この記事はスタンバイ Advent Calendar 2022の21日目の記事です。
Modern Data Stackの一つであるDBTについて、Amazon Athenaで利用できるかを検証してみることにしました。
DBTとは
ELT処理 (Extract、Load、Transform) のTransformの工程を効率化できるツール、という位置づけです。
詳細は割愛しますが、以下の記事がわかりやすくまとめられています。
dbt-athenaとは
dbtのAthena用Adapterです。
大前提として、Saas版であるdbt Cloudでは非サポートであるため、CLI版であるdbt-coreを利用することになります。
開発コミュニティ
githubで開発が進められています。執筆時点での最新バージョンは1.3.3です。
以前はfork元である別repositoryで開発が行われていたようで、PyPIパッケージ名もdbt-athena-adapterでしたが、
直近ではこちらのrepositoryに移りパッケージ名もdbt-athena-communityに変わっています。
環境構築
公式ドキュメントの手順に従って構築します。
また、旧バージョン (dbt-athena-adapter==1.0.1以前) の情報ではありますが以下の記事も参考にさせていただきました。
% python -V
Python 3.10.8
% pip install dbt-athena-community==1.3.3
(中略)
% dbt --version
Core:
- installed: 1.3.1
- latest: 1.3.1 - Up to date!
Plugins:
- athena: 1.3.3 - Ahead of latest version!
※↑ちなみに、筆者の環境ではversion1.3.2以前では上記のPlugins:の部分に何も表示されず、後続のdbt initが実行不可能でした...
DBの作成
Athenaでクエリを実行し、DBを作ります。事前にS3バケットも作成しておいてください。
CREATE DATABASE IF NOT EXISTS test_dbt
LOCATION 's3://test-dbt-gondo/data/';
プロジェクトの作成
dbt initコマンドで作ります。引数にはプロジェクト名を指定します。
% dbt init test_project
続いていくつか入力の必要があります。
- adapterの選択: athenaの番号を選択
-
s3_staging_dir: Athenaのクエリ結果を保存するS3のバケット・フォルダ名を入力 -
region_name: AWSリージョン名を入力 -
schema: Athenaで作成したDB名を入力 -
database:awsdatacatalogを入力
入力後、~/.dbt/profiles.ymlが作られます。このファイルは初回のdbt init時に作成され、指定したプロジェクト名ごと (今回だとtest_project) に設定が管理されます。
test_project:
outputs:
dev:
database: awsdatacatalog
region_name: ap-northeast-1
s3_staging_dir: s3://test-dbt-gondo/result/
schema: dbt
type: athena
target: dev
上記に加えて、以下の項目も追加します。
-
aws_profile_name: AWS Profile名を指定 -
work_group: Athenaのワークグループ名を指定
今回利用するProfileにはフル権限を持たせていますが、実際の運用では必要なアクセス権限に絞ってください。AthenaとS3の権限があれば問題なく動作すると思われます。
ワークグループは任意ですが、結構な数のAthenaクエリが実行されるのでprimaryグループと分けておいたほうが良いでしょう。
その他の設定については、githubのREADMEをご確認ください。
test_project:
outputs:
dev:
database: awsdatacatalog
region_name: ap-northeast-1
s3_staging_dir: s3://test-dbt-gondo/result/
schema: dbt
type: athena
aws_profile_name: test-profile
work_group: test-dbt target: dev
接続のテスト
dbt debugコマンドで確認します。最後にAll checks passed!と出力されればOKです。
% cd test_project
% dbt debug
17:09:26 Running with dbt=1.3.1dbt version: 1.3.1
python version: 3.10.8
python path: /Users/naoki.gondo/dbt-athena-1.3.3/.venv/bin/python
os info: macOS-11.6-x86_64-i386-64bit
Using profiles.yml file at /Users/naoki.gondo/.dbt/profiles.yml
Using dbt_project.yml file at /Users/naoki.gondo/dbt-athena-1.3.3/test_project/dbt_project.yml
Configuration:
profiles.yml file [OK found and valid]
dbt_project.yml file [OK found and valid]
Required dependencies:
- git [OK found]
Connection:
s3_staging_dir: s3://test-dbt-gondo/result/
work_group: test-dbt
region_name: ap-northeast-1
database: awsdatacatalog
schema: test_dbt
poll_interval: 1.0
aws_profile_name: test-profile
endpoint_url: None
s3_data_dir: None
s3_data_naming: schema_table_unique
Connection test: [OK connection ok]
All checks passed!
