本稿は個人の見解および確認によるもので、所属する団体等とは関係がありません。
はじめに
MuleSoftが提供するAnypoint Platformは、APIを実装・運用するためのプラットフォームですが、スケジューラーによる定時実行や、指定のディレクトリに対してファイルの存在チェックを行うといったコンポーネントも用意されており、バッチ処理も可能となっています。
バッチ処理については、一般的にデータ量が大きいため、事前にファイルを分割して処理する方法や、データをストリーミングで流しこんで、後続のプロセッサで処理する方法が考えられます。
しかしながら、いづれの場合にせよ、できるだけパフォーマンスをあげるためにはディスクI/Oを引き起こす中間ファイルの抑制をすることが求められます。
本稿では、ストリーミングに焦点をあて、次章以降で説明する関連オプション(DataWeaveのstreaming, deferred)が中間ファイルの生成にどのように影響するか検証を行います。
今回参考にした資料は以下となります。
MuleSoft チュートリアル
https://jp.mulesoft-labs.dev
手っ取り早く MuleSoft 識者となるためのおすすめ学習コンテンツ
https://qiita.com/hairyhg99/items/925cf50b61d8a32d43db
オンラインマニュアル
https://docs.mulesoft.com/jp/mule-runtime/4.4/streaming-strategies-reference
https://docs.mulesoft.com/jp/dataweave/2.4/dataweave-streaming
それでは、はじめに検証で使用したフローの説明から行います。
使用フロー
使用するフローは以下のように、HTTP::ListenerからJSONにてファイルのパスを与え、そのパスをFile::Readで読み出したのち、処理、そして書き出しを行う単純なものとします。
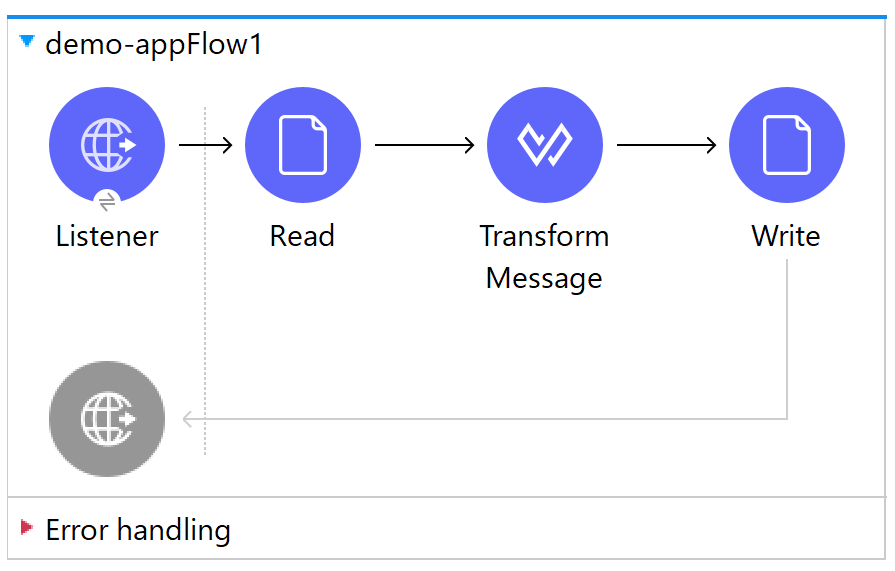
XMLファイル
<?xml version="1.0" encoding="UTF-8"?>
<mule xmlns:db="http://www.mulesoft.org/schema/mule/db" xmlns:file="http://www.mulesoft.org/schema/mule/file"
xmlns:aggregators="http://www.mulesoft.org/schema/mule/aggregators"
xmlns:ee="http://www.mulesoft.org/schema/mule/ee/core" xmlns:jpcharactersconverter="http://www.mulesoft.org/schema/mule/jpcharactersconverter" xmlns:http="http://www.mulesoft.org/schema/mule/http" xmlns="http://www.mulesoft.org/schema/mule/core" xmlns:doc="http://www.mulesoft.org/schema/mule/documentation" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.mulesoft.org/schema/mule/core