Amazon OpenSearch Service と S3 の zero-ETL integration (Direct Query) は 2023/12 時点で Preview の機能です。
はじめに
2023年11月に「Amazon OpenSearch Service の Amazon S3 とのゼロETL統合」が発表されました。
OpenSearchについて概要に触れつつ、今回のゼロETL統合によりどんなことが変わったのかを中心にご紹介します。
- OpenSearchの概要
- 検証① 従来のデータ取り込み方法
- 検証② 今回リリースされた方法
- 追加検証
OpenSearchとは
- オープンソースの分散型検索・分析パッケージ
- OpenSearch Projectで開発される

大きく以下で構成されます。
- OpenSearch:データストア、検索エンジン
- OpenSearch Dashboards:可視化、UI ツール
OpenSearchの開発経緯
もともとElasticsearchと呼ばれるオープンソースです。
2021年1月に開発元のElasitic社が独自ライセンスにすることを発表。
AWSをはじめとする企業が参加したprojectによりフォークされApache License 2.0に準拠したオープンソースとしてOpenSearchがリリースされました。
その際、サービス名も以下のように変更になっています。
- Elasticsearch → OpenSearch
- Kibana → OpenSearch Dashboard
OpenSearchのユースケース
全文検索(自然言語、近似最近傍探索、ベクトル検索)、ストリーム処理分析、分析やAI/MLのベクトルDBとして利用されます。
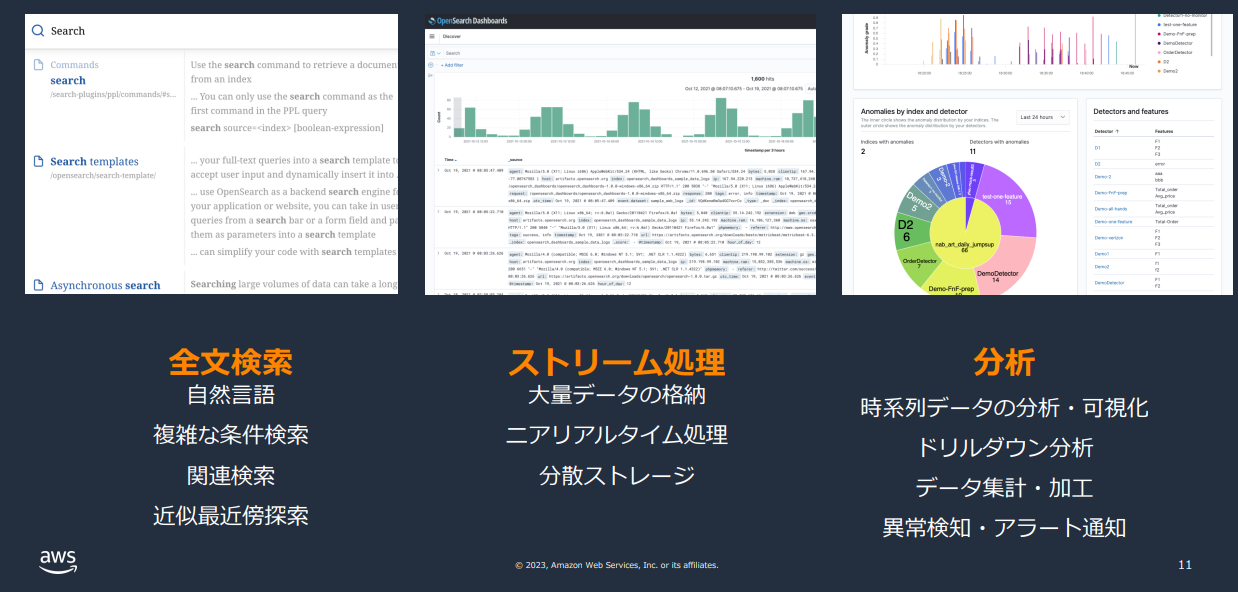
引用1
Amazon OpenSearch Service とは
Amazon OpenSearch Service(以下OSS)はOpenSearchクラスターのデプロイ、管理、スケーリングが可能なマネージドサービスです。
サーバレスを選択することも可能です。
前提知識
OpenSearch自体はとても奥の深い内容になります。
概要のみの説明になりますが、前提知識をご紹介します。
必要に応じて参考サイトをご確認ください。
1. 利用方法
データの登録や検索・分析はクラスタのREST APIを通したやり取りで行われます。
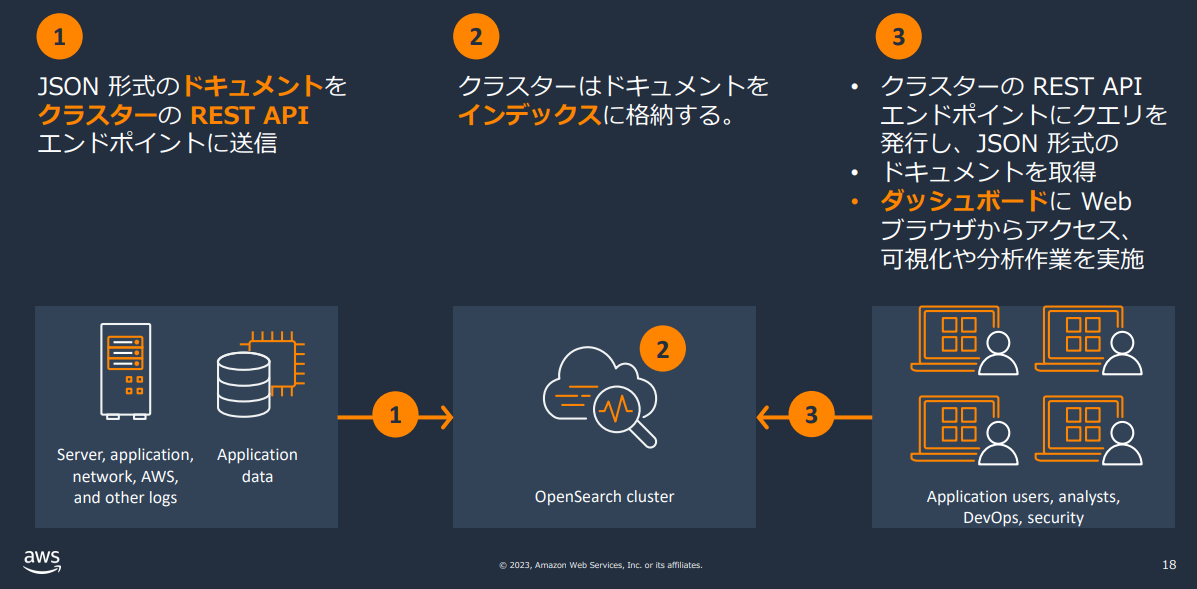
引用1
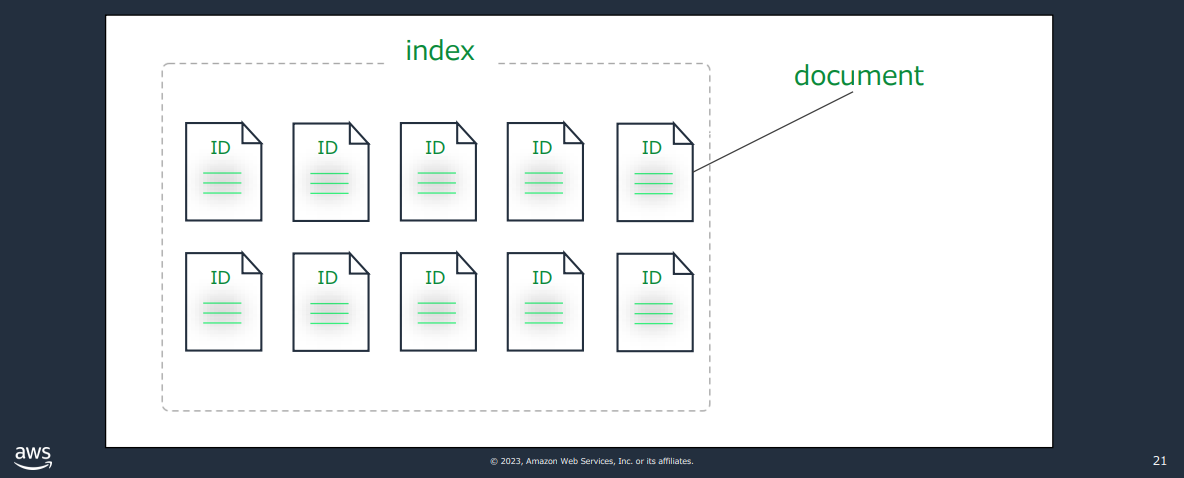
2. 用語
OpenSearchでは通常のテーブルとデータの持ち方が異なります。
