はじめに
業務システムにて、あるテーブルのあるカラムに対して、本来あるべき「ユニーク制約」がついていなかった。後からテーブル設計の間違いに気がついて、ユニーク制約を追加したいものの、運用がはじまって既に該当カラムで重複しているレコードがあって、追加できない・・といった経験はないでしょうか? 私はあります。
このような場合、重複している行をテーブルから削除してからユニーク制約を追加することになります。
この記事では「重複している行をテーブルから削除する」SQLの操作についてまとめます。
動作確認環境
- macOS Big Sur(バージョン11.2.1)
- psql (PostgreSQL) 13.1
初級編: 1つのカラムでユニーク制約を追加したい場合
以下のようなテーブルがあるとします。
| id | station_name |
|---|---|
| 1 | 渋谷 |
| 2 | 渋谷 |
| 3 | 渋谷 |
| 4 | 恵比寿 |
| 5 | 恵比寿 |
| 6 | 五反田 |
山手線の駅名を管理するテーブルがあり、駅名でユニークにしたい! と思ったタイミングで既に重複するレコードが入っていた・・というケースを想定します。
上記の状態の場合は「渋谷」のレコードが3件、「恵比寿」のレコードが2件あります。これをそれぞれ1件づつ残るようにしたいです。
基本的に重複しているレコードのうち、idが小さいを残すことにしましょう。
id=1(渋谷), 4(恵比寿) のレコードを残し、id=2, 3(渋谷), 5(恵比寿)のレコードを削除することにします。
サンプル用テーブルを手元の環境で作成する場合は、以下を実行してください。
CREATE TABLE stations(
id SERIAL NOT NULL,
station_name varchar(20),
PRIMARY KEY (id)
);
INSERT INTO stations(station_name) VALUES ('渋谷');
INSERT INTO stations(station_name) VALUES ('渋谷');
INSERT INTO stations(station_name) VALUES ('渋谷');
INSERT INTO stations(station_name) VALUES ('恵比寿');
INSERT INTO stations(station_name) VALUES ('恵比寿');
INSERT INTO stations(station_name) VALUES ('五反田');
1. 重複データを確認したい
そもそも重複があるかどうかを確認する場合は、以下のSQL文を実行します。
# SELECT station_name FROM stations GROUP BY station_name HAVING count(id) > 1;
station_name
--------------
渋谷
恵比寿
(2 rows)
ユニークにしたいカラム(station_name)でGROUP BYでまとめ、まとめた後にレコード数(=count(id))が1より大きくなるものを抽出しました。
2. 重複したデータのうち、最小のidのレコードのみ出力したい
残したいレコードのidを調べるには、以下のSQL文を実行します。
# SELECT MIN(id), station_name FROM stations GROUP BY station_name HAVING count(id) > 1;
min | station_name
-----+--------------
1 | 渋谷
4 | 恵比寿
さきほどと同じ条件ですが、idの最小値であるMIN(id)をSELECT句で指定しました。
3. 重複したデータのうち、最小のid以外のみ出力したい(消すレコードだけ出力したい)
そもそもやりたかったことは
「id=1(渋谷), 4(恵比寿) のレコードを残し、id=2, 3(渋谷), 5(恵比寿)のレコードを削除したい」
でした。削除するレコードだけを抽出してみましょう。
ここでは自己結合というテクニックを使います。
# SELECT id, station_name FROM stations S1 WHERE id >
(SELECT MIN(S2.id) FROM stations S2
WHERE S1.station_name = S2.station_name);
id | station_name
----+--------------
2 | 渋谷
3 | 渋谷
5 | 恵比寿
(3 rows)
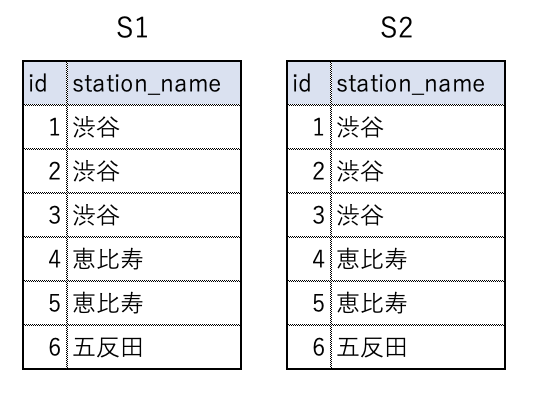
左側のS1の表を基準にして、上から1行づつ追ってみましょう。
左側のS1の表にて、id=1 の行を考えます。
左側のS1の表にて、id=1となっている行の駅名は「渋谷」です。
これと同じ駅名になっている行は、右側の表では id=1, 2, 3の行が該当します。
SQL文の (かっこ) で囲まれているSELECT文で、この3件が選択されます。
id=1, 2, 3 のうち 最小値 MIN(id)は 1 になります。
S1のid=1の行では、
WHERE id > 1
とはならないため、S1.id=1 の行は出力されません。
次にS1の id=2 の行を考えましょう。
またしても駅名は「渋谷」なので、右側の表 S2 では id=1, 2, 3の行が選択され、MIN(id) は 1 となります。
S1の id=2 の行では、
WHERE id > 1