http://www.mulesoft.org/schema/mule/core/current/mule.xsd
http://www.mulesoft.org/schema/mule/http http://www.mulesoft.org/schema/mule/http/current/mule-http.xsd
http://www.mulesoft.org/schema/mule/jpcharactersconverter http://www.mulesoft.org/schema/mule/jpcharactersconverter/current/mule-jpcharactersconverter.xsd
http://www.mulesoft.org/schema/mule/ee/core http://www.mulesoft.org/schema/mule/ee/core/current/mule-ee.xsd
http://www.mulesoft.org/schema/mule/aggregators http://www.mulesoft.org/schema/mule/aggregators/current/mule-aggregators.xsd
http://www.mulesoft.org/schema/mule/file http://www.mulesoft.org/schema/mule/file/current/mule-file.xsd
http://www.mulesoft.org/schema/mule/db http://www.mulesoft.org/schema/mule/db/current/mule-db.xsd">
<http:listener-config name="HTTP_Listener_config" doc:name="HTTP Listener config" doc:id="13954594-2579-47fd-9d9a-b692326bc335" >
<http:listener-connection host="0.0.0.0" port="8081" />
</http:listener-config>
<flow name="demo-appFlow1" doc:id="42d1f3b4-c6fd-4741-9b27-92a1a7deb84a" >
<http:listener doc:name="Listener" doc:id="9a39b578-4382-457a-a5be-ac99b286e2e2" config-ref="HTTP_Listener_config" path="/"/>