モデルの作成
test_projectフォルダの初期状態は以下のようになっています。サンプル用のモデルが作成されています。
% tree
.
├── README.md
├── analyses
├── dbt_project.yml
├── logs
│ └── dbt.log
├── macros
├── models
│ └── example
│ ├── my_first_dbt_model.sql
│ ├── my_second_dbt_model.sql
│ └── schema.yml
├── seeds
├── snapshots
└── tests
この状態でもdbt runコマンドは動くのですが、もう少し実際の運用に則った構成にしたいと思います。
(以降の作業では、不要となるmodels/example配下のファイルは一旦削除した上で話を進めます)
テスト用ログデータの準備
既にログが存在し、AthenaからSQLで参照可能、日付のpartitionごとにデータが分かれているようなケースを想定してみます。
以下のようなCSVを例があり、
user_id,session_id,event_time
1cee5be1-0a73-4260-93a4-3045dda713c3,433c2174-4836-4196-9351-4823ff3d8646,2022-12-12 00:00:58.586
711995dd-b99e-4cbd-8636-c9ace1ee1fe7,b591c712-de0c-48b3-a1b6-a02eb15241e7,2022-12-12 00:24:04.599
S3に以下のように配置します。
% aws s3 ls --recursive s3://test-dbt-gondo/logs/session/ | awk '{print $4}'
logs/session/
logs/session/date=2022-12-12/
logs/session/date=2022-12-12/sessions_20221212.csv
logs/session/date=2022-12-13/
logs/session/date=2022-12-13/sessions_20221213.csv
テーブルを作成します。
CREATE EXTERNAL TABLE IF NOT EXISTS `sampledb`.`sample_session` (
`user_id` string,
`session_id` string,
`event_time` timestamp
)
PARTITIONED BY (
`date` date
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LOCATION
's3://test-dbt-gondo/logs/session/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1',
'projection.date.format'='yyyy-MM-dd',
'projection.date.range'='2022-01-01,2022-12-31',
'projection.date.type'='date',
'projection.enabled'='true'
);
これで、AthenaのSQLで参照可能になりました。
Sourcesでの取り込み
既存のリソースを取り込む機能として、Sourcesがあります。
schema.ymlに以下のように記述します。
sources:
- name: sampledb
tables:
- name: sample_session
columns:
- name: user_id
description: user id
- name: session_id
description: session id
- name: event_time
