Pythonでスクレイピングなどする際、BeautifulSoupを用いてHTMLをパースすることがよくあると思います。表をパースする場合はTableタグのパースをすれば良いので同様に対処できます。
しかし以下のようなcolspanやrowspanが設定されている表の場合には工夫が必要になります。

sample.html
<!DOCTYPE html>
<html lang="ja">
<body id="top">
<table class="teiden-table">
<colgroup>
<col class="col-datetime">
<col class="col-pref-name">
<col class="col-city-name">
<col class="col-addr-name">
<col class="col-cause">
<col class="col-status">
<col class="col-count-of-occurrence">
</colgroup>
<thead>
<tr>
<th rowspan="2">
<div>発生日時</div>
</th>
<th colspan="3">停電地域</th>
<th rowspan="2">停電理由</th>
<th rowspan="2">対応状況</th>
<th rowspan="2">
<div>現在の停電戸数<br>(発生時の停電戸数)</div>
</th>
</tr>
<tr>
<th>県</th>
<th>市町村名</th>
<th>地域名</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="2" class="data-datetime">
<div>20xx年xx月xx日 xx時xx分</div>
</td>
<td rowspan="2" class="data-pref-name">徳島県</td>
<td class="data-city-name">鳴門市</td>
<td class="data-addr-name">
<ul class="addr-name-list">
<li>大津町 徳長</li>
<li>大津町 矢倉</li>
</ul>
</td>
<td rowspan="2" class="data-cause">調査中</td>
<td rowspan="2" class="data-status">現在、停電地域において故障箇所と原因を特定中です。</td>
<td rowspan="2" class="data-count-of-occurrence">約300戸<br>(約900戸)</td>
</tr>
<tr>
<td class="data-city-name">板野郡 松茂町</td>
<td class="data-addr-name">
<ul class="addr-name-list">
<li>中喜来</li>
</ul>
</td>
</tr>
</tbody>
</table>
</body>
rowspanを考慮しないパース
from bs4 import BeautifulSoup
with open("sample.html") as f:
data = f.read()
soup = BeautifulSoup(data)
table = soup.find("table")
trs = table.select("tbody > tr")
[[td.text for td in tr.find_all("td")] for tr in trs]
output
[['\n20xx年xx月xx日 xx時xx分\n',
'徳島県',
'鳴門市',
'\n\n大津町\u3000徳長\n大津町\u3000矢倉\n\n',
'調査中',
'現在、停電地域において故障箇所と原因を特定中です。',
'約300戸(約900戸)'],
['板野郡\u3000松茂町', '\n\n中喜来\n\n']]
これだと、板野郡松茂町の都道府県名や停電戸数などが取得できていません。rowspanが設定されていることにより、値が省略されてしまっているためです。
Pandasを用いたパース方法
Pandasがインストール済みの場合は、read_htmlを用いるのが手軽で便利です。rowspanやcolspanを考慮してよしなにパースしてくれます。
import pandas as pd
from bs4 import BeautifulSoup
with open("sample.html") as f:
data = f.read()
soup = BeautifulSoup(data)
table = soup.find("table")
pd.read_html(str(table))[0]
output
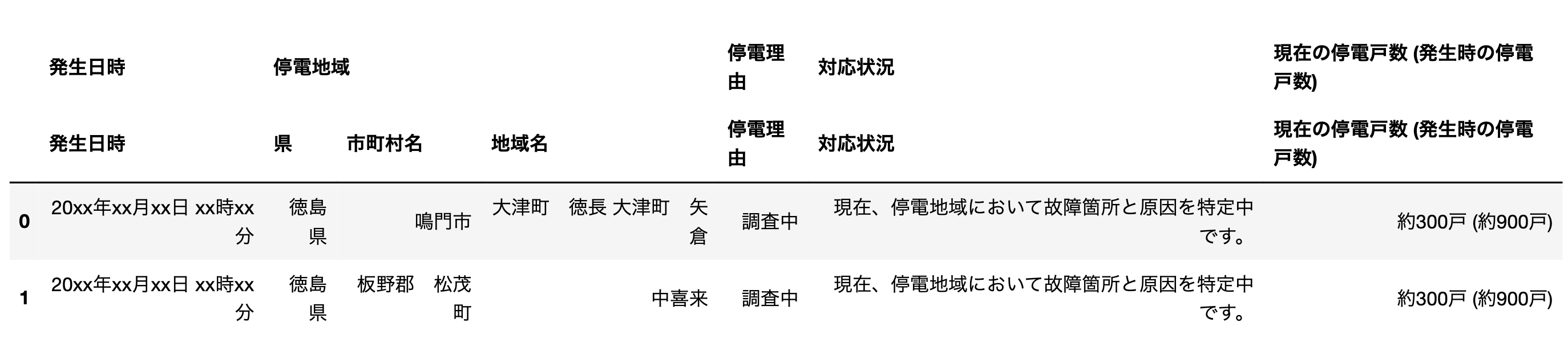
ちなみにPandasでパースする際は注意が必要で、以下のようにread_htmlの引数にdata(もしくはサイトのURL)を渡すことでも同様の結果が得られますが速度が非常に遅くなります。場合にもよるとは思いますが個人的にはtableタグを文字列にして渡すほうが良いと思います。
import pandas as pd
with open("sample.html") as f:
data = f.read()
pd.read_html(data)[0]
Pandasを用いないパース方法
Pandasを利用するのがtoo muchな環境や、インストールできない環境ではPandasのソースコードを改変して利用すると良いです。
from typing import Literal
import re
from re import Pattern
def parse_td(row):
return row.find_all(("td", "th"), recursive=False)
def text_getter(obj):
return obj.text
def attr_getter(obj, attr):
return obj.get(attr)
RE_WHITESPACE = re.compile(r"[\r\n]+|\s{2,}")
def remove_whitespace(s: str, regex: Pattern = RE_WHITESPACE) -> str:
