これまでのあらすじ
前回はこちら
ヅカの芸名の一覧を作って、まずその解析をしていたところ。
当初は90期(2002年入団、つまりここ20年)以降の芸名を集めれば、現代風のヅカの芸名の学習データになると想定していた。しかし、ざっと解析すると想像以上にそれより前の年代から現代っぽい気がしており、それを確認しているところ。
年代を10期ごとに分ける
本来であれば、2020年代、2010年代と西暦で10年紀ごとに分けたいのだが、宝塚の期と入団年を合わせるのは実は面倒臭い…。初期は入団年が一定でなかったり、戦争期の混乱もあったようで、安定して期=>入団年を特定できるのは音楽学校からの入団制度が整ってからになる。
なので入団期を10期ごとに分けて便宜上10年紀とする。
データ解析編(1)で取り込んだDataFrameを基に、10期ごとかつ芸名と読み仮名を姓名に分けたDataFrameを作成する。
import math
def devide_name(df, key):
df = df[key].str.split(' ', expand = True)
df.rename(columns = {0:'姓', 1:'名'}, inplace=True)
return df
dec_data = list()
for i in range(math.ceil(MAX_PERIOD / 10)):
print('{} - {}'.format(i * 10, (i + 1) * 10))
name = actress_data.query('{} * 10 <= 期 < {} * 10'.format(i, i + 1))
dec_data.append({'芸名':devide_name(name, '芸名'), '読み仮名':devide_name(name, '読み仮名')})
dec_data[9]
{'芸名': 姓 名
0 芽吹 幸奈
1 愛原 実花
2 響 れおな
3 香綾 しずる
4 花音 舞
.. ... ...
32 春矢 祐璃
33 隼 玲央
34 万名月 洸
35 璃央 じゅん
36 桜里 まお
[433 rows x 2 columns],
'読み仮名': 姓 名
0 めぶき ゆきな
1 あいはら みか
2 ひびき れおな
3 かりょう しずる
4 かのん まい
.. ... ...
32 はるや ゆうり
33 はやと れお
34 まなづき こう
35 りおう じゅん
36 おうり まお
[433 rows x 2 columns]}
これでindex=0に1期から9期、1に10期から19期と…10に100期から108期、10期ごとに分割した姓名が別列のDataFrameができた。
解析するもの
前回はひらがなヒートマップなども作ったが、あれは趣味であんまり傾向を知る解析としては意味がないので、解析内容を絞り、以下の3つを解析する。
- 文字の出現回数
- 姓、名に使われる文字が各年代でどう変化しているか
- ランキング
- 重複の多い(=その年代で人気の高い)姓、名
- ユニーク率
- 姓、名の重複率の推移
データとして「芸名」と「読み仮名」を別に持っているので、芸名、読み仮名どちらも解析する。
文字の出現回数
DataFrameから文字の出現回数をカウントする関数を定義する。
使われている文字すべてを出すと多くなりすぎ、人気のある文字の傾向が分かれば良いのでTOP10くらいに絞る。
#使われている文字の出現回数TOP20をカウントする関数
def count_char_appearance(df, type_key, name_key):
d = dict()
for index, data in df[type_key][name_key].iteritems():
for s in data:
d.setdefault(s, 0)
d[s] = d[s] + 1
d2 = sorted(d.items(), key = lambda x : x[1], reverse = True)
return d2[:10]
count_char_appearance(dec_data[9], '芸名', '姓')
[('月', 30),
('花', 29),
('咲', 23),
('華', 22),
('乃', 20),
('風', 20),
('真', 18),
('美', 17),
('羽', 16),
('海', 16)]
ランキング
DataFrameから重複している姓名やその重複数をカウントする。
おおむねユニークなのはこれまでの解析でわかっているので、これもTOP10くらいに絞る。
#重複の多いTOP10を出力する関数
