初めに
これから様々な仕事がAIにとって代わるであろう時代で
使うだけの側から作る側でいたいという思いから学習を始めました。
アイデミーで学習した内容
Python入門
ライブラリ「NumPy」基礎(数値計算)
ライブラリ「Pandas」基礎(表計算)
ライブラリ「Matplotlib」基礎(可視化)
データクレンジング
データハンドリング
機械学習概論
教師あり学習(回帰)
教師あり学習(分類)
教師なし学習
自然言語処理基礎
ディープラーニング基礎
ネガ・ポジ分析
日本語テキストのトピック抽出
自然言語処理を用いた質問応答
学習の流れ
大体1コース20~30程度のコンテンツがあり、
コンテンツごとに演習問題に挑むことになります。
カリキュラムごとにある添削問題では「Google Colaboratory」を利用してプログラミングを行いんす。
今までAIを学習するにはハイスペックパソコンを用意して様々なソフトをインストールするなど、
環境構築を行うだけでもハードルが高いイメージがあったのですが、
研究開発をするだけなら気軽に環境が整えられる点には驚かされました。
ボストンデータを使用してデータを分析してみた。
データについて
今回はscikit-learn に付属しているデータセットの中から「Boston house-prices (ボストン市の住宅価格)」を使ってデータ分析を行いたいと思います。
詳しいデータの説明は以下のサイトを参照してください
実行環境
Colaboratoryを使用して実装しています。
詳細は以下のリンクで実際に動かして確認していただければと思います。
モジュールをインポート
最初に次のモジュールをインポートします。
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dense, Dropout, Input, BatchNormalization
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_boston
import matplotlib.pyplot as plt
データセットの読み込み
# ボストン住宅価格データセットの読み込み
boston = load_boston()
データの取得
読み込んだデータからデータを取得します
# 説明変数
X = boston.data
# 目的変数
y = boston.target
・目的変数とは
目的変数とは、機械学習の教師あり学習において求めたい(予測したい)変数のこと。
(詳細は前述のデータセットの詳細を説明したサイトを参照してください)
・説明変数とは
説明変数とは、機械学習の教師あり学習において目的変数に作用する変数のこと。
(1,000 ドル台でオーナーが所有する住宅の価格の中央値)
データの分割
取得したデータをテストデータ(X_test, y_test)とトレーニングデータ(X_train,y_train)に分割します。
(以下の例では80%がトレーニングデータ、20%がテストデータ)
(random_stateを指定することで実行毎に結果が変わってしまうという現象を防ぎます)
# テストデータとトレーニングデータに分割します
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.20, random_state=42)
モデルの構築
下の例ではSequentialモデルにて
ユニット数32の隠れ層1つ、ユニット数128の隠れ層1つ、出力層で構成しています。
説明変数の項目数が13ですので1層目のinput_dimには13を指定しています。
また活性化関数には「ReLU」を使用しました。
model = Sequential()
# 1層目のニューラルネットワーク
model.add(Dense(32, input_dim=13, activation='relu'))
# 2層目のニューラルネットワーク
model.add(Dense(128, activation='relu'))
# 出力層
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
モデルの学習
次に構築したモデルを学習させます。
(epochsにて反復回数、batch_sizeにてモデルに一度に入力するデータの数を指定します)
history = model.fit(X_train, y_train, epochs=75, batch_size=16, verbose=1, validation_data=(X_test, y_test) )
適切なエポック数を設定しなかった場合、途中から精度が伸びなくなり、それだけでなく学習を繰り返すことで損失関数を最小化させようとして過学習を引き起こしてしまう可能性があります。
イレギュラーなデータが多い時には バッチサイズを大きくする、少ないときには バッチサイズを小さくする といったように、バッチサイズを調整します。
とのこと。皆さんいろいろ試してみてください。
結果を見てみる
# 予測値を出力します
y_pred = model.predict(X_test)
# 二乗誤差を出力します
mse= mean_squared_error(y_test, y_pred)
print("REG RMSE : %.2f" % (mse** 0.5))
実行結果は以下の通りです。
誤差が小さくなるように各種パラメータを調整する作業が発生します。

分析
誤差だけでなく、いろいろな方法で構築したモデルが正しいのかを分析します。
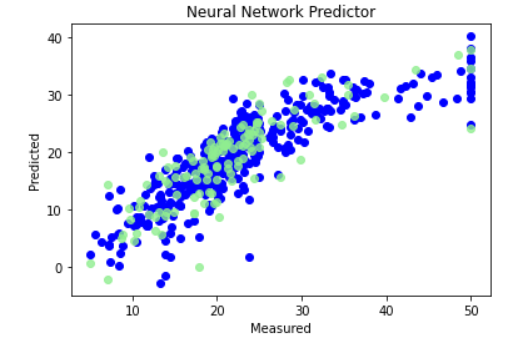
参考1
以下ではテストデータと、学習データの実際の値と、予測値の散布図を出力します
過学習していないか確認しましょう
%matplotlib inline
plt.figure()
plt.scatter(y_train,model.predict(X_train),label='Train',c='blue')
plt.scatter(y_test,y_pred,c='lightgreen',label='Test',alpha=0.8)
plt.title('Neural Network Predictor')
plt.xlabel('Measured')
plt.ylabel('Predicted')
plt.show()
参考2
以下はepoch毎の予測値の正解データとの誤差を出力します
バリデーションデータのみ誤差が大きい場合、過学習を起こしています
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs=len(loss)
plt.plot(range(epochs), loss, marker = '.', label = 'loss')
plt.plot(range(epochs), val_loss, marker = '.', label = 'val_loss')
plt.legend(loc = 'best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()

まとめ
いかがでしょうか?
AIによる分析と聞くとなかなかハードルが高く感じますが、
順を追って実装するとそんなに難しくはなかったのではないでしょうか?
(私はAidemyの添削問題の際、かなりてこずりましたが、振り返って文章にまとめることで理解が深まったと感じています)
研究用のデータも多数公開されているので、まずは実際に触れてみてはいかがでしょうか?
学習を終えて
正直なところAIという技術においての理解度でいうと、
ようやく入口に立ったというところだと考えています。
それくらい奥深い技術であると思います。
躓いた点など
課題、演習問題については順を追って学習しているため、
さほど躓くことなく回答できたと思います。
ただし、コードを記述しそれっぽい結果を出力することはできるのですが、
適切な回答を導き出すことはおろか、
自分の出した答えが最適解かどうかを判断することさえ、経験が必要だと感じました。
ある意味それが一番躓いた点だと思います。
ただ、課題については細かく解説していただけますし
疑問点があれば直接対話による解説もしていただけます。
その点では安心して着実に力をつけていけるかと思います。
これから作りたいもの
自社で運用している評価システムなどで
成長が早い(実際に評価されている)は普段どのような評価・指導を受けているのか、
など、定量的に分析できるようなシステムを徐々にではありますが作っていければと考えています。
最後に
前にも書きましたがまだまだようやくスタートできた程度だと考えています。
近道はなく、実際にモノづくりを繰り返し、制度や理解度を徐々に上げていくしかないと思います。
一通りカリキュラムはこなしましたが、
本当に理解するに繰り返し学習していくことが必要だと痛感しています。
「千里の道も一歩から」との格言にもあるように第一歩を踏み出せたことは非常に大きいことだと思います。
「難しいから」、「どうせ自分にはできないから」などと考えることよりも、まずは行動を起こしてみてはいかがいたしましょうか。
あきらめるのは行動してからでも遅くないと思います!!