<file:read doc:name="Read" doc:id="9a39fa5e-0b68-48f1-972f-3c886c4b78f4" path="#[payload.path]" outputMimeType="application/csv; streaming=true">
<non-repeatable-stream />
</file:read>
<ee:transform doc:name="Transform Message" doc:id="94a602c6-dc13-4f08-a3f5-d7504e51cd6f" >
<ee:message >
<ee:set-payload ><![CDATA[%dw 2.0
output application/csv deferred=true
---
payload]]></ee:set-payload>
</ee:message>
</ee:transform>
<file:write doc:name="Write" doc:id="b84d1bc4-3fce-4387-b576-e2cad816809b" path="/tmp/result.csv"/>
</flow>
</mule>
次に、関連オプションの説明を行っていきます。
ストリーミング関連オプション
MuleSoftのマニュアルによると、データをストリーミングで処理する場合には、以下のようなオプションが存在します。

Mule Runtimeに関するものと、DataWeave処理系に関する2種類があることを認識しておきます。
Mule Runtime関連オプション
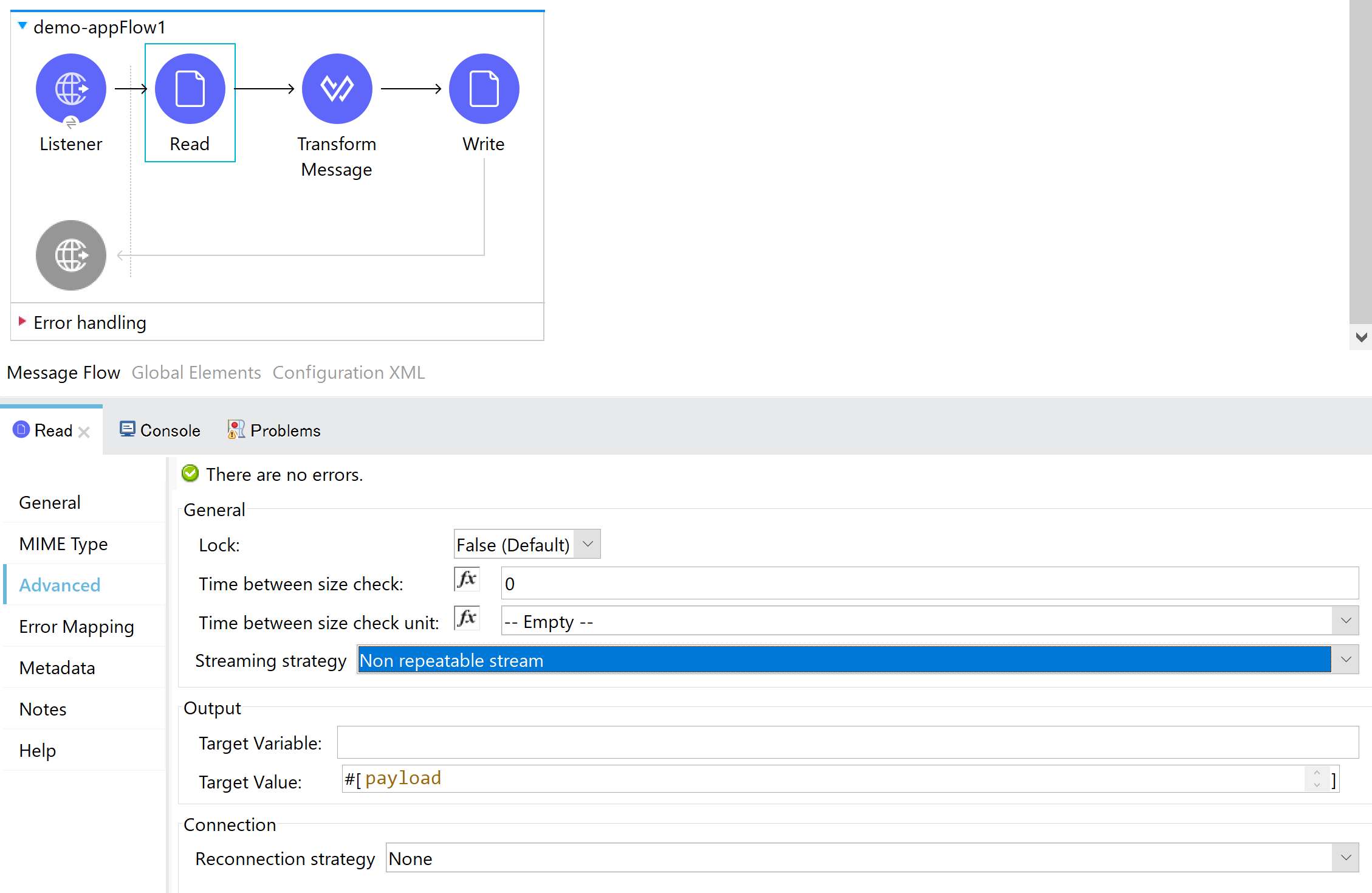
上図オプションの1つ目のStreaming Strategy(Data)は、HTTP ListnerのソースコンポーネントやFile::ReadのAdvancedタブで設定ができるようになっており、ストリーミング処理での処理タイプが選択できるようになっています。
JavaのInputStreamを扱った人はピンとくるかと思いますが、基本的にStreamと呼ばれるものは一度そのなかからデータを読み出したら消失してしまうので、繰り返しデータを読み出したいといった場合には、ディスクに保存しておくといった手段が必要となります。このオプションでは、保存しておくかどうか、するとしたらメモリなのかファイルなのかという選択が行えるようになっています。
デフォルトではRepeatable file store streamとなっていて、Streamの内容をファイルとして保存しておくことにより、何度でも読み出すことができるようになっています。
他のオプションとしては、1度読み出せるNon-Repeatable、メモリ内に保持して何度でも読み出せるRepeatable in memory store streamというオプションが用意されています。
上記テーブル内の2行目に記載のObjectに対するStreaming Strategyは、取得したオブジェクト単位での処理タイプで、RDBやSalesforceでSelectをおこなった結果をどのタイプでストリーミングするかを選択できます。こちらはデータサイズではなくオブジェクトの個数での指定が可能となっています。
