大学の3年から大学院でPython使って個人事業主でもPython使っていて思うのが「これ作っておくと便利だな」と思った関数が何個かあるので紹介します。
というか自分の備忘録でもあります。
※なお、この記事は思い付きで書いていますので思い立った時に更新します。
JSONの自動解析
正確には辞書型配列(連想配列)を自動的に解析する関数です。
やり方としては再帰アルゴリズムを応用した深さ優先探索で辞書・リストじゃないデータまで探索して、キーを表示するものです。
def depth(jsn, var=""):
if isinstance(jsn, dict):
for row in jsn:
depth(jsn[row], var=var+"[\""+row+"\"]")
elif isinstance(jsn, list) and jsn != []:
for i in range(len(jsn)):
depth(jsn[i], var=var+"["+str(i)+"]")
else:
print(var+"="+str(jsn))
pass
使用例
import json
import requests
url = "https://www.jma.go.jp/bosai/forecast/data/forecast/130000.json"
res = requests.get(url)
data = json.loads(res.text)
depth(data, "data") #深さ優先探索
print()
data[0]["publishingOffice"]=気象庁
data[0]["reportDatetime"]=2024-04-17T17:00:00+09:00
data[0]["timeSeries"][0]["timeDefines"][0]=2024-04-17T17:00:00+09:00
data[0]["timeSeries"][0]["timeDefines"][1]=2024-04-18T00:00:00+09:00
data[0]["timeSeries"][0]["timeDefines"][2]=2024-04-19T00:00:00+09:00
data[0]["timeSeries"][0]["areas"][0]["area"]["name"]=東京地方
data[0]["timeSeries"][0]["areas"][0]["area"]["code"]=130010
data[0]["timeSeries"][0]["areas"][0]["weatherCodes"][0]=200
data[0]["timeSeries"][0]["areas"][0]["weatherCodes"][1]=212
data[0]["timeSeries"][0]["areas"][0]["weatherCodes"][2]=101
<中略>
data[1]["precipAverage"]["areas"][0]["min"]=11.5
data[1]["precipAverage"]["areas"][0]["max"]=30.9
data[1]["precipAverage"]["areas"][1]["area"]["name"]=八丈島
data[1]["precipAverage"]["areas"][1]["area"]["code"]=44263
data[1]["precipAverage"]["areas"][1]["min"]=28.3
data[1]["precipAverage"]["areas"][1]["max"]=58.3
data[1]["precipAverage"]["areas"][2]["area"]["name"]=父島
data[1]["precipAverage"]["areas"][2]["area"]["code"]=44301
data[1]["precipAverage"]["areas"][2]["min"]=7.6
data[1]["precipAverage"]["areas"][2]["max"]=28.1
包括的な効果測定
効果検証は因果推論をする上で必要な内容で、質的データでデータの群をまとめて、そこから平均値の差を求めたり分布の違いを考察して原因と結果や交絡を明らかにします。
def effecttest(df, columns, y_name):
ave = []
dtr = []
pos = []
lab = []
x = 0
for col in columns:
values = list(set(df[col].values))
tmp_ave = []
tmp_dtr = []
tmp_pos = []
tmp_lab = []
for val in values:
df_tmp = df[df[col]==val]
tmp_ave.append(df_tmp[y_name].mean())
