今年も35℃を超える猛暑日が増えてきましたね。
毎年猛暑、酷暑と言っていますが、過去からどれくらい気温の変化があるのかをヒートマップで可視化されている下記ブログが面白かったので、エクセル(パワークエリ、パワーピボット)でまねしてみました。
データの取得
気象庁のページから過去データを取得しています。
https://www.data.jma.go.jp/risk/obsdl/index.php
今回取得したデータは、「大阪府」「日別値」「日平均気温、日最高気温
、日最低気温」の条件です。
一度でのデータ取得上限があるので、期間を調整しつつcsvダウンロードします。
csvを一つのフォルダへまとめておきます。
エクセルでヒートマップ
パワークエリでcsv読込み
エクセル2019での内容です。
- 「データ」-「データの取得」-「ファイルから」-「フォルダーから」で、csvを保存した場所を選択します
- 「データの結合と変換」で、「OK」
- これで複数のcsvファイルを一つにまとめてパワークエリで取得できました
- この内容はシートに書き出す必要は無いので、「閉じて次に読み込む」で「接続の作成のみ」と「このデータをデータモデルに追加する」にチェックして「OK」

データの変換
パワークエリのエディターでの作業
- ダウンロードしたcsvのままでは不要な情報があるので削除する
- 以下は結合されたソースではなく、「ヘルパークエリ」-「サンプルファイルの変換」で作業する
- 下記はGUI操作で生成されたソースそのままです(詳細エディターの内容)
サンプルファイルの変換
let
ソース = Csv.Document(パラメーター1,[Delimiter=",", Columns=10, Encoding=932, QuoteStyle=QuoteStyle.None]),
削除された他の列 = Table.SelectColumns(ソース,{"Column1", "Column2", "Column5", "Column8"}),
削除された最初の行 = Table.Skip(削除された他の列,6),
#"名前が変更された列 " = Table.RenameColumns(削除された最初の行,{{"Column1", "日付"}, {"Column2", "平均気温"}, {"Column5", "最高気温"}, {"Column8", "最低気温"}})
in
#"名前が変更された列 "
- 上記の変更をすると、結合したソースの方でエラーになります
- 列名を変えたり、列削除したりしたのでエラーになっています
- エラーになっている「変更された型」を削除して、適当な型へ手動で変更する
-
"C:\Users\xxx保管場所xxx\過去の天気_気象\data"はcsvを保存しているフォルダのこと
data
let
ソース = Folder.Files("C:\Users\xxx保管場所xxx\過去の天気_気象\data"),
#"フィルター選択された非表示の File1" = Table.SelectRows(ソース, each [Attributes]?[Hidden]? <> true),
カスタム関数の呼び出し1 = Table.AddColumn(#"フィルター選択された非表示の File1", "ファイルの変換", each ファイルの変換([Content])),
#"名前が変更された列 1" = Table.RenameColumns(カスタム関数の呼び出し1, {"Name", "Source.Name"}),
削除された他の列1 = Table.SelectColumns(#"名前が変更された列 1", {"Source.Name", "ファイルの変換"}),
展開されたテーブル列1 = Table.ExpandTableColumn(削除された他の列1, "ファイルの変換", Table.ColumnNames(ファイルの変換(#"サンプル ファイル"))),
削除された列 = Table.RemoveColumns(展開されたテーブル列1,{"Source.Name"}),
変更された型 = Table.TransformColumnTypes(削除された列,{{"日付", type date}, {"平均気温", type number}, {"最高気温", type number}, {"最低気温", type number}})
in
変更された型
- これで複数csvをまとめた気温の一覧ができました
日付テーブルをつくる
- 日付テーブルを別でつくることにします
- 「データ」-「データモデルの管理」を開く
- 「デザイン」-「日付テーブル」-「新規作成」で日付テーブルができる
- 「リレーションシップの作成」で、気温データの日付と日付テーブルのリレーションを設定する
- 日付テーブルに「日」だけを取り出した列を追加する
- 列の追加で
=FORMAT([Date],"d")として「データ型」を「整数」に設定する
- 列の追加で
シート上に表示する
パワーピボットでの内容です。
- 「挿入」-「ピボットテーブル」-「データモデルから」で「OK」
- 「ピボットテーブルのフィールド」を設定する
- 列:MonthNumber、dayNo
- 行:Year
- Σ値:合計/平均気温 ⇒最終的に:fx区分

