- 【今回】ポケモン×データサイエンス(1) - ポケモン剣盾のランクバトルデータを解析してTableau上で可視化してみた
- ポケモン×データサイエンス(2) - ポケモン剣盾のパーティ構築をネットワーク分析から考える 試行編
- ポケモン×データサイエンス(3) - ポケモン剣盾のパーティ構築をネットワーク分析から考える ネットワークの中心はどこ編
Too Long, Didn’t Read
こんにちは、この記事を呼んでいる諸兄はポケットモンスター、縮めてポケモン(ポケットモンスター・Pokémonは任天堂・クリーチャーズ・ゲームフリークの登録商標です。)を遊んだことはあるだろうか。
最新作のポケットモンスター ソード・シールド(通称 剣盾)の拡張パッチ第二弾である冠の雪原が先週の10月23日に配信開始となり、これを期に再びガラル地方に舞い戻ったポケモントレーナーも多いのではないだろうか。
例にもれず私もその一人であり、私の最愛のポケモンであるエレキブル(黒と黄色の滅茶苦茶カッコいいやつ)が使えるようになると聞き、逆立ちしながらゲームを開始したのがつい先ほどのことのように感じられる。
余談はさておき、本作剣盾にはランクマッチというオンライン対人戦ができる機能(ランクというだけあって戦績によって順位が決まる)が存在しており、本作のやりこみ要素もといエンドコンテンツとなっている。1か月を1シーズンとして、シーズンの変わり目にランクのリセット・使用できるポケモンの変更などが行われ、シーズン毎に環境が大きく変わっていくことが過去作のレーティングマッチとの大きな違いである。
先に述べた通り、私は鎧の孤島(拡張パッチ第一弾)でひと段落してから久しくポケモンに触れていなかったため、環境が目まぐるしく変化するポケモン剣盾のランクマッチにおける流行や所謂「メタ」が何なのか把握できていないため、戦略を練りづらい現状がある。
勿論、ご存知の通り今年2月のポケモンHOME配信以降、スマホ版アプリ上にてバトル関連のデータが開示されるようになり、採用率トップ10やどのような技を覚えているのか等の情報を集められるようになっている。
ただ、それだけじゃあ物足りないと感じたのだ。
もっと一覧性が高く、もっと”Tier”を反映したものは作れないか?
そのような問題意識が今回の記事を書き始めるに至った主たる動機である。
Goal
出来上がったもの(ネタバレ)

ゴールの設定
今回の出発地点は、
- ポケモンHOME上のバトルデータから得られる情報が少ない、もっと欲しい
- データが見づらい、欲しいデータにたどり着くまでに時間が掛かる
でした。
なので着地地点は、
- ポケモンHOME上だけでは得られないデータを集める
- データを見やすく可視化する
になりそう。
課題解決策
しかし今回の大本のゴールである”シーズン毎の流行・メタを捉える”ためにはポケモンHOMEのデータに頼らざるを得なさそうです、ポケモンが外部に公表しているバトル関連のデータは自分の知る限りこれだけなので。
ランクマッチのバトルデータをAPIから取得している先駆者の方を参考にすれば、ポケモンHOME+αのデータは得られそう。
今回はここから得られたデータに加工を加えてなんとなく”Tier”っぽいものが分かるような可視化をすることにする(雑)。
可視化手法はいくつかあると思いますが、インタラクティブな操作の簡便さとビジュアルの良さ、機能の豊富さなどを総合的に評価して(というかガッツリ好みを反映して)Tableau Desktopを使うことにした。
改めて今回のゴールを提示する。
- APIから得られたデータに加工を加えて、公式が出している以上の示唆を得る
- Tableauにより可視化し、データを見やすくする
Let's Try it
2020/11/03 Githubにて全コードを公開しました。
1. APIについて
以下のデータダウンロードについては@retrorocket さん (2020年06月07日)の記事を参考にしています。詳細はこちらをお読みください。
curl 'https://api.battle.pokemon-home.com/cbd/competition/rankmatch/list' \
-H 'accept: application/json, text/javascript, */*; q=0.01' \
-H 'countrycode: 304' \
-H 'authorization: Bearer' \
-H 'langcode: 1' \
-H 'user-agent: Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Mobile Safari/537.36' \
-H 'content-type: application/json' \
-d '{"soft":"Sw"}'
上記のAPIリクエストで得られたレスポンスにランクマッチのシーズン情報が入っている。
{
"code": 200,
"detail": 0,
"list": {
"7": {
"10072": {
"name": "シーズン7",
"start": "2020/06/01 13:00",
"end": "2020/07/01 08:59",
"cnt": 147244,
"rule": 1,
"season": 7,
"rst": 0,
"ts1": 1591187503,
"ts2": 1591187515,
"reg": "000000248"
},
"10071": { // シングルバトルのID
"name": "シーズン7",
"start": "2020/06/01 13:00",
"end": "2020/07/01 08:59",
"cnt": 147202,
"rule": 0,
"season": 7,
"rst": 0,
"ts1": 1591187503,
"ts2": 1591187515,
"reg": "000000247"
}
}, // 以下略
}
こちらに入っているシーズンのIDとrst等の値を
'https://resource.pokemon-home.com/battledata/ranking/{season_id}/{rst}/{ts2}/pdetail-{1~5の値}'
に突っ込んでAPIを叩くとポケモンHOMEからデータを得られる。
2. データダウンロード
適当に書いたコードなので悪しからず
(カレントディレクトリにresourcesフォルダ、resources\splitフォルダを事前に作成しています。)
import urllib.request
import json
import datetime
import os
def load_ids():