tmp_dtr.append(df_tmp[y_name])
tmp_pos.append(x)
tmp_lab.append(col+"_"+str(val))
x = x + 1
ave.append(tmp_ave)
dtr.append(tmp_dtr)
pos.append(tmp_pos)
lab.append(tmp_lab)
return ave, dtr, pos, lab
使用例
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import scipy.stats as stats
df = pd.read_csv("rossi2.csv")
columns = []
for col in df.columns:
if col != "prio":
columns.append(col)
ave, dtr, pos, lab = effecttest(df, columns, "prio")
for i in range(len(dtr)):
plt.boxplot(dtr[i], positions=pos[i], labels=lab[i])
plt.plot(pos[i], ave[i], marker="x")
plt.xticks(rotation=90)
plt.show()
for i in range(len(dtr)):
print(columns[i])
f, p = stats.bartlett(dtr[i][0], dtr[i][1])
if (2 * p) <= 0.05:
t, p = stats.ttest_ind(dtr[i][0], dtr[i][1], equal_var=False)
else:
t, p = stats.ttest_ind(dtr[i][0], dtr[i][1], equal_var=True)
print("t = %f"%(t))
print("p = %f"%(p))
print("val = %f"%(ave[i][0]-ave[i][1]))
print()

arrest
t = -2.931893
p = 0.003877
val = -1.070672
fin
t = 0.016594
p = 0.986768
val = 0.004630
race
t = 1.871865
p = 0.061904
val = 0.792702
wexp
t = 5.252460
p = 0.000000
val = 1.522070
mar
t = 0.614361
p = 0.539302
val = 0.261114
paro
t = 2.479255
p = 0.013753
val = 0.751856
包括的な効果測定(自動版)
今度は図示や各因子で平均値の比較やt値、p値の算出まで行います。
import scipy.stats as stats
import matplotlib.pyplot as plt
def effecttest2(df, columns, y_name, auto=False):
ave = []
dtr = []
pos = []
lab = []
x = 0
for col in columns:
values = list(set(df[col].values))
tmp_ave = []
tmp_dtr = []
tmp_pos = []
tmp_lab = []
for val in values:
df_tmp = df[df[col]==val]
tmp_ave.append(df_tmp[y_name].mean())
tmp_dtr.append(df_tmp[y_name])
tmp_pos.append(x)
tmp_lab.append(col+"_"+str(val))
x = x + 1
ave.append(tmp_ave)
dtr.append(tmp_dtr)
pos.append(tmp_pos)
lab.append(tmp_lab)
if auto:
for i in range(len(dtr)):
for j in range(len(dtr[i])):
for k in range(j, len(dtr[i])):
if j != k:
f, p = stats.bartlett(dtr[i][0], dtr[i][1])
if (2 * p) <= 0.05:
t, p = stats.ttest_ind(dtr[i][j], dtr[i][k], equal_var=False)
else:
t, p = stats.ttest_ind(dtr[i][j], dtr[i][k], equal_var=True)
print(lab[i][j], lab[i][k])
print("t = %f"%(t))
print("p = %f"%(p))
print("val = %f"%(ave[i][j]-ave[i][k]))
