はじめに
GKEでContainer-native Load Balancing(NEG)を使用している環境で、ローリングアップデート時に502エラーが発生する問題を調査・解決しました。この記事ではその過程を記録しています。
問題の概要
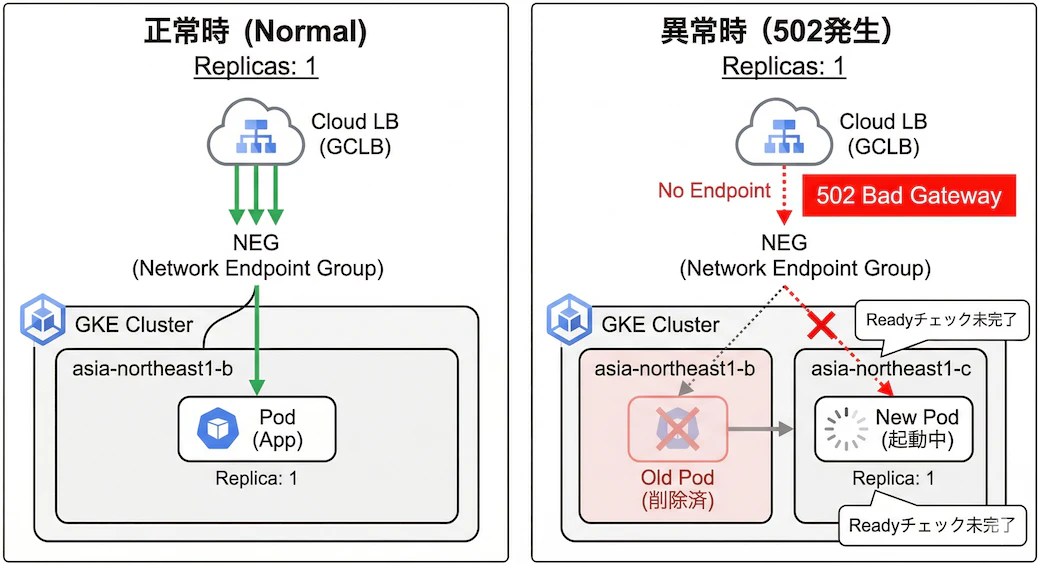
GKE(Container-native Load Balancing / NEG)環境で、 「レプリカ数がゾーン数未満」 の状態でローリングアップデートを行うと、502エラーが発生する場合があります。
TL;DR
原因はingress-gceコントローラの既知のバグ(仕様)(kubernetes/ingress-gce #1718) です。Podが別ゾーンに再配置される際、LBのヘルスチェックが新Podを認識する前に旧Podが削除され、一瞬「正常なバックエンドが0」の状態が発生します。
対策は、以下の2つを組み合わせて「新旧Podの生存期間をオーバーラップ」させることです。
- BackendConfig: checkIntervalSec を短縮し、新PodがHealthyになるまでの時間を早める。
- Deployment: minReadySeconds を設定し、新PodがAvailableと見なされるまでの猶予期間を設ける。
# BackendConfig: ヘルスチェック間隔を短縮
apiVersion: cloud.google.com/v1
kind: BackendConfig
spec:
healthCheck:
checkIntervalSec: 5
timeoutSec: 3
healthyThreshold: 1
unhealthyThreshold: 3
# Deployment: 新PodのAvailable判定を遅延
apiVersion: apps/v1
kind: Deployment
spec:
# minReadySeconds > (checkIntervalSec * healthyThreshold) に設定
minReadySeconds: 15
minReadySeconds > (checkIntervalSec * healthyThreshold)にすることで、LBヘルスチェックが新Podをhealthyと判定する前に旧Podが消えることを防ぎます。
環境
- GKE 1.34.4(Regular channel)
- リージョン: asia-northeast1(3ゾーン: a, b, c)
- Ingress: GCE Class(L7 HTTP Load Balancer)
- Container-native Load Balancing(NEG)有効
- レプリカ数: 1
根本原因
メカニズム
- ローリングアップデートで新Podが別ゾーンにスケジュールされます
- NEGコントローラが新ゾーンにNEGエンドポイントを作成します
- NEGコントローラ内部のキャッシュが未同期のため、BackendServiceとの紐付けを認識できません
- Readiness Gateの条件
cloud.google.com/load-balancer-neg-readyがLBヘルスチェック通過を待たずに即座にTrueになります(LoadBalancerNegWithoutHealthCheck) - Kubernetesは新PodがReadyと判断し、旧Podの削除を開始します
- 旧PodがService Endpointsから除去され、NEGからDetachされます
- 新PodはNEGにAttach済みですが、LBのヘルスチェックがまだ通過していません
- LBから見てhealthyなバックエンドが0個 →
failed_to_pick_backend→ 502
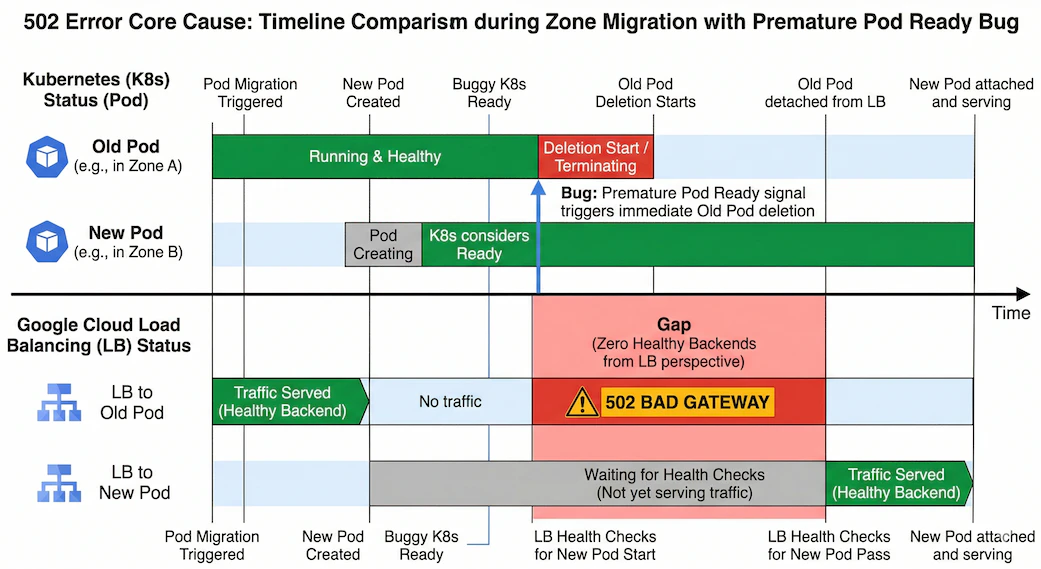
同一ゾーン内で発生しない理由
同一ゾーン内のPod入れ替えでは、LBが既にそのゾーンのNEGをhealthyと認識しているキャッシュが残っているため、新Podが素早くhealthy判定されます。
Googleの対応:事実上の「仕様」
Google Issue Trackerでは、この挙動はWONTFIX(修正予定なし) とされています。これは単なる放置ではなく、GKE Ingress(L7 LB)のアーキテクチャ設計に起因する制限です。
設計上の理由: ingress-gceコントローラは、パフォーマンスとスケーラビリティの観点から、すべての BackendServiceの紐付けをリアルタイムかつ完全に同期することが困難です。
「楽観的Ready」の採用: バックエンドとの紐付けが確認できない場合、コントローラは通信を遮断するリスクを避けるため、「安全側に倒して拒否」するのではなく**「楽観的にReady(True)にする」**動作がハードコードされています。
結論: GKEの標準動作として「Readiness Gateはゾーンを跨ぐ際のLBヘルスチェックまでは保証しない」という仕様として扱う必要があります。