def get_same_name(df, type_key, name_key):
l = list()
for index, data in df[type_key][name_key].value_counts()[:10].iteritems():
l.append((index, data))
return l
get_same_name(dec_data[9], '芸名', '姓')
[('麗', 2),
('朝陽', 2),
('芽吹', 1),
('夢華', 1),
('咲妃', 1),
('春海', 1),
('瀬戸花', 1),
('秋音', 1),
('夢奈', 1),
('音咲', 1)]
ユニーク率
DataFrameから姓名がどの程度重複しているかの数字を出す。
おおむねユニークなのはわかっているが、率の変化を見ることで、どの程度個性化が変化しているかが見てとれるかを期待している。
#ユニーク性(重複のない率)を計測する関数
def measure_unique(df, type_key, name_key):
return df[type_key][name_key].value_counts().value_counts(normalize = True, sort = False)[1]
measure_unique(dec_data[9], '芸名', '姓')
0.9953596287703016
文字の出現回数の変化
芸名/姓
| 文字 | 1位 | 2位 | 3位 | 4位 | 5位 | 6位 | 7位 | 8位 | 9位 | 10位 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1期代 | 野 | 8 | 山 | 7 | 田 | 5 | 松 | 5 | 小 | 4 | 高 | 4 | 秋 | 3 | 三 | 3 | 良 | 3 | 川 | 3 |
| 10期代 | 野 | 35 | 山 | 20 | 川 | 13 | 月 | 12 | 千 | 11 | 路 | 11 | 松 | 10 | 小 | 9 | 高 | 9 | 島 | 9 |
| 20期代 | 野 | 33 | 山 | 31 | 川 | 28 | 美 | 26 | 花 | 25 | 路 | 24 | 月 | 22 | 小 | 22 | 大 | 22 | 高 | 20 |
| 30期代 | 美 | 22 | 月 | 18 | 千 | 18 | 野 | 15 | 路 | 13 | 城 | 12 | 春 | 12 | 山 | 11 | 朝 | 11 | 花 | 11 |
| 40期代 | 城 | 26 | 月 | 25 | 川 | 23 | 千 | 23 | 路 | 22 | 里 | 20 | 美 | 20 | 島 | 14 | 野 | 14 | 白 | 12 |
| 50期代 | 美 | 37 | 月 | 25 | 城 | 21 | 里 | 20 | 千 | 19 | 路 | 17 | 麻 | 13 | 真 | 13 | 奈 | 12 | 木 | 10 |
| 60期代 | 城 | 21 | 美 | 21 | 花 | 18 | 千 | 16 | 麻 | 14 | 月 | 13 | 奈 | 13 | 原 | 12 | 風 | 12 | 樹 | 11 |
| 70期代 | 月 | 18 | 城 | 18 | 美 | 17 | 大 | 16 | 花 | 14 | 真 | 13 | 原 | 12 | 風 | 12 | 夏 | 12 | 奈 | 12 |
| 80期代 | 花 | 33 | 月 | 22 | 華 | 21 | 美 | 18 | 輝 | 17 | 乃 | 15 | 音 | 15 | 麻 | 14 | 真 | 14 | 咲 | 14 |
| 90期代 | 月 | 30 | 花 | 29 | 咲 | 23 | 華 | 22 | 乃 | 20 | 風 | 20 | 真 | 18 | 美 | 17 | 羽 | 16 | 海 | 16 |
| 100期代 | 美 | 19 | 乃 | 18 | 羽 | 17 | 花 | 17 | 彩 | 15 | 愛 | 15 | 華 | 15 | 音 | 14 | 咲 | 14 | 風 | 13 |
20期代まで人気のあった「野」が30期以降順位を落とし、50期以降ではTOP10から消えている。「山」も同じ傾向を辿っている。
これは20期までは万葉集などを参考に名付けられることが多く、野や山が多く詠われていたのだろう。
「月」はコンスタントに人気があり、30期以降高位にランク入りしている。100期代ないのは興味深い。
「美」も20期以降、ほぼランク入りしており人気の高い文字だが、100期代では下がっている。「花」は安定して人気がある。