- ドキュメント:JSON形式のデータ(一般的なRDBのレコードに相当)
- インデックス:ドキュメントの格納先(テーブルに相当)
- マッピング:データ型の定義(カラム名やデータ型等に相当)
データとマッピング
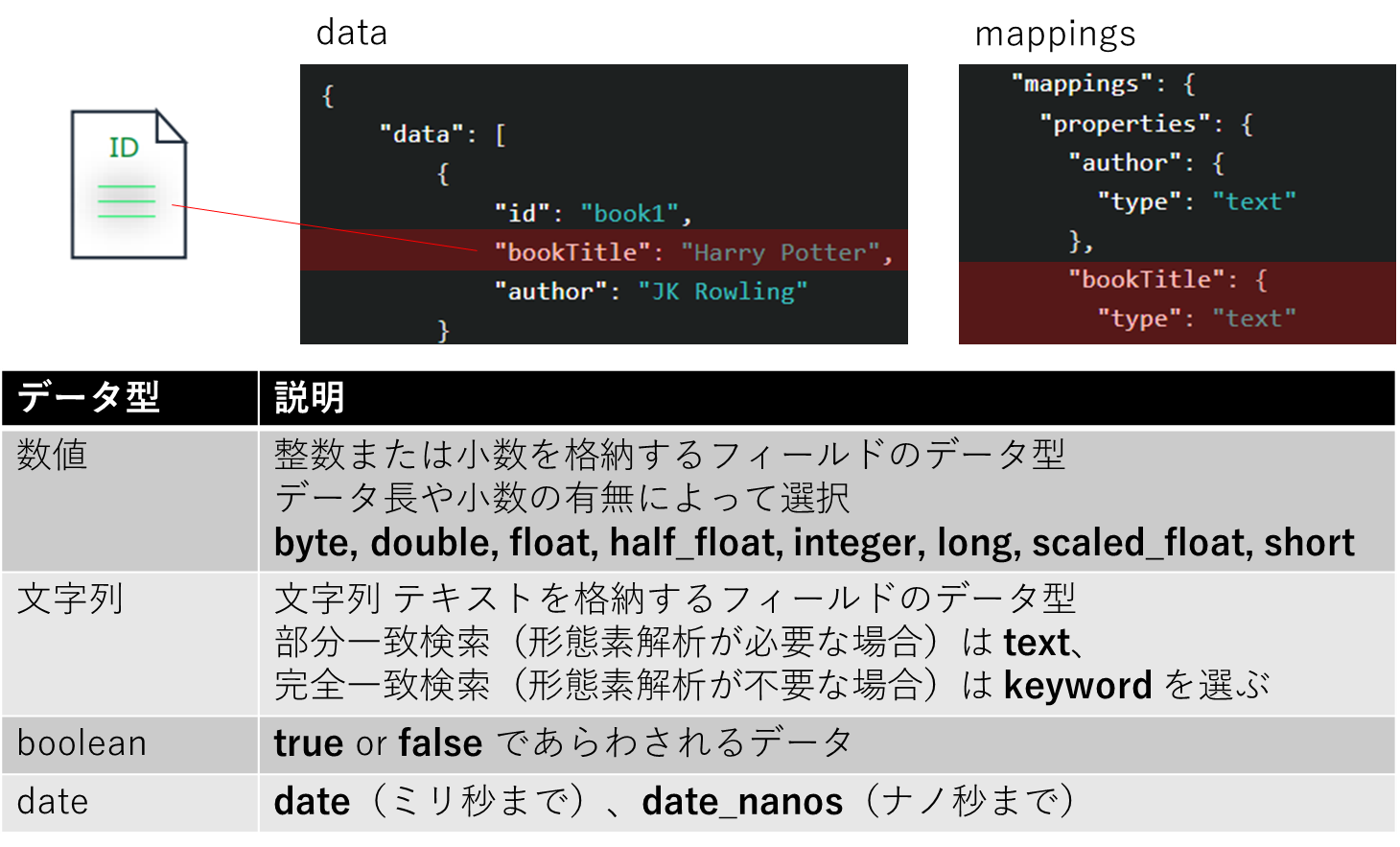
https://opensearch.org/docs/2.0/opensearch/mappings/
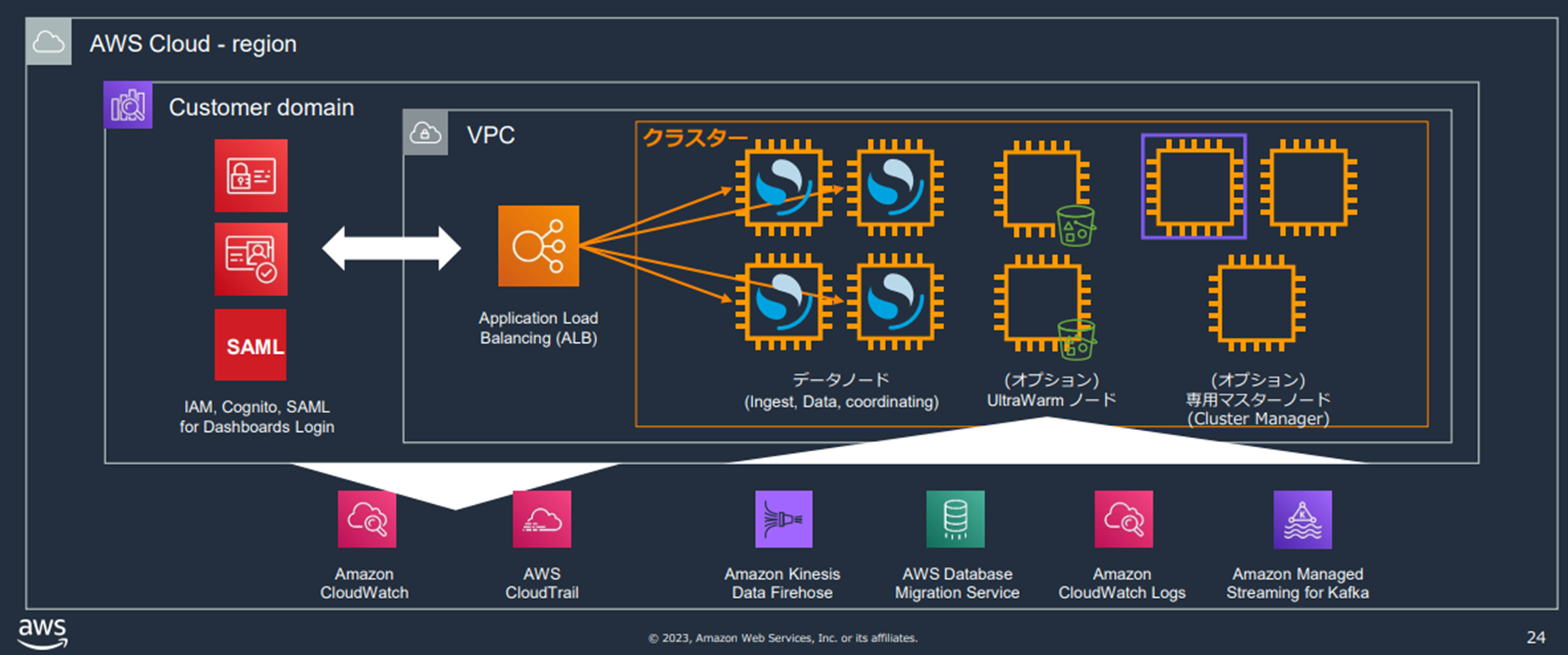
OSSにおけるドメインとは
- OpenSearch クラスター、およびクラスターと連携する AWS サービスの総称
- ノードはデータノード、専用マスターノード、UltraWarm ノードの 3 種類
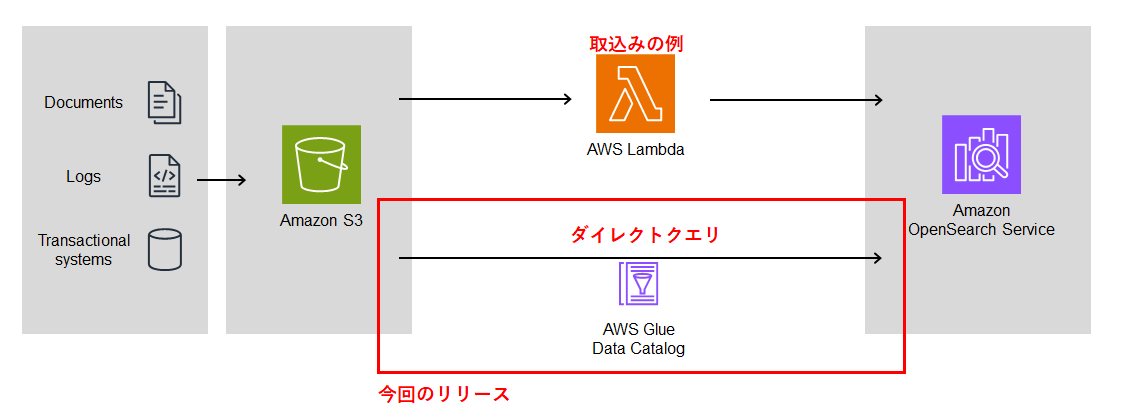
今回のリリース内容
従来の方法ではOpenSearchにデータをロードすることでのみ利用が可能でした。
今回のプレビュー版リリースにより以下が実現できます。
- Glueテーブルを利用することでS3にあるデータを直接クエリできる(ダイレクトクエリ)
- データの複製や複数の分析ツールの管理に伴う運用の複雑さを軽減できる
環境準備
利用条件
利用にあたって以下の条件があります。
- OpenSearchドメインのバージョン2.11以降で対応
- リージョン:東京、フランクフルト、アイルランド、バージニア、オハイオ、オレゴン
- S3へのダイレクトクエリはGlueデータカタログが必要
- サポートされるデータ型は、Parquet、CSV、および JSON のみ
- OpenSearchドメインとGlueデータカタログは同じAWSアカウントのみ
- S3はドメインと同じリージョンに置く(別アカウントでもよい)
- Athena 経由で作成されたテーブルはサポートされない
- OpenSearch Serverless では使用できない
料金
Amazon OpenSearch Service では「インスタンス時間、必要なストレージの量、OSSとの間で転送されるデータ」によって課金されます。
インスタンスの種類は以下の通りです。オンデマンドとリザーブの機能は全く同じものです。
| 種類 | 料金 |
|---|---|
| オンデマンドインスタンス | 1時間ごとの利用によって課金される |
| リザーブドインスタンス | 1年か3年間でインスタンスを予約することができ費用を抑えられる |
| サーバレス | ワークロードによって消費されたリソースに対してのみ課金される |
詳細は料金ページをご確認ください。
ドメインの作成
OSSのダッシュボードからドメインの作成を選択します。
画面の案内に沿って最小構成で設定します。
