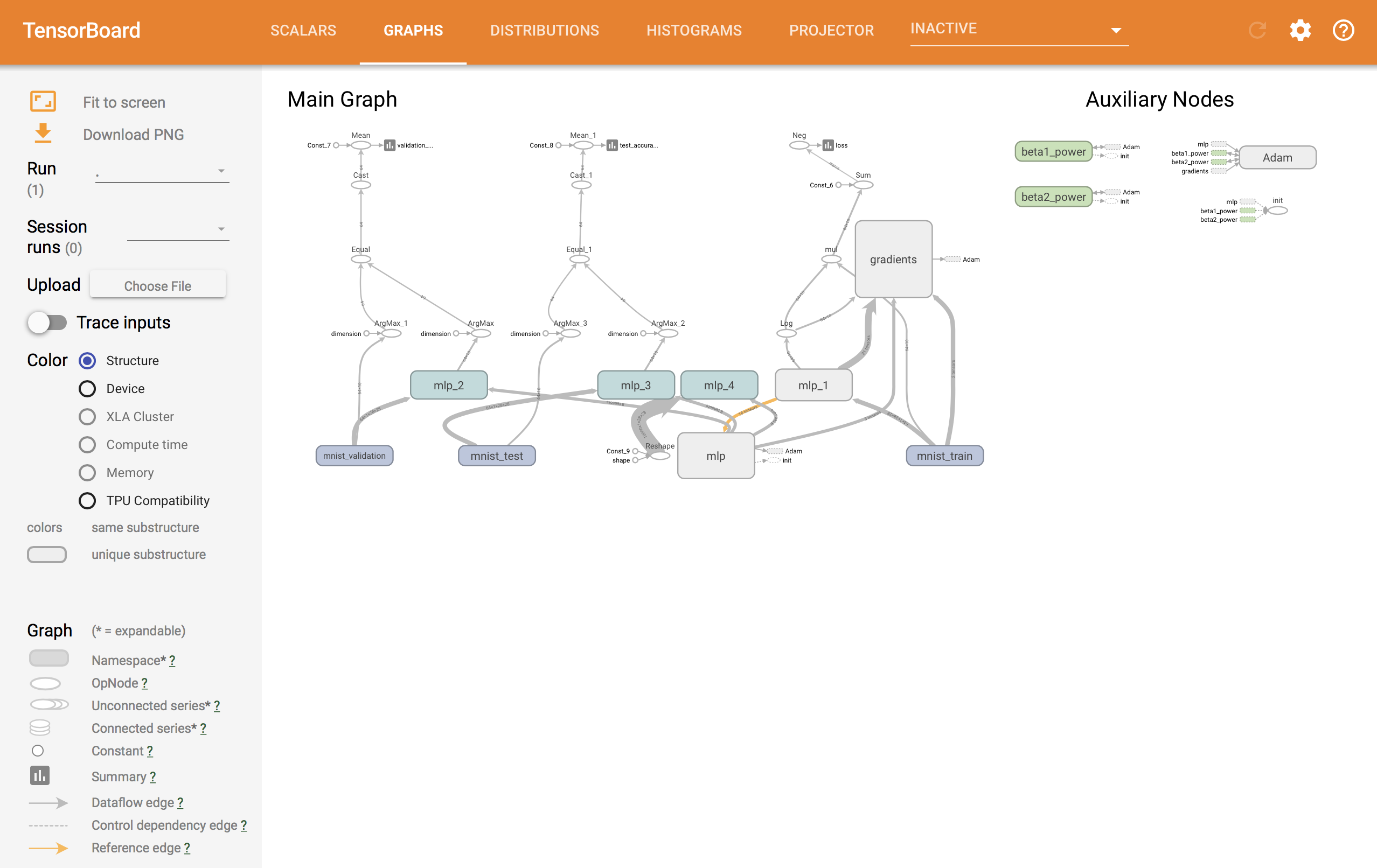
Sonnetのサブモジュールを組み合わせて構成することで、全体構成がだいぶ把握しやすくなっています。
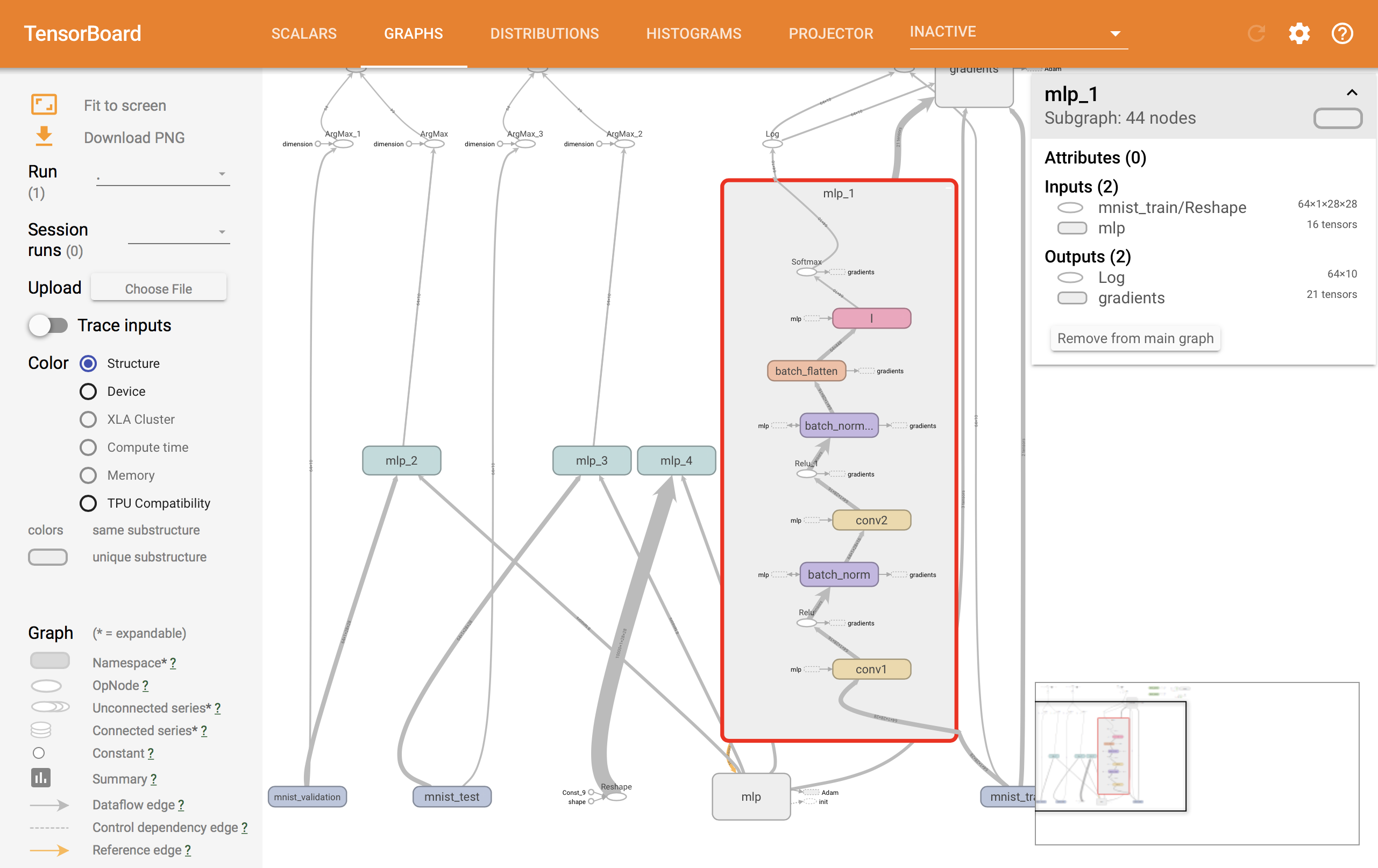
mlp_1の内部を表示すると、以下のようにネットワーク内部の構造を見ることができます。色付きのボックスで表示されているものは全てSonnetのサブモジュールとなります。