「城」は70期まではランク入りしているが、それ以降は無くなっている。いないわけではなく、月城かなとさんなどが思いつく。
「風」は60期代からランク入りしている。「海」は90期にランク入りしただけでそれ以外にはいない。
ここ30期で目立つのは、「乃」「羽」「咲」「華」「音」。
しかし、「彩」「愛」は100期にしかなく、ランク傾向に変化が見られる。100期はまた時代が変わってきている感がある。
100期生は、2012年音楽学校入学、15〜18歳が入学資格なので、1994年〜97年生まれの女性でバブル崩壊後、平成に生まれている。108期だと全員21世紀の生まれである。エンジニア的には、生まれた時からパソコンがあり、幼少期には家庭にインターネットが広まっている世代でもある。
90期もおおむね平成生まれだが、昭和生まれが混じっている年代である。
社会が大きく変わり、名付けにも何か変化が起きているようだが、90期と同世代の筆者には明確に捉えきれない何かを感じる。
予測であるが、スマホネイティブな世代(2010年ころ生まれ)が入団する頃にはまた名前の傾向が変わっているのではないだろうか。
芸名/名
| 文字 | 1位 | 2位 | 3位 | 4位 | 5位 | 6位 | 7位 | 8位 | 9位 | 10位 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1期代 | 子 | 53 | も | 3 | し | 3 | 久 | 3 | み | 2 | 浪 | 2 | 咲 | 2 | ほ | 2 | 小 | 2 | 夜 | 2 |
| 10期代 | 子 | 261 | み | 29 | か | 17 | 美 | 16 | 代 | 13 | 千 | 13 | し | 11 | る | 11 | 浪 | 9 | さ | 9 |
| 20期代 | 子 | 427 | み | 65 | 美 | 60 | 千 | 48 | か | 38 | 代 | 30 | る | 30 | さ | 24 | ゆ | 19 | り | 19 |
| 30期代 | 子 | 159 | 美 | 52 | み | 41 | 千 | 34 | か | 31 | る | 27 | 代 | 24 | り | 19 | ゆ | 16 | し | 11 |
| 40期代 | 子 | 151 | 美 | 87 | み | 63 | 千 | 58 | る | 40 | り | 33 | か | 32 | 代 | 27 | 里 | 22 | ひ | 20 |
| 50期代 | み | 80 | る | 74 | か | 67 | 子 | 57 | り | 49 | 美 | 47 | き | 37 | ま | 35 | 千 | 35 | ゆ | 33 |
| 60期代 | か | 51 | り | 40 | み | 39 | さ | 31 | ゆ | 30 | る | 27 | 美 | 27 | い | 26 | ま | 23 | き | 22 |
| 70期代 | か | 45 | り | 35 | み | 31 | ゆ | 28 | あ | 27 | 美 | 26 | き | 25 | い | 23 | る | 21 | ま | 18 |
| 80期代 | り | 53 | ら | 36 | か | 35 | み | 34 | ゆ | 30 | あ | 26 | い | 25 | る | 25 | な | 24 | さ | 23 |
| 90期代 | り | 52 | ら | 37 | か | 35 | あ | 29 | い | 28 | ゆ | 28 | み | 26 | な | 25 | ま | 24 | き | 22 |
| 100期代 | り | 42 | ら | 32 | あ | 29 | い | 28 | み | 24 | ゆ | 18 | さ | 17 | と | 16 | か | 15 | ん | 15 |
これまた面白い結果が出たもんだ。
子が使われなくなったのは、前々回の記事で解析したが、80期以降のひらがなの利用率の高さ。ひらがなのほうが柔らかい印象は出るが…
「美」の字が定番だったのに80期以降ランク外になっている。姓の方では使われていることから、昔は姓名どちらかに美を使うが、徐々に姓のほうに移っていったという推移があるようだ。
前回のひらがなヒートマップで、「か」「み」「り」「る」が多い傾向はわかっている。この4文字を見てみたい。
「か」は安定して高いが、100期では下がっている。
「み」は安定して3位以内におおむね入っていたが、80期以降徐々にランクを下げている。100期では少し復権。「美」の推移と相関がある?
