社内にあるルータやスイッチなどのsnmpしかないネットワーク機器をCloudWatchで監視したい欲求にかられてやってみたので設定方法のまとめです。
TL;DR
VPNなどでVPCと直接つながっていないsnmp機器をCollectdとCloudWatch Agent 経由でCloudWatchにデータを投げて、メトリクスをグラフにします。
もう一度試す気力がないので設定した際の記録をもとに書いています。
collectdはデータ収集ツールです。グラフを描画する機能はありません。
https://collectd.org
前提
- AWSのVPCと直接つながっていない。
- 踏み台にできるマシンがある。
- 複数のネットワーク機器を1台の踏み台を経由してCloudWatchにポイポイする。
踏み台サーバの準備
collectdのインストール
collectdとsnmp pluginをインストールします。centos7を利用していて下記をインストールしました。
collectd-snmp-5.8.1-1.el7.x86_64
collectd-5.8.1-1.el7.x86_64
こちらEC2へのインストールですが、参考になります。https://dev.classmethod.jp/cloud/aws/collectd-cloudwatch/
CloudWatch AgentでCollectdを有効にする。
踏み台サーバのCloudWatch Agent のCollectdを有効にします。
ウィザードを使ってもいいですし、設定ファイルをいじってもいいです。とりあえず踏み台サーバ自身のメトリクスがCloudWatchにあがるところまで確認しておいてください。
意外としくったりします。
参考) https://qiita.com/murata-tomohide/items/3e66d63b21c08d6481a2
Collectd CloudWatch Pluginをインストールする。
CollectdからデータをCloudWatchに流すためのプラグインを入れます。
git clone してsetup.pyを動かします。
collectd.confにsnmp設定追加
/etc/collectd.conf で↓のディレクトリを読むようにして、ディレクトリ配下にsnmp.confを置きました。
上のsetup.pyが/etc/collectd.confをいじるので注意してください。
~snip
# </Plugin>
Include "/etc/collectd-cloudwatch.conf"
Include "/etc/collectd.d/"
LoadPlugin snmp
<Plugin snmp>
# <Data "powerplus_voltge_input">
# Type "voltage"
~snip
# ORESW006
<Data "uptime_ORESW006">
Type "uptime"
Table false
Instance "ORESW006-UPTIME"
Values "DISMAN-EVENT-MIB::sysUpTimeInstance"
</Data>
<Data "std_traffic_ORESW006">
Type "if_octets"
Table true
InstancePrefix "ORESW006-"
Instance "IF-MIB::ifDescr"
