これまでのあらすじ
前回はこちら
ヅカの芸名の一覧を作って、まずその解析をしていたところ。
大体見たのでまあいいかなと思ったが、やっぱりもうちょっとやりたいことがあったので、今回はその続き。
いい加減keras使った機械学習に入れと自分でも思わなくはないが、気になる点はまだ多いので、pandasやmatplotlibの勉強がてらもう少し解析を続けようと思う。
(次の記事は10年代ごとの姓名、使われる字を調べて年代の比較をしたい)
ひらがなヒートマップ
詳細は前回記事に譲るが、宝塚の芸名のうち名前の方は、ひらがなの使用率が高い(参照)。
ひらがなをヒートマップにしたくなってしまったのだ。
漢字と違って個数が少ないのと、規則性のある並べ方をしやすいので(漢字もできなくはない部首順で並べるとか。が、漢字は数が多すぎる)、ヒートマップにすると法則性が可視化しやすい。
出現回数とかなをExcelでヒートマップにするのも思わなくはなかったが、ここはmatplotlibの勉強がてらやってみたい
ひらがな一覧
kana = [
['あ', 'い', 'う', 'え', 'お'],
['か', 'き', 'く', 'け', 'こ'],
['さ', 'し', 'す', 'せ', 'そ'],
['た', 'ち', 'つ', 'て', 'と'],
['な', 'に', 'ぬ', 'ね', 'の'],
['は', 'ひ', 'ふ', 'へ', 'ほ'],
['ま', 'み', 'む', 'め', 'も'],
['や', 'ゐ', 'ゆ', 'ゑ', 'よ'],
['ら', 'り', 'る', 'れ', 'ろ'],
['わ', '', '', '', 'を'],
['ん', '', '', '', ''],
['が', 'ぎ', 'ぐ', 'げ', 'ご'],
['ざ', 'じ', 'ず', 'ぜ', 'ぞ'],
['だ', 'ぢ', 'づ', 'で', 'ど'],
['ば', 'び', 'ぶ', 'べ', 'ぼ'],
['ぱ', 'ぴ', 'ぷ', 'ぺ', 'ぽ'],
['ぁ', 'ぃ', 'ぅ', 'ぇ', 'ぉ'],
['', '', 'っ', '', ''],
['ゃ', '', 'ゅ', '', 'ょ'],
]
使う人がいるかはわからないが、Pythonでひらがな一覧を使う予定があれば、上のソースのコピーをどうぞ。
これは人が見やすく(書きやすく)するため「あいうえお」を横に、「あかさたな」を縦に並べている。よく見る「あ行」が一番右にあるひらがな表にするには、時計回りに回転させる。
ひらがなごとの出現回数
kana_counts = []
for k_1 in kana:
kc_1 = [name_dic[c] if c != '' and c in name_dic else 0 for c in k_1]
kana_counts.append(kc_1)
print(kana_counts)
kana_counts = np.rot90(np.array(kana_counts), -1)
kana_counts
name_dicは宝塚の芸名のうち、名前を解析し、字一文字をkeyとし出現回数をvalueにした辞書。
使われないひらがなもありうるため、ひらがなの一覧を別途作り、一覧に対して出現回数を参照する。
二次元配列を一次元配列にするとヒートマップにしたときにひらがな表にできないので、2次元配列のまま出現回数をカウントしている。
ヒートマップにした際、よく見るあ行が一番右の表形式にするため、時計回りに90度回転させる(np.rot90()の箇所)。
ヒートマップの作成
import matplotlib.pyplot as plt
R = 5
C = 19
plt.rcParams['font.family'] = 'Hiragino Sans'
# ヒートマップを作成
fig, ax = plt.subplots(ncols = 1, nrows = 1, figsize = (13, 5)) # 図の設定
ax.pcolor(kana_counts, cmap=plt.cm.Reds) # ヒートマップ
ax.set_xticks(np.arange(C) + 0.5) # x軸目盛の位置
ax.set_xticklabels(['ゅ', 'っ', 'ぁ', 'ぱ', 'ば', 'だ', 'ざ', 'が', 'ん', 'わ', 'ら', 'や', 'ま', 'は', 'な', 'た', 'さ', 'か', 'あ']) # x軸目盛のラベル
ax.set_yticks(np.arange(R) + 0.5) # y軸目盛の位置