「り」は20期代から使われているが、徐々にランクを上げ、60期以降は定番の文字にな理、30期連続で一位。
「る」は50期で2位である以外は中〜下位にランク入りしていたが、80期以降尻すぼみで90期以降消えた。ここ20年で人気がなくなった文字。
興味深いのは「ら」で、ここ30期でいきなりランク2位になっている。なぜだ。
100期特有で「と」「ん」がある。
読み仮名/姓
| 文字 | 1位 | 2位 | 3位 | 4位 | 5位 | 6位 | 7位 | 8位 | 9位 | 10位 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1期代 | ま | 19 | か | 13 | た | 12 | の | 12 | お | 11 | つ | 11 | あ | 9 | み | 9 | き | 8 | ら | 8 |
| 10期代 | ま | 68 | か | 61 | み | 55 | き | 52 | の | 47 | な | 46 | し | 45 | さ | 43 | や | 42 | ら | 39 |
| 20期代 | み | 157 | か | 142 | ま | 125 | き | 111 | さ | 100 | ら | 91 | お | 89 | し | 89 | な | 79 | の | 78 |
| 30期代 | み | 81 | か | 69 | き | 57 | ま | 57 | さ | 54 | し | 53 | ら | 46 | あ | 46 | や | 45 | な | 45 |
| 40期代 | か | 100 | み | 99 | き | 94 | ま | 86 | し | 78 | さ | 66 | あ | 61 | な | 58 | た | 55 | じ | 54 |
| 50期代 | み | 94 | き | 89 | な | 82 | ま | 80 | か | 79 | う | 71 | し | 67 | あ | 61 | た | 52 | さ | 51 |
| 60期代 | か | 83 | き | 81 | み | 73 | あ | 65 | さ | 63 | な | 62 | う | 52 | お | 49 | ま | 45 | い | 43 |
| 70期代 | き | 90 | か | 82 | み | 73 | な | 65 | あ | 61 | お | 61 | さ | 57 | う | 50 | ま | 50 | し | 47 |
| 80期代 | き | 91 | み | 77 | か | 74 | な | 71 | あ | 58 | う | 58 | は | 55 | さ | 53 | お | 52 | ま | 47 |
| 90期代 | き | 106 | な | 92 | か | 82 | う | 70 | さ | 65 | み | 65 | あ | 62 | は | 62 | ま | 51 | お | 44 |
| 100期代 | き | 74 | あ | 67 | な | 65 | み | 63 | か | 61 | は | 54 | い | 52 | お | 40 | さ | 39 | ま | 38 |
「ま」が順当に順位を下げている。逆に「き」は順位を上げ、ここ40期は安定している。「な」も上昇傾向にある。
「か」は安定していたが、ここ30期で下降傾向が見える。
「み」も下降傾向に思えるが、100期でランクを上げているので、まだわからない。
「は」はここ30期のトレンド。「羽」「華」が使われるようになった影響だろう。「華」は「か」とも読むが、華優希のように「はな」読みが多いのかもしれない。80期以降で「華」のつく姓で、「はな」読みは25名、「か」読みは32名だった。ごめん。
読み仮名/名
| 文字 | 1位 | 2位 | 3位 | 4位 | 5位 | 6位 | 7位 | 8位 | 9位 | 10位 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1期代 | こ | 53 | き | 15 | み | 13 | さ | 8 | し | 8 | つ | 7 | な | 5 | ち | 5 | や | 4 | ま | 4 |