print()
for i in range(len(dtr)):
plt.boxplot(dtr[i], positions=pos[i], labels=lab[i])
plt.plot(pos[i], ave[i], marker="x")
plt.xticks(rotation=90)
plt.show()
return ave, dtr, pos , lab
使用例
import pandas as pd
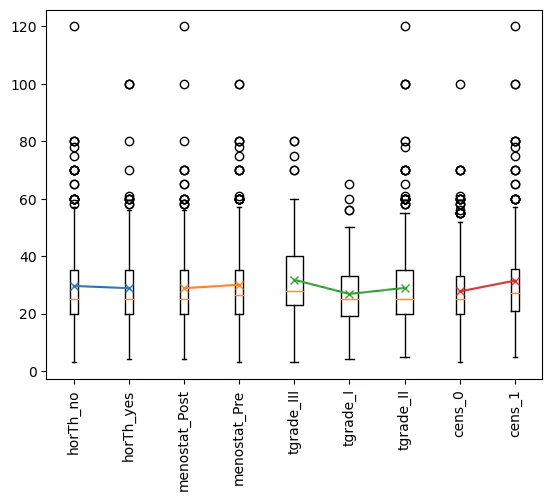
df = pd.read_csv("gbsg2.csv")
ave, dtr, pos, lab = effecttest2(df, ["horTh", "menostat", "tgrade", "cens"], "tsize", auto=True)
horTh_no horTh_yes
t = 0.718341
p = 0.472793
val = 0.817849
menostat_Post menostat_Pre
t = -1.078167
p = 0.281413
val = -1.215378
tgrade_III tgrade_I
t = 2.697732
p = 0.007477
val = 4.911970
tgrade_III tgrade_II
t = 2.119908
p = 0.034422
val = 2.826968
tgrade_I tgrade_II
t = -1.204302
p = 0.229018
val = -2.085002
cens_0 cens_1
t = -3.366996
p = 0.000811
val = -3.773439
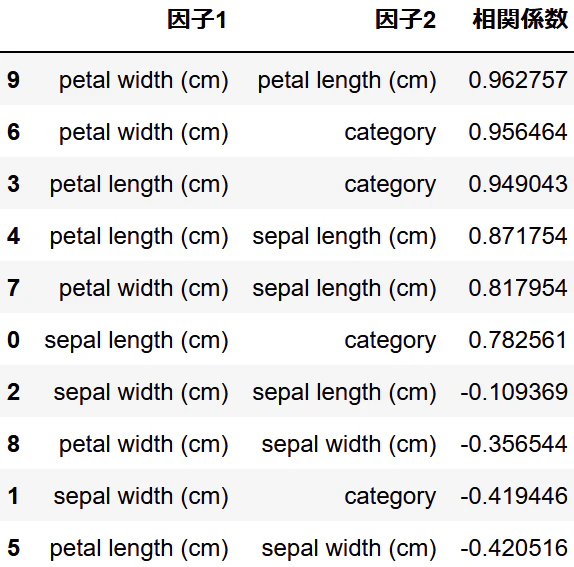
相関係数の順番
相関行列は簡単に出せますが、それだと昇順降順が分からないため相関の強さの順序が一目では分かりません。
そこで相関行列から相関係数と因子のデータフレームを作ります。
import pandas as pd
def corr_sort(df):
corr = df.corr().values
dst = []
for i in range(0, len(df.corr().columns)):
for j in range(0, i):
if i != j:
dst.append([df.corr().columns[i], df.corr().columns[j], corr[i][j]])
df_corr = pd.DataFrame(dst)
df_corr.columns = ["因子1", "因子2", "相関係数"]
return df_corr.sort_values("相関係数", ascending=False)
使用例
import pandas as pd
df = pd.read_csv("iris.csv")
df_corr = corr_sort(df)
df_corr
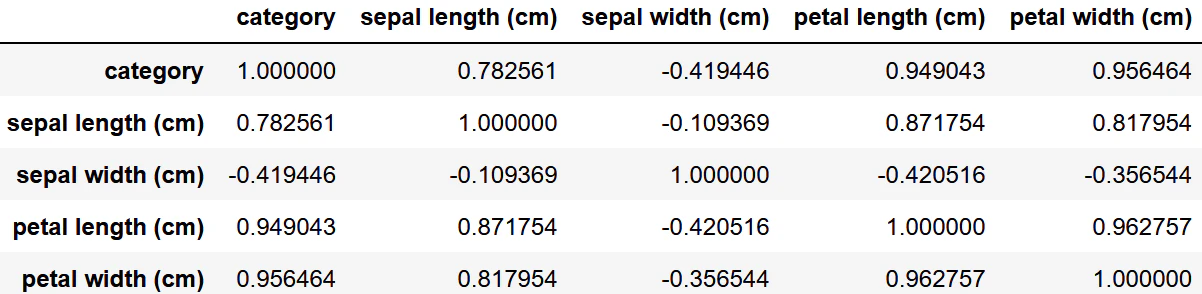
df.corr()
偏相関係数
偏相関係数はある相関係数について第三の因子を用いて第三の因子を考慮した上で計算される相関係数で、疑似相関を検証する際に使うことができます。
数式としては以下のようになっています。
r_{xy・z}=\frac{r_{xy} - r_{yz} \times r_{xz}}{{\sqrt{1 - r_{yz}^2}\times\sqrt{1 - r_{xz}^2}}}
import pandas as pd
import numpy as np
def pcorr(df):
pcor = []
corr = df.corr()
columns = df.corr().columns
for i in range(len(columns)):
for j in range(i+1, len(columns)):
for k in range(len(columns)):
if columns[i] != columns[k] and columns[j] != columns[k]:
xy = corr.loc[columns[i], columns[j]]
yz = corr.loc[columns[j], columns[k]]
zx = corr.loc[columns[k], columns[i]]
pc = (xy - yz * zx) / (np.sqrt(1-yz**2) * np.sqrt(1-zx**2))
pcor.append([columns[i],
columns[j],
columns[k],
corr.loc[columns[i], columns[j]],
pc,
abs(corr.loc[columns[i], columns[j]]-pc)])
df_pcor = pd.DataFrame(pcor)