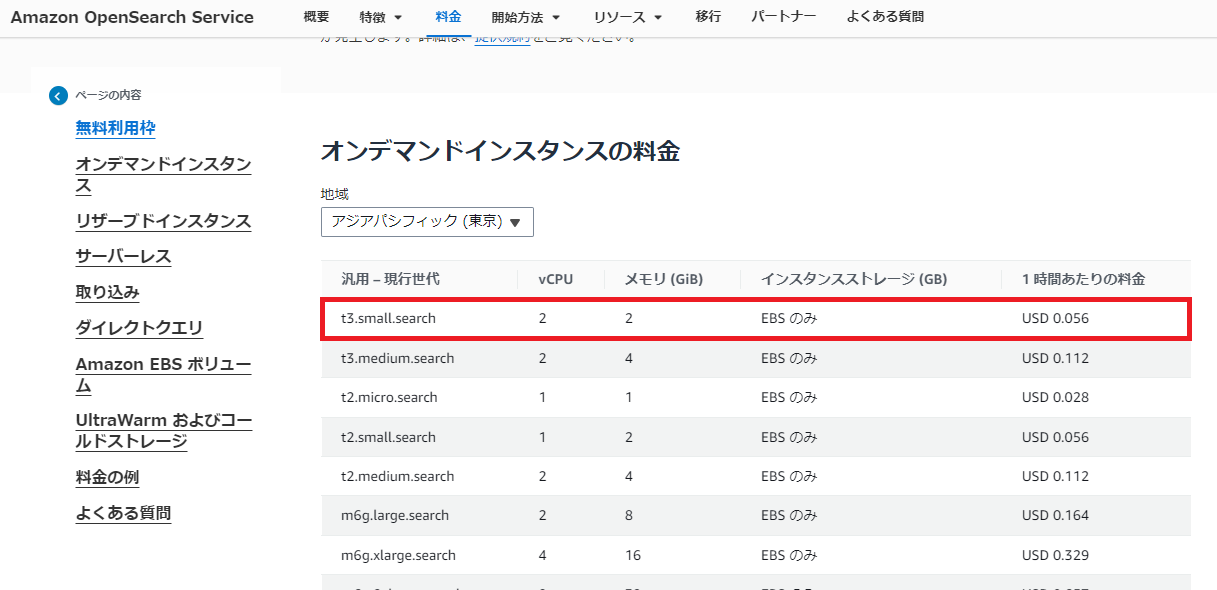
インスタンスはテスト用の「t3.small.search」を使用します。
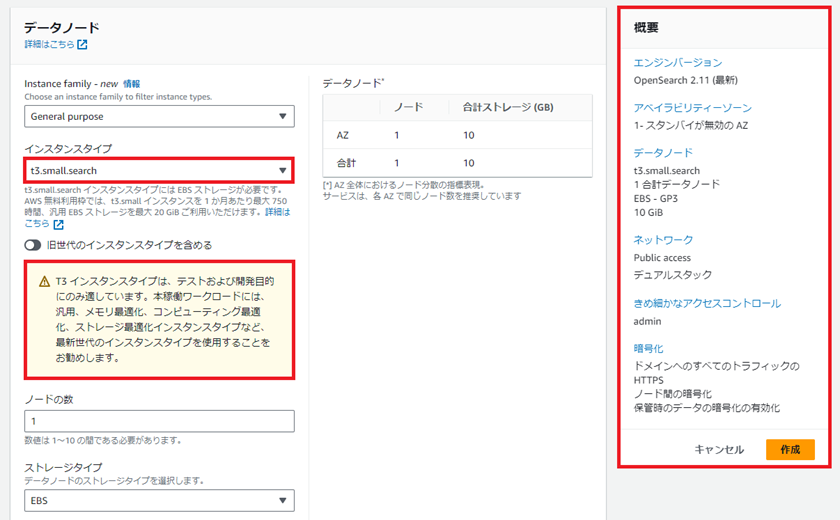
東京リージョンでは1時間当たりUSD0.056です。
今回の構成は以下の通りです。
- AZ:1
- インスタンス:t3.small.search(テスト用最小)
- ノード:1
- ストレージ:EBS
- EBS:汎用SSD gp3
- EBSサイズ:10(最小)
- ネットワーク:パブリック、デュアルスタック(IPv4、IPv6)
- マスターユーザの作成:ユーザ名admin/パスワード
作成を押して数分後にドメインが作成されます。
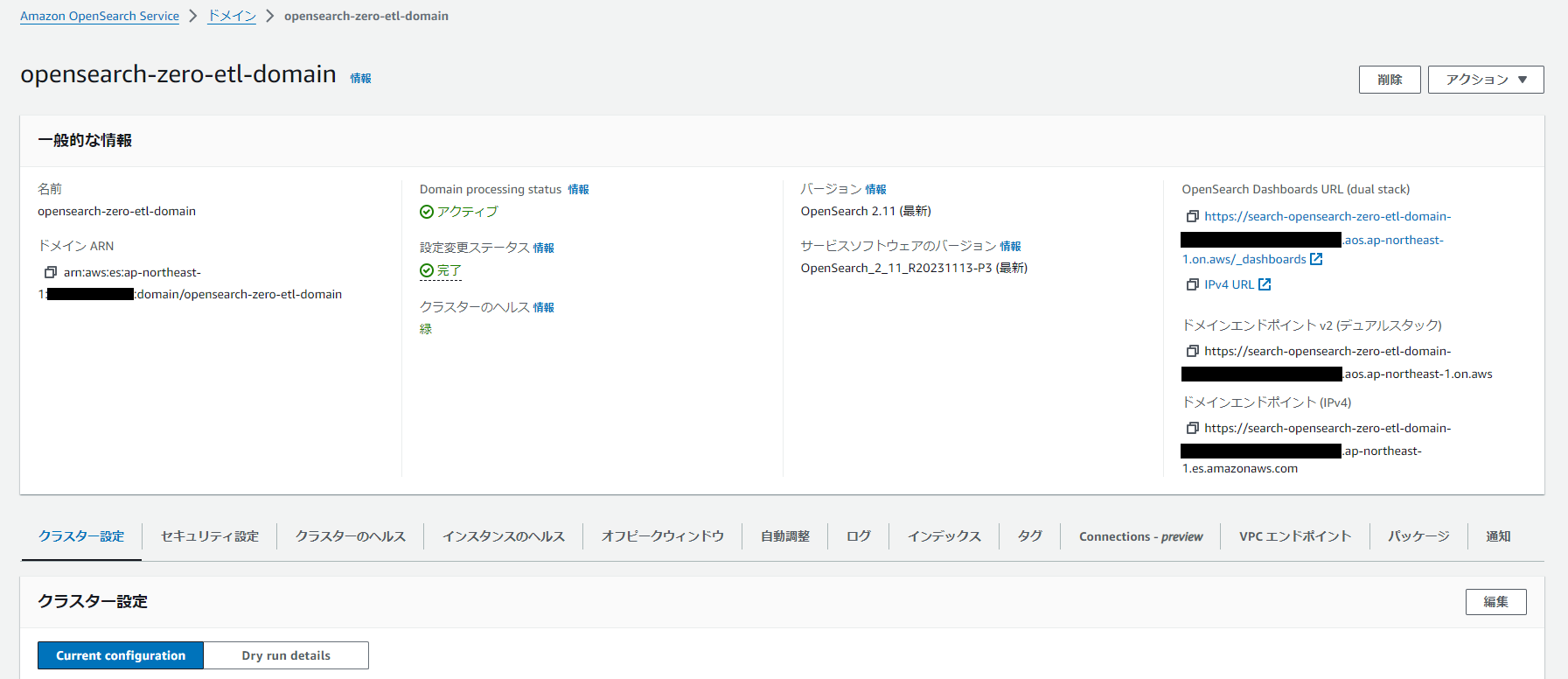
ドメインとそのダッシュボードにそれぞれREST API エンドポイントとなるURLが発行されます。違いは末尾「/_dashboards」だけです。
OpenSearch URL:
https://search-(ドメイン名)-(省略).aos.ap-northeast-1.on.aws
OpenSearch Dashboards URL:
https://search-(ドメイン名)-(省略).aos.ap-northeast-1.on.aws/_dashboards
Dashboards URLを開き、作成したマスターユーザーでログインできます。
動作検証
検証① 従来のデータ取り込み方法
OpenSearchクラスタへデータをロードする方法はいくつかありますが、今回は比較対象としてS3からLambdaを用いたロードを試します。
AWSドキュメントを参考にしています。
1. 事前準備
事前にS3バケットおよび必要なIAMロールを作成します。
Lambdaに必要な権限
- S3 読み取り許可
- OpenSearch Service 書き込み許可
2. デプロイパッケージの作成
以下の手順でデプロイパッケージを作成します。
- ディレクトリを作成する
- ディレクトリ内に.pyファイルを作成しドキュメントにあるコードを貼り付け
- region と host の変数を編集する
- 必要なモジュールをpackage ディレクトリにインストール
- アプリケーションコード一式をパッケージ化する
import boto3
import re
import requests
from requests_aws4auth import AWS4Auth
region = '' # e.g. us-west-1
service = 'es'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token)