| 10期代 | こ | 264 | み | 75 | き | 41 | よ | 40 | さ | 35 | つ | 35 | か | 35 | な | 30 | う | 29 | た | 28 |
| 20期代 | こ | 443 | み | 192 | き | 90 | さ | 82 | ち | 79 | か | 74 | よ | 73 | る | 70 | え | 61 | ま | 57 |
| 30期代 | こ | 164 | み | 124 | か | 54 | る | 52 | き | 49 | よ | 47 | ち | 44 | り | 43 | さ | 40 | し | 37 |
| 40期代 | み | 200 | こ | 161 | り | 86 | か | 81 | ち | 78 | る | 72 | さ | 65 | よ | 60 | き | 54 | ゆ | 54 |
| 50期代 | み | 151 | か | 115 | る | 96 | り | 86 | き | 83 | こ | 72 | ま | 64 | ゆ | 64 | ち | 63 | さ | 58 |
| 60期代 | み | 93 | か | 91 | り | 77 | ま | 56 | ゆ | 55 | き | 53 | さ | 52 | い | 50 | あ | 44 | な | 42 |
| 70期代 | か | 89 | み | 78 | き | 73 | り | 65 | ゆ | 62 | あ | 54 | い | 50 | ま | 47 | う | 47 | な | 38 |
| 80期代 | か | 81 | り | 80 | み | 60 | い | 59 | あ | 50 | ゆ | 47 | な | 46 | き | 46 | ま | 45 | ら | 42 |
| 90期代 | り | 79 | か | 66 | い | 60 | き | 58 | み | 49 | ゆ | 48 | あ | 48 | な | 47 | ま | 46 | ら | 46 |
| 100期代 | り | 59 | い | 56 | あ | 46 | み | 44 | ゆ | 40 | ん | 40 | ら | 40 | き | 39 | か | 37 | な | 34 |
「り」は徐々に上がってきて、「こ」は途中消滅。「み」は安定していたが、近年下降気味。というのは、芸名/名と同様。
「い」がランクを上げている。芸名/名も同様だったが気づかなかった。
「ら」は芸名/名だとここ30期のランクは高いが、読み仮名だとランクが下がる。
「る」は芸名/名だとランク内にいるが、読みだとランク外になる。ひらがなでしか使われない。確かに「る」読みする感じはあまり思いつかない。
ランキング
芸名/姓
| 名前 | 1位 | 2位 | 3位 | 4位 | 5位 | 6位 | 7位 | 8位 | 9位 | 10位 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1期代 | 秋田 | 2 | 奈良 | 2 | 松帆 | 2 | 關守 | 2 | 松山 | 2 | 若菜 | 2 | 泉 | 1 | 天津 | 1 | 有明 | 1 | 初瀬 | 1 |
| 10期代 | 千鳥 | 3 | 八重 | 2 | 岸 | 2 | 雄島 | 2 | 如月 | 2 | 須磨 | 2 | 泉 | 2 | 櫻井 | 2 | 筑紫 | 2 | 山野 | 2 |
| 20期代 | 曙 | 4 | 大和 | 3 | 京 | 2 | 小波 | 2 | 三室 | 2 | 旭 | 2 | 櫻木 | 2 | 南 | 2 | 大宮 | 2 | 鈴川 | 2 |
| 30期代 | 深山 | 2 | 吾妻 | 2 | 吉野 | 2 | 立花 | 2 | 川霧 | 2 | 常盤 | 2 | 春日 | 2 | 千代田 | 2 | 恵 | 2 | 三室 | 2 |
| 40期代 | 藤 | 3 | 園 | 3 | 峯 | 3 | 桜 | 3 | 東 | 3 | 浜 | 3 | 千波 | 3 | 星 | 2 | 多摩川 | 2 | 八雲 | 2 |
