この記事は、Arm Treasure Data advent calendar 23日目の記事です。前回の記事に引き続き、Hivemall v0.6.0で導入済みの特徴量エンジニアリングに焦点を当てて紹介していきます。
BigQueryMLでも最近、特徴量エンジニアリング機能が強化されているようですが、Hivemallでも多くの特徴量エンジニアリング機能を提供しています1ので、本記事ではそのいくつかを紹介していきます。特徴量の前処理や学習用のインプットデータの整備にSQLは強力2ですので、学習や予測処理は他のライブラリを使う場合でも前処理にHivemall/HiveQLを使っていただくのは便利かと思います。
Feature Pairing
特徴量の組合せを明示的に作成する機能です。
多項式展開用の関数
線形分類による分類境界ではうまく分類ができないようなケースは多々あります。詳しくはCourseraのAndrew Ng先生の講義ビデオなどを参照していただければと思いますが、多項式展開し高次空間に写像し、高次空間で線形分離することで低次空間での非線形の分類を実現することができます。
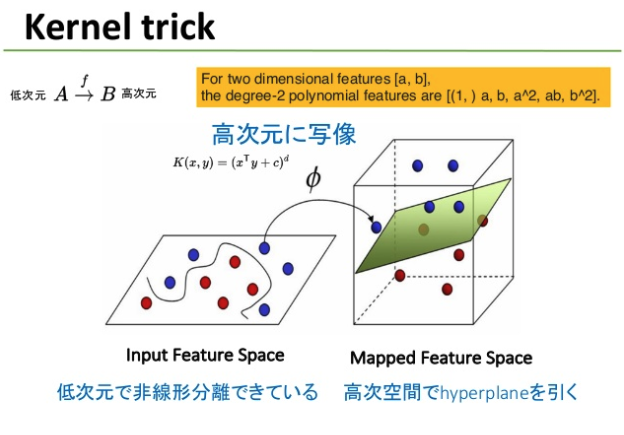
このような多項式展開をHivemallではpolynomial_feature(array<String> features, int degree [, boolean interactionOnly=false, boolean truncate=true])関数で実現可能です3。
-- 2次の多項式展開 (interactionOnly=false, truncate=false)
select polynomial_features(array("a:0.5","b:0.2"), 2);
> ["a:0.5","a^a:0.25","a^b:0.1","b:0.2","b^b:0.040000003"]
-- 2次の多項式展開 (interactionOnly=true, truncate=false)
-- (x^2などを省き、変数間のinteractiveがる場合xyのみ出力)
select polynomial_features(array("a:0.5","b:0.2"), 3, true);
> ["a:0.5","a^b:0.1","b:0.2"]
-- 3次の多項式展開 (interactionOnly=false, truncate=false)
select polynomial_features(array("a:0.5","b:1.0", "c:0.3"), 3, false, false);
> ["a:0.5","a^a:0.25","a^a^a:0.125","a^a^b:0.25","a^a^c:0.075","a^b:0.5","a^b^b:0.5","a^b^c:0.15","a^c:0.15","a^c^c:0.045","b:1.0","b^b:1.0","b^b^b:1.0","b^b^c:0.3","b^c:0.3","b^c^c:0.09","c:0.3","c^c:0.09","c^c^c:0.027000003"]
-- 3次の多項式展開 (interactionOnly=false, truncate=true)
-- truncate=trueを指定するとb:1.0と変わらないb^b:1.0など重みが1.0の意味をなさない冗長な組合せを除去
select polynomial_features(array("a:0.5","b:1.0","c:0.3"), 3);
> ["a:0.5","a^a:0.25","a^a^a:0.125","a^a^c:0.075","a^c:0.15","a^c^c:0.045","b:1.0","c:0.3","c^c:0.09","c^c^c:0.027000003"]
-- 3次の多項式展開 (interactionOnly=true, truncate=true)
-- interactionOnlyを指定するとa^2やb^2などpowered featureを出力せずに変数の組合せだけを出力
select polynomial_features(array("a:0.5","b:1.0","c:0.3"), 3, true, true);
> ["a:0.5","a^c:0.15","b:1.0","c:0.3"]
累乗用の関数
powered_features(array<String> features, int degree [, boolean truncate=true] ) is a function to generate polynomial features.は組合せではなく、累乗した変数を作成する関数です。
select powered_features(array("a:0.5","b:0.2"), 3);
> ["a:0.5","a^2:0.25","a^3:0.125","b:0.2","b^2:0.040000003","b^3:0.008"]
Feature Binning
Feature binningは量的変数を質的変数に変換するテクニックです4。
まず、分位数に基づいて年齢を3つのビンに分割してみましょう。
SELECT
map('age', build_bins(age, 3)) AS quantiles_map
FROM
users
> {"age":[-Infinity,18.333333333333332,30.666666666666657,Infinity]}
ここでは、build_bin関数を利用することで次のような区間の3つのビンが作られました。
1: [-Infinity,18.333333333333332]
2: (18.333333333333332,30.666666666666657]
3: (30.666666666666657,Infinity]
feature_binning 関数はこのbinを利用して量的変数であるageを質的変数に変換します。
WITH bins AS (
SELECT
map('age', build_bins(age, 3)) AS quantiles
FROM
users
)
SELECT
feature_binning(features, quantiles) AS features
FROM
input
CROSS JOIN bins;
| features: arrayfeatures::string |
|---|
| ["name#Jacob","gender#Male","age:1"] |
| ["name#Mason","gender#Male","age:1"] |
| ["name#Sophia","gender#Female","age:2"] |
