概要
主要クラウドデータウェアハウス(Snowflake、Microsoft Fabric、AWS Redshift、Google Cloud Bigquery)へのPythonからのデータ書き込み手法比較 で紹介したAWS Redshiftのウェアハウスに対する外部からPythonでデータ書き込み方法に関する補足に関する記事となる.
AWS Redshift に外部システム(例:ETLツールやスクリプトなど)からデータを書き込むには,適切な IAM 権限の設定が必要となる.本記事では,AWS マネジメントコンソール上で実施すべき IAM の設定手順を解説する.
1. アクセスキーの作成
外部システムから AWS にアクセスするには,アクセスキー(Access Key ID / Secret Access Key)の作成が必要である.
手順:
IAM > ユーザ > セキュリティ認証情報 > アクセスキー の順に遷移し,新しいアクセスキーを作成する.
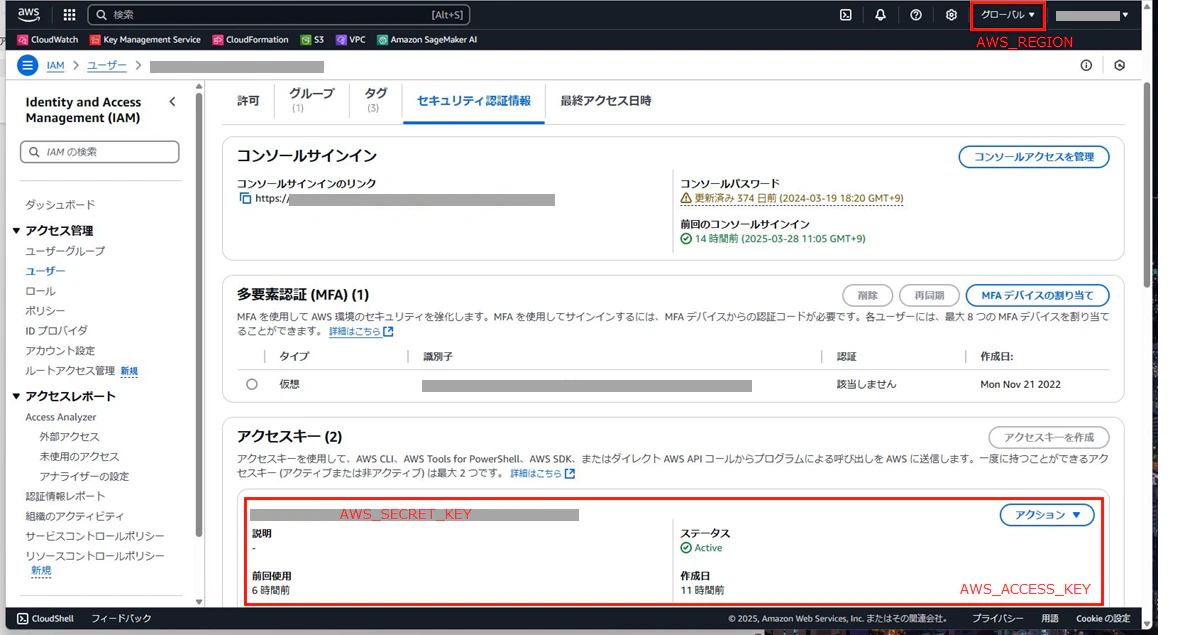
アクセスキーは一度しか表示されないため,必ずダウンロードし安全に保管すること.
2. IAM ポリシーの付与
Redshift へのアクセスや他の AWS リソース操作を許可するためには,ユーザーまたはユーザーグループに対して適切な IAM ポリシーを付与する必要がある.
手順:
IAM > ユーザグループ > 許可 > 許可を追加 より,AWSCostAndUsageReportAutomationPolicy を追加する.

必要に応じて
AmazonRedshiftFullAccessやカスタムポリシーを使用してもよい.
3. ユーザーのユーザーグループへの追加
ポリシーが適用されるように,対象の IAM ユーザーをユーザーグループへ追加する.