| 50期代 | 紅 | 3 | 響 | 2 | 真 | 2 | 駒草 | 2 | 団 | 2 | 登流 | 2 | 条 | 2 | 長月 | 2 | 茜 | 2 | 千城 | 2 |
| 60期代 | 宮 | 2 | 姫 | 2 | 英 | 2 | 一城 | 2 | 若菜 | 2 | 空 | 2 | 翼 | 2 | 街 | 2 | 花 | 2 | 高嶺 | 2 |
| 70期代 | 大空 | 2 | 穂高 | 2 | 悠 | 2 | 鈴奈 | 2 | 宝樹 | 2 | 茜 | 2 | 路 | 2 | 楓 | 1 | 純名 | 1 | 名城 | 1 |
| 80期代 | 初輝 | 2 | 高宮 | 2 | 南帆 | 2 | 七海 | 2 | 夢咲 | 2 | 千 | 2 | 蓮城 | 2 | 遥海 | 1 | 青葉 | 1 | 華城 | 1 |
| 90期代 | 麗 | 2 | 朝陽 | 2 | 芽吹 | 1 | 夢華 | 1 | 咲妃 | 1 | 春海 | 1 | 瀬戸花 | 1 | 秋音 | 1 | 夢奈 | 1 | 音咲 | 1 |
| 100期代 | 蘭 | 1 | 真澄 | 1 | 鳳城 | 1 | 和真 | 1 | 湖春 | 1 | 華世 | 1 | 明希翔 | 1 | 青風 | 1 | 水城 | 1 | 花翔 | 1 |
重複がほとんどないので、あまり見るべきところがない。
強いて言えば、40期〜70期に多かった一文字姓が減っていることか。比較的バリエーション豊かに見える。
芸名/名
| 名前 | 1位 | 2位 | 3位 | 4位 | 5位 | 6位 | 7位 | 8位 | 9位 | 10位 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1期代 | 君子 | 2 | 八重子 | 2 | 道子 | 2 | 小夜子 | 2 | もしほ | 2 | 咲子 | 2 | 浪子 | 2 | 千鳥 | 2 | 月子 | 2 | 音羽子 | 1 |
| 10期代 | 浪子 | 5 | 櫻子 | 4 | 浦子 | 3 | 麗子 | 3 | 光子 | 3 | 葉子 | 3 | 邦子 | 3 | 関子 | 3 | 幾代 | 3 | 清子 | 3 |
| 20期代 | 陽子 | 8 | 京子 | 8 | 明子 | 7 | 輝子 | 6 | 妙子 | 6 | 玲子 | 6 | 松子 | 4 | 都 | 4 | 黎子 | 4 | 公子 | 4 |
| 30期代 | みどり | 8 | ゆかり | 7 | 京子 | 6 | 妙子 | 6 | 洋子 | 6 | かほる | 6 | 千鶴 | 5 | 公子 | 5 | 三千代 | 4 | 薫 | 4 |
| 40期代 | 京子 | 8 | 洋子 | 7 | 千鶴 | 6 | まり | 6 | ひろみ | 5 | みどり | 5 | 由美 | 5 | 万里子 | 5 | ひかる | 5 | 美千代 | 4 |
| 50期代 | ひかる | 8 | のぼる | 8 | みちる | 6 | かほる | 6 | まり | 6 | あきら | 5 | ゆたか | 5 | みつる | 5 | ひろみ | 5 | みき | 5 |
| 60期代 | じゅん | 5 | 幸 | 3 | かおる | 3 | あすか | 3 | ゆう | 3 | ゆかり | 3 | ひかる | 3 | あい | 3 | 愛 | 3 | のぼる | 3 |
| 70期代 | ゆう | 6 | まり | 6 | はるか | 5 | ひとみ | 5 | 薫 | 4 | 愛 | 4 | 舞 | 4 | れい | 3 | つかさ | 3 | あい | 3 |
| 80期代 | ひかる | 3 | 奏 | 2 | しゅん | 2 | 涼 | 2 | れい | 2 | うらら | 2 | 萌 | 2 | さら | 2 | ゆり | 2 | きら | 2 |
| 90期代 | りょう | 5 | れい | 5 | 輝 | 3 | 凜 | 3 | ゆう | 3 | 玲央 | 3 | ゆめ | 3 | みらい | 3 | 蘭 | 3 | 舞 | 3 |