| ["name#Ethan","gender#Male","age:2"] |
| ... |
上記の例では、分位数を用いた変換ルールを用いましたが、次のように明示的に変換ルールを与えることも可能です5。
select
features as original,
feature_binning(
features,
-- [-INF-10.0], (10.0-20.0], (20.0-30.0], (30.0-40.0], (40.0-INF]
map('age', array(-infinity(), 10.0, 20.0, 30.0, 40.0, infinity()))
) as binned
from
input;
| original | binned |
|---|---|
| ["name#Jacob","gender#Male","age:20.0"] | ["name#Jacob","gender#Male","age:1"] |
| ["name#Mason","gender#Male","age:22.0"] | ["name#Mason","gender#Male","age:2"] |
| ["name#Sophia","gender#Female","age:35.0"] | ["name#Sophia","gender#Female","age:3"] |
| ["name#Ethan","gender#Male","age:55.0"] | ["name#Ethan","gender#Male","age:4"] |
| ["name#Emma","gender#Female","age:15.0"] | ["name#Emma","gender#Female","age:1"] |
| ... | ... |
Feature Scaling
特徴量のスケールの変換(Feature Scaling)は、線形学習器やニューラルネットへの入力データの用意に不可欠処理です。
Hivemallでは、min-max normalizationおよびzscoreを利用したnormalizationをサポートしております6。
以下は応答変数のスケールを変換する例です。
select
rescale(target, min(target) over (), max(target) over ()) as target,
zscore(target, avg(target) over (), stddev_pop(target) over ()) as target
from
train
より複雑な特徴ベクトルの変換はこのドキュメントを参照ください。
地理情報の変数化
Tile番号
緯度経度情報を特徴量として利用したい時のために、地理メッシュ上でのタイル番号を返す処理をサポートしております。
WITH data as (
select 51.51202 as lat, 0.02435 as lon, 17 as zoom
union all
select 51.51202 as lat, 0.02435 as lon, 4 as zoom
union all
select null as lat, 0.02435 as lon, 17 as zoom
)
select
lat, lon, zoom,
tile(lat, lon, zoom) as tile
from
data;
タイルの意味やズームレベル(タイルの粒度)についてはリンク先を参照ください。
距離の算出
ユーザの店舗やランドマークからの距離などを求め、それを特徴量として利用したい場合は距離を求めるhaversine_distance関数が便利です。
以下の例は東京-大阪間の距離をkmおよびmileで求める例です。
-- Tokyo (lat: 35.6833, lon: 139.7667)
-- Osaka (lat: 34.6603, lon: 135.5232)
select
haversine_distance(35.6833, 139.7667, 34.6603, 135.5232) as km,
haversine_distance(35.6833, 139.7667, 34.6603, 135.5232, true) as mile;
| km | mile |
|---|---|
| 402.09212137829684 | 249.8484608500711 |
Feature Hashing
Feature Hashingは、非数値の特徴を数値インデックスに変換するときに利用されます。
Hivemallでは、特徴ベクトルに対してfeature hashingを適用するfeature_hashing関数と特徴単体に対してMurmur Hashing 3を適用するmhash関数を用意しています。利用方法は次のとおり。
select feature_hashing(array("userid#4505:3.3","movieid#2331:4.999", "movieid#2331"));
["1828616:3.3","6238429:4.999","6238429"]
select feature_hashing();
usage: feature_hashing(array<string> features [, const string options]) -
returns a hashed feature vector in array<string> [-features <arg>]
[-libsvm]
-features,--num_features <arg> The number of features [default:
16777217 (2^24)]
-libsvm Returns in libsvm format
(<index>:<value>)* sorted by index
ascending order
select mhash('aaa');
4063537
Hivemallのドキュメントにはより多くのfeature hashingの適用例を記載しております。
Term Vector Model
Term Vector Model7は、文書などの自然言語表現のテキストをベクトルとして表すためのモデリング手法です。
ユーザのレビュー内容や訪問ページ(のテキスト)などからユーザの特徴量をつけたり、商品の紹介文から商品の特徴量をつけたりする場合に利用されます。
N-gram
英語のようにスペース区切りの言語では、出現単語の組合せから特徴表現を作るためにngram等が利用されます。
ngramは、文字列を連続したn個の文字で分割するテキスト分割方法で、nが1の場合をユニグラム(uni-gram),2の場合をバイグラム(bi-gram)、3の場合をトライグラム(tri-gram)と呼びます。
