はじめに
この記事はNRI xPaletteアドベントカレンダー12日目になります。
何かを作りたいと思いつつも、形にできない自分ですが、AIのアシストがあれば作れるんじゃないかと、今回試みました。
ラズベリーパイと画像認識AIを用いて値を判定して、結果をずんだもんの声で返すアプリガジェットを作りました。
ハードウェア構成
- ボード: Raspberry Pi 4 Model B 8GB
- カメラ: Raspberry Pi Camera Module V3
- その他: microSD(128GB), HDMI2microHDMI, USBケーブル&充電器
ソフトウェア・技術スタック
- AI: Gemini 2.5/3
- OS: Debian 12 (bookworm)
- 言語: Python 3.x
- 音声合成: VOICEVOX 0.25.0 (ずんだもん)
AIによる設計
まず、作りたいものをイメージして、下記のプロンプトを用いてGeminiで構成案を生成しました。
step by stepで思考してください。じっくり考えて良いです。試行中は英語で考えて良いです。
Rasberry Pi とV3 cameraを用いて、持ち運びしながら指さし確認を行う業務を、AIや画像認識技術を取り入れて確認した証跡および、指さし確認で確認した物体の情報(目盛りの値や色など)を保存する仕組みを作りたいです。
- AI技術にはGeminiを用いて画像解析し、指さし確認している目盛りの値や物を認識し、正しい値、物であるかを判定してください。
- 指さし確認時には目盛りの値および、「ヨシ」と発声するのでそれを認識して処理を行ってください
- プログラムはpythonを用いてください。
- 合っている場合、voicevoxのずんだもんの声で「確認OKなのだ」、「違うのだ」と返してください。
- 音声は、bluethoothのヘッドセットでやりとりをする想定で設定を行ってください
- この仕組みを作る当たってプログラムだけでなく、ディレクトリ構成や必要な設定などすべて記載してください
処理概要
アプリケーションのロジックについて、想定と合っているか確認します。
-
ユーザー
- 「ヨシ!」と発声
-
BTヘッドセット(マイク)
- 音声を拾い、Raspberry Piへ送信
-
Raspberry Pi (Python)
-
speech_recognitionが「ヨシ」を認識 -
picamera2がV3カメラで撮影
-
-
Raspberry Pi (Gemini API)
- 撮影した画像をGoogle Gemini APIに送信し、解析を依頼(例:「目盛りの値は?安全範囲か?」)
-
Gemini API (Cloud)
- 画像を解析し、結果(例:「100, はい」)を返す
-
Raspberry Pi (Python)
- Geminiの応答と事前定義(
config.json)を比較し、OK/NGを判定 - 結果を
logs/ディレクトリに保存(証跡画像とCSV)
- Geminiの応答と事前定義(
-
Raspberry Pi (VOICEVOX)
- 判定結果に基づき、読み上げテキスト(「確認OKなのだ」)をローカルのVOICEVOXエンジンに送信
-
VOICEVOX
- 音声データ(.wav)を生成して返却
-
Raspberry Pi (Python)
- 生成された音声データを再生
-
BTヘッドセット(スピーカー)
- ユーザーに「確認OKなのだ」とフィードバック
ディレクトリ構成
アプリケーション名は「Recognition(認識)」と「ずんだもん」を掛け合わせた「れこだもん(Recodamon)」にしました。
ディレクトリ構成は下記になります。
/home/work/recodamon/
├── main.py # メインプログラム
├── find_audio_devices.py # BTデバイスID検索用スクリプト
├── config.json # チェック項目の設定ファイル
├── .env # APIキー保存用
├── requirements.txt # Pythonライブラリ一覧
├── .venv/ # Python仮想環境
└── logs/
├── images/ # 証跡画像の保存場所
└── verification_log.csv # 確認結果のCSVログ
キッティング
OS インストール
Raspberry Pi Imager の公式ウェブサイトにアクセスし、「Download for Windows」をクリックし、インストールします。
使用するRaspberry Piを選択します。
モジュールの互換性など考えて、最新バージョンではなく、「Raspberry Pi OS (other)」から「Raspberry Pi OS (Legacy, 64-bit)」を選択しました。

後は、「ストレージを選択」で書き込み対象の SD カードを選択して、書き出します。
日本語設定
日本語入力できるように、fcitx-mozc をインストールします。
sudo apt update