| 100期代 | さくら | 3 | みら | 2 | りり | 2 | 雅 | 2 | ゆう | 2 | れん | 2 | 陽 | 2 | くらら | 2 | 涼 | 2 | 凜 | 2 |
これも全般的に重複は減っている。そこは詳しくはこの後のユニーク率で見ればいいか。
1期代から20期代の××子がすごい。それだけ定番の名前だったという事か。
30期からチラホラひらがな名が増え、50期代は全てひらがな名、70期以降は漢字名も復権するが、一文字名になっている。
ひらがな名、バリエーションは多いが、ここでも着目はやはり100期。
90期以前のひらがな名は、漢字を開いたものが多い。例えば、「りょう」は「涼」などの開きだろう。「れい」は「礼」など。
対して100期は漢字が当たらないひらがな名が多い。「みら」「りり」「くらら」が当たる。漢字を当てるのはできるだろうし、字面も思いつくが、日本人っぽくない。
なお100期以前でも、「さら」、「玲央」などは同様に日本人らしくない名前である。
読み仮名/姓
| 名前 | 1位 | 2位 | 3位 | 4位 | 5位 | 6位 | 7位 | 8位 | 9位 | 10位 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1期代 | あきた | 2 | なら | 2 | まつほ | 2 | せきもり | 2 | まつやま | 2 | わかな | 2 | いずみ | 1 | あまつ | 1 | ありあけ | 1 | はつせ | 1 |
| 10期代 | おじま | 3 | たかやま | 2 | やえ | 2 | みむろ | 2 | やまの | 2 | やまと | 2 | はまの | 2 | いずみ | 2 | すま | 2 | さくらい | 2 |
| 20期代 | あけぼの | 4 | みなみ | 4 | あき | 3 | やしま | 3 | みやま | 3 | みずき | 3 | はるな | 3 | ふじ | 3 | やまと | 3 | みやぎ | 2 |
| 30期代 | まき | 3 | たちばな | 3 | みやま | 3 | むらさき | 3 | つきしろ | 3 | よしの | 3 | おおみ | 2 | ゆり | 2 | まり | 2 | かすが | 2 |
| 40期代 | ふじ | 5 | しらかわ | 4 | その | 4 | みなみ | 4 | やしろ | 3 | あずま | 3 | まり | 3 | まき | 3 | はま | 3 | ちなみ | 3 |
| 50期代 | まり | 4 | あき | 4 | しま | 4 | なつ | 3 | わか | 3 | ほうじょう | 3 | くれない | 3 | ゆみ | 3 | たき | 3 | じょう | 3 |
| 60期代 | はるの | 3 | ゆうき | 2 | よう | 2 | ひめ | 2 | まち | 2 | わかな | 2 | みや | 2 | あそう | 2 | りか | 2 | いちじょう | 2 |
| 70期代 | あい | 2 | あかね | 2 | すずな | 2 | ふたば | 2 | しづき | 2 | おおぞら | 2 | ゆうき | 2 | ゆう | 2 | みち | 2 | たからぎ | 2 |
| 80期代 | あやね | 2 | せん | 2 | みなほ | 2 | あおみ | 2 | ななみ | 2 | ゆうき | 2 | はるか | 2 | ゆめさき | 2 | さわき | 2 | みや | 2 |
| 90期代 | はなき | 2 | きづき | 2 | うらら | 2 | ななせ | 2 | おうか | 2 | あまき | 2 | しざき | 2 | そうま | 2 | かな | 2 | あさひ | 2 |
| 100期代 | おとか | 2 | らん | 1 | れあき | 1 | かずま | 1 | こはる | 1 | かせ | 1 | あきと | 1 | あおかぜ | 1 | みずしろ | 1 | はなと | 1 |
これもあまり語ることはない。と思ったが、…これ姓のよみだよな?
