概要
HRNetV2という,様々なダウンストリームタスク(eg. human pose estimation, semantic segmentation, object detection)に対応したCNNモデルを紹介します.このモデルは,トップジャーナル「TPAMI(Transactions on Pattern Analysis and Machine Intelligence)」に掲載された,「Deep High-Resolution Representation Learning
for Visual Recognition」[1]で示されたモデルになります.V2というだけあって,V1もありますのでそちらも合わせて紹介します.
さらに,Pytorchによる実装の話も紹介します.
HRNet (V1)
HRNetの元祖はCVPR2019で発表された論文,「Deep High-Resolution Learning for Human Pose Estimation」[2]において示されました.それまでの多くの研究で紹介されたCNNモデルでは,下図の(a)~(d)に示されたように高解像度の画像を畳み込んで低解像度の特徴マップにした上で,それを再度up convolutionして高解像度化したり,それを元の高解像度マップと足し算していたりしました.
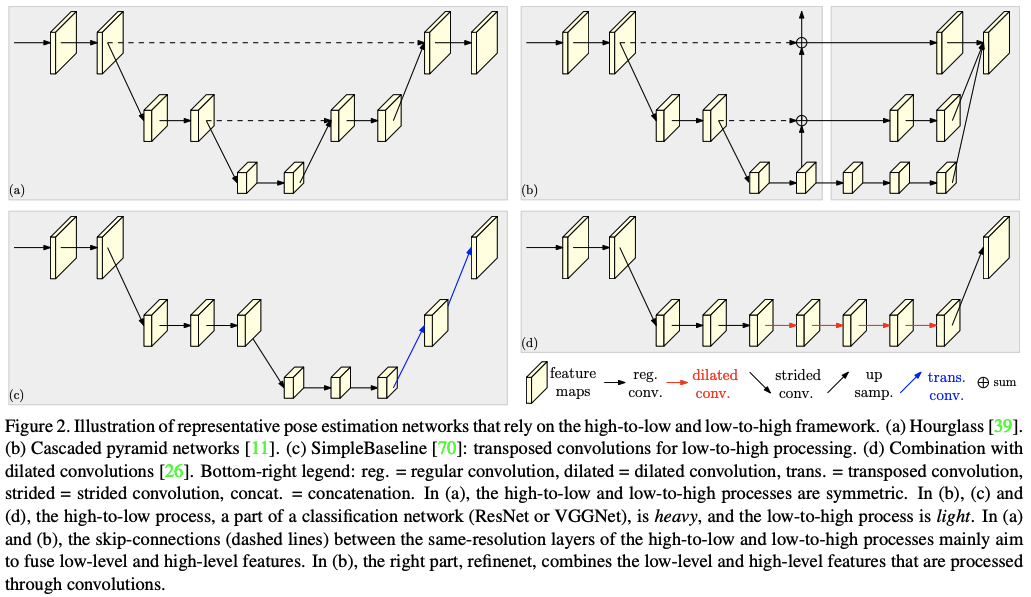
畳み込むことで深いレベルの特徴量を抽出できるのはいいですが,画像としての解像度を落としているので細かな位置情報などは削られていきます.そこで,この論文では下図のように高解像度マップを維持しつつ,低解像度マップも派生させていくようなモデルが提案されます.これがHRNetです.
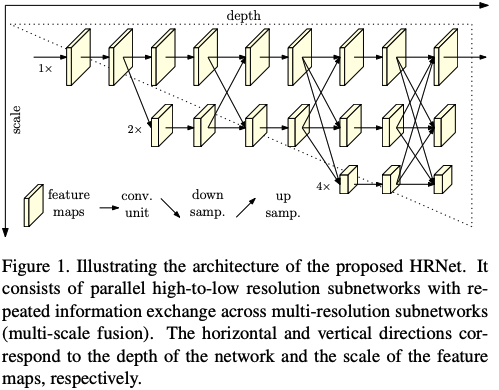
モデルはおよそ3つのパートに分解できます.