sudo apt install fcitx-mozc
デスクトップの右端にキーボード表示が出ればOKです。
Bluetooth設定
ヘッドセットをペアリングモードにし、Add Deviceで接続します。
接続後、デスクトップ上の音量、マイクアイコンを右クリックし、どちらもヘッドセットに繋がっていることと、
Device ProfileがHSP/HFPであることを確認します。
VOICEVOXのインストール
公式サイトのダウンロードページから、Linux -> CPU(arm64) 版の インストーラ をダウンロードします。インストーラを実行してVOICEVOXをインストールします。
インストール後は、GUIから起動できることを確認します。
今回は、自動起動設定は行わず、都度GUIからVOICEVOXを起動することにしました。
システムライブラリおよびPython環境の構築
OSに必要なパッケージをインストールします。
sudo apt-get update
sudo apt-get install -y libopenjp2-7 portaudio19-dev libatlas-base-dev libgpiod2
sudo apt-get install -y python3-tk python3-pil.imagetk
今回は、高速なパッケージとプロジェクト管理ツールであるuvを用いました。
curl -LsSf https://astral.sh/uv/install.sh | sh
タイムアウトがよく発生したため、下記を.bashrcに入れました。
export UV_HTTP_TIMEOUT=1200
インストール後、設定を反映させるために一度ターミナルを閉じて、開き直します。
次に、仮想環境の作成をします。
cd work/recodamon
python3 -m venv --system-site-packages .venv ※1
uvで管理するパッケージを requirement.txtに書き出します。
google-generativeai
python-dotenv
SpeechRecognition
pyaudio
#picamera2 ※1
opencv-python-headless
numpy<2 ※2
requests
sounddevice
soundfile
vosk ※3
※1 No module named 'libcamera'となったため、OSパッケージにするため外しました。
--system-site-packages をオプションを付けることで、仮想環境の壁に「穴」を開け、OS側 (/usr/lib/python3/dist-packages) にある純正の picamera2 を参照できるようにします。
※2 ライブラリ(picamera2など)が期待している numpy のバージョンと合わないようでしたので、バージョン 2未満を指定しました。
※3 画像取得の合図である「ヨシ!」や、どの確認項目なのか選ぶ音声認識もGemini APIを用いていましたが、応答が遅いため、ローカルで判定するために入れました。
uv管理パッケージから外したので、下記を追加で行いました。
sudo apt install -y python3-picamera2 python3-libcamera
次に、uv管理パッケージをインストールします。
uv pip install -r requirements.txt
※自分の環境では、Raspberry PiのWifi速度が出なくて、時間が掛かりました。
タイムアウトが生じた際はタイムアウト値を伸ばしたり、uv pip install <パッケージ>で個々にインストールすると良いです。
Vosk音声認識モデルの設定
Voskを使用するには、日本語の学習済みモデルが必要です。
今回、軽量なモデル(vosk-model-small-ja-0.22)を用いました。
# モデルをダウンロードする
wget https://alphacephei.com/vosk/models/vosk-model-small-ja-0.22.zip
# 解凍する
unzip vosk-model-small-ja-0.22.zip
# 名前をシンプルに "model" に変更する
mv vosk-model-small-ja-0.22 model
これで、work/recodamon/model/ にモデルデータが入りました。
Recodamonの設定
Gemini API設定
Google AI Studioにログインし、 Get API key -> APIキー作成をクリックし、新しいプロジェクトを作成およびキー名の設定を行い、API keyを発行します。
.envにAPI keyを記載します。
GOOGLE_API_KEY=<作成したAPI key>
Recodamonのデバイス、VOICEVOX設定
Recodamonが呼び出すオーディオデバイスおよびVOICEVOXを設定します。
PyAudioからは、デバイス番号でしか指定できないようなので、スクリプトで調べます。
find_audio_devices.py