Objectに対するStreaming Strategyを設定した場合(DB ConnectorのSelectなど)、XMLファイルをみると、repeatable-file-store-iterableとなっていて、末尾がstreamでなく iterableとなっていることに注意。
尚、本稿では、ファイルからCSVを読み込んで処理を行う形とするため、File::ReadのStream Strategy OptionをNon-Repeatableとして検証を行い、オブジェクトストリームは使用しません。
DataWeave関連オプション
DataWeaveと関連があるオプションとしては、streamingと、deferredというものが存在します。
- streaming = true|false
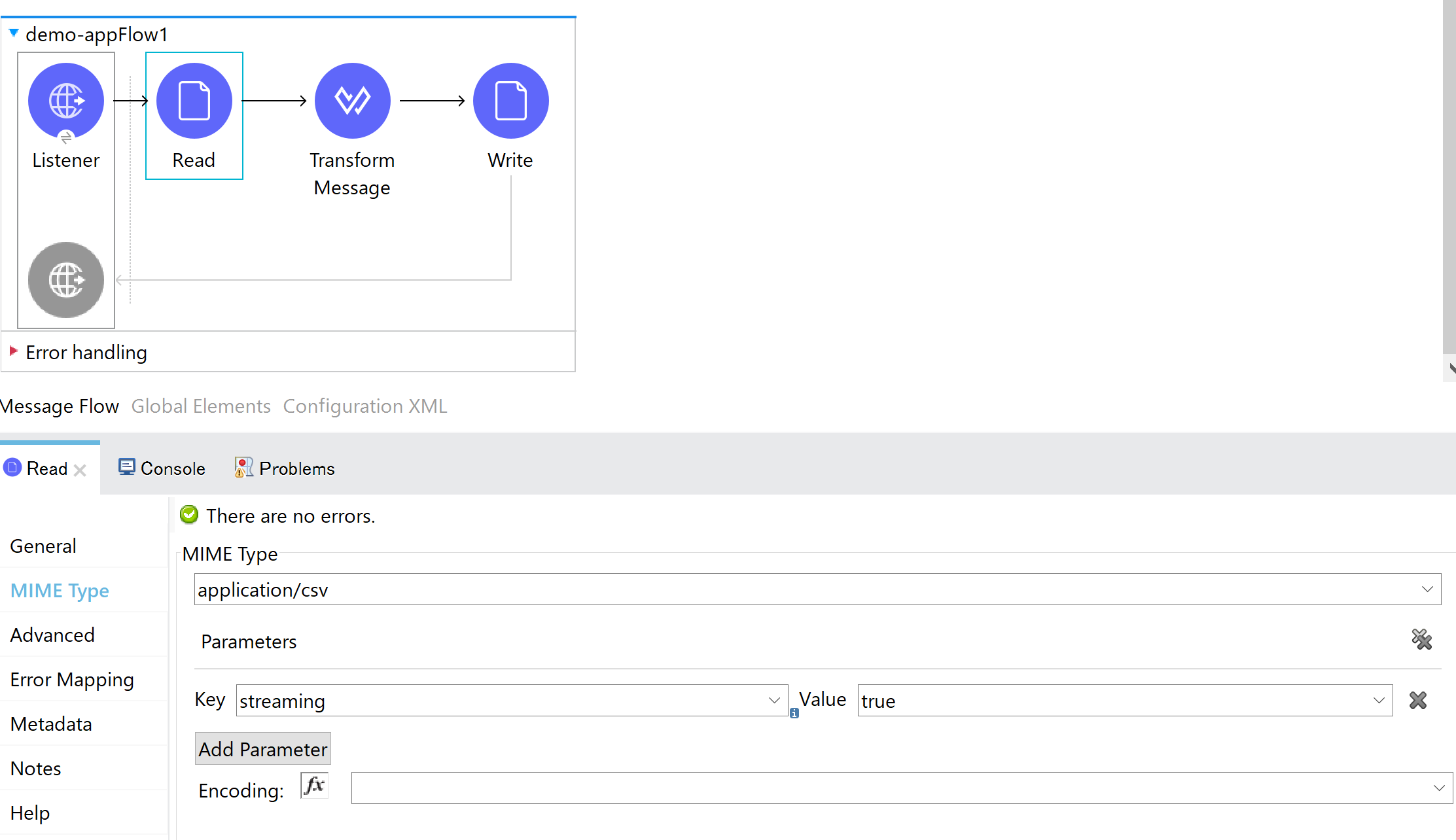
streamingオプションは、DataWeaveを記述するプロセッサ(Transformなど)の1つ前のプロセッサのOutput MIMEに付与します。
例えば、以下の図ようにファイルを読み込み、DataWeaveによる変換、書き出しといった処理の場合、DataWeaveを記述しているTransformの1つ前のFile::ReadプロセッサのOutput MIMEへ付与します。
このオプションは、DataWeave処理系が未処理データをファイルとして書き出すかどうかの判断に使用されます。
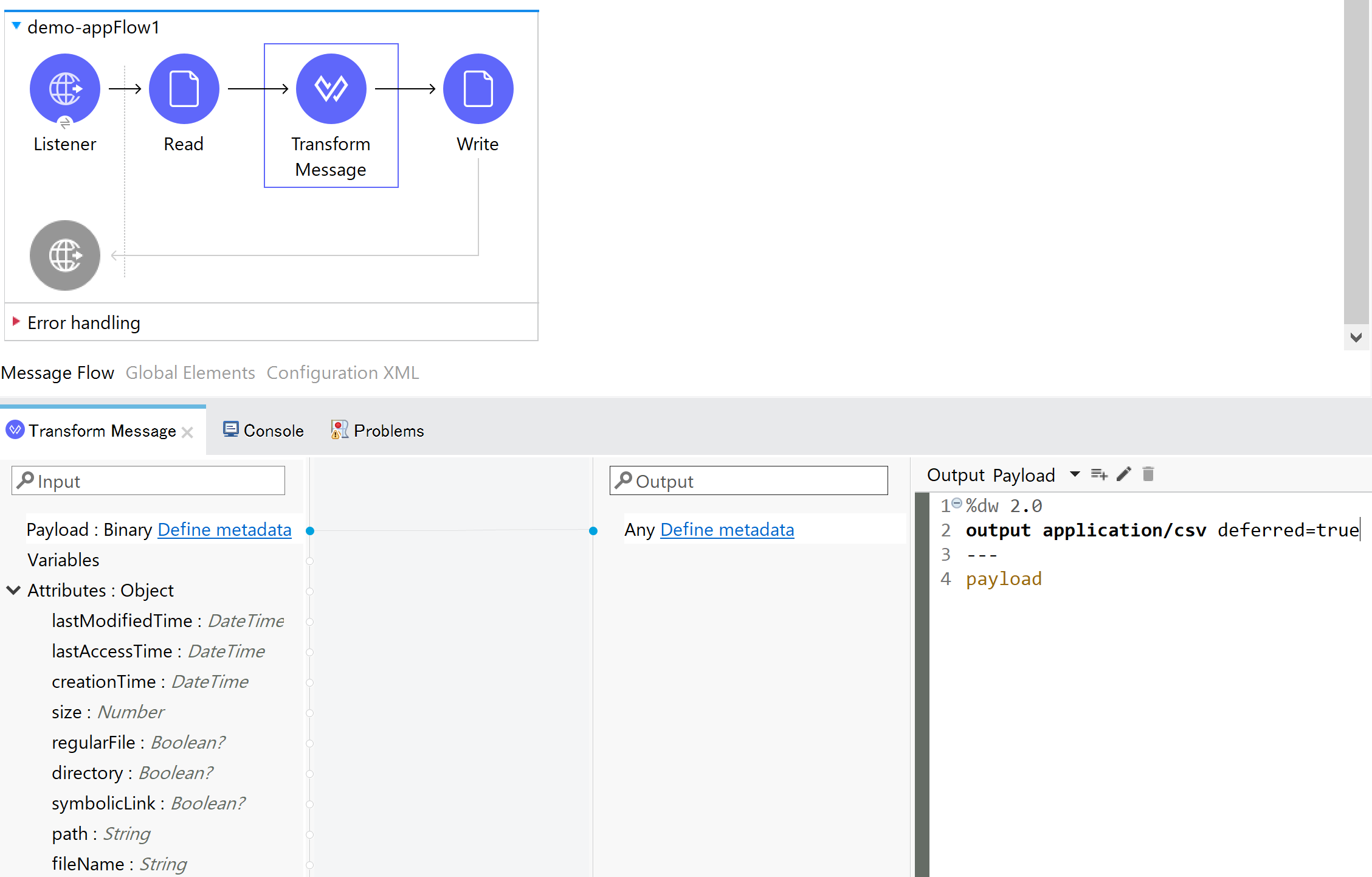
- deferred = true|false
deferredオプションは、DataWeaveのヘッダ部分に記載するOutput MIMEに付与します。デフォルトはfalseとなっています。このオプションは、DataWeave処理系が処理済のデータをファイルとして保存するかどうかの判断に使用されます。
実際は、出力が必要な時までDataWeaveの実行を遅延させて中間ファイルをつくらないということを行っており、遅延処理を行っています。
中間ファイル
DataWeave メモリ管理のページを確認すると、DataWeaveは以下3種類の中間ファイルを条件に応じて生成する記載があります。
dw-buffer-output-${count}.tmp
変換の結果がしきい値の 1572864 バイトよりも大きい場合に、変換の出力を保存するために使用されます。
dw-buffer-input-${count}.tmp
変換の入力がメモリ内のバッファ (デフォルトでは 1572864 バイト) よりも大きい場合に、変換の入力を保存するために使用されます。 これは dw-buffer-output-${count}.tmp ファイルと似ていますが、入力データ用です。
dw-buffer-index-${count}.tmp
読み取られている値のインデックス情報を保存するために使用されます。このファイルは、DataWeave がデータにすばやくアクセスするのに役立ちます。