ほとんど名前…一見、自分のプログラムミスを疑う程度には。
読み仮名/名
| 名前 | 1位 | 2位 | 3位 | 4位 | 5位 | 6位 | 7位 | 8位 | 9位 | 10位 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1期代 | きみこ | 2 | やえこ | 2 | みちこ | 2 | さよこ | 2 | もしほ | 2 | さきこ | 2 | なみこ | 2 | ちどり | 2 | つきこ | 2 | おとわこ | 1 |
| 10期代 | ようこ | 8 | たかこ | 5 | なみこ | 5 | みなこ | 5 | ひさこ | 4 | うらこ | 4 | あきこ | 4 | きよこ | 4 | ひでこ | 4 | せきこ | 4 |
| 20期代 | れいこ | 15 | ようこ | 15 | みやこ | 13 | あきこ | 11 | きょうこ | 11 | きみこ | 10 | みちこ | 9 | てるこ | 9 | たえこ | 8 | よしこ | 8 |
| 30期代 | みどり | 13 | かおる | 11 | ようこ | 11 | けいこ | 9 | れいこ | 9 | きょうこ | 8 | あけみ | 7 | よしこ | 7 | ゆかり | 7 | みゆき | 6 |
| 40期代 | ようこ | 14 | みどり | 14 | みちよ | 11 | きょうこ | 11 | ひろみ | 10 | かおり | 10 | まり | 10 | ひかる | 9 | かおる | 9 | けいこ | 9 |
| 50期代 | かおる | 16 | ひかる | 11 | まり | 11 | みき | 10 | じゅん | 8 | のぼる | 8 | あきら | 7 | ゆき | 7 | ゆか | 7 | ゆたか | 7 |
| 60期代 | じゅん | 10 | かおる | 6 | ゆう | 6 | あい | 6 | まき | 5 | みゆき | 5 | ひかる | 5 | まり | 5 | れい | 4 | なつき | 4 |
| 70期代 | ゆう | 11 | みき | 9 | ひとみ | 8 | まり | 7 | あい | 7 | ゆき | 7 | かおる | 7 | まい | 7 | ゆうき | 6 | れい | 6 |
| 80期代 | りん | 4 | れい | 3 | りょう | 3 | れいか | 3 | ひかる | 3 | まい | 3 | かほ | 3 | きら | 2 | けいか | 2 | さら | 2 |
| 90期代 | れい | 8 | りょう | 7 | じゅん | 7 | ゆう | 5 | れお | 4 | みつき | 4 | ひかる | 4 | らん | 4 | まき | 4 | ゆうり | 3 |
| 100期代 | ゆうき | 5 | よう | 4 | はな | 4 | りん | 4 | ゆう | 4 | ひめか | 3 | しゅん | 3 | けい | 3 | さくら | 3 | みお | 3 |
全般的に重複は減っており、また××子が見られなくなった50期以降は、バリエーションが多い。
年代で共通しているのは、「かおる」「まり」「ゆう」などだろうか。
ここ20年人気だった、「れい」「りょう」が100期でなくなり、新規の読みが増えている。
ユニーク率
これはmatplotlibでグラフにする。
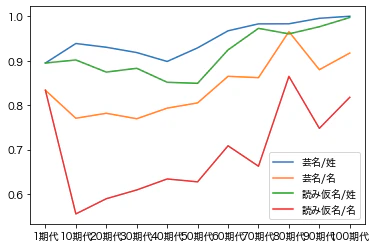
全般的に姓のほうがユニーク性が高い。またユニーク率は上昇傾向にある。個性化が進んでいるのが見てとれる。
1期代の名前がユニーク性が高いのは少人数のため、重複が少なかったものと思われる。
80期代は名前が際立ってユニーク率が高い。
80期代は、1992〜2001年音楽学校入学、1994〜2003年入団。15〜18歳が入学資格なので、1974年〜86年生まれの女性にあたる。一般に団塊ジュニアが74年までをいうので、その後の世代になる。明日海りおさんが89期で数年前までトップスターをされていたので、最近の人の感覚がある。
89期も専科の凪七瑠海を除き、全員退団済みになる。
個性を思い切り前面に押し出したのがこの世代なのかもしれない。
解析を終えて
流石にキリがないので、解析は今回で終え、次回からAIの作成に入る。
まず、GPT-2をファインチューニングして、ヅカの芸名を自動生成するのを第一段階。
第二段階は解析器の作成や生成をKerasなどで試してみたいと思う。
ただ、学習のベースにするのは、これまでの解析結果を踏まえ、80期代以降に変更しようと思う。
サンプル数が単純に増えるのもあるが、十分現代的な芸名をつけていると判断した。