1.各解像度でサイズ変化を伴わない畳み込みを行うパート
2.高解像度に加えて低解像度に派生するパート
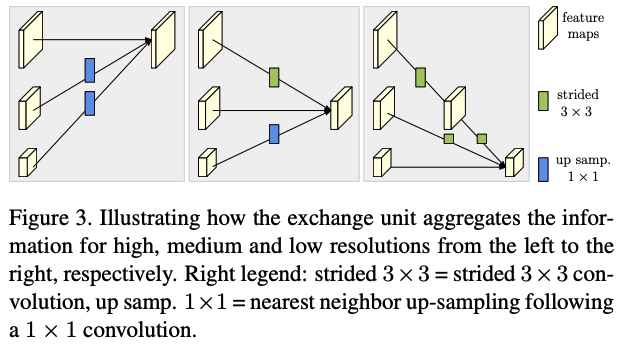
3.各解像度の特徴量を互いに交換するパート
パート1〜3を繰り返し行っていくようなモデルです.
このような方法を取る事によるメリットは大きく2つあります.ひとつめは,それまでのモデルとは違って低解像度に畳み込むのと並列に高解像度のマップも維持しているため,低解像度マップからアップスケールするよりも空間情報が正確である.もうひとつは,パート3の特徴量を互いに交換するところで,それぞれの解像度における特徴マップにはない部分を互い補完し合うような形となり,よりリッチな特徴マップとなって,最終的なタスクの精度も上がる.
結局,低解像度への派生は3回行われ,4種類の解像度の特徴マップが生成されます.最後はこのうちの一番高解像度なマップが予測に使われます.いままでの特徴量交換により,高解像度マップにも低解像度マップすべての特徴量が反映されているからです.
このように,いままでのCNNモデルにはなかった,高解像度のマップを維持したり,特徴量を交換するというありそうでなかった新しいアイデアにより,human pose estimationにおいてそれまでのモデルの精度を上回ることができたことが,CVPRに通った理由と考えています.
HRNetV2
さて,前置きが長くなりましたが本題のHRNetV2です.とはいっても,正直HRNetを少し改良しただけといった感じです.
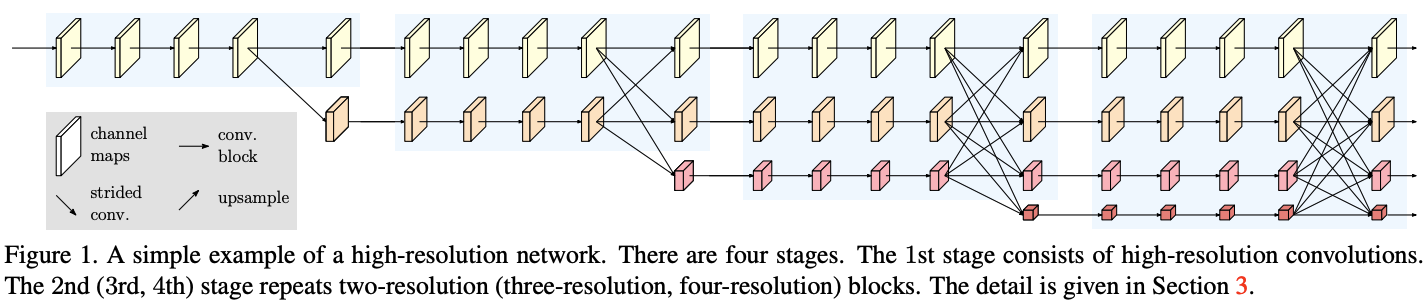
HRNetではhuman pose estimationを行っていましたが,同じアーキテクチャで最後の層の部分だけをうまく変更すれば他のタスクにも応用できるのではないか,ということで生み出されたのがHRNetV2です.全体のアーキテクチャを下図に示します.4ステージからなり,ステージごとに新しい低解像度のマップが派生します.