outputおよびinputについては、バッファよりも大きい場合に作成されるとありますが、streamingやdeferredオプションとの関係性についての記述がなく、indexについても、DataWeave のインデックス付きリーダーというページに記載はありますが、明確な関係性の記載がありません。
そこで、次の章で、実際にそれらの関連オプションをつかって検証を行っていきます。
検証
File::ReadのStreaming StrategyはNon-repeatableにしておいて、残り2つのstreamingおよびdeferredオプションのtrue/falseの組み合わせによる挙動を検証します。
DataWeaveでのストリーミングというページを確認すると、DataWeaveでストリーミングとして扱える基本単位は以下となっています。
今回はCSVで実施しています。
| データ形式 | 単位 |
|---|---|
| CSV | レコード |
| JSON | 配列要素 |
| XML | コレクション単位 |
オブジェクト単位でのストリーミングという印象を受けますが、あくまでもDataWeave処理系に上がってきた後の話なので、File::ReadからDataWeave処理系へ渡されるまではバイナリストリームで流れてきます。
それでは、前章で記載した簡単なフローに、サイズの大きいファイルで処理を実施します。
以下のような形で、扱うファイルのパスをPOSTします。(例では7GBのファイルとしています)
POST http://localhost:8081
Content-Type: application/json
{"path": "test-7G.csv"}
以下がそれぞれのオプションを有効化した場合の結果となります。
| 処理中に作成されたファイル | streaming = false deferred = false |
streaming = true deferred = false |
streaming = fa;se deferred = true |
streaming = true deferred = true |
|---|---|---|---|---|
| dw-buffer-input | 出現 | 出現 | ||
| dw-buffer-output | 出現 | 出現 | ||
| dw-buffer-index | 出現 | 出現 |
上記結果から以下が導かれます。
- inputおよびindexは、DataWeaveスクリプトの1つ前のOutput MIMEへstreaming=trueを付与することで抑制が可能
- outputは、DataWeaveスクリプトのOutput MIMEへdeferred=trueを付与することで抑制が可能
尚、追加情報として、中間ファイルのサイズについては、inputは元のファイルサイズと同等程度のサイズが生成され、indexはその1.5倍~ほどのサイズとなっており、可能な限り抑制を行うよう実装することが望まれます。
以下、参考までに、処理中に/tmpをlsした結果となります。result.csvはFile::Writeによる最終的な書き出しファイルです。
streaming=false, deferred=false
/tmp$ ls -l dw* result.csv