df_pcor.columns = ["因子1", "因子2", "第三の因子", "相関係数", "偏相関係数", "偏相関係数と相関係数の差"]
return df_pcor
使用例
import pandas as pd
import numpy as np
df = pd.read_csv("boston.csv")
df_pcor = pcorr(df)
df_pcor.sort_values("偏相関係数と相関係数の差", ascending=False)

regression_report
分類ではclassification_reportがあるのに対して回帰にはそれらしいものが無かったので作りました。補正R2は以下の記事を参考にしました。
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_squared_log_error
import numpy as np
def adjr2_score(y_test, y_pred, x):
return 1 - (1 - r2_score(y_test, y_pred)) * (len(y_test) - 1) / (len(y_test) - len(x.columns) - 1)
def regression_report(y_test, y_pred, x):
print("R2 : %f"%(r2_score(y_test, y_pred)))
print("adjR2 : %f"%(adjr2_score(y_test, y_pred, x)))
print("MSE : %f"%(mean_squared_error(y_test, y_pred)))
print("RMSE : %f"%(np.sqrt(mean_squared_error(y_test, y_pred))))
try:
print("RMSLE : %f"%(np.sqrt(mean_squared_log_error(y_test, y_pred, squared=False))))
except:
_ = 0
print("MAE : %f"%(mean_absolute_error(y_test, y_pred)))
pass
使用例
import pandas as pd
import statsmodels.api as sm
df = pd.read_csv("boston.csv")
y = df["PRICE"]
x = df.drop("PRICE", axis=1)
model1 = sm.OLS(y, x).fit()
y_pred1 = model1.predict(x)
regression_report(y, y_pred1, x)
R2 : 0.713738
adjR2 : 0.706174
MSE : 24.166099
RMSE : 4.915903
MAE : 3.286734
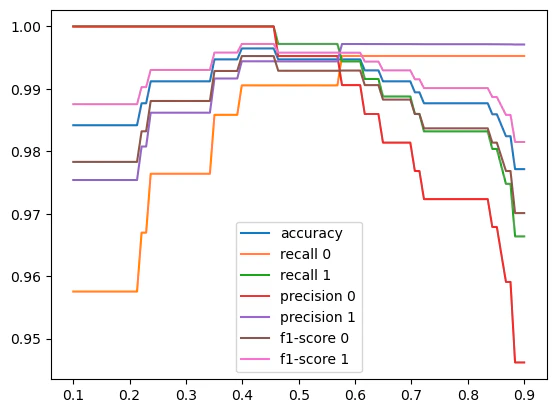
二値分類の最適なしきい値探索
二値分類は基本的に0.5を境に陽性と陰性を決めているが、必ずしもそれがベストとは限らない。
そこで最適なしきい値を考察する材料を提供する関数として各指標の図示とそ指標における最適なしきい値を返り値にする。
from sklearn.metrics import classification_report
import numpy as np
import matplotlib.pyplot as plt
def optimal_threshold(y, pred, n="0.0", p="1.0"):
tsd = np.linspace(0.1, 0.9, 100)
accs = []
rec0 = []
rec1 = []
pcs0 = []
pcs1 = []
f1_0 = []
f1_1 = []
for i in range(len(tsd)):
y_pred = np.where(pred >= tsd[i], 1, 0)
rep = classification_report(y, y_pred, output_dict=True)
accs.append(rep["accuracy"])
rec0.append(rep[n]["recall"])
rec1.append(rep[p]["recall"])
pcs0.append(rep[n]["precision"])
pcs1.append(rep[p]["precision"])
f1_0.append(rep[n]["f1-score"])
f1_1.append(rep[p]["f1-score"])
plt.plot(tsd, accs, label="accuracy")
plt.plot(tsd, rec0, label="recall 0")
plt.plot(tsd, rec1, label="recall 1")
plt.plot(tsd, pcs0, label="precision 0")