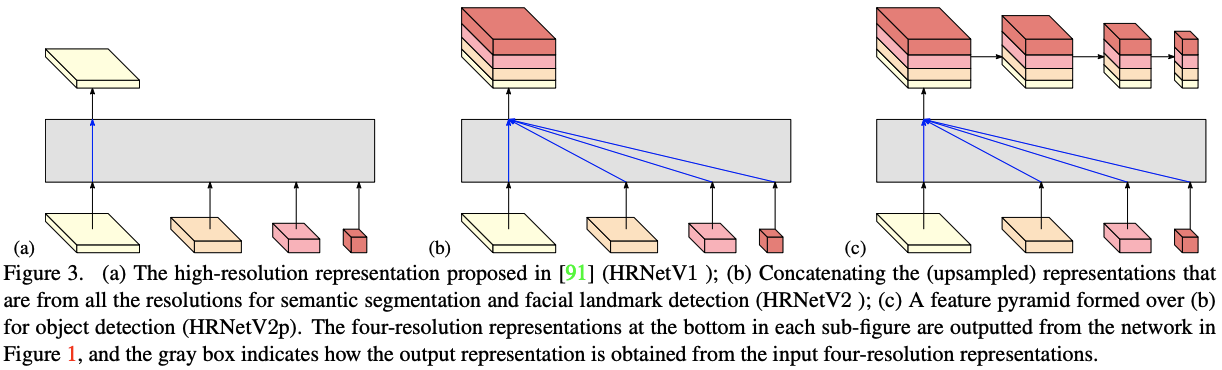
HRNet初号機から拡張された最終層に関しては下図に示されています.(a)はHRNetのときの方法です.対して,(b)は各解像度すべての特徴を高解像度にフィットするようにupscaleして,concatしています.こうすることで,semantic segmentationやfacial landmark heatmapsに使えるそうです.また,(c)は,そこからさらにaverage poolingによりdownsamplingしていて,object detectionに使えるそうです.
...以上です!
簡単ですが,これらの変更により,いくつかの評価で既存のモデルを上回る精度を出しています.残念ながらCVPRは通っていないようですが,この新しいモデルがさらに様々なタスクに応用でき,それぞれにおいて高い精度を叩き出していることが買われ,トップジャーナルに掲載されたと考えます.
実装
今回私はsemantic segmentation向けのHRNetV2の実装を行いました.データセットはCityscapesです.実装した内容は大きく以下の通り.
- HRNetV2のモデル
- 学習コード
- テストコード
- 評価コード
順番に簡単に内容を紹介します.詳しい実装はgithubを参照ください.
1. HRNetV2モデル
論文に忠実に,わかりやすく書いたつもりです.上でも紹介したように,最後の層を除くと,モデルは大きく分けて3つのパートから構成されます.パート1はgroupConvUnit,パート2と3はexchageConvUnitとして実装しています.また,最初のステージは少し特殊なので,firstBlockを用いてfirstStageとして別に実装してあります.2ステージ以降はotherBlockを用いて~Stageとしてそれぞれ実装されています.基本的に2ステージ以降はgroupconv→exchangeの繰り返しです.繰り返し回数は2,3,4ステージそれぞれ1,4,3回です.
HRNetV2モデルコード(クリックで展開)
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import List
"""
There are 4 resolution levels in HRNet. We name each level as large, middle, small, tiny.
"""
class firstBlock(nn.Module):
def __init__(self, in_channel, out_channel, identity_conv=None):
super(firstBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channel, 64, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(64)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(64, out_channel, kernel_size=1, stride=1, padding=0)
self.bn3 = nn.BatchNorm2d(out_channel)
self.relu = nn.ReLU(inplace=True)
self.identity_conv = identity_conv
def forward(self, x):
identity = x.clone()
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x)
# add 1x1conv to match number of channels
if self.identity_conv is not None:
identity = self.identity_conv(identity)
x += identity
x = self.relu(x)
return x
class firstStage(nn.Module):
def __init__(self, block, C):
super(firstStage, self).__init__()
self.units = self._make_units(block, 4)
self.conv2large = nn.Conv2d(256, C, kernel_size=3, stride=1, padding=1)
self.conv2middle = nn.Conv2d(256, 2*C, kernel_size=3, stride=2, padding=1)
def forward(self, x):
x = self.units(x)
x_large = self.conv2large(x)
x_middle = self.conv2middle(x)
return [x_large, x_middle]
def _make_units(self, block, num_units):
layers = []
# 1st unit
identity_conv = nn.Conv2d(64, 256, kernel_size=1, stride=1, padding=0)
layers.append(block(64, 256, identity_conv))
# 2~num_units units
for i in range(num_units - 1):
layers.append(block(256, 256, identity_conv=None))
return nn.Sequential(*layers)
class otherBlock(nn.Module):
def __init__(self, in_channels, out_channels):
super(otherBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
identity = x.clone()
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x += identity
x = self.relu(x)
return x
class groupConvUnit(nn.Module):
def __init__(self, block, C, level=0):
super(groupConvUnit, self).__init__()
self.level = level
self.convlist = nn.ModuleList()
for i in range(level+1):
self.convlist.append(self._make_units(block, 2**i*C, 4))