host = '' # the OpenSearch Service domain, e.g. https://search-mydomain.us-west-1.es.amazonaws.com
index = 'lambda-s3-index'
datatype = '_doc'
url = host + '/' + index + '/' + datatype
headers = { "Content-Type": "application/json" }
s3 = boto3.client('s3')
# Regular expressions used to parse some simple log lines
ip_pattern = re.compile('(\d+\.\d+\.\d+\.\d+)')
time_pattern = re.compile('\[(\d+\/\w\w\w\/\d\d\d\d:\d\d:\d\d:\d\d\s-\d\d\d\d)\]')
message_pattern = re.compile('\"(.+)\"')
# Lambda execution starts here
def handler(event, context):
for record in event['Records']:
# Get the bucket name and key for the new file
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
# Get, read, and split the file into lines
obj = s3.get_object(Bucket=bucket, Key=key)
body = obj['Body'].read()
lines = body.splitlines()
# Match the regular expressions to each line and index the JSON
for line in lines:
line = line.decode("utf-8")
ip = ip_pattern.search(line).group(1)
timestamp = time_pattern.search(line).group(1)
message = message_pattern.search(line).group(1)
document = { "ip": ip, "timestamp": timestamp, "message": message }
r = requests.post(url, auth=awsauth, json=document, headers=headers)
3. Lambdaを作成する