対策の詳細
1. BackendConfig: checkIntervalSecの短縮(30秒→5秒)
新PodがNEGにAttachされてからLBがhealthyと判定するまでの時間を短縮します。
apiVersion: cloud.google.com/v1
kind: BackendConfig
spec:
healthCheck:
checkIntervalSec: 5 # デフォルト30秒から短縮
timeoutSec: 3
healthyThreshold: 1
unhealthyThreshold: 3
これだけでは不十分です。502の持続時間が約35秒→約12秒に短縮されましたが、完全には消えませんでした。
2. Deployment: minReadySecondsの追加
新PodがReadyになってからAvailableと見なされるまでの猶予期間を設けます。Deployment controllerは新PodがAvailableになるまでrolling updateの次のステップ(旧Podの削除)に進まないため、この待機時間中にLBヘルスチェックが新Podをhealthy判定します。
apiVersion: apps/v1
kind: Deployment
spec:
minReadySeconds: 15
検証結果
| checkIntervalSec | minReadySeconds | 502 |
|---|---|---|
| 30秒 | なし | 約35秒間発生 |
| 5秒 | なし | 約12秒間発生 |
| 5秒 | 15秒 | 発生なし |
minReadySecondsの値の決め方
minReadySecondsは 「Readiness Probe通過後」 にカウントが開始される待機時間であり、アプリ自体の起動時間には依存しません。この値は、LBが新PodをHealthyと認識し、トラフィックを完全に切り替えるまでの時間を稼ぐために設定します。目安として、以下の計算式を満たすように設定するのが安全です。
$$minReadySeconds > (checkIntervalSec \times healthyThreshold) + \text{Margin}$$
- checkIntervalSec: LBのヘルスチェック間隔
- healthyThreshold: 正常判定に必要な連続成功回数(BackendConfigで指定)
- Margin: ネットワーク遅延やNEG反映のラグを考慮したバッファ(5〜10秒程度)
今回の検証(checkIntervalSec: 5, healthyThreshold: 1)では、$(5 \times 1) + 10 = 15$秒 としています。
| checkIntervalSec | healthyThreshold | 推奨minReadySeconds | デプロイ時間への影響 |
|---|---|---|---|
| 5秒 | 1回 | 15秒 | +15秒 / Pod |
| 5秒 | 3回 | 25秒 | +25秒 / Pod |
| 10秒 | 3回 | 40秒 | +40秒 / Pod |
効果がなかった対策
preStop hook
lifecycle:
preStop:
exec:
command: ["sleep", "30"]
Podのプロセスは延命されますが、Service Endpointsからの除去とNEG Detachは防げません。LBから見ると旧Podは既にルーティング対象外となるため、502の解消には寄与しませんでした。
レプリカ数による根本回避
レプリカ数がゾーン数以上(3ゾーンなら3レプリカ)の場合、topologySpreadConstraintsで全ゾーンにPodを分散配置すれば、ローリングアップデートでゾーン変更が発生しません。この場合、上記の対策は不要です。
spec:
replicas: 3
template:
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: my-app
matchLabelKeys:
- pod-template-hash
調査の経緯
以下は原因特定に至った調査プロセスの記録です↓↓
再現テスト
継続的にHTTPリクエストを送信しながらkubectl rollout restartを実行し、502の発生を監視しました。
while true; do
code=$(curl -s -o /dev/null -w '%{http_code}' -m 5 "$URL")
if [ "$code" != "200" ]; then
echo "$(date '+%H:%M:%S') HTTP $code"
fi
sleep 0.5
done
結果、同一条件のrollout restartでも502が出る場合と出ない場合がありました。
LBログによる原因特定
Cloud Loggingで502発生時のLBログを確認しました。