Values "IF-MIB::ifInOctets" "IF-MIB::ifOutOctets"
</Data>
<Data "std_errors_ORESW006">
Type "if_errors"
Table true
InstancePrefix "ORESW006-"
Instance "IF-MIB::ifDescr"
Values "IF-MIB::ifInErrors" "IF-MIB::ifOutErrors"
</Data>
<Data "std_discards_ORESW006">
Type "if_dropped"
Table true
InstancePrefix "ORESW006-"
Instance "IF-MIB::ifDescr"
Values "IF-MIB::ifInDiscards" "IF-MIB::ifOutDiscards"
</Data>
<Host "ORESW006.netgear">
Address "192.168.0.6"
Version 2
Community "onesatoshi"
Collect "uptime_ORESW006" "std_traffic_ORESW006" "std_errors_ORESW006" "std_discards_ORESW006"
Interval 60
Timeout 10
Retries 1
</Host>
どんな値があるのか確認するにはsnmpwalkなどでMIBを調べます。 snmpwalk -v 2c -c oregaichiban 192.168.0.6 system とか。
InstancePrefix でわざわざ機器名を指定しているのは、後述のwhitelistに記述する際にどの機器のメトリクスか判別できないので、めんどくさいですがやっておいたほうがいいです。
今回10台ぐらいのルータやスイッチを設定したのですが、3台目ぐらいからわけわかめになります。
設定し終わったらsystemctl restart collectd.serviceをしてください。
CloudWatchにぶん投げるデータを選定 whitelistを調整
今のままだと、CloudWatchのpluginによって、データがせき止められているので、CloudWatchに流すデータを指定してあげます。
具体的には /opt/collectd-plugins/cloudwatch/config/blocked_metrics にリストが入っていますので、必要そうなデータを /opt/collectd-plugins/cloudwatch/config/whitelist.conf にコピーします。
~snip
snmp--if_octets-ORESW006-lag 3.tx
snmp--if_octets-ORESW006-lag 4.rx
snmp--if_octets-ORESW006-lag 4.tx
snmp--if_octets-ORESW006-lag 5.rx
snmp--if_octets-ORESW006-lag 5.tx
snmp--if_errors-ORESW006-1 Gigabit - Level.rx
snmp--if_errors-ORESW006-1 Gigabit - Level.tx
snmp--if_errors-ORESW006-2 Gigabit - Level.rx
snmp--if_errors-ORESW006-2 Gigabit - Level.tx
