背景
- 機械学習プロジェクトで、GPUを使ったサーバーが必要になりました
- 仕様としてサーバーで行う処理はジョブ形式で、常時サーバーを起動しておく必要はありませんでした
- そこで、AWSのSageMakerを使うことにしました。SageMakerは、機械学習モデルの構築、トレーニング、デプロイを効率的に行えるサービスで、コストも抑えられます。
この記事では、SageMakerについての基本的な情報や、私が参考にした記事を紹介します。
SageMakerとは
SageMakerはフルマネージドのMLサービスです. SageMakerによって、データサイエンティストはMLモデルの構築・学習・デプロイを本番環境レベルの環境で高速に行うことが可能になります.
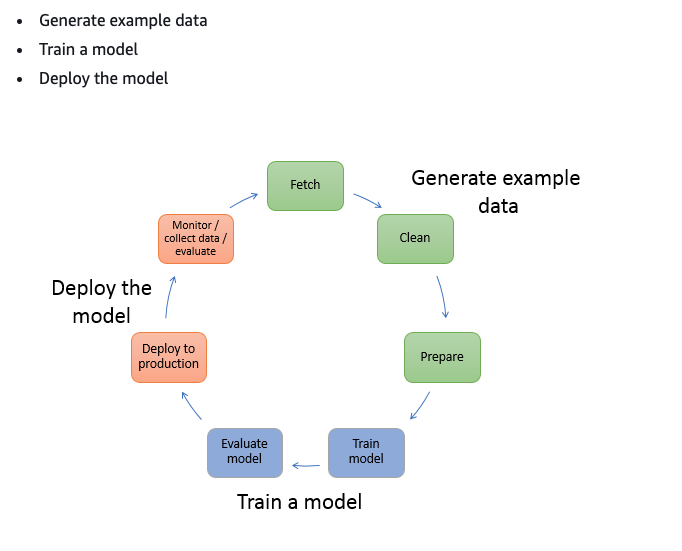
SageMakerでは以下の処理を行うことができます。
- データの前処理
- モデルの学習
- モデルのデプロイ
今回の記事では、モデルのデプロイ に焦点を当てています。
SageMakerのデプロイとは
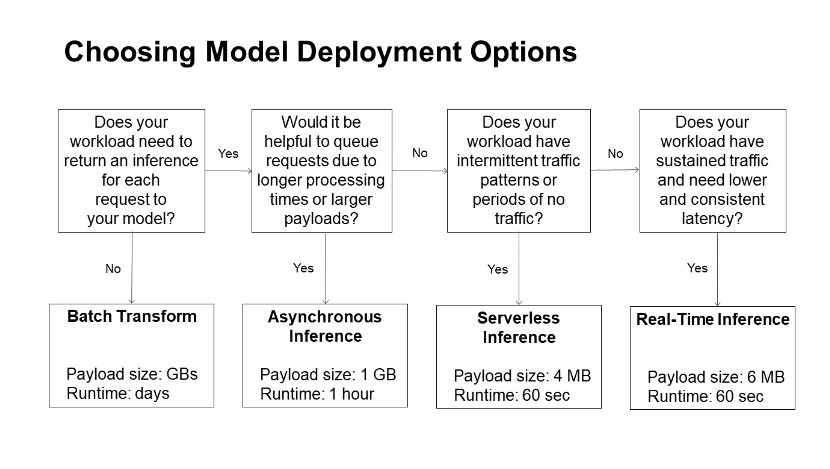
SageMakerデプロイには大きく分けて4種類あります
- リアルタイム
- サーバーレス
- 非同期
- バッチ
使い分けは以下のフローチャートから
デプロイの大まかな流れ
- SageMaker用のContainer Image(※1)とMLモデルを組み合わせてSagemaker用のモデルを作成します
- SageMaker用のモデル(※2)が作成とエンドポイント設定(※3)を使ってデプロイするとサーバーが用意されます
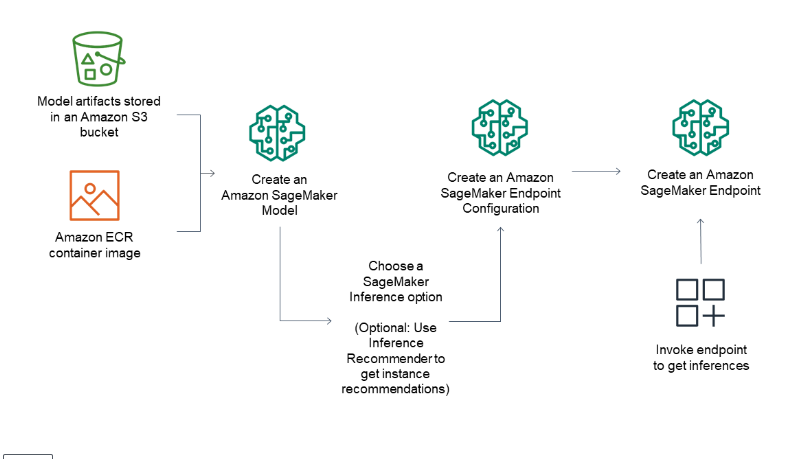
- (※1) SageMaker用のContainer Image一覧: https://docs.aws.amazon.com/ja_jp/sagemaker/latest/dg-ecr-paths/ecr-ap-northeast-1.html
- (※2) SageMakerのモデル: AWSのコンソールの SageMaker -> 推論 -> モデル で表示されるオブジェクト
- (※3) エンドポイント設定: AWSのコンソールの SageMaker -> 推論 -> エンドポイント設定 で表示されるオブジェクト
詳細とGettingStarted
色々書いてきましたが以下のyoutubeで、デプロイの全体像がめちゃくちゃわかりやすく説明されています
この動画を見てサンプルのScikit-Learnコンテナや、Pytorchコンテナのデプロイまで一通りやるとかなり理解が深まります.
Python Libraryでのデプロイサンプルコードもありますが、基本的にはboto3でのデプロイサンプルで挙動を把握していくことをお勧めします. 非同期推論や、バッチ推論のサンプルはboto3でのものが多いですし、挙動の詳細がよくわかります.