description: event time
- name: date
description: date
このように設定しておくと、後述のモデル用SQLで利用可能になります。
Incrementalモデルの利用
DBTのモデルにはMaterializationsという概念があります。
実際にAthenaで実行されるSQLの挙動を確認した限りだと、以下のようになるみたいです。
-
viewを指定した場合、CREATE VIEWが実行される。仮想Viewでありデータの実体は持たない -
tableを指定した場合、CREATE TABLEが実行されデータの実体も持つ。dbt run実行ごとにDROP TABLEとデータの削除が行われ、再作成される -
incrementalを指定した場合、初回実行時はCREATE TABLEが実行されるが、2回目以降は増分のデータ更新が行われる
未指定時のデフォルトの挙動はdbt_project.ymlで設定可能です。今回はincrementalを利用してみます。
以下のようなSQLを作成します。
{{
config(
materialized='incremental',
partitioned_by=['date'],
external_location='s3://test-dbt-gondo/data/sessions/'
)
}}
select
count(distinct session_id) as session_count,
date
from {{ source('sampledb', 'sample_session') }}
{% if is_incremental() %}
where date = (
select
max(date) + interval '1' day
from {{ this }}
)
{% else %}
where date = date '2022-12-12'
{% endif %}
group by
date
ポイントをまとめると、
- table configurationにオプションを追加
-
partitioned_by: パーティションのカラム名を指定 -
external_location: データを出力するS3のフルパスを指定
-
- 定義したsourceを
{{ source('sampledb', 'sample_session') }}として利用 -
is_incrementalマクロを利用し、WHERE句の絞り込み条件を変化
となります。
追加した2つのtable configurationはdbt-athena特有のものです。詳細はgithubのREADMEをご覧ください。
is_incrementalマクロですが、ざっくり言えば「初回実行時はfalse、2回目以降の実行時はtrue」という真偽値判定となります。
マクロ中の{{ this }}は特殊な構文で、このSQLに対応するテーブル名がコンパイル時に埋め込まれます。
モデルの定義
作成したSQLに合わせて、schema.ymlにも定義を追加します。
今回は先にSQLを準備しましたが、yaml側の修正をを先にしても構いません。
models:
- name: sessions
columns:
- name: session_count
description: session count
- name: date
description: date
今回は割愛させていただきますが、モデルのテストの実行などが可能です。
初回実行
実際に動かしてみて、is_incrementalの挙動を見てみましょう。
dbt compileコマンドを実行します。
これはdryrun的なもので、実際にクエリの実行がされるわけではなく、新しくテーブルやデータが作られることはありません。開発時にはお世話になるコマンドでしょう。
ただし、内部的にはデータベースやテーブルのメタデータを取得するといったクエリは実行されるようです。