return regex.sub(" ", s.strip())
def expand_colspan_rowspan(
rows, section: Literal["header", "footer", "body"]
) -> list[list]:
"""
Given a list of <tr>s, return a list of text rows.
Parameters
----------
rows : list of node-like
List of <tr>s
section : the section that the rows belong to (header, body or footer).
Returns
-------
list of list
Each returned row is a list of str text, or tuple (text, link)
if extract_links is not None.
Notes
-----
Any cell with ``rowspan`` or ``colspan`` will have its contents copied
to subsequent cells.
"""
all_texts = [] # list of rows, each a list of str
text: str | tuple
remainder: list[
tuple[int, str | tuple, int]
] = [] # list of (index, text, nrows)
for tr in rows:
texts = [] # the output for this row
next_remainder = []
index = 0
tds = parse_td(tr)
for td in tds:
# Append texts from previous rows with rowspan>1 that come
# before this <td>
while remainder and remainder[0][0] <= index:
prev_i, prev_text, prev_rowspan = remainder.pop(0)
texts.append(prev_text)
if prev_rowspan > 1:
next_remainder.append((prev_i, prev_text, prev_rowspan - 1))
index += 1
# Append the text from this <td>, colspan times
text = remove_whitespace(text_getter(td))
rowspan = int(attr_getter(td, "rowspan") or 1)
colspan = int(attr_getter(td, "colspan") or 1)
for _ in range(colspan):
texts.append(text)
if rowspan > 1:
next_remainder.append((index, text, rowspan - 1))
index += 1
# Append texts from previous rows at the final position
for prev_i, prev_text, prev_rowspan in remainder:
texts.append(prev_text)
if prev_rowspan > 1:
next_remainder.append((prev_i, prev_text, prev_rowspan - 1))
all_texts.append(texts)
remainder = next_remainder
# Append rows that only appear because the previous row had non-1
# rowspan
while remainder:
next_remainder = []
texts = []
for prev_i, prev_text, prev_rowspan in remainder:
texts.append(prev_text)
if prev_rowspan > 1:
next_remainder.append((prev_i, prev_text, prev_rowspan - 1))
all_texts.append(texts)
remainder = next_remainder
return all_texts
このexpand_colspan_rowspan関数を用いてあげれば簡単にパースできます。
from bs4 import BeautifulSoup
with open("sample.html") as f:
data = f.read()
soup = BeautifulSoup(data)
table = soup.find("table")
trs = table.select("tbody > tr")
expand_colspan_rowspan(trs, "body")
output
[['20xx年xx月xx日 xx時xx分',
'徳島県',
'鳴門市',
'大津町\u3000徳長 大津町\u3000矢倉',
'調査中',
'現在、停電地域において故障箇所と原因を特定中です。',
'約300戸(約900戸)'],
['20xx年xx月xx日 xx時xx分',
'徳島県',
'板野郡\u3000松茂町',
'中喜来',
'調査中',
'現在、停電地域において故障箇所と原因を特定中です。',
'約300戸(約900戸)']]
正しくパースされています。
※追記
もちろんthead部分もパースできます
trs = table.select("thead > tr")
expand_colspan_rowspan(trs, "body")
output
[['発生日時', '停電地域', '停電地域', '停電地域', '停電理由', '対応状況', '現在の停電戸数(発生時の停電戸数)'],
['発生日時', '県', '市町村名', '地域名', '停電理由', '対応状況', '現在の停電戸数(発生時の停電戸数)']]