snmp--if_errors-ORESW006-3 Gigabit - Level.rx
snmp--if_errors-ORESW006-3 Gigabit - Level.tx
snmp--if_errors-ORESW006-4 Gigabit - Level.rx
snmp--if_errors-ORESW006-4 Gigabit - Level.tx
snmp--if_errors-ORESW006-5 Gigabit - Level.rx
snmp--if_errors-ORESW006-5 Gigabit - Level.tx
snmp--if_errors-ORESW006-6 Gigabit - Level.rx
snmp--if_errors-ORESW006-6 Gigabit - Level.tx
snmp--if_errors-ORESW006-7 Gigabit - Level.rx
snmp--if_errors-ORESW006-7 Gigabit - Level.tx
snmp--if_errors-ORESW006-8 Gigabit - Level.rx
snmp--if_errors-ORESW006-8 Gigabit - Level.tx
snmp--if_errors-ORESW006-9 Gigabit - Level.rx
snmp--if_errors-ORESW006-9 Gigabit - Level.tx
snmp--if_errors-ORESW006-10 Gigabit - Level.rx
snmp--if_errors-ORESW006-10 Gigabit - Level.tx
snmp--if_errors-ORESW006-lag 1.rx
snmp--if_errors-ORESW006-lag 1.tx
snmp--if_errors-ORESW006- CPU Interface for Slot: 3 Port: 1.rx
snmp--if_errors-ORESW006- CPU Interface for Slot: 3 Port: 1.tx
snmp--if_errors-ORESW006-lag 2.rx
snmp--if_errors-ORESW006-lag 2.tx
snmp--if_errors-ORESW006-lag 3.rx
snmp--if_errors-ORESW006-lag 3.tx
snmp--if_errors-ORESW006-lag 4.rx
snmp--if_errors-ORESW006-lag 4.tx
snmp--if_errors-ORESW006-lag 5.rx
snmp--if_errors-ORESW006-lag 5.tx
snmp--if_dropped-ORESW006-1 Gigabit - Level.rx
snmp--if_dropped-ORESW006-1 Gigabit - Level.tx
snmp--if_dropped-ORESW006-3 Gigabit - Level.rx
snmp--if_dropped-ORESW006-3 Gigabit - Level.tx
snmp--if_dropped-ORESW006-lag 4.rx
snmp--if_dropped-ORESW006-lag 4.tx
snmp--if_dropped-ORESW006-7 Gigabit - Level.rx