import pyaudio
def find_devices():
"""
利用可能なオーディオデバイスの一覧を出力する
"""
p = pyaudio.PyAudio()
info = p.get_host_api_info_by_index(0)
num_devices = info.get('deviceCount')
print("--- 入力デバイス (Input Devices) ---")
for i in range(0, num_devices):
device_info = p.get_device_info_by_host_api_device_index(0, i)
if (device_info.get('maxInputChannels')) > 0:
print(f"Index: {i}, Name: {device_info.get('name')}")
print("\n--- 出力デバイス (Output Devices) ---")
for i in range(0, num_devices):
device_info = p.get_device_info_by_host_api_device_index(0, i)
if (device_info.get('maxOutputChannels')) > 0:
print(f"Index: {i}, Name: {device_info.get('name')}")
p.terminate()
if __name__ == "__main__":
print("Bluetoothヘッドセットを接続した状態で実行してください。")
print("表示された 'Index' 番号を config.json に記載してください。")
print("ヘッドセット名(例: 'Jabra Evolve', 'bluez_...')を探してください。")
print("-" * 30)
find_devices()
uv run find_audio_devices.py
自身の環境では、inputが5, outputは4でした。
次に、device_config.jsonにデバイス番号を書きます。
{
"audio": {
"input_device_index": 5,
"output_device_index": 4
},
"voicevox": {
"url": "http://127.0.0.1:50021",
"speaker_id": 3 #ずんだもんのid
},
"trigger_word": "よし"
}
これでデバイス、VOICEVOXの呼び出し設定は完了です。
指さし確認項目の設定
今回、試しやすい計量計(food_scale)の値を確認することにしました。
[
{
"id": 1,
"check_point_name": "food scaleの確認",
"gemini_prompt": "計量計の画像を解析し、値が80gから100gの間であれば「はい」、それ以外は「いいえ」とどのような値と判断したかを答えてください。",
"expected_response_keyword": "はい",
"log_file": "logs/food_scale.csv"
},
{
"id": 2,
"check_point_name": "例:赤いバルブの開閉確認",
"gemini_prompt": "画像の赤いバルブを見てください。バルブのハンドルが縦(配管と平行)なら「開」、横(配管と垂直)なら「閉」と答えてください。",
"expected_response_keyword": "開",
"log_file": "logs/red_valve_B.csv"
}
]
実装コード
main.pyはほぼ100% Geminiに書いてもらいました。
エラーが出たら、内容をコピペして、修正を生成して、試すを繰り返しました。
main.py
import os
import json
import csv
import datetime
import time
import io
import threading
import tkinter as tk
from pathlib import Path
from PIL import Image, ImageTk
# --- ライブラリのインポート ---
import google.generativeai as genai
from dotenv import load_dotenv
import speech_recognition as sr
import sounddevice as sd
import soundfile as sf
import requests
from picamera2 import Picamera2
# 【変更点】Voskを直接インポート
import vosk
# Voskのログを抑制(ターミナルが埋まるのを防ぐ)
vosk.SetLogLevel(-1)
# --- グローバル変数 ---
current_status_text = "起動中..."