plt.plot(tsd, pcs1, label="precision 1")
plt.plot(tsd, f1_0, label="f1-score 0")
plt.plot(tsd, f1_1, label="f1-score 1")
plt.legend()
plt.show()
return tsd[np.argmax(accs)], tsd[np.argmax(rec0)], tsd[np.argmax(rec1)], tsd[np.argmax(pcs0)], tsd[np.argmax(pcs1)], tsd[np.argmax(f1_0)], tsd[np.argmax(f1_1)]
使用例
import pandas as pd
import statsmodels.api as sm
df = pd.read_csv("breast_cancer.csv")
y = df["y"]
x = df.drop("y", axis=1)
for col in x.columns:
x[col] = (x[col] - x[col].mean()) / x[col].std()
model = sm.Logit(y, x).fit_regularized()
otp = optimal_threshold(y, model.predict(x), n="0.0", p="1.0")
otp
(0.398989898989899,
0.5767676767676768,
0.1,
0.1,
0.5767676767676768,
0.398989898989899,
0.398989898989899)
予測を間違ったデータ一覧のデータセット
機械学習を使う上で精度を上げるのは重要です、ただその上でどのような間違え方をしているか分かるとデータの特徴・類似性が分かります。実際Scikit-Learnではmodelの変数に「.predict_proba(説明変数のリアルデータ)」を入れると何%の確率でそう予測したかが出るようになっています。
import pandas as pd
def miss_pred(y_test, y_pred, model):
miss = []
y_predSM = model.predict_proba(x_test)
for i in range(len(y_test)):
if y_test[i] != y_pred[i]:
miss.append([i, y_test[i], y_pred[i], max(y_predSM[i])])
df_miss = pd.DataFrame(miss)
df_miss.columns = ["ID", "real", "predict", "probably"]
return df_miss
使用例
from sklearn.datasets import load_digits
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split as tts
import numpy as np
x = load_digits().data
y = load_digits().target
x = x / max(x.flatten())
x_train, x_test, y_train, y_test = tts(x, y, test_size=0.2, random_state=1)
model = MLPClassifier(hidden_layer_sizes=(500, 1000, 750, 500))
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
df_miss = miss_pred(y_test, y_pred, model)
df_miss.sort_values("probably", ascending=False)
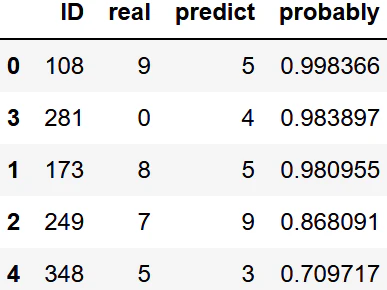
因子負荷量の計算
主成分分析においてどこまで次元を使うか、また圧縮した後どう解釈するかについて累積寄与率と因子負荷量が必要になります。
そこで累積寄与率と因子負荷量のデータフレームを返す関数を実装します。
import pandas as pd
def factor_exp(pca, x):
col = []
for i in range(len(x.columns)):
col.append("第%d主成分"%(i+1))
exp = pca.explained_variance_ratio_
df_exp = pd.DataFrame(exp)
df_exp.index = col
df_exp.columns = ["寄与率"]
df_exp_sum = df_exp.cumsum()
com = pca.components_
fac = []
for i in range(len(exp)):
