作ったプログラム↓
最近転職活動をしていてLightGBMを使う企業みたいで自分も復習に使って見たわけで最近LightGBMを使ってはアウトプットでQiitaに記事を書いていた訳ですが、今回はアウトプットの延長線でSIGNATEをやってみました。
内容はアップル引っ越し需要予測になります。
ただこのデータを見ていて思ったのがパネルデータだったということです。
統計データには
- クロスセクションデータ
普通の多変量データ - 時系列データ
時系列に対しての目的変数があるデータ - パネルデータ
多変量の時系列データ
があります。
ここでパネルデータであることが分かった事から特徴量を増やすことにしました。
具体的には年月日が最初にあったので変数に「year」「month」「day」を付けます。実際引っ越しにはシーズンが有ったり月のいつに引っ越すかの傾向があると聞きます。
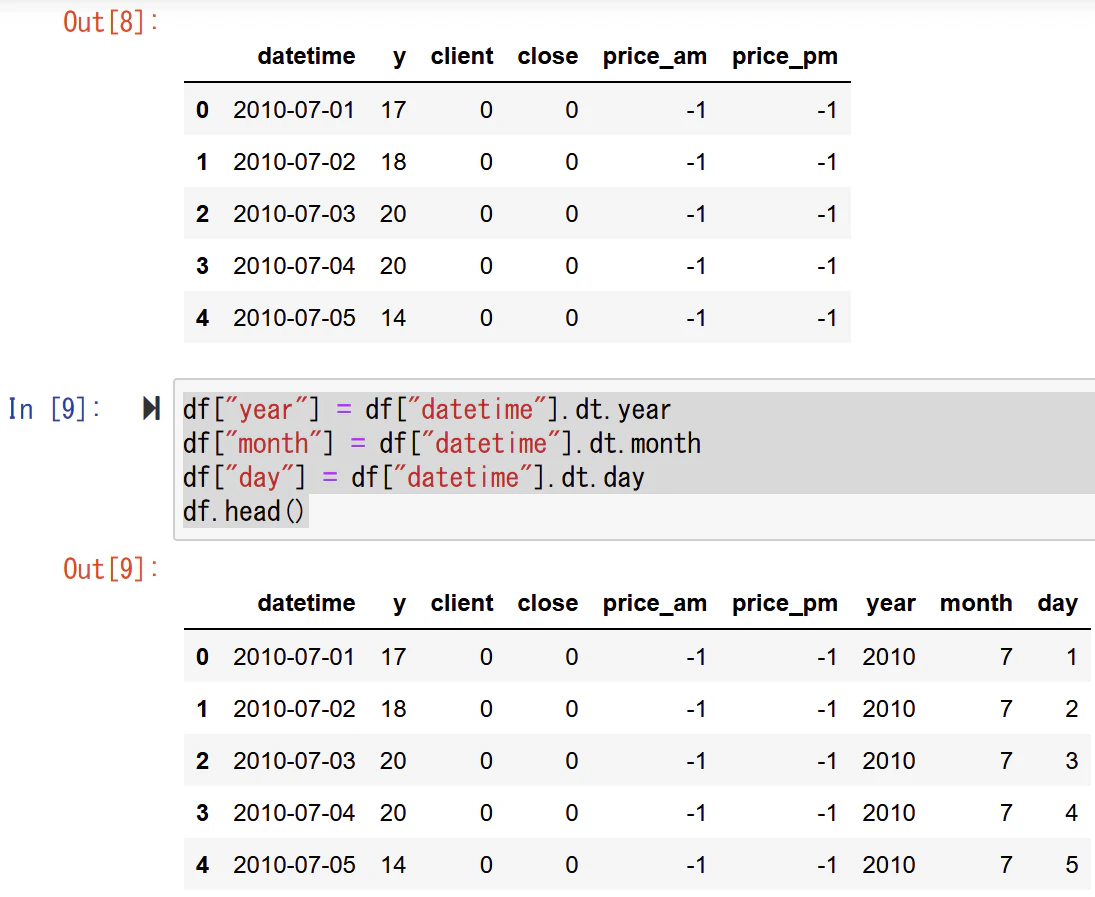
実際実質賃金のデータ一つ見ても例えば月をダミー変数にすることで重回帰分析でも一直線だけで予測しなくてすみます。
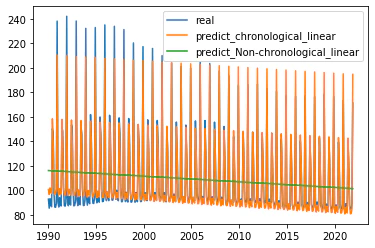
例えばこのグラフのように時系列を数値変換したりするだけでは緑の線のようになりますが、ダミー変数を使うことで月ごとの月の特徴を反映することができます。(このグラフに使っている予測モデルは重回帰分析)。
補足ですが、因子選定を一切せず今回この時系列データの特徴量化するだけでMAEはどうやら11.19478905030105だそうでした。
順位としては上位になれたとは言えませんしむしろ下位ですが、時系列系が苦手な自分が初めてやった予測では割と思っていたより良かったです。
ただ課題として、このデータはテストデータと訓練データでは使う年が違うためLightGBMが実際にはうまく機能しない事が分かります。
そこで恐らくこの手法を使うなら多層パーセプトロン(ニューラルネットワーク)を使った方が良いのかもしれません。ただしその時は全ての変数をちゃんと標準化しないといけませんが・・・
まとめ
特徴量の考え方は恐らく妥当だったと思うけど、多分使うモデルは違う方が良いと思う。