ワンライナーで作るウソ発見器
最初、pythonで書きはじめたら、自宅のpython環境が壊れていて実行できなかったので、Excelでやり直しました。これはこれで、追試したり、応用したりする人の層が広がりそうなので、結果オーライかな、と思います。でも、ワンライナーじゃなくなっちゃうね。
アニメDVDの売上とか、誰かが自慢しているアクセス数推移とか、新規陽性者数とか、そういう数字って、自分の側からは統計の裏側を見通すことなんてできないですよね。でも、「ウソ発見器」があれば大丈夫。たちどころにウソが暴けるのです、というのはもちろん誇大広告極まりないのですが、でもまあ、やりたいことはそういうことです。この手法は、企業の不正会計を探すためのスクリーニングにも応用する研究があるくらいで、ぶっちゃけバカみたいに見えるのですが、案外パワフルなのです。
さて、上記は大きく出すぎましたが、何のことはない、「ベンフォードの法則」です。桁をまたがって散らばっている数値の一番上の桁の数字が、自然なデータでは一定の割合になる、という面白い法則です。
「数値の一番上の数字」というのは、値が5000兆だったら5、値が3257だったら3、値が0.015なら1です。値が0の時は考えず、除外して集計します。川の長さ、石の重さ、企業の売上高など、何かしら単位を揃えてデータを集めると、多くの場合、上の桁が一定の割合になるのです。ただ、上限があるような数字、例えばcmで表した身長なんかは、ほぼ1ばっかりになりますし、人為的に桁を意識した数字、例えば商品の単価なんかは、逆に9が異常に多くなることになります。特価98円、とかそういうやつですね。しかし、そういう本質的に偏っている場合以外は、概ね一定の割合になってしまうのです。
では、この「一定の割合」とはどんな風になるのでしょうか。
| 最上位桁の数字 | 自然な率 |
|---|---|
| 1 | 30.10% |
| 2 | 17.61% |
| 3 | 12.49% |
| 4 | 9.69% |
| 5 | 7.92% |
| 6 | 6.69% |
| 7 | 5.80% |
| 8 | 5.12% |
| 9 | 4.58% |
特徴としてはなにより、1が一番上の位に来るのが30%もある分布が自然である、という点です。均等だったら11%ですから、かなり盛り盛りです。でも、0.3010と来たら、ぴちぴちの高校生の人たちは、ピンと来るんじゃないでしょうか? そう、対数と関係がありそうですね。細かい話は、追記するかもしれないけど、今は結論を急ぎましょう。
このベンフォードの法則は、下記のような応用の仕方もできます。
- 人為的にでたらめに作った数字は、上記とかけ離れたでたらめな分布になる
- 人為的に調整した数字は、上記と微妙に逸れた分布になる
という結果になります。このベンフォードの法則だけで何かの結論を出すことはできませんが、疑惑を定量的に示すことができるのです。上記の率に対して、集計対象から得られた率を比較して、「最上位桁1の率」から「最上位桁9の率」まで、それぞれの差の絶対値を求めると、簡便な評価関数になります。不正会計のスクリーニングでは、0.6ポイントの乖離でちょっと変、1.5ポイントの乖離で結構変、という目安が提唱されているようです。
詳しい人は、ここまでの説明で言いたいことが色々出てくると思いますが、しずまりたまえ。
では、データを処理しよう
厚生労働省のオープンデータから、「新規陽性者数の推移(日別)」を持ってきました。前処理として、値が0の行を母集団から削除します。ここはExcelワークで。
数値だけをA列に並べ、B列に =INT(LEFT(TRIM(A参照行),1)) という感じの数式を入れます。コピペドン。Ctrl+Shift+@ で数式表示をすると、下記のような画面になります。同じキーで元に戻ります。
もう簡単ですね。自動選択範囲からピボットテーブルを新規作成します。
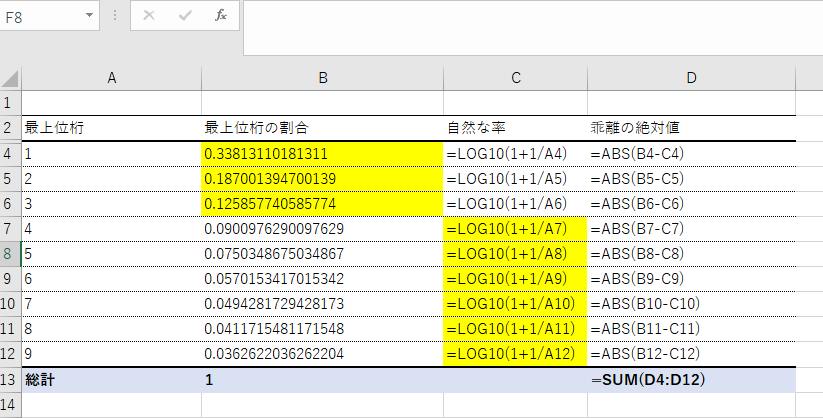
行に「最上位桁」、値に「人数」を入れますが、「人数」については設定が必要です。「値フィールドの設定」から、「集計方法」タブで「個数」を選択、「計算の種類」タブで「総計に対する比率」を選択します。これで、欲しかった最上位桁の数字のシェアが分かります。せっかくなので、その集計値の隣に、 =LOG10(1+1/A参照行) という上に挙げた「望ましい分布」の率を入力しましょう。
そしてその隣には評価関数です。 =ABS(B4-C4) 簡単ですね。これを入れて、また Ctrl+Shift+@ で数式表示にすると、こんな画面になります。
同じ操作で元に戻します。
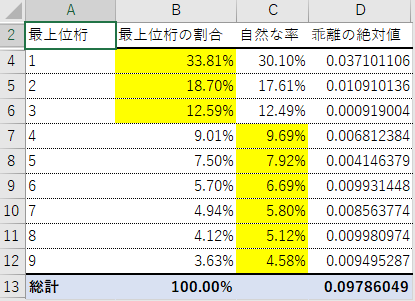
暫定的な結論
さて、もう色を付けてしまいましたが、ちゃんと分析できた感じの結果になったと思います。
でたらめではない
理屈上対数的な分布が想定されるデータ群に対して、全体的に概ね対数的な分布をしており、でたらめではなさそうです。でたらめに作ったら、なかなかこうはなりません。
でも無視できないズレがある
1と2は明らかに多く、4~9は小さめです。とくに、6~9が一律0.9ポイント前後の乖離を見せているのが気になります。これが何を意味するのかは、もうちょっと色んな切り口で(例えば上2桁で分析するとか、期間ごとのサブセットで分析するとか、直値のヒストグラムを取るとか、そういう)追加の分析が必要です。
1が多いというのは、水増しの傾向があるときによく見られるのですが、この場合、過小報告をするインセンティブならば働く可能性もありますが、水増しをしたい人は考えづらいので、ちょっと謎です。もしかしたら、切り上げで丸めて報告した数字が混じっているとか、そういう何かがあるのかも知れません。
いずれにせよ、このゆがみの正体は、あなたの追試にかかっています。なんてね。面白いでしょ? というわけで、久々にAWS資格の話のアクセスが集まっているので、ついでにちょっと面白げな話を書いてみました。セルフ小判鮫上等です。
ベンフォードの法則×コロナ統計というネタが既出だったらごめんなさい。なお、今期はAWS三昧で初動乗り遅れまして、アニメはメイドラゴンSと転スラ2期だけしか観ていません。おすすめがあれば教えて欲しいと思います。