last_image_frame = None
is_running = True
# --- 1. 設定読み込みクラス ---
class ConfigManager:
def __init__(self):
load_dotenv()
self.api_key = os.getenv("GOOGLE_API_KEY")
if not self.api_key:
raise ValueError("GOOGLE_API_KEYが設定されていません。")
with open("device_config.json", "r", encoding="utf-8") as f:
self.device = json.load(f)
with open("checkpoints.json", "r", encoding="utf-8") as f:
self.checkpoints = json.load(f)
# モデルの存在確認
if not os.path.exists("model"):
raise FileNotFoundError("カレントディレクトリに 'model' フォルダが見つかりません。")
# --- 2. 機能関数群 ---
def generate_speech(text, config):
try:
url = config.device["voicevox"]["url"]
speaker = config.device["voicevox"]["speaker_id"]
res_query = requests.post(f"{url}/audio_query", params={"text": text, "speaker": speaker})
res_query.raise_for_status()
res_synth = requests.post(f"{url}/synthesis", params={"speaker": speaker}, json=res_query.json())
res_synth.raise_for_status()
return res_synth.content
except Exception as e:
print(f"VOICEVOXエラー: {e}")
return None
def play_audio(wav_data, config):
if wav_data is None: return
try:
device_idx = config.device["audio"]["output_device_index"]
data, samplerate = sf.read(io.BytesIO(wav_data))
sd.play(data, samplerate, device=device_idx)
sd.wait()
except Exception as e:
print(f"再生エラー: {e}")
# --- 【重要変更】Voskエンジンを直接使う音声認識 ---
def listen_audio(recognizer, microphone, config, vosk_model):
device_idx = config.device["audio"]["input_device_index"]
with microphone(device_index=device_idx) as source:
recognizer.adjust_for_ambient_noise(source, duration=0.5)
try:
update_status("聞き取り中...")
# 音声を録音 (SpeechRecognitionを使用)
audio = recognizer.listen(source, timeout=4.0, phrase_time_limit=3.0)
# --- ここからVosk直接処理 ---
# 録音データを 16000Hz, モノラル, 16bit PCM のRAWデータに変換
raw_data = audio.get_raw_data(convert_rate=16000, convert_width=2)
# Voskの認識器を作成
rec = vosk.KaldiRecognizer(vosk_model, 16000)
# 音声データを流し込む
if rec.AcceptWaveform(raw_data):
result = rec.Result()
else:
result = rec.FinalResult()
# JSONパース
result_dict = json.loads(result)
text = result_dict.get("text", "")
print(f"Vosk認識結果: {text}")
return text
except sr.WaitTimeoutError:
return None
except sr.UnknownValueError:
return None
except Exception as e:
print(f"認識エラー: {e}")
return None
def analyze_image(api_key, image, prompt):
try:
genai.configure(api_key=api_key)
model = genai.GenerativeModel('gemini-2.5-flash')
response = model.generate_content([prompt, image])
return response.text if response.parts else "エラー"
except Exception as e:
return f"エラー: {e}"
def log_result(ckpt_config, img_path, analysis, result):
path = Path(ckpt_config["log_file"])
path.parent.mkdir(parents=True, exist_ok=True)
with open(path, "a", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
if not path.exists():
writer.writerow(["Timestamp", "Checkpoint", "Image", "Result", "Response"])
writer.writerow([
datetime.datetime.now().isoformat(),
ckpt_config["check_point_name"],
img_path,
"OK" if result else "NG",
analysis.replace("\n", " ")
])
def update_status(text):
global current_status_text
current_status_text = text
print(f"Status: {text}")
# --- 4. メインロジック ---
def app_logic(config, picam2):
global is_running
r = sr.Recognizer()
m = sr.Microphone
# --- 【重要】Voskモデルをここで一度だけロード ---
update_status("モデル読み込み中...")