def forward(self, x: List):
out = []
for i in range(self.level+1):
out.append(self.convlist[i](x[i]))
return out
def _make_units(self, block, channel, num_units):
layers = nn.ModuleList()
for i in range(num_units):
layers.append(block(channel, channel))
return nn.Sequential(*layers)
class exchangeConvUnit(nn.Module):
def __init__(self, C, in_level, out_level):
super(exchangeConvUnit, self).__init__()
self.in_level = in_level
self.out_level = out_level
self.convlist = nn.ModuleList()
for i in range(out_level+1):
to_convlist = nn.ModuleList()
for j in range(in_level+1):
if j < i:
to_convlist.append(self._make_downconv(C, j, i))
elif j > i:
to_convlist.append(self._make_upconv(C, j, i))
else:
to_convlist.append(None)
self.convlist.append(to_convlist)
def forward(self, x: List):
assert self.in_level+1 == len(x)
out = []
for j in range(self.in_level+1):
out.append(x[j].clone())
for i in range (min(self.in_level+1, self.out_level+1)):
for j in range(self.in_level+1):
if j < i:
out[i] += self.convlist[i][j](x[j])
elif j==i:
out[i] = out[i]
elif j > i:
out[i] += self.convlist[i][j](F.interpolate(x[j], out[i].shape[2:], mode="bilinear", align_corners=True))
if self.in_level < self.out_level:
out.append(self.convlist[self.out_level][0](x[0]))
for j in range(1,self.in_level+1):
out[self.out_level] += self.convlist[self.out_level][j](x[j])
return out
def _make_downconv(self, C, in_level, out_level):
diff_level = out_level - in_level
layers = nn.ModuleList()
for i in range(diff_level):
layers.append(nn.Conv2d(2**(in_level+i)*C, 2**(in_level+i+1)*C, kernel_size=3, stride=2, padding=1))
if diff_level > 1:
return nn.Sequential(*layers)
else:
return layers[0]
def _make_upconv(self, C, in_level, out_level):
return nn.Conv2d(2**in_level*C, 2**out_level*C, kernel_size=1, stride=1, padding=0)
class secondStage(nn.Module):
def __init__(self, block, C):
super(secondStage, self).__init__()
self.groupconv1 = groupConvUnit(block, C, 1)
self.exchange1 = exchangeConvUnit(C, 1, 2)
def forward(self, x: List):
x = self.groupconv1(x)
x = self.exchange1(x)
return x
class thirdStage(nn.Module):
def __init__(self, block, C):
super(thirdStage, self).__init__()
self.groupconv1 = groupConvUnit(block, C, 2)
self.exchange1 = exchangeConvUnit(C, 2, 2)
self.groupconv2 = groupConvUnit(block, C, 2)
self.exchange2 = exchangeConvUnit(C, 2, 2)
self.groupconv3 = groupConvUnit(block, C, 2)
self.exchange3 = exchangeConvUnit(C, 2, 2)
self.groupconv4 = groupConvUnit(block, C, 2)
self.exchange4 = exchangeConvUnit(C, 2, 3)
def forward(self, x: List):
x = self.groupconv1(x)
x = self.exchange1(x)
x = self.groupconv2(x)
x = self.exchange2(x)
x = self.groupconv3(x)
x = self.exchange3(x)
x = self.groupconv4(x)
x = self.exchange4(x)
return x
class fourthStage(nn.Module):
def __init__(self, block, C):
super(fourthStage, self).__init__()
self.groupconv1 = groupConvUnit(block, C, 3)
self.exchange1 = exchangeConvUnit(C, 3, 3)
self.groupconv2 = groupConvUnit(block, C, 3)
self.exchange2 = exchangeConvUnit(C, 3, 3)
