はじめに
鑑賞した映画の記録に,Filmarksというサービスを利用しています.
鑑賞時の評価を0~5の11段階(0.5刻み)のスコアで残すようにしていますが,評価の一貫性を保つのが難しいです.過去に自分がつけた評価を見ていても,「厳しくつけすぎた」とか「甘くつけすぎた」というのが多々あります.
スコア一覧を取得
現在の評価の分布を確認してみます.
Filmarksは「自分がつけたスコア毎に一覧を確認」的な操作がやり辛いので,BeautifulSoupを使用してhtmlから一覧を取得します.Jupyter Notebook を使用しました.
import
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
スコア一覧取得
dict = {"title":[], "infobar":[]}
for page in range(1, 11):
rs = requests.get("https://filmarks.com/users/<ユーザ名>?view=poster", params={"page":page})
soup = BeautifulSoup(rs.content, "lxml")
titles = soup.select(".c-movie-item__title > a")
infobars = soup.select(".c-movie-item-infobar__item.c-movie-item-infobar__item--star.is-active > a > span")
for title, infobar in zip(titles, infobars):
dict["title"].append(title.string)
dict["infobar"].append(infobar.string)
df = pd.DataFrame(dict)
df.infobar = df.infobar.str.replace('-', '0')
df.infobar = df.infobar.astype("float64")
鑑賞済み映画一覧のページ数はハードコードです.(自分の場合10ページあった)
データの中身を確認
df.info()
df.head(10)
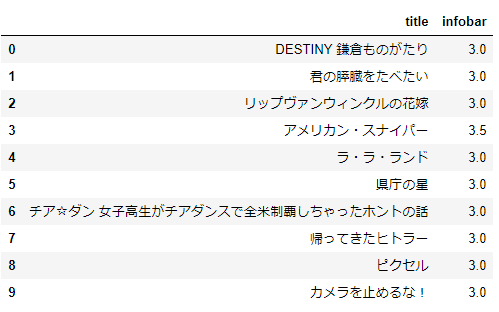
直近10件分のタイトルとスコア.きちんと取れてそう.
df.hist()
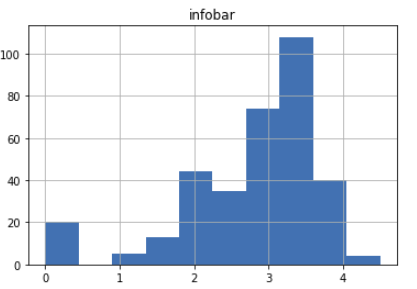
ヒストグラム.これが見たかった.
(昔に見た映画等スコアをつけていないものは便宜上0として処理.0.5, 5.0は実質欠番.)
おわりに
「必要なら,分布がいい感じになるように過去の評価を微修正しよう」などと考えていましたが,面倒なのでやめました.(というより見ている映画がそもそも少ないので,あまり分布を気にしても仕方がない気がします)
全体のスコア平均と自分のスコアを比較したり,レビューを全て取得してきて字句解析とかすると面白そうです.