また、対応する
% dbt compile
ここでエラーが発生した場合は、モデルの記述内容に問題があるため見直して見てください。
compileが成功すると、以下のファイルが出力されます。
初回実行時はis_incremental()がfalseとなっていることがわかります。
select
count(distinct session_id) as session_count,
date
from sampledb.sample_session
where date = date '2022-12-12'
group by
date
確認ができたらdbt runを実行します。--modelオプションでモデルの指定が可能です。
% dbt run --model sessions
test_dbt.sessionsテーブルが作成されます。
2回目の実行
続けてdbt compileコマンドを実行すると、compileされたSQLが以下のようになります。
今度はis_incremental()がtrueとなっていることがわかります。
select
count(distinct session_id) as session_count,
date
from sampledb.sample_session
where date = (
select
max(date) + interval '1' day
from test_dbt.sessions
)
group by
date
再度dbt runコマンドを実行すると、データが追加されます。
増分更新実行時の内部処理を見てみると、以下の順にクエリが実行されているようです。
drop table if exists test_dbt.sessions__dbt_tmpcreate table test_dbt.sessions__dbt_tmp with (...) as select ...select distinct date from test_dbt.sessions__dbt_tmpinsert into test_dbt.sessions ... select ... from test_dbt.sessions__dbt_tmpdrop table if exists test_dbt.sessions__dbt_tmp
なるほどな、と理解できる内容でした。
気になった点としては、一度temporaryテーブルを経由してINSERTされるため、直接INSERTするクエリと比較してスキャンサイズがわずかに増えることになります。今回のようなテーブル構造ならば問題になりませんが、テーブル設計時は気をつけたいところです。
incrementalモデルの運用とvarの使い方
先ほどのSQLは、1日1回実行の運用を想定したものです。
公式ドキュメントの例を踏襲した場合、以下のようなクエリも考えられます。
-- (前略)
select
count(distinct session_id) as session_count,
date
from {{ source('sampledb', 'sample_session') }}
{% if is_incremental() %}
where date > select (max(date) from {{ this }})
{% endif %}
group by
date
これは初回実行時に全データを取り込み、2回目以降の実行でも1回の実行で増分データを全て取り込むことができます。
ただし以下のような欠点もあります。
- 全データをスキャンするため、スキャンサイズや実行時間が大きくなる
- else句を指定していないため、実行開始日の指定が不可能
- 例えば12/11の途中から
sampledb.sessionのデータが取り込まれ始めた場合、12/11のデータは不足しているため集計対象としたくない、というユースケースはあるだろう