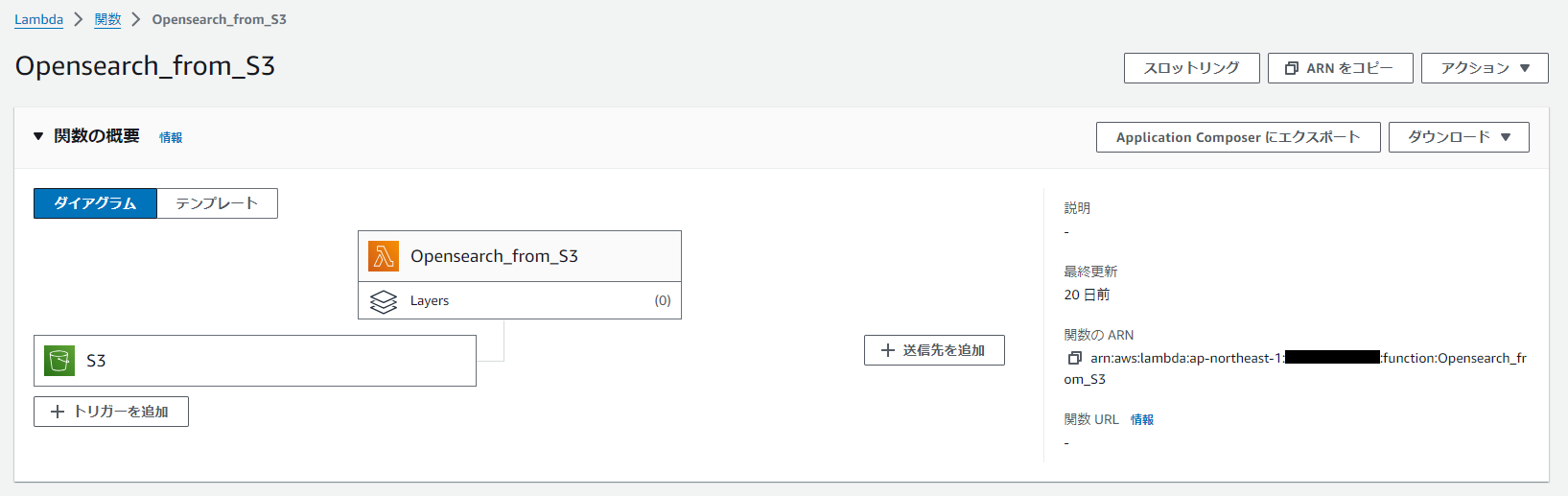
用意したS3バケットとロール、デプロイパッケージを用いてLambda関数を作成します。
今回は「OpenSearch_from_S3」として作成し、S3バケットトリガーを設定しています。
4. テストファイルの用意
以下のjsonファイルを用意しました。
idに加え、author著者とbookTitle著書名をKey・Valueで持たせています。
{
"data": [
{
"id": "book1",
"bookTitle": "Harry Potter",
"author": "JK Rowling"
},
{
"id": "book2",
"bookTitle": "Inferno",
"author": "Dan Brown"
}
]
}
5. OpenSearchでロールの設定
OpenSearch側でロールを設定する必要があります。
- OpenSearchダッシュボードのSecurity->Roles
- Mapped usersにBackend roleとしてLamdaのIAMロールをアタッチする
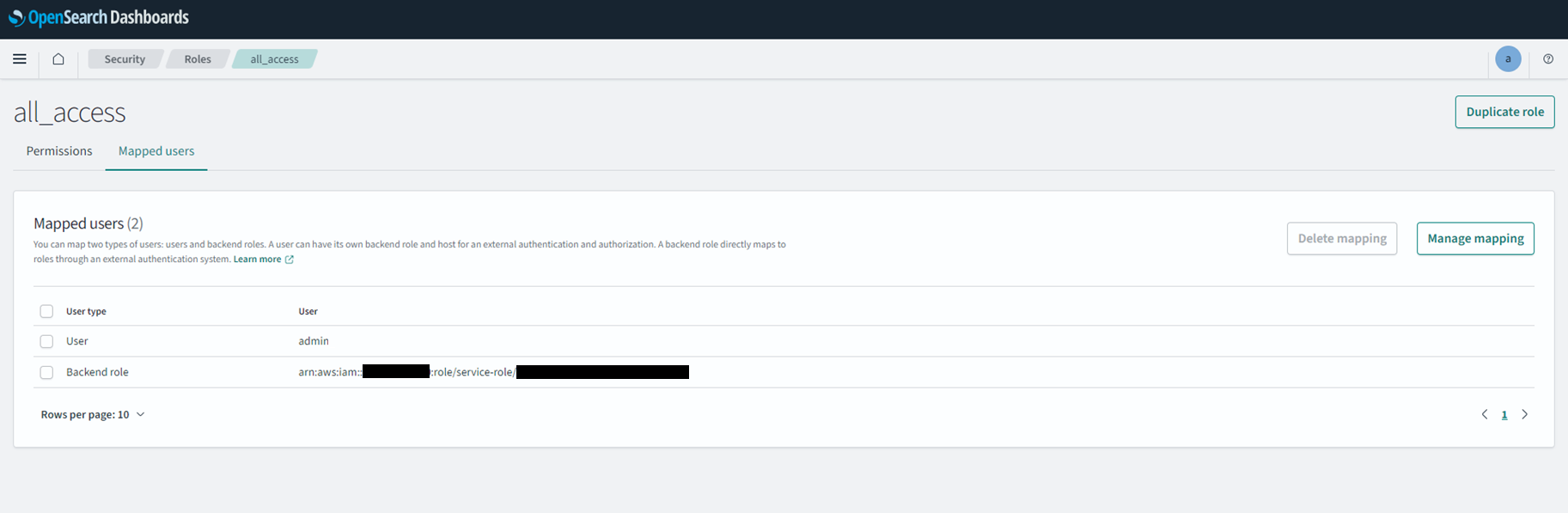
参考
6. OpenSearch側でMappingを設定
Mappingを事前に設定します。(RDBでいうカラム名やデータ型等)
OpenSearchDashboardsタブからDevToolsを選択するとConsoleが開けます。
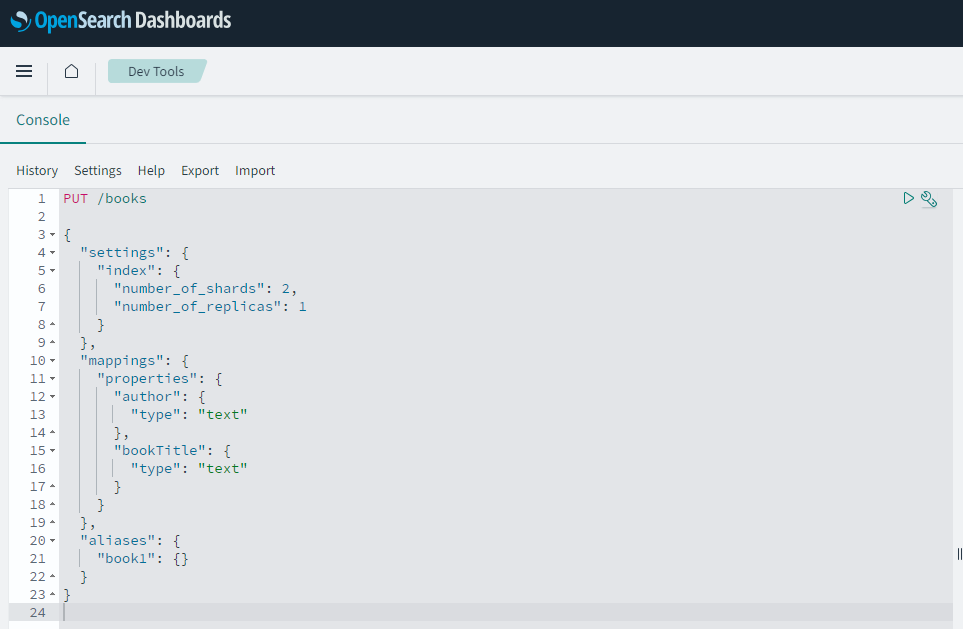
以下PUTしてこれから格納するデータの定義を行います。
author著者とbookTitle著書名をtextとして定義しています。
PUT /books
{
"settings": {
"index": {
"number_of_shards": 2,
"number_of_replicas": 1
}
},
"mappings": {
"properties": {
"author": {
"type": "text"
},
"bookTitle": {
"type": "text"
}
}
},
"aliases": {
"book1": {}
}
}
7. S3にファイルを配置
S3からOpenSearchへデータをロードする準備ができました。
用意したテストファイルをS3に配置するとLambdaが起動してOpenSearchに反映されます。
コンソールでテストファイルの情報が確認できました。
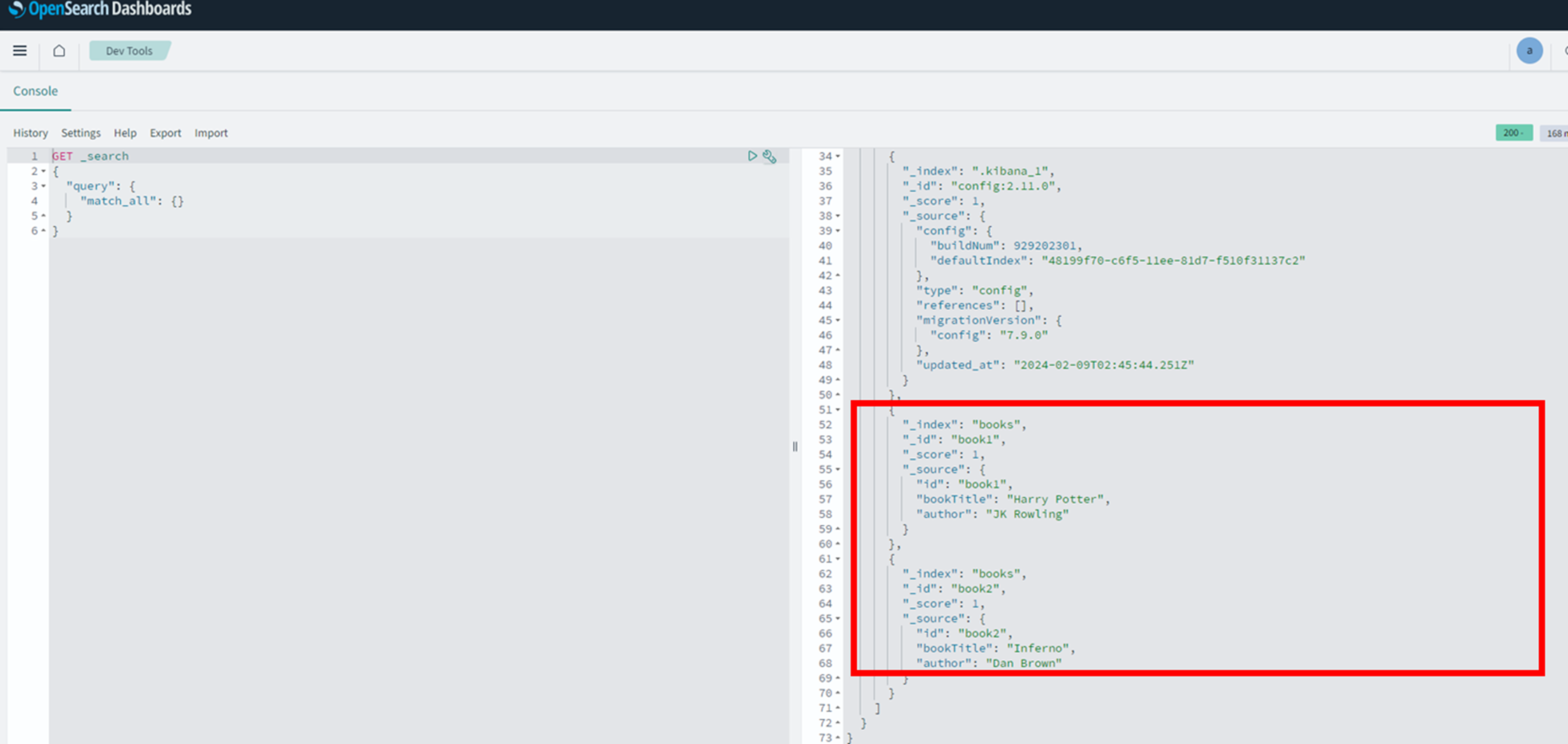
GET _search
{
"query": {
"match_all": {}
}
}
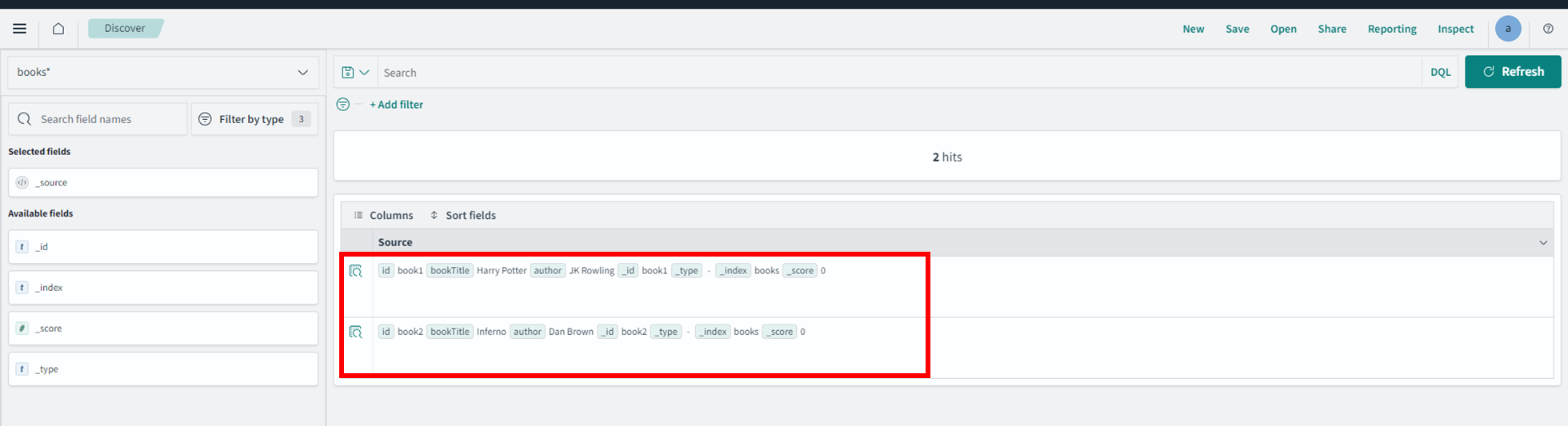