HiveやBigQueryでもngramがサポートされまいます。
BigQuery MLのngramと異なり、Hiveの場合は出現頻度の返す関係で集約関数(UDAF)として実装されています。
WITH docs as (
select 'I live in Tokyo. You live in Osaka.' as contents
),
ngrams as (
-- bi-gramで上位3件の出現単語をするクエリ
-- ngramは集約関数であることに注意
SELECT ngrams(split(contents, ' '), 2, 3) as ngram
from docs
)
select
ngram.ngram,
ngram.estfrequency,
ngram.ngram[0],
ngram.estfrequency[0]
from
ngrams;
> [["live","in"],["I","live"],["Tokyo.","You"]] [2.0,1.0,1.0] ["live","in"] 2.0
集約関数だと後処理が必要で面倒ということも考えられますので、Hivemallではword_ngram関数を用意しています。
desc function word_ngrams;
> word_ngrams(array<string> words, int minSize, int maxSize]) - Returns list of n-grams for given words, where `minSize <= n <= maxSize`
SELECT word_ngrams(tokenize('Machine learning is fun!', true), 1, 2);
["machine","machine learning","learning","learning is","is","is fun","fun"]
この単数では近接単語の組合せの下限(minSize)と上限(maxSize)を指定します。uni-gramまたはbi-gramを返したい場合は上記のようになります。逆に、bi-gramだけ欲しい時には次のようにします。
SELECT word_ngrams(tokenize('Machine learning is fun!', true), 2, 2);
> ["machine learning","learning is","is fun"]
Hivemallでは、kuromojiを利用した形態素解析もサポートしています。日本語の解析をする場合はtokenize_jaを利用ください。
TF-IDFとBM25
TF-IDFおよびBM258を利用したTerm-vector Modelingとして広く利用されており、トレジャーデータのお客様でもHivemallを利用して類似ニュース記事等を算出している事例があります。
具体例はドキュメントにありますが、HivemallでTF-IDFまたはBM25を利用するときは、次のようなクエリ(少々長いですが定型です)を実行します。
WITH wikipage_exploded as (
select
docid,
word
from
wikipage LATERAL VIEW explode(tokenize(page,true)) t as word
where
not is_stopword(word)
),
term_frequency as (
select
t1.docid,
t2.word, t2.freq
from (
select
docid,
tf(word) as word2freq
from
wikipage_exploded
group by
docid
) t1
LATERAL VIEW explode(word2freq) t2 as word, freq
),
document_frequency as (
select
word,
count(distinct docid) docs
from
wikipage_exploded
group by
word
),
doc_len as (
select
docid,
count(1) as dl,
avg(count(1)) over () as avgdl,
count(distinct docid) over () as total_docs
from
wikipage_exploded
group by
docid
)
select
tf.docid,
tf.word,
tfidf(tf.freq, df.docs, dl.total_docs) as tfidf,
bm25(tf.freq, dl.dl, dl.avgdl, dl.total_docs, df.docs
-- , '-k1 1.5 -b 0.75'
) as bm25
from
term_frequency tf
JOIN document_frequency df ON (tf.word = df.word)
JOIN doc_len dl ON (tf.docid = dl.docid)
特徴ベクトルの生成までをここにDigdagワークフローとしてまとめてあります。
実際の運用ではワークフロー化してご利用頂くのが良いかと思います9。
まとめ
本記事では説明しきれませんでしたが、Hivemallにはこの他にもOne-hot encoding用の関数や応答変数のバイナリ化用の関数など機械学習の前処理に便利な関数や各種評価用の関数を用意しておりますので、(他の機械学習ライブラリを利用しても)データ前処理にお困りの皆様もぜひ一度ご利用いただければと思います。
-
http://hivemall.apache.org/userguide/ft_engineering/ft_trans.html ↩
-
プロダクション用の操作をPandas/Dataframeで前処理を頑張るのはスケーラビリティやメモリスペース面でも大変かと思います。 ↩
-
BigQueryのfeature_cross関数に相当しますが、polynomial_featuresには2次以外の展開や組合せ(xy)以外の高次展開(x^2)を省く機能もあります。詳細はこのページを参照ください。 ↩
-
BigQueryでいうquantile_bucketizeに相当します。 ↩
-
BigQueryでもmin-maxとzscoreを用いたスケーリングがサポートされています。 ↩
-
Vector Space Model(ベクトル空間モデル)とも呼ばれます。 ↩
-
Lucene/SolrではTF-IDFに変わってBM25が標準の単語重みづけに採用されております。TF-IDFとBM25の比較については他の記事を参照ください。 ↩
-
なお、こういう話もあるのでご利用にはお気をつけください。tfidfは分類精度を向上させるのか?→向上しなかった ↩