fac.append(np.sqrt(exp[i])*com[i])
df_fac = pd.DataFrame(fac)
df_fac.columns = x.columns
df_fac.index = col
return df_fac, df_exp_sum
使用例
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
df = pd.read_csv("wine.csv")
y = df["Wine"]
x = df.drop("Wine", axis=1)
for col in x.columns:
x[col] = (x[col] - x[col].mean()) / x[col].std()
pca = PCA()
pca.fit(x)
df_fac, df_exp_sum = factor_exp(pca, x)
df_exp_sum
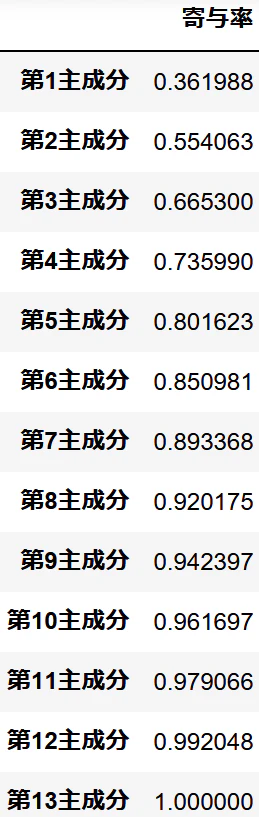
結果から第5主成分までで大丈夫みたいです。
df_fac
第5主成分までキャプチャしました。

tx = pca.transform(x)
tx2 = tx[:, 0:5]
df_tx2 = pd.DataFrame(tx2)
df_tx2.columns = ["PC1", "PC2", "PC3", "PC4", "PC5"]
df_t2 = pd.concat([y, df_tx2], axis=1)
sns.pairplot(df_t2, hue="Wine", palette="Pastel1")
plt.show()

CART分析と因子寄与率
決定木を使うと分類寄与率や回帰寄与率が分かりますし、結果までの過程までも分かるなど原始的ですが分析には非常に優れたアルゴリズムですが、データフレーム化したり(しないと見にくい)、決定木そのものの出力が非常に面倒くさいのでそこを関数化すると楽になります。
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.tree import export_graphviz as EG
from pydotplus import graph_from_dot_data as GFDD
import pandas as pd
def x_importance(x, y, dtc):
imp = dtc.feature_importances_
df_imp = pd.DataFrame(imp)
df_imp.index = x.columns
df_imp.columns = ["var_imp"]
y_data = list(set(y.values))
for i in range(len(y_data)):
y_data[i] = str(y_data[i])
dotdata = EG(dtc,filled=True, rounded=True, class_names=y_data, feature_names=x.columns, out_file=None)
graph = GFDD(dotdata)
graph.write_png("CART.png")
return df_imp
使用例
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.tree import export_graphviz as EG
from pydotplus import graph_from_dot_data as GFDD
import pandas as pd
df = pd.read_csv("iris.csv")
y = df["category"]
x = df.drop("category", axis=1)
dtc = DTC()
dtc.fit(x, y)
df_imp = x_importance(x, y, dtc)
df_imp.sort_values("var_imp", ascending=False)

また、関数内で自動的に決定木の画像が保存されます(もしかしたら保存する時のファイル名もしていしたほうがいいかもしれません)。
それはエクスプローラーやPILを使って見てみるといいかもしれません。

決定境界の描画
元々2次元の説明変数や、主成分分析で圧縮して2次元にしたデータに対して分類アルゴリズムを適用した時にどのように分類されているかを図示して確認するのに役立ちます。
仕組みとしては正規化した二次元平面に対してデータを学習して細かく平面を分割し、分割した場所を予測して色を付けるということです。
from sklearn import preprocessing
from sklearn.機械学習のライブラリ import 機械学習の名前
import matplotlib.pyplot as plt
import numpy as np