8. OpenSearch Dashboardで確認する
DashboardのDiscoverからもテストファイルの情報が確認できます。
S3にあるファイルに対してOpenSearchへ取り込むには
Lambda関数などで処理を一通り用意してロードする作業が必要となります。
検証② 今回リリースされた方法
今回のプレビューであるダイレクトクエリにより、ロード作業がどのように変わるのか確認します。
AWSドキュメントを参考にしています。
1. テストファイルを用意
S3バケットに以下のcsvファイルを配置します。
ヘッダー(id,bookTitle,author)は除いています。
1,Harry Potter,JK Rowling
2,Inferno,Dan Brown
2. Glueデータカタログを作成
ダイレクトクエリを実行するためS3にあるファイルをテーブルとして扱えるようGlueデータカタログでメタデータを作成します。
- Glueデータベースを作成
- Glueテーブルを作成する
今回作成したデータカタログは以下の通りです。
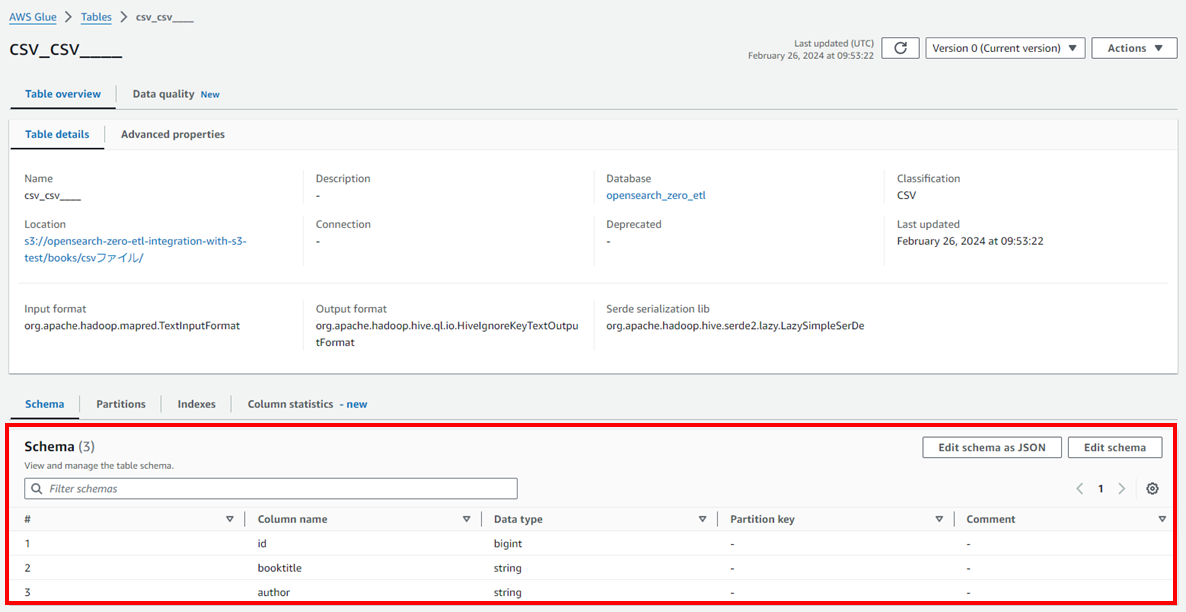
3. データカタログを接続する
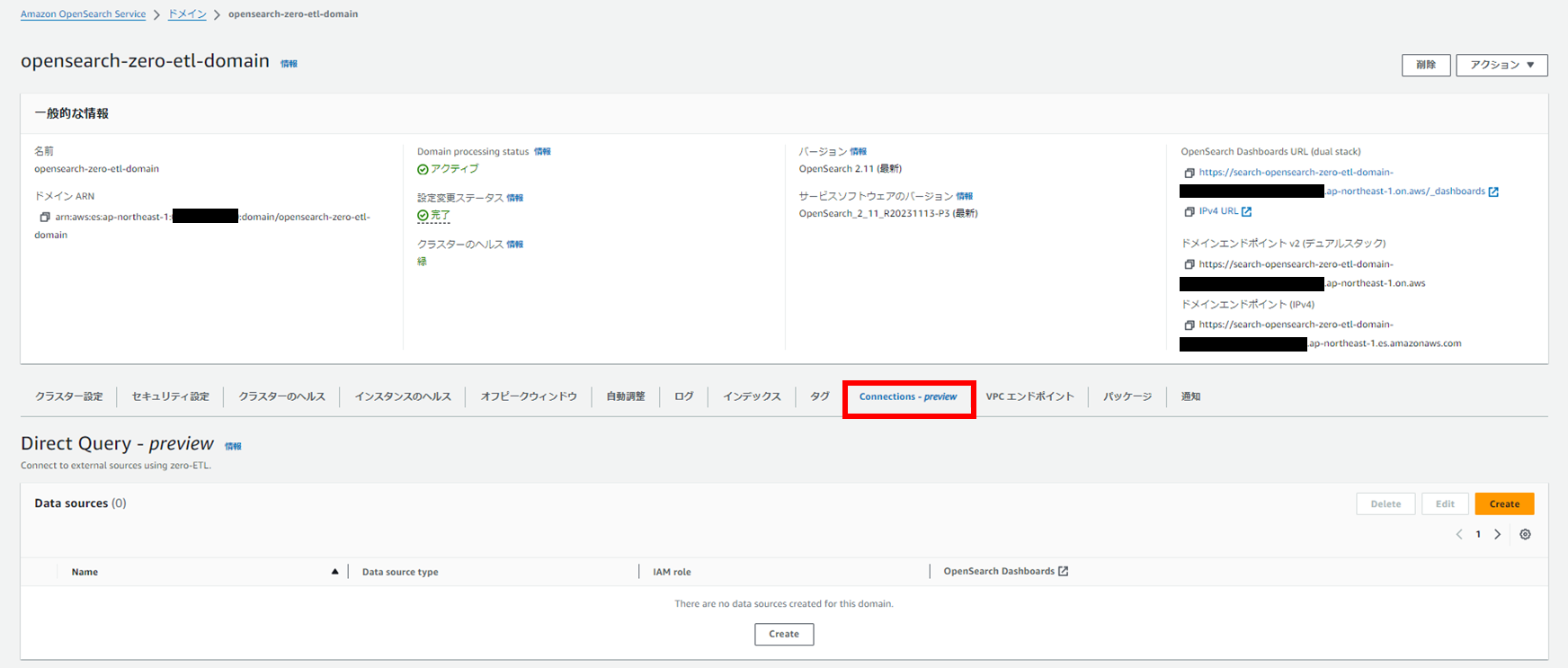
OpenSearchドメインにGlueデータカタログを接続します。
作成したドメインの「Connections - preview」タグから「Create」を選択します。
任意の接続名を入力、IAMロールを選択します。
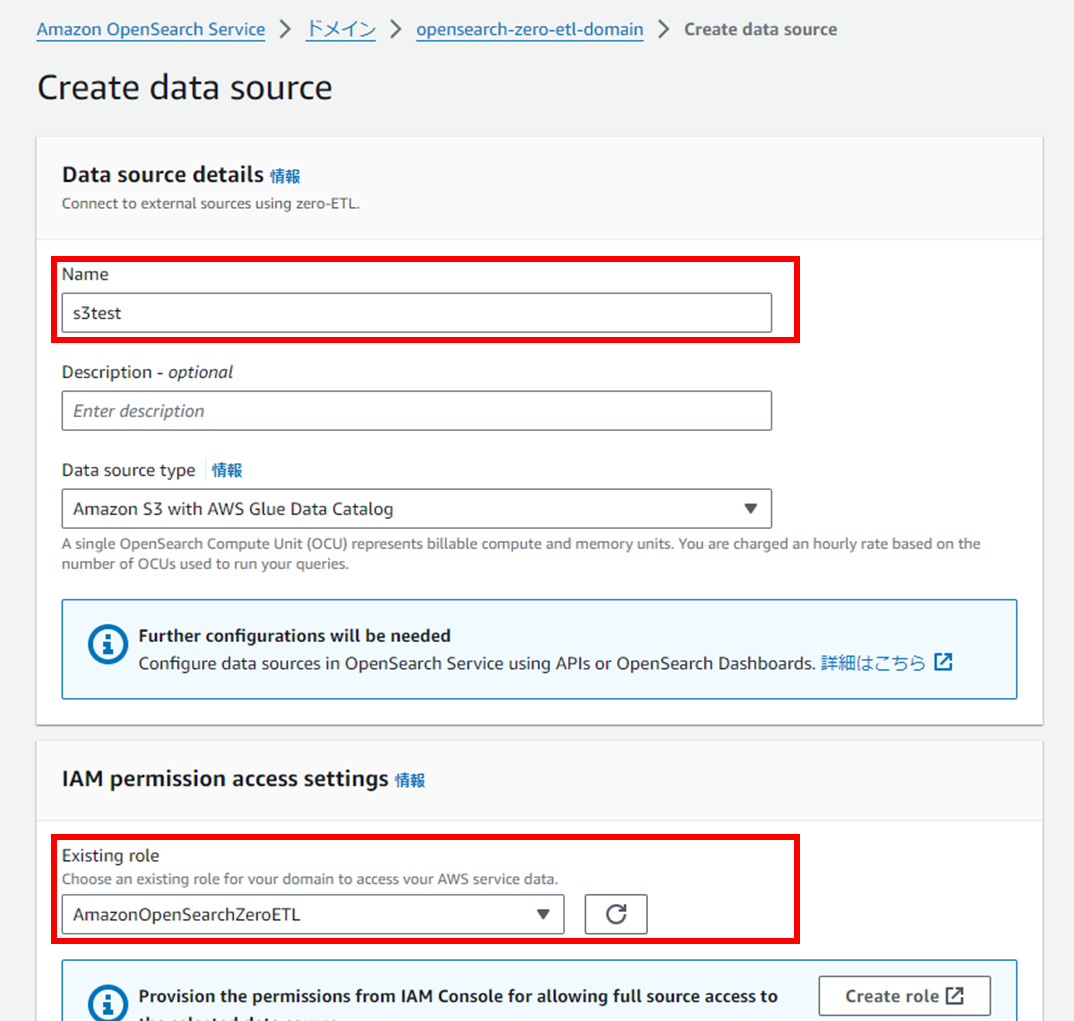
ここでOpenSearchからS3とGlueデータカタログに対するIAMロールが必要となります。
またOpenSearch側でロールのアタッチが必要になります。
必要なアクセス許可
4. ダイレクトクエリを実行する
ダッシュボードを開くとデータソースから接続したGlueデータカタログが選択できるようになります。
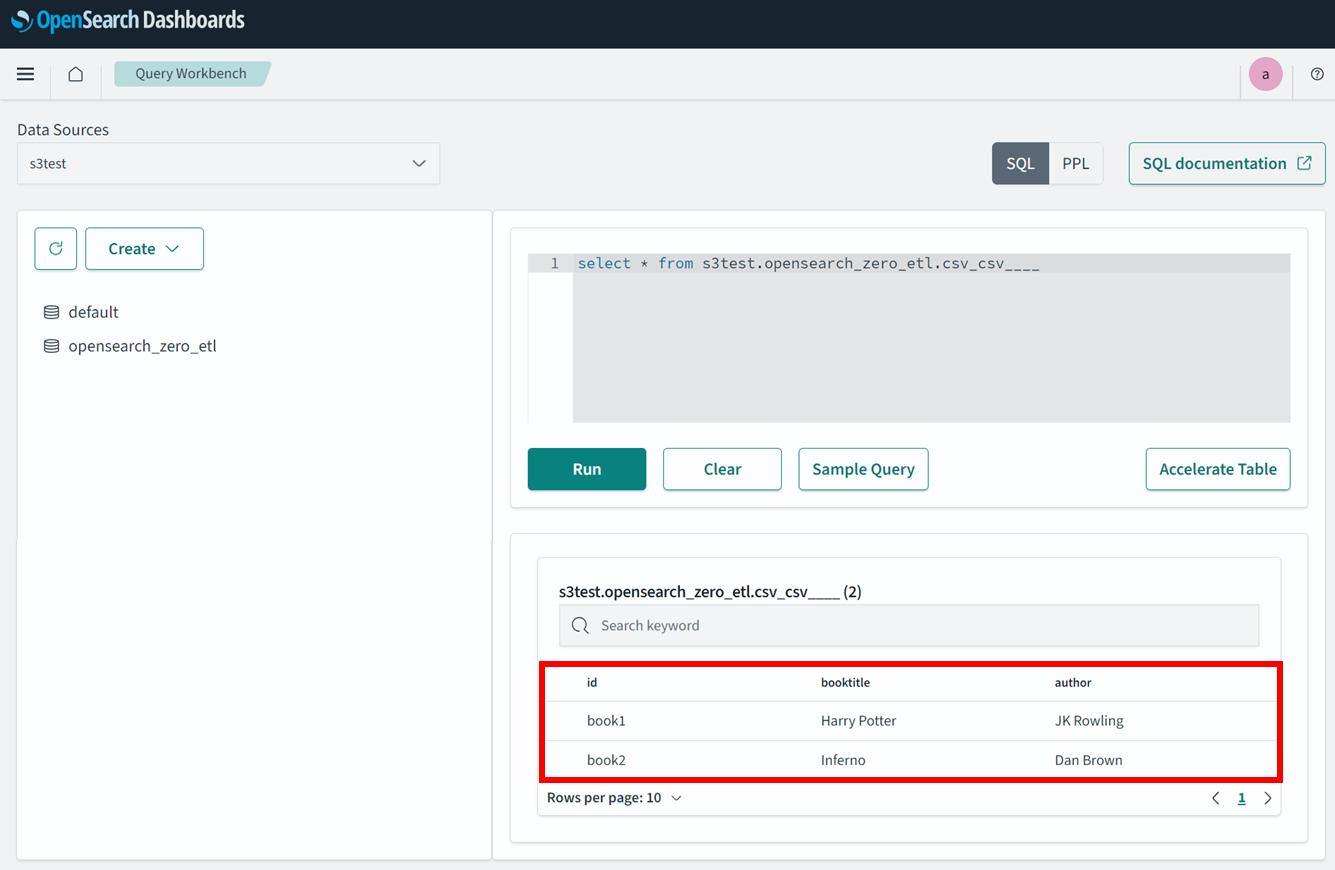
「opensearch_zero_etl」はGlueデータベースで「csc_csv____」はGlueテーブルです
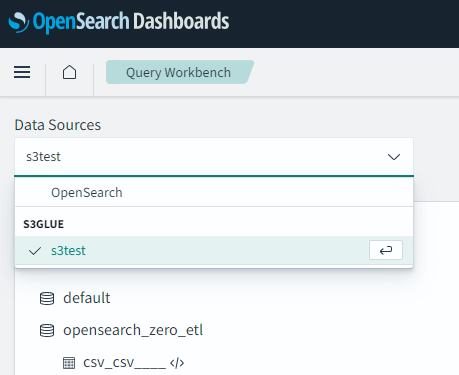
QueryWorkbenchでクエリを発行すると、CSVファイルの中身が確認できました。
必要になるのはGlueデータカタログのみで直接ロードすることができました。
Observabirityでも確認ができます。
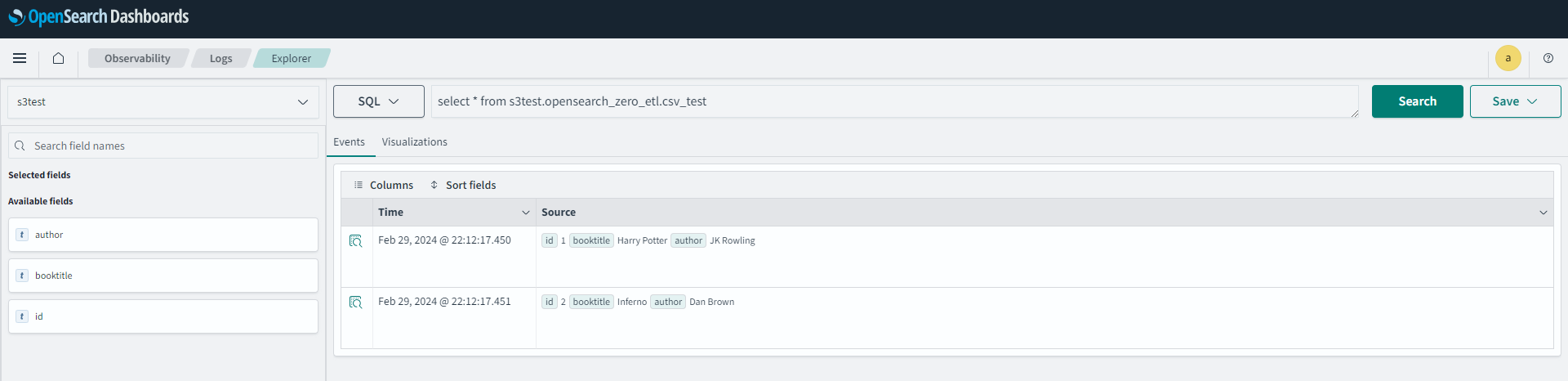
現在SQL をサポートしているのは、Observabirityと Query Workbenchの2つのみです。