self.groupconv3 = groupConvUnit(block, C, 3)
self.exchange3 = exchangeConvUnit(C, 3, 3)
def forward(self, x: List):
x = self.groupconv1(x)
x = self.exchange1(x)
x = self.groupconv2(x)
x = self.exchange2(x)
x = self.groupconv3(x)
x = self.exchange3(x)
return x
class finalStage(nn.Module):
def __init__(self, C, num_class):
super(finalStage,self).__init__()
self.lastlayer =nn.Sequential(
nn.Conv2d(15*C, 15*C, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(15*C),
nn.ReLU(inplace=True),
nn.Conv2d(15*C, num_class, kernel_size=1, stride=1, padding=0)
)
def forward(self, x: List):
x_large = x[0]
x_middle = x[1]
x_small = x[2]
x_tiny = x[3]
x_middle = F.interpolate(x_middle, x_large.shape[2:], mode="bilinear", align_corners=True)
x_small = F.interpolate(x_small, x_large.shape[2:], mode="bilinear", align_corners=True)
x_tiny = F.interpolate(x_tiny, x_large.shape[2:], mode="bilinear", align_corners=True)
out = torch.cat([x_large, x_middle, x_small, x_tiny],1)
out = F.interpolate(out, (out.shape[2]*4, out.shape[3]*4), mode="bilinear", align_corners=True)
out = self.lastlayer(out)
return out
class HRNetV2(nn.Module):
def __init__(self, C, num_class):
super(HRNetV2, self).__init__()
# stem stage
self.conv0_1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False)
self.bn0_1 = nn.BatchNorm2d(64)
self.conv0_2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1, bias=False)
self.bn0_2 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
# 1st stage
self.firstStage = firstStage(firstBlock, C)
# 2nd stage
self.secondStage = secondStage(otherBlock, C)
# 3rd stage
self.thirdStage = thirdStage(otherBlock, C)
# 4th stage
self.fourthStage = fourthStage(otherBlock, C)
#final
self.finalStage = finalStage(C, num_class)
def forward(self, x):
x = self.conv0_1(x)
x = self.bn0_1(x)
x = self.conv0_2(x)
x = self.bn0_2(x)
x = self.relu(x)
x_list = self.firstStage(x)
x_list = self.secondStage(x_list)
x_list = self.thirdStage(x_list)
x_list = self.fourthStage(x_list)
out = self.finalStage(x_list)
return out
2. 学習コード
学習コードの流れは,データセットの準備→モデルの準備→学習パラメータのセッティング,になります.データセットの準備の際には,RandomScale,RandomCrop,RandomHorizontalFlip,のaugmentationを適用.モデルは先程作ったHRNetV2のインスタンスを作成します.その際に,モデルの大きさを指定できるようにしました.各解像度の特徴マップのチャンネル数が,大きい方からC,2C,4C,8Cとなる仕様ですので,Cを決めることで中間層のチャンネル数が決まります.論文内では,C=40,48について評価を行っています.今回は40として学習させてみました.ここの数値を変えるだけでC=48のモデルも簡単に作成できます.
最後に学習環境のセッティングですが,論文では「バッチサイズ12で4つのGPU上で,syncBNにより120Kイテレーション学習させた」とあるので,そのとおり並列で学習させられるように並列化可能にしました.ただ,メモリの問題でバッチサイズは8に変更し,その代わり178Kイテレーション(480エポック)学習させました.このあたりの設定パラメータは./config/default.pyにすべて格納されており,このファイルを書き換えることで簡単にパラメータを変更できるようにしています.syncBNとは何かというと,並列化したGPU間をまたいで,全体のテンソルでBatchNormalizationをする手法です.これを適用しない場合,GPUを並列化して計算中に通常のBatchNormalizationを行うとそれぞれのGPUに乗っているテンソル内のみでのnormalizationになってしまうため,結果が変わってしまします.今回はsyncBNを可能にする非公式のコードを使用させていただきました(Synchronized-BatchNorm-PyTorch).また,学習率の減衰を「The poly learning rate plicy」に従って行っていますが,PyTorch公式にこのschedulerがないため,こちらも非公式のライブラリを使用させていただきました(pytorch-polynomial-lr-decay).