手順:
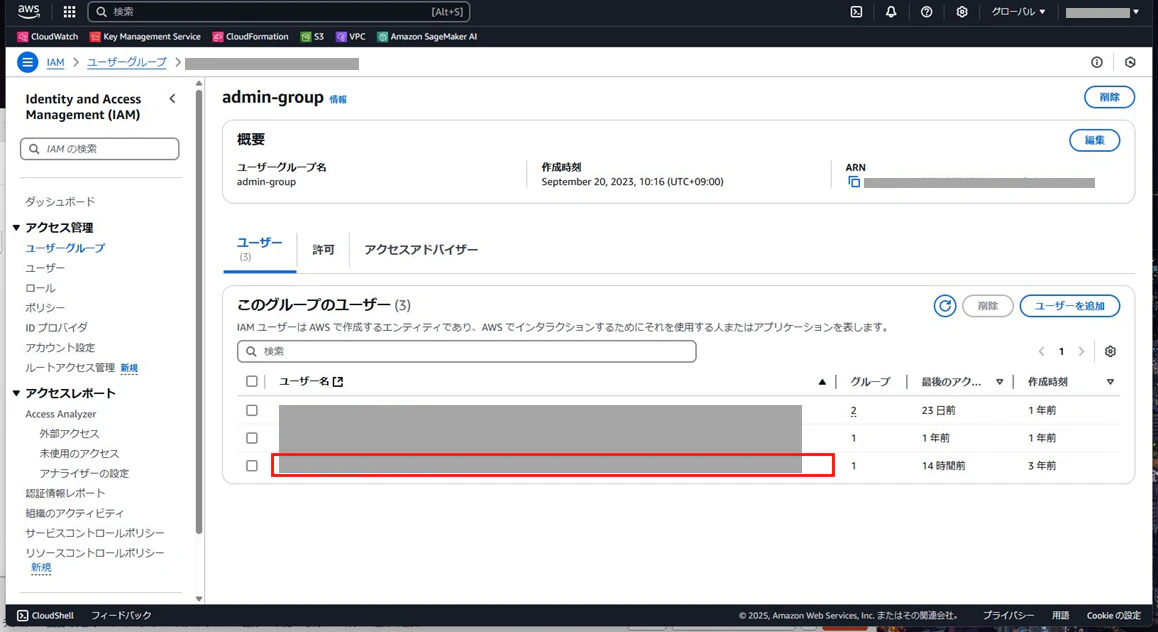
IAM > ユーザグループ > ユーザ > 必要なユーザの追加 を選択する.
4. Redshift クラスター情報の確認
Python コードで Redshift に接続するには,以下の 2 つの情報が必要である.
-
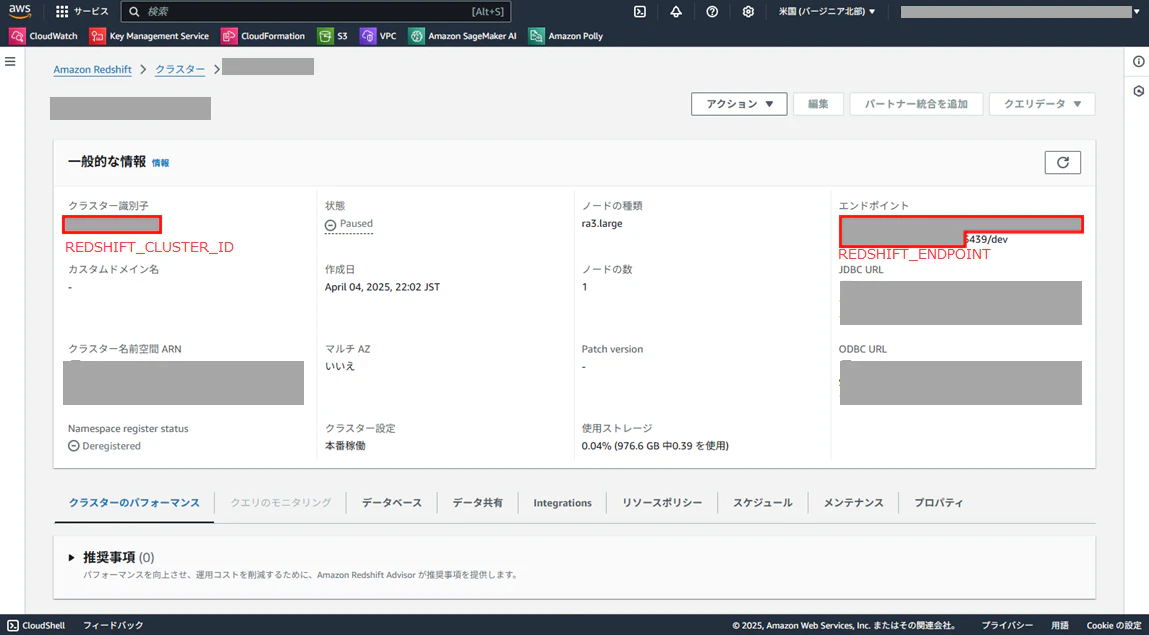
REDSHIFT_ENDPOINT:クラスターのエンドポイント(JDBC 接続先) -
REDSHIFT_CLUSTER_ID:クラスター ID(Boto3 経由で一時認証情報を取得する際に必要)
これらの情報は,AWS マネジメントコンソールの Redshift クラスター画面から確認できる.
① Redshift クラスターの一覧画面を開く
AWS 管理コンソールで「Amazon Redshift」を検索し,左メニューの「クラスター」から対象のクラスターを選択する.
② クラスター詳細からエンドポイントを確認
クラスター詳細ページに移動すると,「エンドポイント」欄に REDSHIFT_ENDPOINT が表示されている.以下のような形式である:
5. 接続確認
IAM 設定後は,外部システム(AWS CLI,SDK,ETLツールなど)から Redshift に対し,正常に接続および書き込みができることを確認する.IAM 設定が完了した後,実際に Redshift にデータを書き込むことで接続確認を行うことができる.以下は Python による簡易な接続およびデータ書き込みのサンプルコードである.
import boto3
import psycopg2
from psycopg2.extras import execute_values
# Redshift クラスター情報
host = '<REDSHIFT_ENDPOINT>'
port = 5439
dbname = 'dev'
cluster_id = '<REDSHIFT_CLUSTER_ID>'
region = 'us-east-1'
db_user = 'awsuser'
# AWS 認証情報
aws_access_key = '<AWS_ACCESS_KEY_ID>'
aws_secret_key = '<AWS_SECRET_ACCESS_KEY>'
# スキーマとテーブル
schema = 'demo_schema'