https://docs.aws.amazon.com/ja_jp/opensearch-service/latest/developerguide/direct-query-s3-query.html
追加検証1 S3ファイルを変更する
S3ファイルを変更した場合の振る舞いを確認します。
- 上書き:すでにあるファイルの中身を書き換える
- 追加:別のファイルをS3バケットに格納する
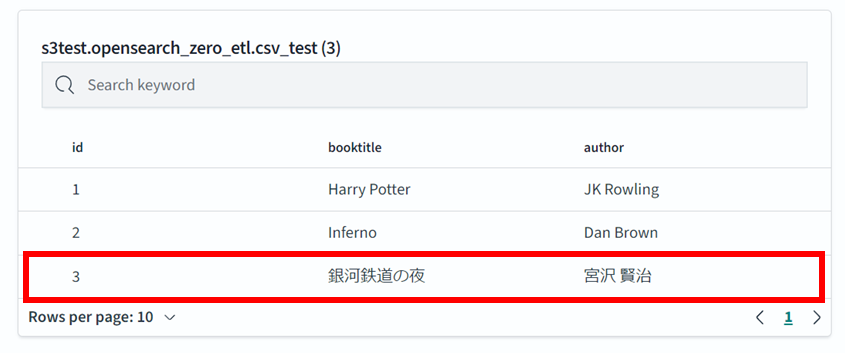
1. ファイルを上書きした場合
先ほどあったファイルを変更し、3行目を追加してみます。
1,Harry Potter,JK Rowling
2,Inferno,Dan Brown
3,銀河鉄道の夜、宮沢 賢治
ダッシュボードでクエリすると即座に確認できました。
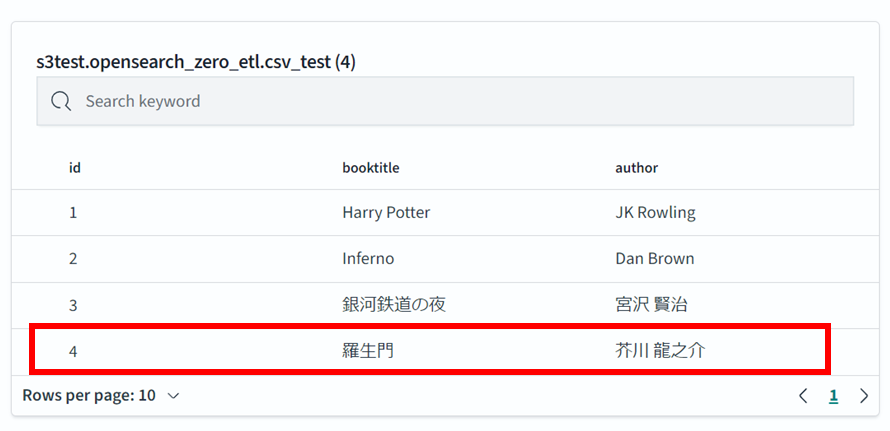
2. ファイルを追加した場合
新しいファイルを追加してみます。
4,羅生門,芥川龍之介
同様に追加したデータを確認できます。
特にリフレッシュ等は必要ありません。
追加検証2 OpenSearchからS3へのデータ操作
クエリによりOpenSearchからS3へデータを操作できるか確認します。
事前にOpenSearchのIAMポリシーでS3へのすべてのアクションを許可しています。("s3:*")
1. INSERT
INSERTしてみます。
insert into s3test.opensearch_zero_etl.csv_test
(id, booktitle, author) VALUES(5, 'こころ', '夏目 漱石');
エラー等はなく実行できます。
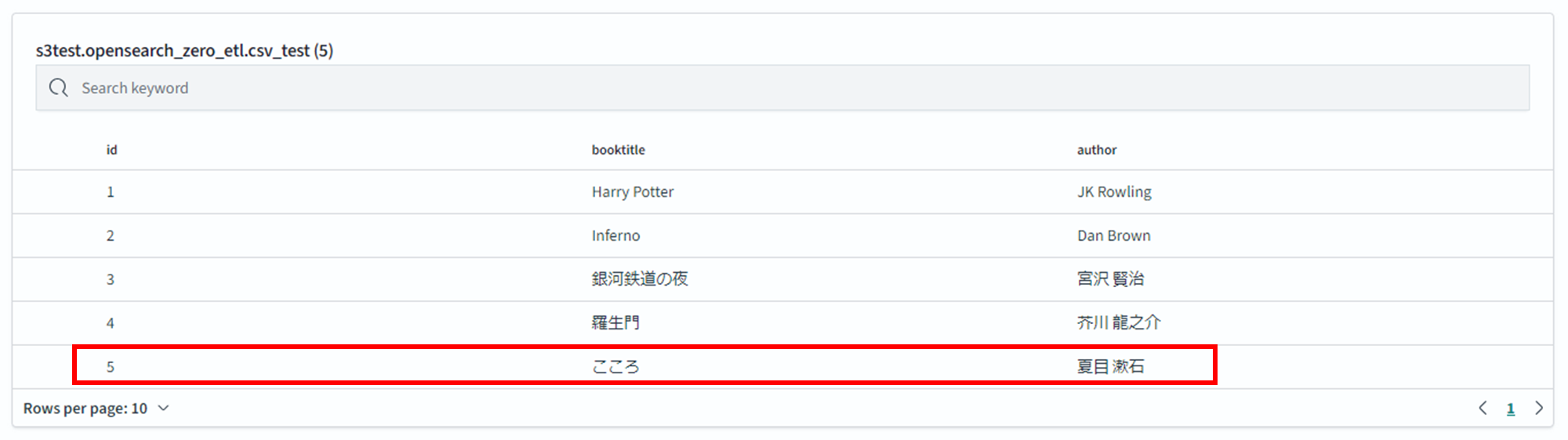
S3バケットを見るとファイルが作成されています。
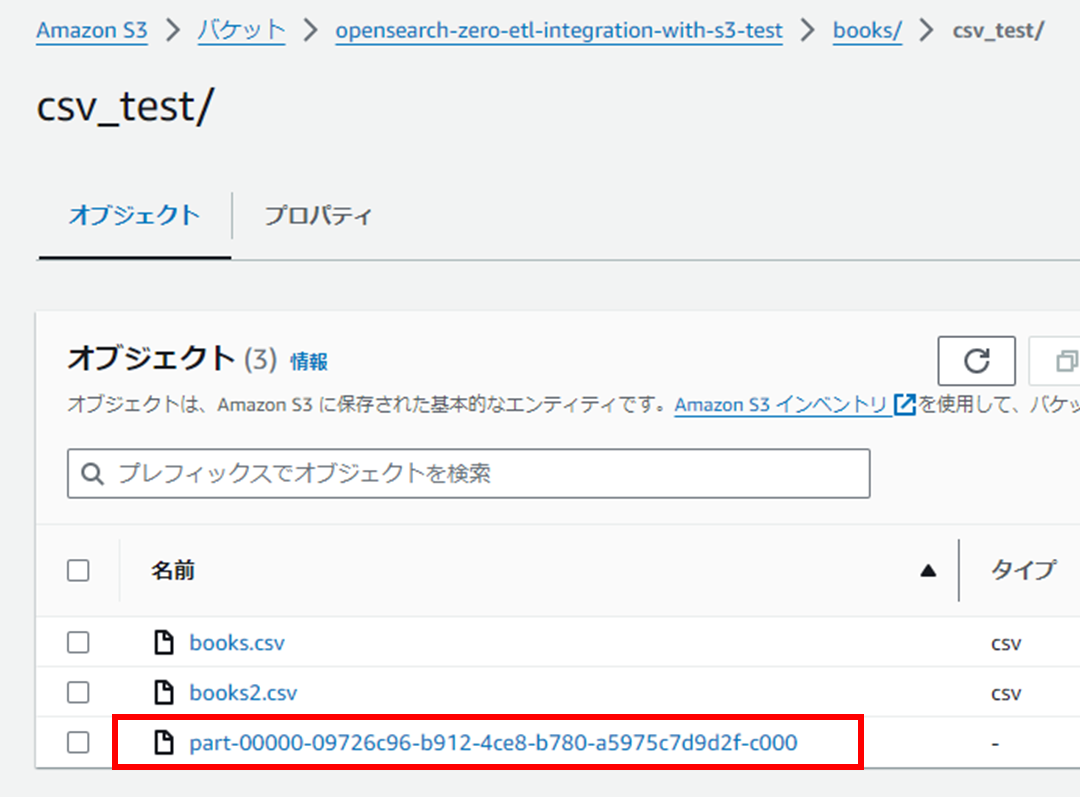
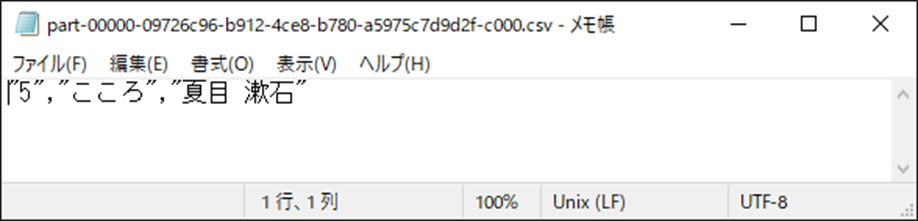
INSERTした内容が反映されています。
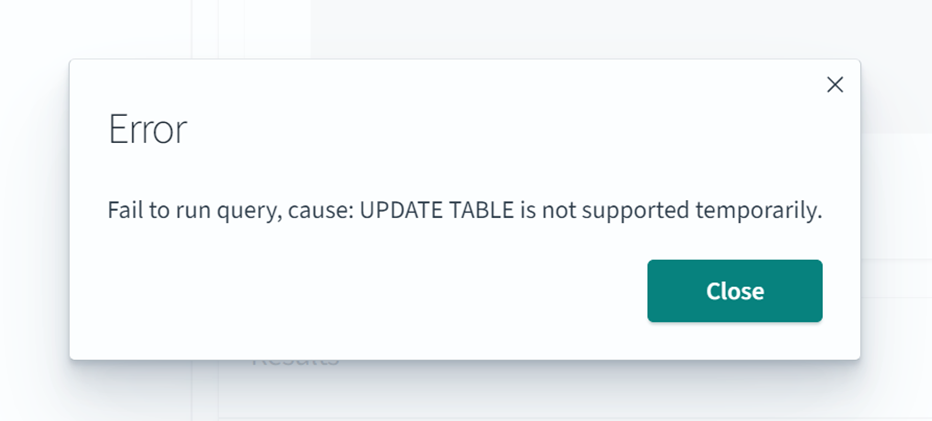
2. UPDATE
UPDATE文を試します。
update s3test.opensearch_zero_etl.csv_test
set booktitle = 'Harry Potter and the Philosopher''s Stone'
where id = 1
エラーで実行できませんでした。
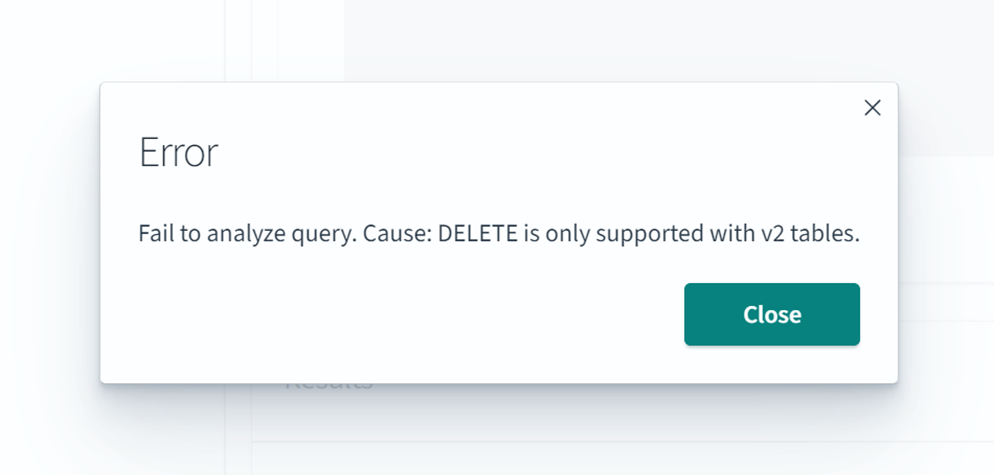
3. DELETE
DELET分を実行してみます。
delete from s3test.opensearch_zero_etl.csv_test where id = 5