学習コード
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from dataset.cityscapes import Cityscapes
from config.default import get_cfg_defaults
from models.hrnet import HRNetV2
import argparse
import utils.transforms as t
from utils.utils import Denormalize
from torch_poly_lr_decay import PolynomialLRDecay
import numpy as np
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
import os
from tqdm import tqdm
from sync_batchnorm import convert_model, DataParallelWithCallback
def main(args):
cfg = load_config(args.config_path)
device_print = 'cuda:'+ ",".join(map(str,cfg.CUDA.CUDA_NUM)) if cfg.CUDA.USE_CUDA and torch.cuda.is_available() else 'cpu'
print("device:"+str(device_print))
base_device = torch.device('cuda:'+ str(cfg.CUDA.CUDA_NUM[0]) if cfg.CUDA.USE_CUDA and torch.cuda.is_available() else 'cpu')
# prepare dataset
train_transform = t.PairCompose([
t.PairRandomScale(scale_range=(0.5, 2.0)),
t.PairRandomCrop(size=(512, 1024), pad_if_needed=True),
t.PairRandomHorizontalFlip(p=0.5),
t.PairToTensor(),
t.PairNormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
train_dataset = Cityscapes(root=cfg.DATASET.ROOT, split='train', target_type='semantic', transform=train_transform)
train_dataloader = DataLoader(train_dataset, batch_size=cfg.TRAIN.BATCH_SIZE, shuffle=True, num_workers=cfg.TRAIN.NUM_WORKERS, drop_last=True)
denorm = Denormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# model
print("setting up model ...")
model = HRNetV2(cfg.MODEL.C, 19)
if cfg.CUDA.USE_CUDA:
#model = nn.DataParallel(model, device_ids=cfg.CUDA.CUDA_NUM)
model = convert_model(model)
model.to(base_device)
model = DataParallelWithCallback(model, device_ids=cfg.CUDA.CUDA_NUM)
if cfg.TRAIN.CHECKPOINT != '':
model.load_state_dict(torch.load(cfg.TRAIN.CHECKPOINT))
# checkpoint path
if not os.path.exists(cfg.TRAIN.SAVE_WEIGHT_PATH):
os.makedirs(cfg.TRAIN.SAVE_WEIGHT_PATH)
# optimizer
optimizer = torch.optim.SGD(model.parameters(),lr=cfg.TRAIN.LERNING_RATE, momentum=0.9, weight_decay=0.0005)
scheduler = PolynomialLRDecay(optimizer, max_decay_steps=100, end_learning_rate=0.001, power=0.9)
# loss
loss = nn.CrossEntropyLoss(ignore_index=255, reduction='mean')
# prepare logging
if not os.path.exists(cfg.TRAIN.LOG_PATH):
os.makedirs(cfg.TRAIN.LOG_PATH)
writer = SummaryWriter(cfg.TRAIN.LOG_PATH)
print("=================start training==================")
for epoch in range(cfg.TRAIN.EPOCH_START, cfg.TRAIN.EPOCH_END + 1):
print(f'epoch : {epoch}')
for i , (image, label) in enumerate(tqdm(train_dataloader)):
model.train()
step = epoch * len(train_dataloader) + i
image = image.to(base_device, dtype=torch.float32)
label = label.to(base_device, dtype=torch.long)
optimizer.zero_grad()
pred = model(image)
loss_pred = loss(pred, label)
# back prop
loss_pred.backward()
optimizer.step()
if (i+1) % cfg.TRAIN.LOG_LOSS == 0:
np_loss = loss_pred.detach().cpu().numpy()
writer.add_scalar('loss', np_loss, step)
if (i+1) % cfg.TRAIN.LOG_IMAGE == 0:
image_save = denorm(image[0])
target_save = label[0].detach().cpu().numpy()
pred_save = pred.detach().max(dim=1)[1].cpu().numpy()[0]
#image_save = (denorm(image_save) * 255).transpose(1, 2, 0).astype(np.uint8)
target_save = train_dataloader.dataset.decode_target(target_save).astype(np.uint8)
target_save = torch.from_numpy(target_save.astype(np.float32)).clone().permute(2, 0, 1)
pred_save = train_dataloader.dataset.decode_target(pred_save).astype(np.uint8)
pred_save = torch.from_numpy(pred_save.astype(np.float32)).clone().permute(2, 0, 1)
writer.add_image('train_image', image_save, step)
writer.add_image('label_image', target_save, step)
writer.add_image('pred_image', pred_save, step)
del image, label, pred
if (step + 1) % cfg.TRAIN.SAVE_WEIGHT_STEP == 0:
torch.save(model.state_dict(), cfg.TRAIN.SAVE_WEIGHT_PATH + f'/checkpoint_epoch{epoch}_iter{step}.pth')
torch.save(model.module.state_dict(), cfg.TRAIN.SAVE_WEIGHT_PATH + f'/checkpoint_epoch{epoch}_final.pth')
scheduler.step()
def load_config(config_path=None):
cfg = get_cfg_defaults()
if config_path is not None:
cfg.merge_from_file(config_path)
cfg.freeze()
return cfg
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--config_path", type=str, help="extra config file path", default=None)
args = parser.parse_args()
main(args)
3. テストコード
テストコードでは,学習したモデルの重みを使って指定した画像ファイルのsegmentationを行います.ディレクトリを指定すると,ディレクトリ内にあるすべての画像ファイルについて予測が行われます.結果画像はオプションで指定した場所に保存されます.