snmp--if_dropped-ORESW006-7 Gigabit - Level.tx
snmp--if_dropped-ORESW006-5 Gigabit - Level.rx
snmp--if_dropped-ORESW006-5 Gigabit - Level.tx
snmp--if_dropped-ORESW006-8 Gigabit - Level.rx
snmp--if_dropped-ORESW006-8 Gigabit - Level.tx
snmp--if_dropped-ORESW006-4 Gigabit - Level.rx
snmp--if_dropped-ORESW006-4 Gigabit - Level.tx
~snip
こんな感じで入ってきますので、whitelist.conf に書いていきます。この時にPrefixがついていないとわけわかめになるんですよ。
正規表現が使えるので楽ですね。
~snip
# ORESW006
snmp--uptime-ORESW006-UPTIME
snmp--if_octets-ORESW006-[0-9].*
snmp--if_dropped-ORESW006-[0-9].*
snmp--if_errors-ORESW006-[0-9].*
~snip
拾ったものをすべて流す設定もあります。setup.pyを実行する際に‘whitelist_pass_through ‘って項目があったかとおもいますが、それをtrueにすれば全部ぶん投げます。
※10,000メトリクスまで月額$0.3/metricです。金額に注意しましょう。
ちなみにその辺のconfは /opt/collectd-plugins/cloudwatch/config/plugin.conf ですhostの項目が設定されていたら空欄にしましょう。(CloudWatchのHost部分にsnmpのhostが表示されるようになります。)
CloudWatchのグラフを作成
↑の設定がちゃんとできていれば、CloudWatchにデータが流れてきていると思います。メトリクスを確認してみてください。
こんな感じですべてのメトリクスにcollectdって項目ができていると思います。
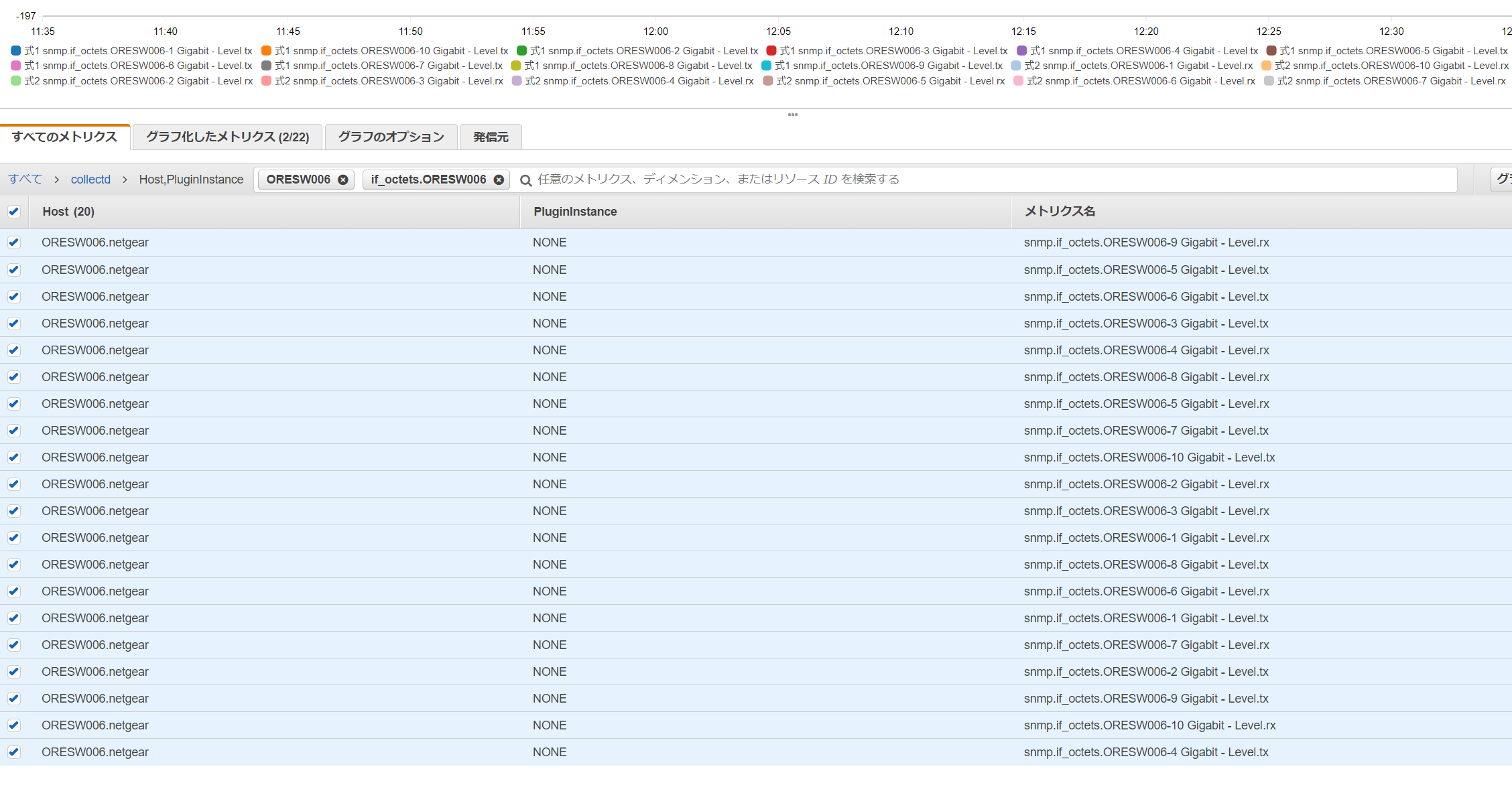
スイッチのメトリクスを選択
例としてスイッチのトラフィックをグラフにしてみましょう。
if_octetsのtxとrxを拾います。
Metric Mathで調整
Metric Mathを使ってrxは負の値にします。このままだとbit per sec なので8で割ってbyteにしてみます。
まだデータが取れていないのでこれで計算が合っているのかよくわかっていません。どなたかヘルプ!
RATE(SEARCH('{collectd,Host,PluginInstance} Host="ORESW006.netgear" if_octets.ORESW006 tx', 'Average', 300)) / 8
-(RATE(SEARCH('{collectd,Host,PluginInstance} Host="ORESW006.netgear" if_octets.ORESW006 rx', 'Average', 300)) / 8)
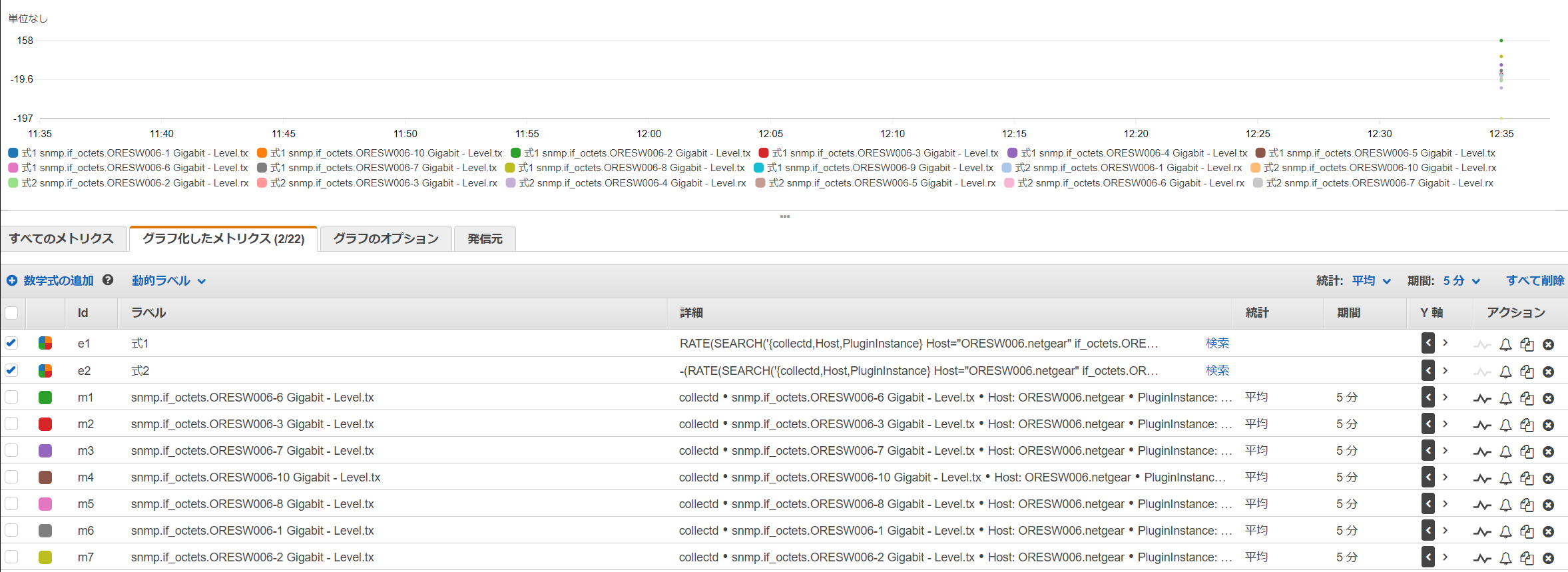