こちらもエラーで実行できませんでした。
動作検証のまとめ
- データロード処理を別途用意することなく、OpenSearchから直接S3にデータをクエリ(ダイレクトクエリ)することが可能
- データはOpenSearchでは持たないので、S3ファイルの更新が即座に反映する
- INSERT文が実行可能
最後に
今回の検証ではAmazon OpenSearch Service(OSS)におけるS3とのゼロETL統合(ダイレクトクエリ)についてプレビュー版の機能を取り上げました。
S3に対するデータロードを主とした検証となりましたが、S3 にある膨大なログデータ (VPC Flow ログ、ELB ログなど)に対してインシデントがあった時に OpenSearch 上で分析と可視化が簡単に実施可能になるということです。
ログタイプに合わせて、データアクセラレーションというクエリ実行を高速化する3つのオプションが提供されています。
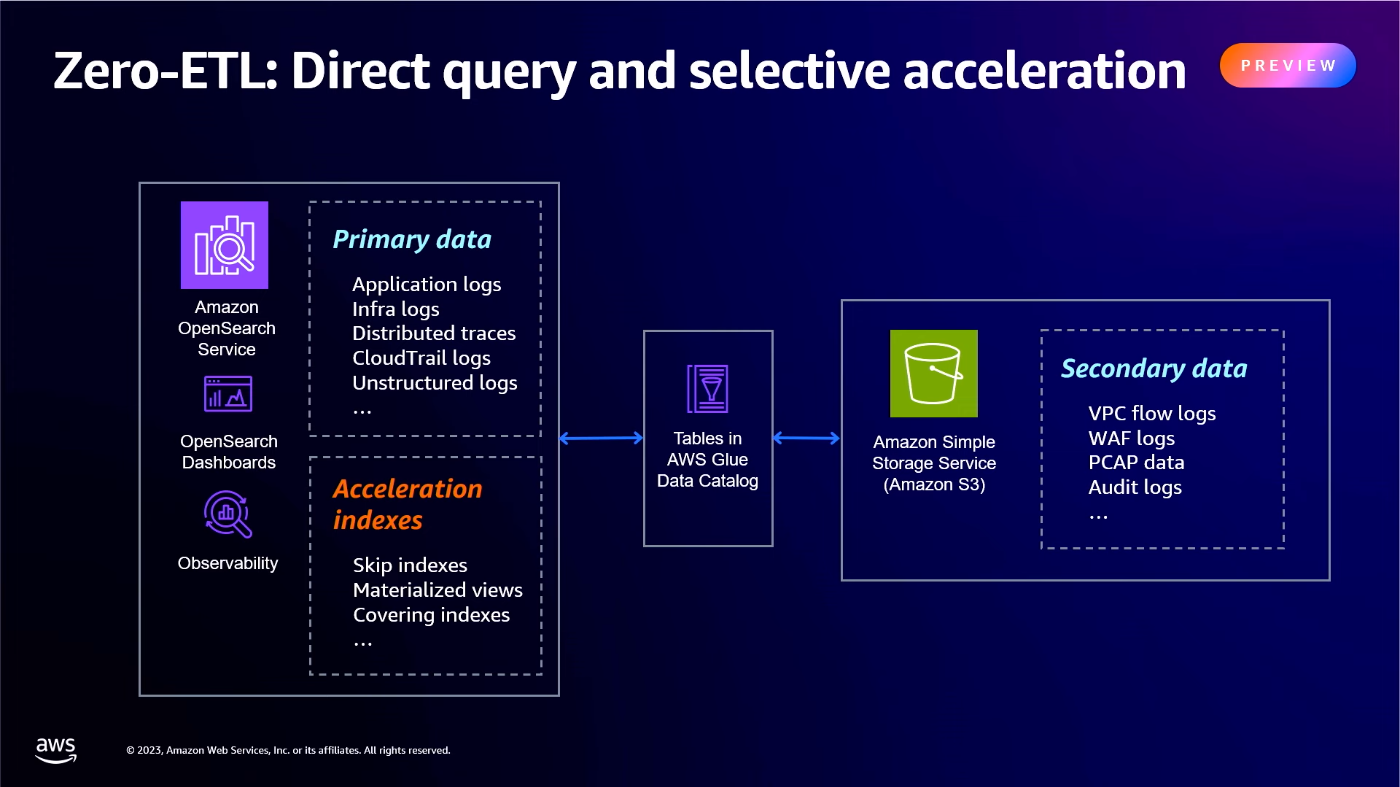
引用2 動画39:15~

引用
引用1:Amazon OpenSearch Service - AWS サービス活用資料集
https://pages.awscloud.com/rs/112-TZM-766/images/AWS-Black-Belt_2023_Amazon-OpenSearch-Service-Basic_0131_v1.pdf
引用2:AWS re:Invent 2023 - What’s new in Amazon OpenSearch Service (ANT301)
https://www.youtube.com/watch?v=CKYCxw0mMiE&t=2527s
引用3:AWS re:Invent Recap - ソリューション編 Search & Streaming Updates
https://pages.awscloud.com/rs/112-TZM-766/images/reInvent2023-recap-ANALYTICS-1-searchstreaming.pdf
株式会社ジールでは、初期費用が不要で運用・保守の手間もかからず、ノーコード・ローコードですぐに手元データを分析可能なオールインワン型データ活用プラットフォーム「ZEUSCloud」を提供しております。
ご興味がある方は是非下記のリンクをご覧ください:
https://www.zdh.co.jp/products-services/cloud-data/zeuscloud/?utm_source=qiita&utm_medium=referral&utm_campaign=qiita_zeuscloud_content-area