テストコード
import torch
import torchvision.transforms.functional as f
import os
import glob
from models.hrnet import HRNetV2
from config.default import get_cfg_defaults
from PIL import Image
from tqdm import tqdm
from dataset.cityscapes import Cityscapes
import numpy as np
import argparse
def main(args):
cfg = load_config("./config/predict.yaml")
#cfg = load_config(args.config_path)
device = torch.device('cuda:'+str(cfg.CUDA.CUDA_NUM[0]) if cfg.CUDA.USE_CUDA and torch.cuda.is_available() else 'cpu')
print("device:"+str(device))
if os.path.isdir(args.input_path):
file_list = [*glob.glob(os.path.join(args.input_path, "**.png"), recursive=True),
*glob.glob(os.path.join(args.input_path, "**.jpg"), recursive=True)]
elif os.path.isfile(args.input_path):
file_list = glob.glob(args.input_path)
else:
print("Please input valid image path.")
return
# model
print("setting up model ...")
model = HRNetV2(cfg.MODEL.C, 19).to(device)
print("loading pretrained model")
model.load_state_dict(torch.load(cfg.TEST.CHECKPOINT, map_location = device))
# result path
if not os.path.exists(args.output_path):
os.makedirs(args.output_path)
model.eval()
if len(file_list) == 0:
print("No image files !!")
return
with torch.no_grad():
for file in tqdm(file_list):
image = Image.open(file).convert("RGB")
image = f.to_tensor(image)
image = f.normalize(image, mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
image = image.unsqueeze(0)
image = image.to(device)
output = model(image)
pred = output.detach().max(dim=1)[1][0].cpu().numpy()
pred_save = Cityscapes.decode_target(pred).astype(np.uint8)
file_name = os.path.splitext(os.path.basename(file))[0]
Image.fromarray(pred_save).save(os.path.join(args.output_path, file_name+"_pred.png"))
del image, output, pred, pred_save
def load_config(config_path=None):
cfg = get_cfg_defaults()
if config_path is not None:
cfg.merge_from_file(config_path)
cfg.freeze()
return cfg
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--config_path", type=str, help="extra config file path", default=None)
parser.add_argument("--input_path", type=str, help="image path", required=True)
parser.add_argument("--output_path", type=str, help="extra config file path", required=True)
args = parser.parse_args()
main(args)
4. 評価コード
評価コードでは,学習済みモデルの性能を評価します.準備は学習済みモデルのパスを./config/default.pyに記入するだけです.はじめCityscapesのtestセットで評価しようと思っていたのですが,testセットのground truthは公開されていないんですね....ということでvalセットで評価を行うようにしました.
評価コード
import torch
import argparse
from utils import transforms as t
from utils.utils import Denormalize
from dataset.cityscapes import Cityscapes
from models.hrnet import HRNetV2
from torch.utils.data import DataLoader
from config.default import get_cfg_defaults
from metrics.metrics import SegMetrics
from tqdm import tqdm
import numpy as np
from PIL import Image
import os
def main(args):
cfg = load_config("./config/test_eval.yaml")
#cfg = load_config(args.config_path)
device = torch.device('cuda:'+str(cfg.CUDA.CUDA_NUM[0]) if cfg.CUDA.USE_CUDA and torch.cuda.is_available() else 'cpu')
print("device:"+str(device))
# prepare dataset
test_transform = t.PairCompose([
#t.PairRandomCrop(size=(512, 1024)),
t.PairToTensor(),
t.PairNormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
test_dataset = Cityscapes(root=cfg.DATASET.ROOT, split='val', target_type='semantic', transform=test_transform)
test_dataloader = DataLoader(test_dataset, batch_size=cfg.TEST.BATCH_SIZE, shuffle=True, num_workers=cfg.TEST.NUM_WORKERS, drop_last=True)
denorm = Denormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
# model
print("setting up model ...")
