はじめに
プログラミングを学び始めたばかりですが、実際のデータを使って何かを作ってみたいと思い、私が以前住んでいたカナダ・ウィスラーの降雪予測をAIで分析してみました。
今回は、データの取得からモデル構築、Webアプリ化、クラウド公開までを一通り実装しました。
使用技術
Python・pandas・Flask・scikit-learn・gunicorn・Render(クラウド公開)
実行環境
Google Colaboratory
Visual Studio Code
準備
カナダ政府の気象データ(ECCC)から2020年~2026年2月までの最高気温・最低気温・平均気温・降水量・積雪量のデータをダウンロードしました。これらのデータをGoogle Colabratoryで複数のCSVを結合し、Webアプリで扱えるように整理しました。
このアプリでは、以下の流れで処理を行っています。
1.データの準備と前処理
2020年〜2026年のデータを使用しています。
TRAIN_CSV_PATH = os.path.join("data", "whistler_train.csv")
2.CSVデータの読み込み
CSVからデータを読み込み、日付や数値を整形します。
df = pd.read_csv(TRAIN_CSV_PATH)
df[DATE_COL] = pd.to_datetime(df[DATE_COL], errors="coerce")
df[TARGET_COL] = pd.to_numeric(df[TARGET_COL], errors="coerce")
df = df.dropna(subset=[DATE_COL, TARGET_COL])
※日付は datetime型に変換、降雪量は数値型に変換、欠損値は削除しました。
3.特徴量の作成
日付をそのままモデルに入れることはできないため、日付データを「モデルが学習できる数値」に変換しています。
START_DATE = df[DATE_COL].min()
df["day_number"] = (df[DATE_COL] - START_DATE).dt.days
df["month"] = df[DATE_COL].dt.month
df["day"] = df[DATE_COL].dt.day
4.学習と評価
時系列データなので shuffle=False(未来データが混ざらないようにする)
精度は MAE(平均絶対誤差)で評価
X_train, X_test, y_train, y_test = train_test_split(..., shuffle=False)
model = LinearRegression()
model.fit(X_train, y_train)
pred = model.predict(X_test)
mae = mean_absolute_error(y_test, pred)
起動時にモデルを1回だけ学習
model, mae, START_DATE, LAST_TRAIN_DATE = build_model()
5.予測関数
入力日付から特徴量を作り、model.predict() で予測
def predict_snow(target_date):
6.Webアプリ化(Flask)
GET:初期画面表示
POST:日付入力 → 予測実行
@app.route("/", methods=["GET", "POST"])
def index():
今回作成したアプリはこちらです。
https://whistler-snow-app.onrender.com/
日付を入力して、『予測する』ボタンを押します。
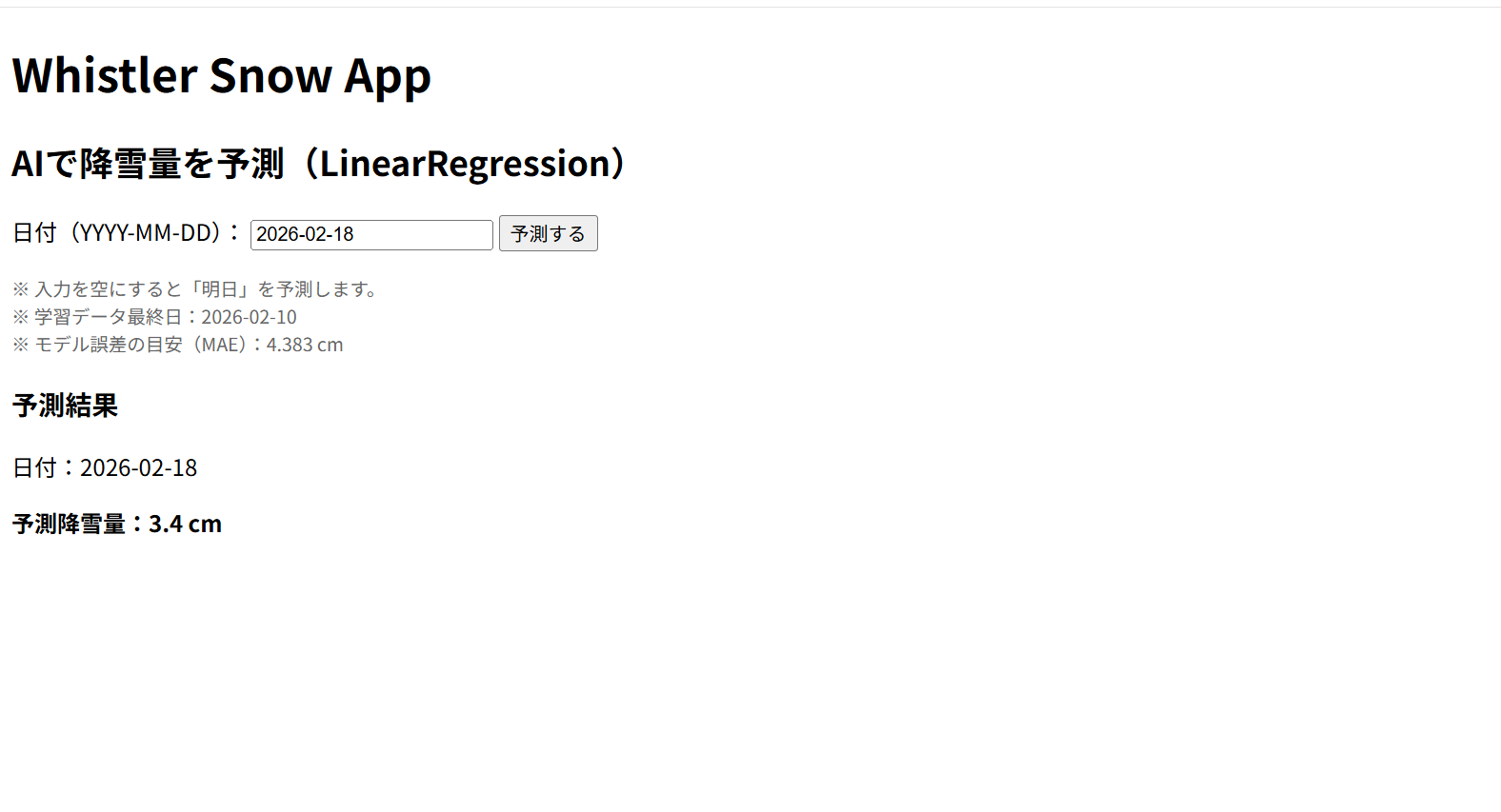
すると結果が返ってきます。
改善点・考察
当初はRandomForestを用いてモデルを構築していましたが、
LinearRegressionへ変更したところ、予測結果に変化が見られました。
RandomForestは複数の決定木を組み合わせたアンサンブル学習であり、
非線形な関係を捉えることが得意で、一方のLinearRegressionは
入力特徴量と出力の関係を直線的に近似するシンプルな線形モデルです。
そのため、データの構造が非線形である場合、
RandomForestの方が複雑なパターンを学習できる可能性があります。
今回LinearRegressionに変更したことで、
予測値の傾向がシンプルになり、モデルの挙動が理解しやすくなりました。
この経験から、
モデルの選択が予測結果に大きく影響すること
シンプルなモデルほど解釈しやすいこと
データ構造とアルゴリズムの相性が重要であることを学びました。