がマッチするため、結果行に出力されます。
同様に、id=3の行、id=4の行・・を考えると、上記のように
id=2, 3, 5
の行が選択されることが分かります。
4. 重複のある行を消す
ここまでできたら、あとは簡単です。
# DELETE FROM stations S1 WHERE id >
(SELECT MIN(S2.id) FROM stations S2
WHERE S1.station_name = S2.station_name);
DELETE 3
# SELECT * FROM stations;
id | station_name
----+--------------
1 | 渋谷
4 | 恵比寿
6 | 五反田
(3 rows)
無事、station_name列でユニークになりました。
中級編: 複数カラムの組み合わせでユニークにしたい場合
駅名と飲食店を管理する以下のようなテーブルがあるとします。
| id | station_name | shop_name |
|---|---|---|
| 1 | 渋谷 | 富士そば |
| 2 | 渋谷 | 富士そば |
| 3 | 渋谷 | はなまるうどん |
| 4 | 恵比寿 | 富士そば |
| 5 | 恵比寿 | はなまるうどん |
| 6 | 恵比寿 | はなまるうどん |
| 7 | 五反田 | はなまるうどん |
駅ごとにどの飲食店があるかを表したテーブルです。ひとつの駅の近くには同じ店は1件しかないものとします(あくまでサンプルです。東口店と西口店があるはず!というようなツッコミは無しでお願いします!)
駅名と店名の組み合わせでユニークにしたい。だがしかし、そのユニーク制約をつける前にデータが入ってきてしまっている。しかも重複してしまっているじゃねえか・・・といったケースを想定しています。
サンプル用テーブルを手元の環境で作成する場合は、以下を実行してください。
CREATE TABLE station_shops(
id SERIAL NOT NULL,
station_name varchar(20),
shop_name varchar(20),
PRIMARY KEY (id)
);
INSERT INTO station_shops(station_name, shop_name) VALUES ('渋谷', '富士そば');
INSERT INTO station_shops(station_name, shop_name) VALUES ('渋谷', '富士そば');
INSERT INTO station_shops(station_name, shop_name) VALUES ('渋谷', 'はなまるうどん');
INSERT INTO station_shops(station_name, shop_name) VALUES ('恵比寿', '富士そば');
INSERT INTO station_shops(station_name, shop_name) VALUES ('恵比寿', 'はなまるうどん');
INSERT INTO station_shops(station_name, shop_name) VALUES ('恵比寿', 'はなまるうどん');
INSERT INTO station_shops(station_name, shop_name) VALUES ('五反田', 'はなまるうどん');
1. 重複データを確認
GROUP BYの後のカラムを2つ指定します。
# SELECT station_name, shop_name FROM station_shops GROUP BY station_name, shop_name HAVING count(id) > 1;
station_name | shop_name
--------------+----------------
恵比寿 | はなまるうどん
渋谷 | 富士そば
(2 rows)
(・・手元の環境で試したところ、この順番で出力されていました。本当は「渋谷」の行が先に来てほしいような気もしましたが、深追いせず、このままとします)
2. 重複したデータのうち、最小のidのレコードのみ出力
同様に、GROUP BYの後のカラムを2つ指定します。
SELECT MIN(id), station_name, shop_name FROM station_shops GROUP BY station_name, shop_name HAVING count(id) > 1;
min | station_name | shop_name
-----+--------------+----------------
5 | 恵比寿 | はなまるうどん
1 | 渋谷 | 富士そば
(2 rows)
3. 重複したデータのうち、最小のid以外のみ出力(消す行だけ出力)
同様に・・・。
SELECT id, station_name, shop_name FROM station_shops S1 WHERE id >
(SELECT MIN(S2.id) FROM station_shops S2
WHERE S1.station_name = S2.station_name
AND S1.shop_name = S2.shop_name);
id | station_name | shop_name
----+--------------+----------------
2 | 渋谷 | 富士そば
6 | 恵比寿 | はなまるうどん
4. 重複行を削除!