try:
# フォルダパスを直接指定してモデルをロード
vosk_model = vosk.Model("model")
print("Voskモデル読み込み完了")
except Exception as e:
update_status(f"モデルエラー: {e}")
print("modelフォルダが正しいか、中身が空でないか確認してください。")
return
# --- A. 起動時のチェックポイント選択 ---
update_status("チェックポイント選択中")
intro = "チェックポイントを選んでください。"
for cp in config.checkpoints:
intro += f"{cp['id']}番、{cp['check_point_name']}。"
intro += "番号をどうぞ。"
play_audio(generate_speech(intro, config), config)
selected_cp = config.checkpoints[0]
for _ in range(10):
# vosk_model を引数で渡す
text = listen_audio(r, m, config, vosk_model)
if text:
text = text.replace(" ", "")
found = False
for cp in config.checkpoints:
str_id = str(cp['id'])
jp_num = ["ゼロ","一","二","三","四","五"][cp['id']] if cp['id'] < 6 else ""
if str_id in text or jp_num in text:
selected_cp = cp
found = True
break
if found:
play_audio(generate_speech(f"{selected_cp['check_point_name']}、開始なのだ。", config), config)
break
else:
play_audio(generate_speech("番号がわからないのだ。", config), config)
# --- B. メインループ ---
trigger = config.device["trigger_word"]
while is_running:
update_status(f"待機中: 「{trigger}」")
# vosk_model を引数で渡す
text = listen_audio(r, m, config, vosk_model)
if text:
text = text.replace(" ", "")
if trigger in text:
update_status("認識しました!")
play_audio(generate_speech("確認するのだ。", config), config)
# 撮影 & 保存
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
img_path = Path("logs/images") / f"{timestamp}.jpg"
img_path.parent.mkdir(parents=True, exist_ok=True)
array = picam2.capture_array()
pil_image = Image.fromarray(array)
pil_image.save(img_path, quality=95)
# 解析
update_status("AI解析中...")
analysis = analyze_image(config.api_key, pil_image, selected_cp["gemini_prompt"])
is_ok = selected_cp["expected_response_keyword"] in analysis
log_result(selected_cp, img_path, analysis, is_ok)
update_status(f"判定結果: {'OK' if is_ok else 'NG'}")
msg = "確認オッケーなのだ!" if is_ok else "違うのだ。"
play_audio(generate_speech(msg, config), config)
time.sleep(0.1)
# --- 5. GUIセットアップ ---
def main():
global is_running
try:
config = ConfigManager()
except Exception as e:
print(f"設定エラー: {e}")
return
# カメラ起動
picam2 = Picamera2()
# GUI表示用にサイズを小さくする
config_cam = picam2.create_preview_configuration(main={"size": (640, 480), "format": "RGB888"})
picam2.configure(config_cam)
picam2.start()
root = tk.Tk()
root.title("指さし確認AI (Vosk Direct)")
root.geometry("800x600")
lbl_title = tk.Label(root, text="AI指さし確認モニター", font=("Arial", 20))
lbl_title.pack(pady=10)
lbl_video = tk.Label(root)
lbl_video.pack()
lbl_status = tk.Label(root, text="起動中...", font=("Arial", 16), fg="blue")
lbl_status.pack(pady=20)
def on_close():
global is_running
is_running = False
picam2.stop()
root.destroy()
root.protocol("WM_DELETE_WINDOW", on_close)
thread = threading.Thread(target=app_logic, args=(config, picam2))
thread.daemon = True
thread.start()
def update_gui():
lbl_status.config(text=current_status_text)
try:
# プレビュー表示
frame = picam2.capture_array()
img = Image.fromarray(frame)
imgtk = ImageTk.PhotoImage(image=img)
lbl_video.imgtk = imgtk
lbl_video.config(image=imgtk)
except Exception:
pass
if is_running:
root.after(50, update_gui)
update_gui()
root.mainloop()
if __name__ == "__main__":
main()
gemini-1.5-flashからgemini-2.5-flashに変更や、リトライ回数のパラメータ微調整はしましたが、コードに関して、語れることが無いため、実装については以上です。
やってみた
アプリ起動
準備が整いましたので、早速やってみます。
まず、VOICEVOXを起動します。次に、main.pyを実行します。
uv run main.py
起動しました!