あとはグラフのオプションなどのラベルを調整したりしてダッシュボードに追加してください。
入れすぎるとダッシュボードに入れすぎ!って怒られるので注意です。
まとめ
ストレージを気にしなくていい。
こーいうののモニタリングサーバを自前で持つと結構なストレージ容量が必要になってくるのですが、踏み台はawsにデータをぶん投げているだけなのであまり気にする必要ありません。
踏み台サーバの負荷が結構低くてうれしい。
collectdが優秀なのか、1000メトリクス超えてもCPU負荷は3-5%ぐらいでした。Intel(R) Xeon(R) CPU E3-1241 v3 @ 3.50GHz
メモリもほとんど使っていません。
snmpのCloudWatchのプラグインがいまいち
whitelistの関係上、Collectdのsnmpプラグインでホストごとに取得する項目を書かないといけないので設定ファイルがでかくなってしまいます。
まったく同じ製品が結構な量あるって場合には1か所に書いてもいいかもしれませんが、寄せ集めてきな感じだとつらいです。
取得できるもの全部上げるわけにいかない。
お金とかの問題。でも1000メトリクスで月額$300ぐらい。スイッチだと1ポートにつきrx, tx, dropped, errorsとなる。
~utとかリクエストの金額は誤差だけど。。。1メトリクスあたりで課金って思うと必要なものだけ上げたくなるよね。
最初は請求をこまめにチェックしましょう。
AmazonCloudWatch APN1-TimedStorage-ByteHrs
$0.033 per GB-mo of log storage - Asia Pacific (Tokyo)
データの保持期間がCloudWatch依存になる
メトリクスの保持
昔は14日で消えていましたが、今はMAX455日間保持してくれます。(徐々に細かいデータは消えていく感じ)
保持されたデータをDL等することはできなさそうなので、一度使い始めたら移行期間は併用するしかないためしばらくはロックインされます。
CloudWatch には、メトリクスデータが次のように保持されます。
期間が 60 秒未満のデータポイントは、3 時間使用できます。これらのデータポイントは高解像度カスタムメトリクスです。
期間が 60 秒 (1 分) のデータポイントは、15 日間使用できます。
期間が 300 秒 (5 分) のデータポイントは、63 日間使用できます。
期間が 3600 秒 (1 時間) のデータポイントは、455 日 (15 か月) 間使用できます。最初は短い期間で発行されるデータポイントは、長期的なストレージのため一緒に集計されます。たとえば、1 分の期間でデータを収集する場合、データは 1 分の解像度で 15 日にわたり利用可能になります。15 日を過ぎてもこのデータはまだ利用できますが、集計され、5 分の解像度のみで取得可能になります。63 日を過ぎるとこのデータはさらに集計され、1 時間の解像度のみで利用できます。
CloudWatch は、2016 年 7 月 9 日の時点で 5 分および 1 時間のメトリクスデータを保持し始めました。
まだ試し始めて間もないためわかっていない部分もありますが、とりあえずこんな感じでした。
View部分はgrafanaとか別のツールを使ったほうがいい気がしているこの頃。
(だったらPrometheusでsnmp-exporterでいいのでは?あれ?あれれ?)