この中にTensorFlowによる計算グラフがあるのですが、サブモジュールを使うことでこれらが機能ごとにまとまって表示されるため、とても見やすくなります。
お待ちかね、Embedding Visualizationです。
事前にラベル等のメタデータを保存したTSVファイルと、画像を表示する場合はsprite画像を用意する必要があります。それらのファイルをコード中に指定したファイル名でモデル保存先と同じディレクトリに置き、TensorBoardを表示するとこんな感じ↓
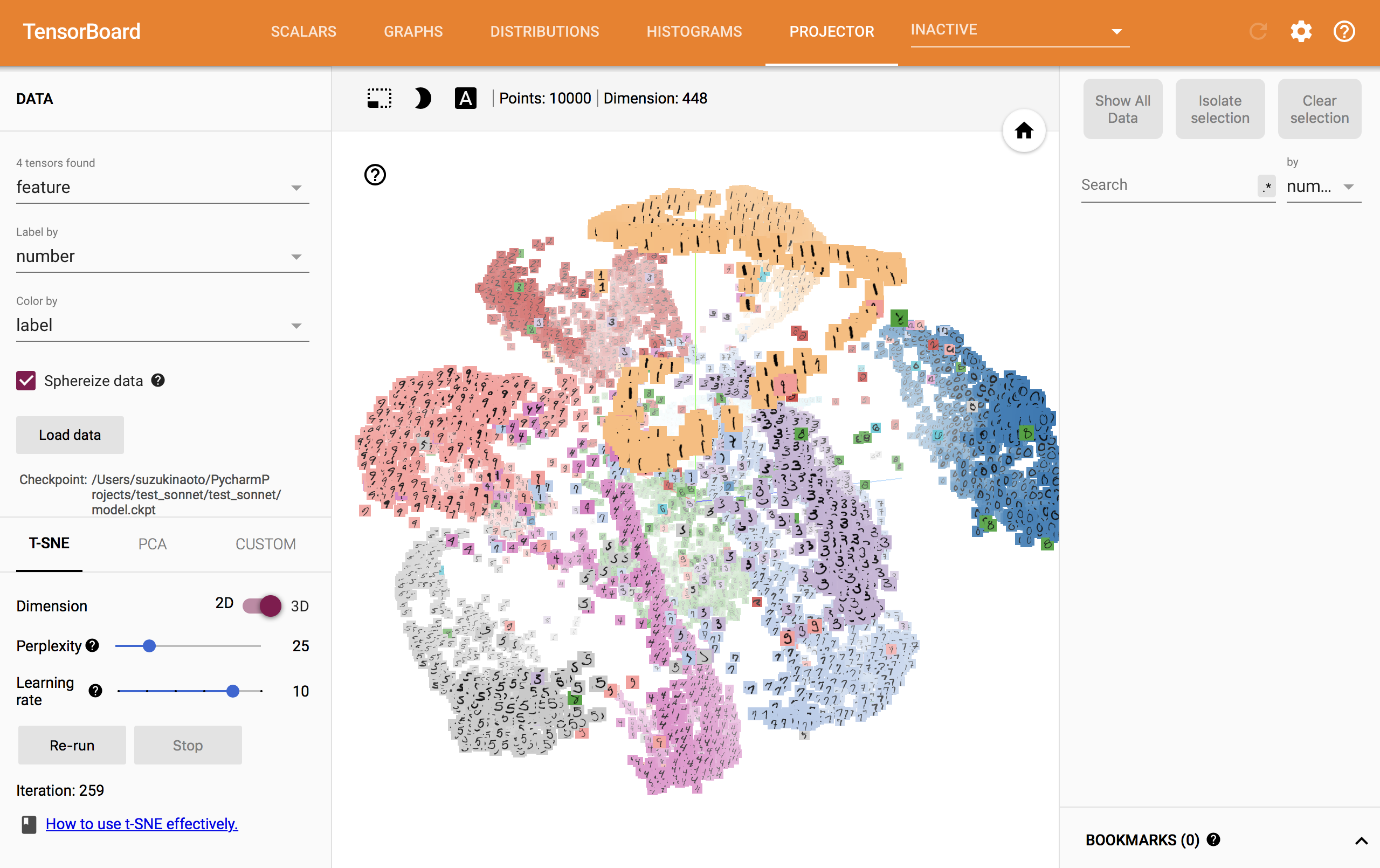
今回出力した特徴量は、最後のAffine層の直前の出力です。表示したグラフは自分でグリグリ動かすことができます。結構楽しい笑
次回予告
以上までが一通りのSonnetの使い方です。と言っても、まだまだ使いこなしてはいませんが。。
次の記事では応用編で、XceptionモデルをSonnetで実装してみようと思います。(※予定が変わるかもしれません!)