resource.type="http_load_balancer"
resource.labels.url_map_name:"<your-url-map>"
timestamp>="2026-03-25T00:56:00Z"
timestamp<="2026-03-25T00:58:00Z"
全ての502でstatusDetailsが**failed_to_pick_backend**でした。これはLBがhealthyなバックエンドを1つも見つけられなかったことを意味します。
NEGのAttach/Detachイベントとの照合
LBログと同じ時間帯のNEGイベントを確認しました。
resource.type="k8s_cluster"
(jsonPayload.message:"Attach" OR jsonPayload.message:"Detach")
jsonPayload.message:"<service-name>"
502が発生した場合(Podが別ゾーンに配置):
| 時刻 | イベント | ゾーン |
|---|---|---|
| 00:57:13 | Attach(新Pod) | zone-c |
| 00:57:26 | 最後の200 | |
| 00:57:27 | 502開始 | |
| 00:57:39 | Detach(旧Pod) | zone-b |
502が発生しなかった場合(同一ゾーン内):
| 時刻 | イベント | ゾーン |
|---|---|---|
| Attach(新Pod) | zone-c | |
| Detach(旧Pod) | zone-c | |
| 502なし |
ゾーンをまたぐPod移動時にのみ502が発生していました。
ゾーン変更の強制再現
nodeSelectorで特定ゾーンへの配置を強制し、ゾーン変更を確実に発生させることで502を安定的に再現できました。
kubectl patch deployment <name> -n <ns> --type='json' \
-p='[{"op":"add","path":"/spec/template/spec/nodeSelector","value":{"topology.kubernetes.io/zone":"asia-northeast1-b"}}]'
Readiness Gateの確認
NEGのReadiness Gate条件を確認したところ、根本原因が判明しました。
kubectl get pod <pod> -o jsonpath='{.items[0].status.conditions}' | python3 -m json.tool
{
"reason": "LoadBalancerNegWithoutHealthCheck",
"message": "NEG is not attached to any BackendService with health checking. Marking condition to True.",
"status": "True",
"type": "cloud.google.com/load-balancer-neg-ready"
}
まとめ
- GKE NEGのReadiness Gateには既知の仕様があり、ゾーンをまたぐPod移動時に502が発生します
-
checkIntervalSec短縮 +minReadySecondsの組み合わせで防止できます -
preStophookはこの問題には効果がありません - レプリカ数 >= ゾーン数 にできる場合は
topologySpreadConstraintsで根本回避が可能です
参考
- kubernetes/ingress-gce #1718 - NEG readiness gate is set to true without health check — 本記事の根本原因となるissue
- Container-native load balancing through standalone zonal NEGs — GKE NEGの公式ドキュメント
- Ingress for external Application Load Balancers — GKE Ingressの概要
- BackendConfig custom resource — BackendConfigによるヘルスチェック設定
- Container-native load balancingの概要 - Podの準備状況 — 公式ドキュメント上はReadiness Gateにより安全なrolling updateが保証されるとあるが、ゾーン変更時には機能しない
- Deployments - minReadySeconds — Kubernetes公式のminReadySecondsリファレンス
- Topology Spread Constraints — topologySpreadConstraintsの公式ドキュメント