ピボットテーブルの見た目を設定
- 小計/総計とかは不要なので非表示にする
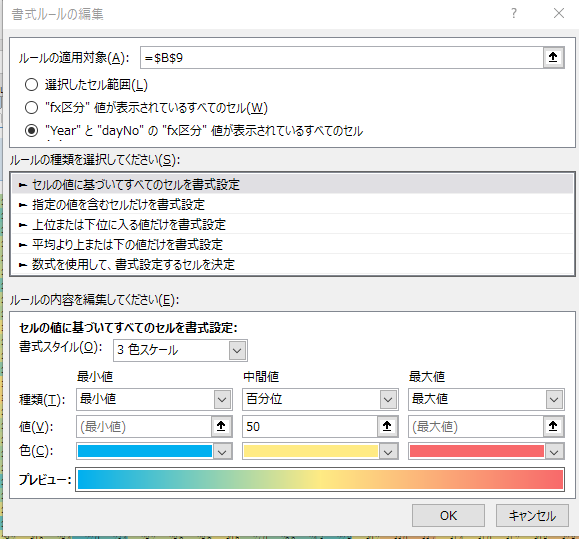
- 「ホーム」-「条件付き書式」で「新しいルール」をつくる
- ルールの適用対象:"Year"と"dayNo"の"fx区分"値が表示されているすべてのセル
- ルールの種類:セルの値に基づいてすべてのセルを書式設定
- ルールの内容を編集:書式スタイル:3色スケールで青(最小値)、黄(百分位_50)、赤(最大値)
おかしな値
- おかしな値がでている
- csvで重複した日付データがあったようで合計されていた
- パワークエリの方で、「重複の削除」を追加しておく
月スライサー
- 「挿入」-「スライサー」で「MonthNumber」を追加
- これで6,7,8,9月だけにフィルターしたり変える
- 色のグラデーションはフィルターされた内容での「最小~百分位_50~最大」となるのでいい感じになってくれる
- スライサーで切り替えると値の幅で自動調整されるのがイヤな時は、「ピボットテーブルオプション」から「更新時に列幅を自動調整する」のチェックを外す
集計切り替えスライサーの追加
- 平均気温、最高気温、最低気温をスライサーで切り替えられるようにする
- 「空のクエリ」を追加して以下を詳細エディターで入力
区分
let
ソース = #table({"区分"}, {{"平均気温"}, {"最高気温"}, {"最低気温"}})
in
ソース
- 「接続先の作成のみ」と「このデータをデータモデルに追加する」にチェックして「OK」
- このテーブルにはリレーションシップは付けないで、独立したテーブルのままにします
- それぞれ集計用のメジャーを作っておきます
dax
メジャー名:fx平均気温
=MAX('data'[平均気温])
メジャー名:fx最高気温
=MAX('data'[最高気温])
メジャー名:fx最低気温
=MAX('data'[最低気温])
- スライサーの選択で上記のメジャーを切り替えるものを作ります
dax
メジャー名:fx区分
=IF(
COUNTROWS(VALUES('区分'[区分])) = 1,
SWITCH(
VALUES('区分'[区分]),
"平均気温", 'data'[fx平均気温],
"最高気温", 'data'[fx最高気温],
"最低気温", 'data'[fx最低気温]
)
)
-
fx区分のみをΣ値へ入れます - 「挿入」-「スライサー」で「区分」を表示する
- 区分スライサーを変更する事で内容も変更されます!
- 使用するメジャーを変えたので、条件付き書式が無くなるので付けなおす
完成したヒートマップ
データ量も多くて、条件付き書式を設定しているので、とても重くなります。
エクセルでやる事ではないですね。
-
平均気温 6-9月

-
範囲 (最高気温 - 最低気温) 7-8月
-
青色:一日での差が小さい 赤色:一日での差が大きい
-
昔より、一日の中での気温差が小さくなっていると見えなくもない?

-
という2つのヒートマップより、平均気温が上がっていて、暑いままの日が多い
可視化の集計方法
行を年で、列を月/日で表すというのがおもしろい方法で知れてよかった!
これまでは日付の場合、ただ横とか縦に伸びていく表現方法しか考えた事なかった。