model = HRNetV2(cfg.MODEL.C, 19)
model.to(device)
if cfg.TEST.CHECKPOINT != '':
print("loading pretrained model ...")
model.load_state_dict(torch.load(cfg.TEST.CHECKPOINT))
# metric
metric = SegMetrics(19, device)
# results path
if cfg.TEST.RESULTS_NUM != 0 and not os.path.exists(cfg.TEST.RESULTS_PATH):
os.makedirs(cfg.TEST.RESULTS_PATH)
save_count = 0
model.eval()
for i , (image, target) in enumerate(tqdm(test_dataloader)):
with torch.no_grad():
image = image.to(device, dtype=torch.float32)
target = target.to(device, dtype=torch.long)
output = model(image)
pred = output.detach().max(dim=1)[1]
metric.update(target, pred)
if cfg.TEST.RESULTS_NUM != 0 and i % (len(test_dataloader) // cfg.TEST.RESULTS_NUM) == 0:
image_save = image[0].detach().cpu().numpy()
target_save = target[0].cpu().numpy()
pred_save = pred[0].cpu().numpy()
image_save = (denorm(image_save)*255).transpose(1, 2, 0).astype(np.uint8)
target_save = test_dataloader.dataset.decode_target(target_save).astype(np.uint8)
pred_save = test_dataloader.dataset.decode_target(pred_save).astype(np.uint8)
Image.fromarray(image_save).save(cfg.TEST.RESULTS_PATH+"/image_{}.png".format(save_count))
Image.fromarray(target_save).save(cfg.TEST.RESULTS_PATH+"/label_{}.png".format(save_count))
Image.fromarray(pred_save).save(cfg.TEST.RESULTS_PATH+"/predict_{}.png".format(save_count))
save_count += 1
score = metric.get_results()
print(score)
def load_config(config_path=None):
cfg = get_cfg_defaults()
if config_path is not None:
cfg.merge_from_file(config_path)
cfg.freeze()
return cfg
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--config_path", type=str, help="extra config file path", default=None)
args = parser.parse_args()
main(args)
結果
評価コードにより評価を行ったところ,以下のような結果になりました!
論文ではmIoUは80.2まで出ているのですが,同じようにやったのに私の環境では71.5でした....
実はImageNetなどでのpretrainが必要なのか?(HRNetV2-W40はpretrainedとは書いていなかったのですが...)他にもいろんなAugmentationをしてるのか?...
論文の結果を完全再現するのはとても難しいと痛感しました.
| mIoU | 71.5 |
|---|
| Class | IoU |
|---|---|
| road | 97.9 |
| sidewalk | 83.2 |
| building | 91.1 |
| wall | 51.2 |
| fence | 55.1 |
| pole | 60.8 |
| traffic light | 65.4 |
| traffic sign | 73.9 |
| vegetation | 91.7 |
| terrain | 61.7 |
| sky | 94.1 |
| person | 77.7 |
| rider | 56.3 |
| car | 93.3 |
| truck | 50.4 |
| bus | 67.6 |
| train | 71.6 |
| motorcycle | 43.6 |
| bicycle | 71.1 |
| input | prediction | ground truth |
|---|---|---|
 |
 |
 |
 |
 |
 |
まとめ
今回はHRNetV2の論文と実装を紹介しました.現在HRNetはさらに進化してTransformerを含むモデルになっており,トップクラスの性能を誇っています.気になる方はぜひ,本家のリポジトリなどを見てみてはいかがでしょうか.
参考文献
[1] J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, D. Liu, Y. Mu, M. Tan, X. Wang, W. Liu and B. Xiao "Deep High-Resolution Representation Learning for Visual Recognition," TPAMI, vol.43, no.10, pp.3349-3364, Apr 2020.
[2] K. Sun, B. Xiao, D. Liu, J. Wang, "Deep High-Resolution Representation Learning for Human Pose Estimation," CVPR, pp.5693-5703, 2019