table = 'sample_data'
# Boto3 経由で一時認証情報を取得
client = boto3.client(
'redshift',
region_name=region,
aws_access_key_id=aws_access_key,
aws_secret_access_key=aws_secret_key
)
credentials = client.get_cluster_credentials(
DbUser=db_user,
DbName=dbname,
ClusterIdentifier=cluster_id,
DurationSeconds=3600
)
# psycopg2 を用いて Redshift に接続
conn = psycopg2.connect(
host=host,
port=port,
dbname=dbname,
user=credentials['DbUser'],
password=credentials['DbPassword'],
sslmode='require'
)
cur = conn.cursor()
# テーブル作成(存在しない場合のみ)
cur.execute(f"""
CREATE SCHEMA IF NOT EXISTS {schema};
CREATE TABLE IF NOT EXISTS {schema}.{table} (
id INT IDENTITY(1,1),
name VARCHAR(100),
age INT
)
""")
conn.commit()
# データ挿入
data = [('Alice', 30), ('Bob', 25)]
execute_values(
cur,
f"INSERT INTO {schema}.{table} (name, age) VALUES %s",
data
)
conn.commit()
# 挿入確認
cur.execute(f"SELECT * FROM {schema}.{table} LIMIT 5")
for row in cur.fetchall():
print(row)
cur.close()
conn.close()
まとめ
| ステップ | 内容 |
|---|---|
| 1 | アクセスキーの作成 |
| 2 | IAM ポリシーの追加 |
| 3 | ユーザーをグループに追加 |
| 4 | 接続確認 |