しばらくすると、チェックポイントをずんだもんが読み上げますので、「一番(food scale)」を発声して、選択します。
最初、うまく認識しなくて、延々一人で夜中に「一番!」と発声するのは恥ずかしかったです。。。
いよいよメインの画像認識AIによる判定を行います。
OKの場合
チェックポイントが決まりましたので、次に「よし!」と発声します。
「よし!」を認識すると、画像を取得して、Gemeni APIにcheckpoints.jsonで設定したコンテキストと合わせて送られます。
その結果、OKが返ってきました!!
OKの場合、ずんだもん から「確認オッケーなのだ!」と音声回答が返ってきました。
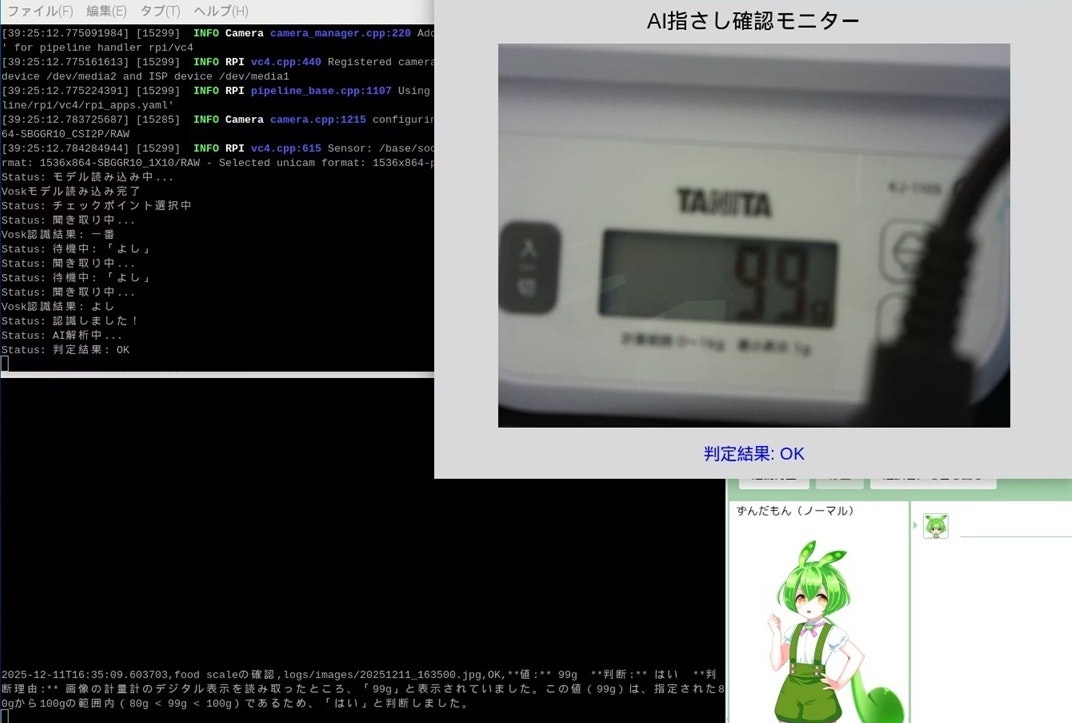
ログには判断理由なども出力されます。
2025-12-11T16:35:09.603703,food scaleの確認,
logs/images/20251211_163500.jpg,
OK,
**値:** 99g
**判断:** はい
**判断理由:** 画像の計量計のデジタル表示を読み取ったところ、「99g」と表示されていました。この値(99g)は、指定された80gから100gの範囲内(80g < 99g < 100g)であるため、「はい」と判断しました。
NGの場合
105gにして、判断がNGになるか試しました。
NGの場合なので、ずんだもん から「違うのだ」が返ってきました。
結果としては想定通りのNGでしたが、画面の反射の影響なのか10.5と判断されたようです。改良の余地がありそうです。