消します。
DELETE FROM station_shops S1 WHERE id >
(SELECT MIN(S2.id) FROM station_shops S2
WHERE S1.station_name = S2.station_name
AND S1.shop_name = S2.shop_name);
DELETE 2
# SELECT * FROM station_shops;
id | station_name | shop_name
----+--------------+----------------
1 | 渋谷 | 富士そば
3 | 渋谷 | はなまるうどん
4 | 恵比寿 | 富士そば
5 | 恵比寿 | はなまるうどん
7 | 五反田 | はなまるうどん
(5 rows)
無事、ユニークキーを追加できる状態となりました。
上級編: 重複レコードを論理削除したいとき
業務システムではレコードを物理削除ではなく論理削除したい、といったケースもあります。論理削除とは、DELETEでレコードを消すのではなく、delete_flag のようなカラムを追加し、delete_flagが1なら削除されたとみなす、というような考え方です。ここでは、Railsプロジェクトで gem 'paranoia' がインストールされている環境を想定します。
paranoiaでは、対象のテーブルには 常に'deleted_at' カラムが存在します。デフォルト値を'1970-01-01 00:00:00'とします。
deleted_atがデフォルト値のレコードは、生きている(削除されていない)レコードです。deleted_atがデフォルト値以外のレコードは、削除されたレコードとして扱われます。
最初の「駅名管理テーブル」を論理削除対応させたテーブルを考えます。
| id | station_name | deleted_at |
|---|---|---|
| 1 | 渋谷 | 1970-01-01 00:00:00 |
| 2 | 渋谷 | 1970-01-01 00:00:00 |
| 3 | 渋谷 | 1970-01-01 00:00:00 |
| 4 | 恵比寿 | 1970-01-01 00:00:00 |
| 5 | 恵比寿 | 1970-01-01 00:00:00 |
| 6 | 五反田 | 1970-01-01 00:00:00 |
サンプル用テーブルを手元の環境で作成する場合は、以下を実行してください。
CREATE TABLE stations(
id SERIAL NOT NULL,
station_name varchar(20),
deleted_at timestamp DEFAULT '1970-01-01 00:00:00',
PRIMARY KEY (id)
);
INSERT INTO stations(station_name) VALUES ('渋谷');
INSERT INTO stations(station_name) VALUES ('渋谷');
INSERT INTO stations(station_name) VALUES ('渋谷');
INSERT INTO stations(station_name) VALUES ('恵比寿');
INSERT INTO stations(station_name) VALUES ('恵比寿');
INSERT INTO stations(station_name) VALUES ('五反田');
システムの挙動として「駅名」でユニークにしたい場合、テーブル定義は station_nameとdeleted_atの組み合わせでユニーク制約を追加します(station_nameだけでユニークにした場合、論理削除されたキーのレコードが追加できなくなってしまいます)。
正しくない例
削除したい場合は deleted_atを現在時刻に更新すればよいため、まず思いつくのは以下のようなクエリーです。
# update stations S1 SET deleted_at = NOW() WHERE id >
(SELECT MIN(S2.id) FROM stations S2
WHERE S1.station_name = S2.station_name);
UPDATE 3
結果を確認してみましょう。
# SELECT * FROM stations ORDER BY id;
id | station_name | deleted_at
----+--------------+----------------------------
1 | 渋谷 | 1970-01-01 00:00:00
2 | 渋谷 | 2021-03-06 22:55:04.967859
3 | 渋谷 | 2021-03-06 22:55:04.967859
4 | 恵比寿 | 1970-01-01 00:00:00
5 | 恵比寿 | 2021-03-06 22:55:04.967859
6 | 五反田 | 1970-01-01 00:00:00
(6 rows)
一見 id=2, 3, 5のレコードが削除扱いされていて、問題ないように思えます。ですが、このままだとstation_name + deleted_atでユニーク制約を追加できません。なぜなら id=2 の行と id=3 の行が重複してしまっているからです。
PostgreSQLでは、NOW()は現在のトランザクションが開始された時間を返します。
deleted_atを更新するときに、「同じ時間にならないように」工夫する必要があります。
正しい例(PostgreSQLの場合)
clock_timestamp() を使います。
# UPDATE stations S1 SET deleted_at = clock_timestamp() WHERE id >
(SELECT MIN(S2.id) FROM stations S2
WHERE S1.station_name = S2.station_name
AND S1.deleted_at = S2.deleted_at);
UPDATE 3
# SELECT * FROM stations ORDER BY id;
id | station_name | deleted_at
----+--------------+----------------------------
1 | 渋谷 | 1970-01-01 00:00:00
2 | 渋谷 | 2021-03-07 00:37:11.939193
3 | 渋谷 | 2021-03-07 00:37:11.93924
4 | 恵比寿 | 1970-01-01 00:00:00
5 | 恵比寿 | 2021-03-07 00:37:11.939249
6 | 五反田 | 1970-01-01 00:00:00
(6 rows)
clock_timestamp()は実際の現在時刻を返しますので、その値は単一のSQLコマンドであっても異なります。
MySQLの場合について
残念ながら、MySQLでは上記のクエリーはうまく動作しません。サブクエリで自分のテーブルと結合しつつupdateしようとするとエラーになります。また、初めから deleted_at をdatetime(6)として設定している場合は、deleted_at = SYSDATE(6) として更新することでpostgresの clock_timestamp() と同等の動きになりますが、ただのdatetime型だと秒単位の更新となってしまいます。
こちらについては、別の記事で考えたいと思います。