ls: cannot access 'result.csv': No such file or directory
-rw-r--r-- 1 myst myst 5094698720 May 18 20:29 dw-buffer-index-11.tmp
-rw-r--r-- 1 myst myst 34603008 May 18 20:29 dw-buffer-index-13.tmp
-rw-r--r-- 1 myst myst 3386376192 May 18 20:29 dw-buffer-input-10.tmp
-rw-r--r-- 1 myst myst 3307798255 May 18 20:29 dw-buffer-output-12.tmp
デフォルトの状態だと全員集合状態で中間ファイルができていることがわかります。
streaming=true, deferred=false
/tmp$ ls -l dw* result.csv
ls: cannot access 'result.csv': No such file or directory
-rw-r--r-- 1 myst myst 3248820566 May 18 20:41 dw-buffer-output-17.tmp
streaming=trueにより、input, indexができていません。注意が必要なのは、途中の状態ではまだ最終ファイルができていない点です。これは、deferred=falseのため、一旦outputへ出力されてから最終ファイルへ出力されるためです。
streaming=false, deferred=true
/tmp$ ls -l dw* result.csv
-rw-r--r-- 1 myst myst 9772529744 May 18 20:38 dw-buffer-index-15.tmp
-rw-r--r-- 1 myst myst 67633152 May 18 20:38 dw-buffer-index-16.tmp
-rw-r--r-- 1 myst myst 6494355456 May 18 20:38 dw-buffer-input-14.tmp
-rw-r--r-- 1 myst myst 6344949760 May 18 20:38 result.csv
outputはなくなって、最終ファイルへ直接ストリーミングがされています。
streaming=true, deferred=true
/tmp$ ls -l dw* result.csv
ls: cannot access 'dw*': No such file or directory
-rw-r--r-- 1 myst myst 288890880 May 19 09:28 result.csv
中間ファイルは作成されず、直接最終ファイルへ出力されています。
まとめ
本稿では、ストリーミングに関連した2つのオプションにおいて、中間ファイルの生成がどのように変化するか検証を行いました。
次稿では、Transformプロセッサを複数並べた場合や、他のコンポーネントを使用した場合などの検証を行っていきます。