ax.set_yticklabels(['あ', 'い', 'う', 'え', 'お']) # y軸目盛のラベル
ax.invert_yaxis()
plt.show() # 図を表示
筆者の環境はmacなので、日本語表示ができるようHiragino Sansを設定する。
ヒートマップの作成は下記の記事を参考にし、大いに助けられた。
できた図がこれである。
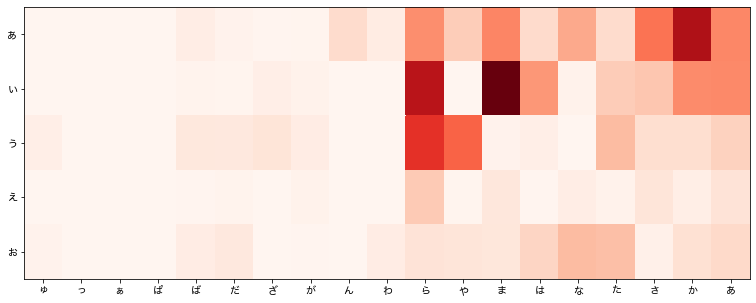
全体的に右上の比率が高い。特に、「あ」音と「い」音。ついで「う」音。
行で言うと、「ま」行「る」行が高い。おそらく読みと相関があるかと思う。一般女性名との比較もしたくなってきたが、そこまですると横道にそれすぎるか…
やはりと言うべきか濁音、半濁音は少ない。半濁音は4700人もいるのだから居てもいい気もするが…。
濁音になると「う」音「お」音の比率が相対的に高いのは不思議だ。
名前読みのひらがなヒートマップも作ってみた。
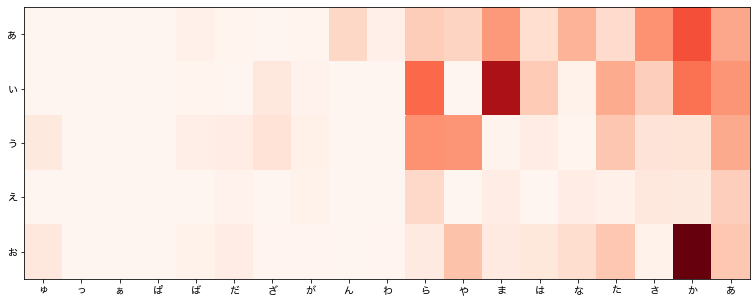
「こ」の利用率が格段に上がるのは、「子」が最も多く使われる字だからだろう。
それ以外の傾向は名前とおおむね同様である。
当たり前な結論のような気もするが、そうでもない気もする。
ひらがな名だから使われる字はなく、漢字の時だけ使われるような字(ひらがな名に開かれにくい)は「子」以外にないと言うことなのだろう。
参考にひらがなに対しての出現回数の表を記載しておく。
| かな | ひらがな名での出現回数 | 読みでの出現回数 |
|---|---|---|
| あ | 177 | 394 |
| い | 175 | 465 |
| う | 75 | 383 |
| え | 46 | 235 |
| お | 63 | 265 |
| か | 366 | 727 |
| き | 172 | 601 |
| く | 57 | 135 |
| け | 19 | 92 |
| こ | 54 | 1270 |
| さ | 205 | 478 |
| し | 93 | 238 |
| す | 57 | 130 |
| せ | 42 | 106 |
| そ | 12 | 27 |
| た | 60 | 181 |
| ち | 84 | 381 |
| つ | 107 | 270 |
| て | 9 | 37 |
| と | 103 | 266 |
| な | 133 | 349 |
| に | 9 | 29 |
| ぬ | 1 | 10 |
| ね | 22 | 64 |
| の | 107 | 169 |
| は | 62 | 167 |
| ひ | 157 | 251 |
| ふ | 18 | 64 |
| へ | 2 | 0 |
| ほ | 71 | 110 |
| ま | 181 | 449 |
| み | 434 | 1079 |
| む | 7 | 17 |
| め | 37 | 69 |
| も | 38 | 89 |
| や | 82 | 212 |
| ゐ | 1 | 0 |
| ゆ | 224 | 464 |
| ゑ | 4 | 0 |
| よ | 41 | 292 |
| ら | 168 | 240 |
| り | 350 | 639 |
| る | 287 | 480 |
| れ | 87 | 189 |
| ろ | 46 | 85 |
| わ | 24 | 49 |
| を | 23 | 9 |
| ん | 61 | 198 |
| が | 5 | 10 |
| ぎ | 10 | 23 |
| ぐ | 23 | 44 |
| げ | 10 | 27 |
| ご | 3 | 6 |
| ざ | 2 | 3 |
| じ | 18 | 106 |
| ず | 43 | 139 |
| ぜ | 0 | 0 |
| ぞ | 1 | 6 |
| だ | 7 | 12 |
| ぢ | 4 | 4 |
| づ | 33 | 64 |
| で | 6 | 22 |
| ど | 33 | 62 |
| ば | 21 | 31 |
| び | 6 | 10 |
| ぶ | 35 | 51 |
| べ | 2 | 4 |
| ぼ | 23 | 28 |
| ぱ | 0 | 1 |
| ぴ | 0 | 0 |
| ぷ | 0 | 0 |
| ぺ | 0 | 0 |
| ぽ | 0 | 0 |
| ぁ | 0 | 0 |
| ぃ | 0 | 1 |
| ぅ | 0 | 0 |
| ぇ | 0 | 0 |
| ぉ | 0 | 0 |
| っ | 0 | 4 |
| ゃ | 0 | 0 |
| ゅ | 17 | 91 |
| ょ | 8 | 101 |
解析編の続きはこちら。10期ごとに分けて各年代の傾向を解析する。