def showline_clf(x, y, model, modelname, x0="x0", x1="x1"):
fig, ax = plt.subplots(figsize=(8, 6))
X, Y = np.meshgrid(np.linspace(*ax.get_xlim(), 1000), np.linspace(*ax.get_ylim(), 1000))
XY = np.column_stack([X.ravel(), Y.ravel()])
x = preprocessing.minmax_scale(x)
model.fit(x, y)
Z = model.predict(XY).reshape(X.shape)
plt.contourf(X, Y, Z, alpha=0.1, cmap="brg")
plt.scatter(x[:, 0], x[:, 1], c=y, cmap="brg")
plt.xlim(min(x[:, 0]), max(x[:, 0]))
plt.ylim(min(x[:, 1]), max(x[:, 1]))
plt.title(modelname)
plt.colorbar()
plt.xlabel(x0)
plt.ylabel(x1)
plt.show()
使用例
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn import preprocessing
import matplotlib.pyplot as plt
import numpy as np
showline_clf(x, y, SVC(kernel="linear"), modelname="SVM")

信頼区間の描画
異常検知などでも使われる信頼区間だが、それについて値と描画をする関数
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
def ci_plot(df, per=0.95):
x = 0
for col in df.columns:
var = df[col].var()
mean = df[col].mean()
trange = stats.t(loc=mean, scale=np.sqrt(var/len(df[col].values)), df=len(df[col].values)-1)
low, high = trange.interval(per)
print(col)
print("%f <= z <= %f"%(low, high))
plt.plot([low, high], [x, x], marker="|", color="#000000")
plt.scatter(mean, x, marker="x", color="#000000")
x = x + 1
plt.yticks(np.arange(len(df.columns)), df.columns)
plt.show()
使用例
import pandas as pd
df = pd.read_csv("iris.csv")
ci_plot(df)
category
0.867824 <= z <= 1.132176
sepal length (cm)
5.709732 <= z <= 5.976934
sepal width (cm)
2.984044 <= z <= 3.123956
petal length (cm)
3.473994 <= z <= 4.043340
petal width (cm)
1.075538 <= z <= 1.321796
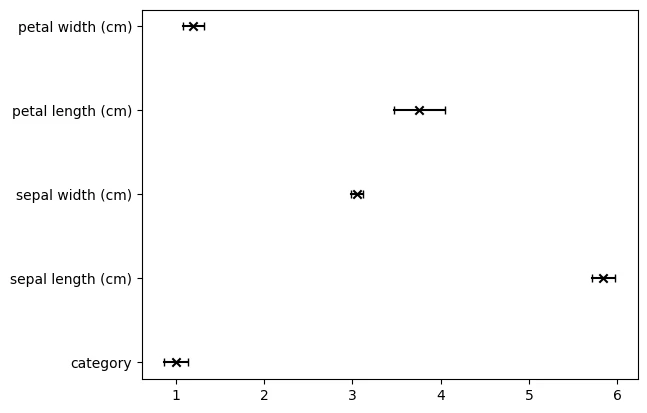
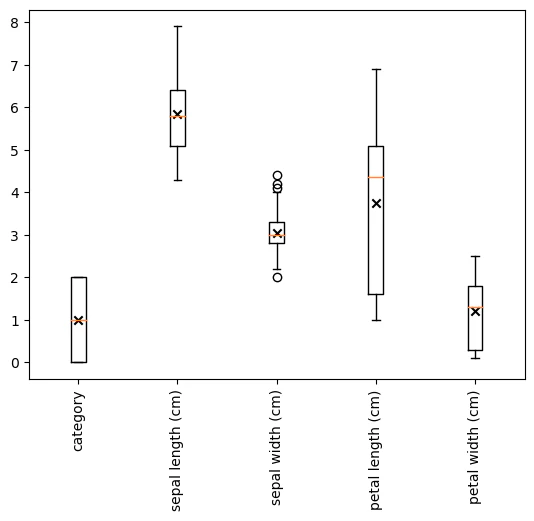
全変数の箱ひげ図(変数が全て量的変数であることが前提)
pandasには「describe()」で要約統計量を出すことができるが、数値だけでは少し分かりにくい。そこで関数化する。
import matplotlib.pyplot as plt
def boxplot(df):
x = 0
for i in range(len(df.columns)):
plt.boxplot(df[df.columns[i]], positions=[x], labels=[df.columns[i]])
plt.scatter(x, df[df.columns[i]].mean(), marker="x", color="#000000")
x = x + 1
plt.xticks(rotation=90)
plt.show()
使用例
import pandas as pd
df = pd.read_csv("iris.csv")
boxplot(df)
参考文献
In-Depth: Decision Trees and Random Forests
機械学習の評価指標とPythonでの実装【回帰編】 #Python - Qiita