- 例えば12/11の途中から
他に、varを指定するやり方も検討してみました。
この場合、dbt run --vars '{"target_date": "2022-12-12"}'というようにコマンド実行時に引数を与えるようなイメージです。
-- (前略)
select
count(distinct session_id) as session_count,
date '{{ var("target_date") }}' as date
from {{ source('sampledb', 'sample_session') }}
where date = date '{{ var("target_date") }}'
しかし、これは増分更新を行うわけではなく2回実行したら2回ともデータができてしまいます。
本来のIncrementalモデルの思想とも違うため、あまり推奨できないと感じました。
このあたりの設計はケースバイケースで、データ構造や実際の運用に合わせて微調整することになるでしょう。
実行結果
SELECT * FROM "test_dbt"."sessions"でデータを見てみると、2日分のデータが出力されていることがわかります。
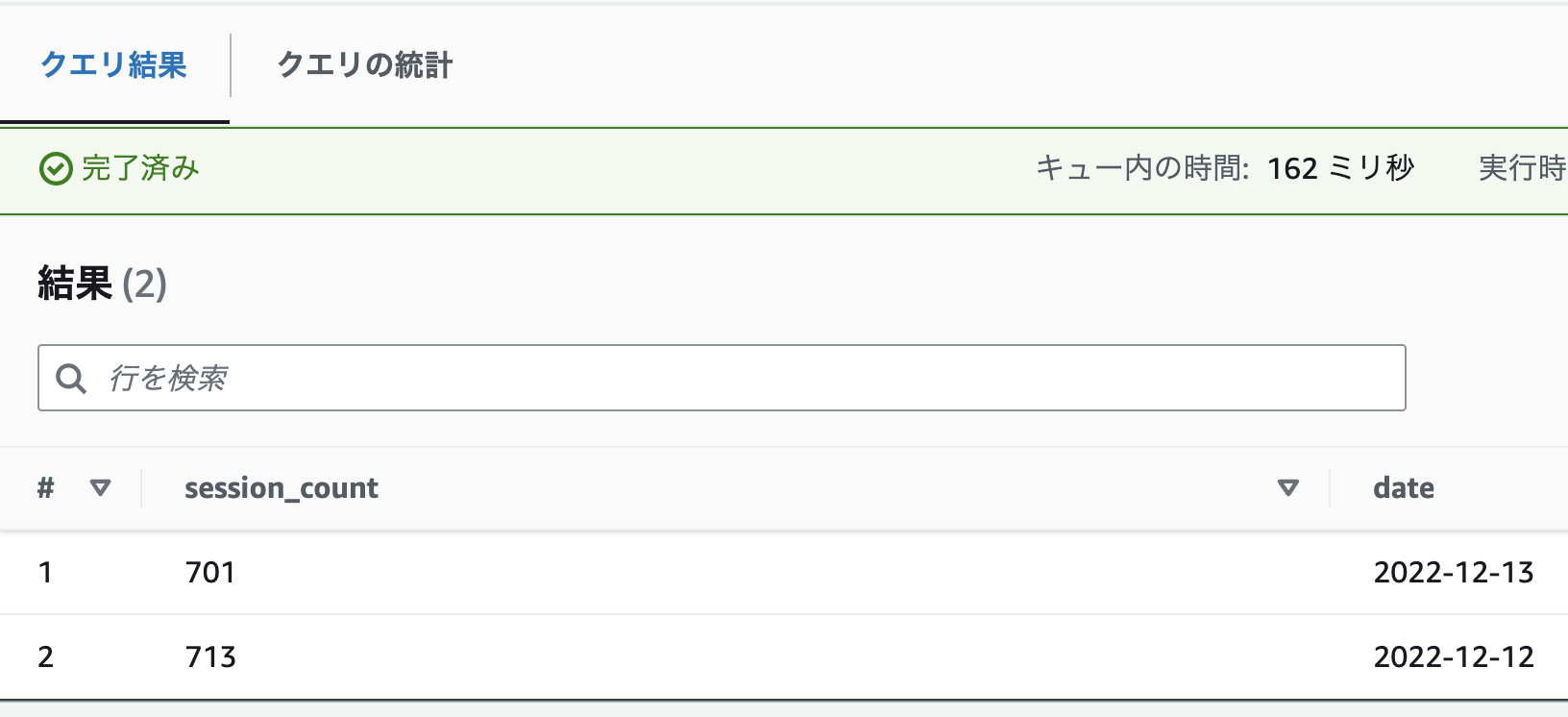
テーブル定義は以下のようになります (一部抜粋)。
CREATE EXTERNAL TABLE `sessions`(
`session_count` bigint)
PARTITIONED BY (
`date` date)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://test-dbt-gondo/data/sessions'
TBLPROPERTIES (
-- (長いので割愛)
)
データが格納されているS3の構造は以下のようになります。partitioned_byやexternal_locationの設定が適用されているのがわかります。
% aws s3 ls --recursive s3://test-dbt-gondo/data/sessions/ | awk '{print $4}'
data/sessions/date=2022-12-12/20221218_055338_00023_9eyvf_12f3141d-2a88-4ba8-9a3b-be6b3eba857c
data/sessions/date=2022-12-13/20221218_060614_00037_uqgea_cf8678c0-ac4d-4aaa-bdd6-d3324e98746b
ドキュメントの生成
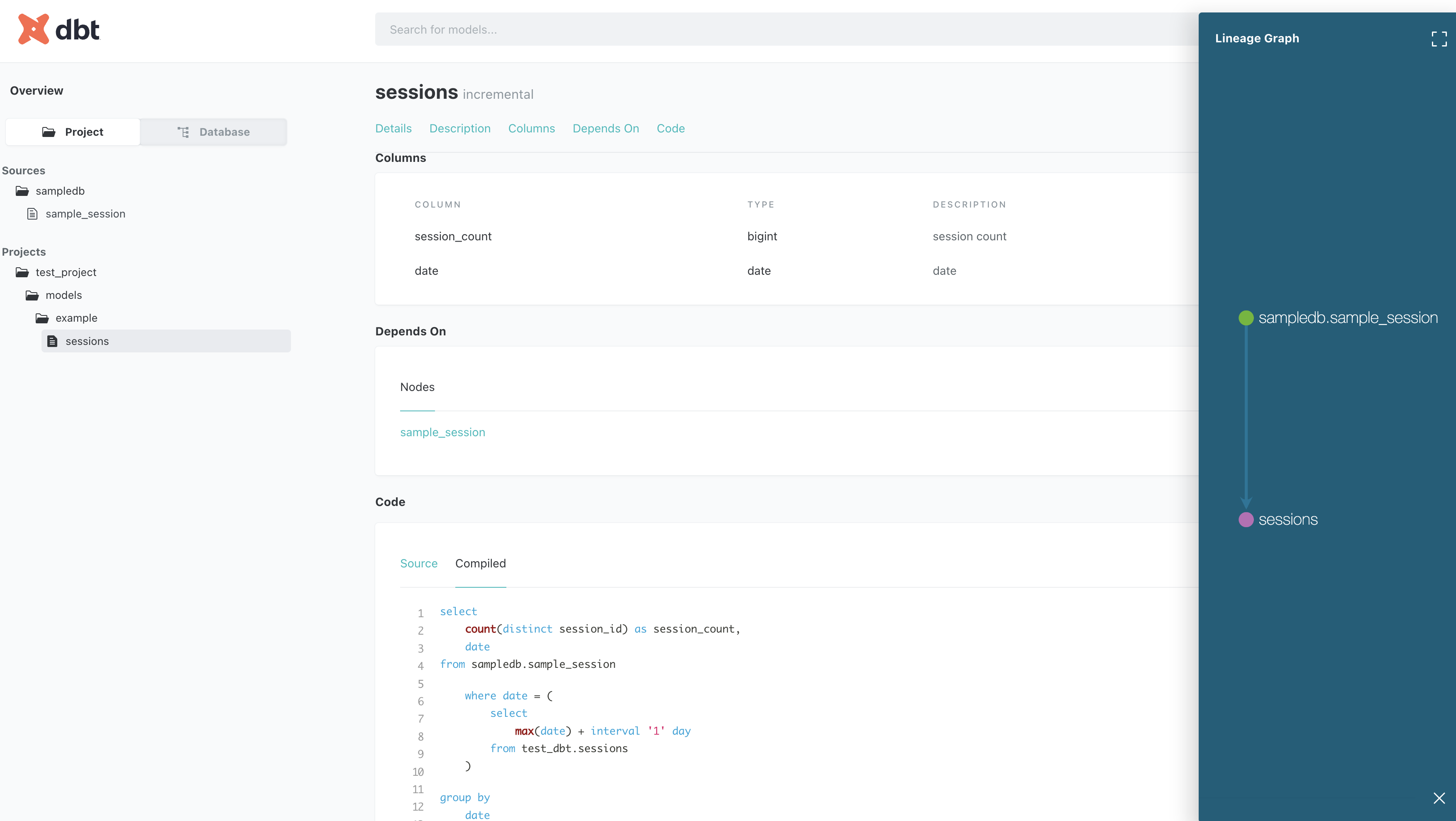
dbt docsコマンドで行います。
% dbt docs generate
% dbt docs serve --port 8001
local環境でブラウザが立ち上がります。
まとめ
実現したい機能はひと通りサポートされている印象を受けました。
筆者がdbt自体を触り始めたばかりで手探りな状態で検証を行いましたが、もう少し理解を深めればより良い構成にできると思いました。
参考記事
- dbt とは何をするツールなのか? | FLYWHEEL Tech ブログ
- データ変換処理をモダンな手法で開発できる「dbt」を使ってみた | DevelopersIO
- dbt Cloudとdbt-core (CLI)の違いを整理してみた | DevelopersIO
- dbtからAmazon Athenaにつないで使ってみる - Qiita
- [dbt] 「incremental」というMaterializationを使ってデータモデルを増分更新する | DevelopersIO
- [dbt] データウェアハウスにロードされているローデータを「sources」として定義する(と便利だよ) | DevelopersIO