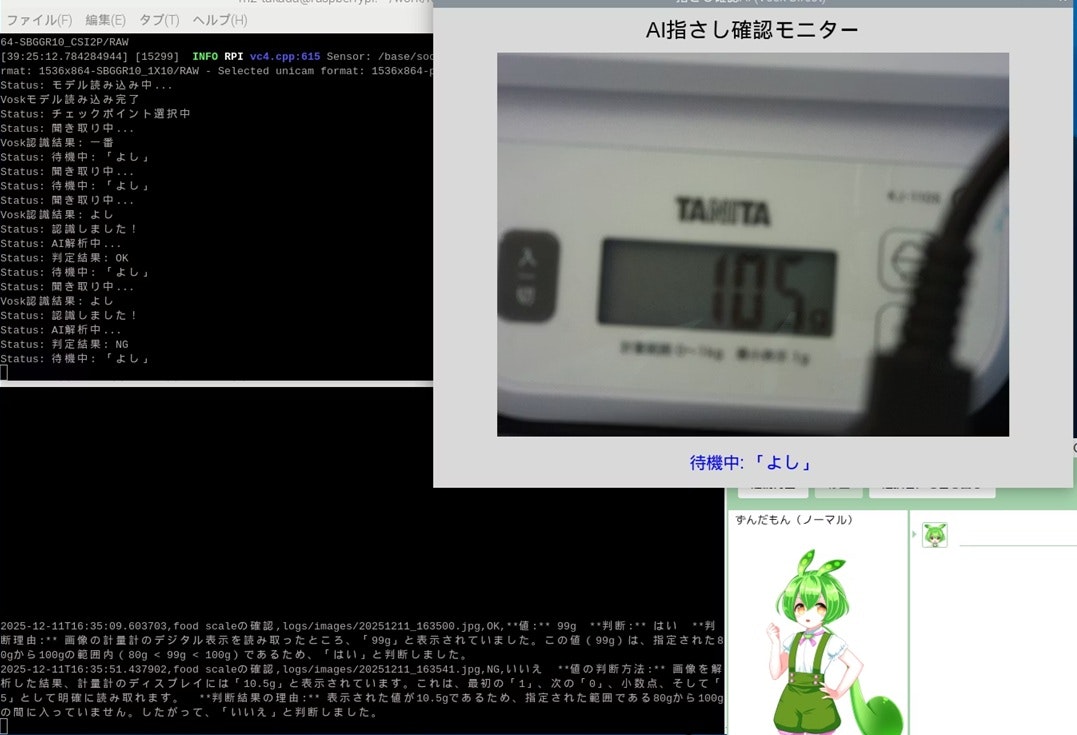
2025-12-11T16:35:51.437902,food scaleの確認,logs/images/20251211_163541.jpg,
NG,
いいえ
**値の判断方法:** 画像を解析した結果、計量計のディスプレイには「10.5g」と表示されています。これは、最初の「1」、次の「0」、小数点、そして「5」として明確に読み取れます。
**判断結果の理由:** 表示された値が10.5gであるため、指定された範囲である80gから100gの間に入っていません。したがって、「いいえ」と判断しました。
まとめ
開発・準備の流れを生成AIに任せ、また、Pythonコードをほぼ書くことなく、アプリを作ることができました。よく途中で頓挫する自分ですが、生成AIによって形に持って行くことが容易にできました。
ただ、当然ながら、生成されものそのままではうまく動かず、問題解決には人の判断を要することもあり、うまくAIを使いこなさなければと思いました。
今後の改良としては、下記の要素を考えております。
今回、単純な値でしたが、メーターや物体状態の指差し確認ができるようにして、現場、フィールドワークで使えるものにしたいです。その場合、Raspberry Piではなく、スマホアプリで作ったほうがいいかもしれません。検討します。
- 指差し確認の判定追加
- GPS情報の判定追加
- 応答速度の向上(音声認識判定、定型文の応答)
- UIの改良(グラフィカルに応答を返す)
利用キャラクター
ずんだもん:VOICEVOX:ずんだもん