ids = "";
# さっきのAPIリクエストで得られたjsonを読み込む
with open(ID_FILEPATH, 'r', encoding='utf-8') as json_open:
return json.load(json_open)
def check_dir(path):
if not os.path.isdir(path):
os.makedirs(path)
def get_response(url, file_name):
try:
with urllib.request.urlopen(url) as response:
body = json.loads(response.read())
with open(f'resources//split//{file_name}', 'w') as f:
json.dump(body, f, indent=4)
return True
except urllib.error.URLError as e:
print(e.reason)
return False
def make_json(ids):
for season_number in ids['list'].keys():
for season_id in ids['list'][season_number].keys():
rst = ids['list'][season_number][season_id]['rst']
ts2 = ids['list'][season_number][season_id]['ts2']
for i in range(1,6,1):
url = f'https://resource.pokemon-home.com/battledata/ranking/{season_id}/{rst}/{ts2}/pdetail-{i}'
file_name = f'Season{season_number}_{"Single" if season_id[4]=="1" else "Double"}_{i}.json'
if get_response(url, file_name):
with open('log', 'a') as f:
print(f'{datetime.datetime.now()} | Generated: {file_name}', file=f)
def merge_json(ids):
for i in ids['list'].keys():
for j in ids['list'][i].keys():
rule = "Single" if j[4] == '1' else "Double"
files = []
for n in range(1,6,1):
with open(f'.//resources//split//Season{i}_{rule}_{n}.json', 'r', encoding='utf-8') as json_open:
files.append(json.load(json_open))
jsonMerged = {**files[0], **files[1], **files[2], **files[3], **files[4]}
file_name = f'Season{i}_{rule}_master.json'
with open(f'resources//{file_name}', 'w') as f:
json.dump(jsonMerged, f, indent=4)
with open('log', 'a') as f:
print(f'{datetime.datetime.now()} | Merged : {file_name}', file=f)
if __name__ == "__main__":
ids = load_ids()
# ここはお好きなディレクトリを指定してください
for path in ['.//resources', './/resources//split']:
check_dir(path)
make_json(ids)
merge_json(ids)
print('Suceeded')
上記のスクリプトを実行すると、シーズン1から最新シーズンまでのバトルデータのjsonファイルが保存される。
しかし厄介なことに1シーズンごとにjsonファイルが5つに分割されていて大変厄介、
マージして1シーズン1ファイルにしてやろう。
def merge_json(ids):
for i in ids['list'].keys():
for j in ids['list'][i].keys():
rule = "Single" if j[4] == '1' else "Double"
files = []
for n in range(1,6,1):
with open(f'.//resources//split//Season{i}_{rule}_{n}.json', 'r', encoding='utf-8') as json_open:
files.append(json.load(json_open))
jsonMerged = {**files[0], **files[1], **files[2], **files[3], **files[4]}
with open(f'resources//Season{i}_{rule}_merged.json', 'w') as f:
json.dump(jsonMerged, f, indent=4)
ids = "";
with open(ID_FILEPATH, 'r', encoding='utf-8') as json_open:
ids = json.load(json_open)
make_jsonchunk(ids)
これで先ほどの先ほどの大量のjsonファイルは1つずつに集約されたことだろう。
こちらのjsonの中身はというと以下の通り。
// 今回は適当なシーズンの1つの結合されたjsonをpokemon.jsonと名付けた
// .\Datachunk\pokemon.json
{
"図鑑番号" : {
"p_detail_id":{
"temoti":{
// 採用されている技TOP10
"waza":[
{
"id":"xxxx",
"val":"value" // 採用率、パーセンテージ
},
...
],
// 採用されている特性
"tokusei":[
{
"id": "xxxx",
"val": "value" // 採用率、パーセンテージ
},
...
],
// 採用されている持ち物に入れられているポケモンTOP10
"motimono": [
{
"id": "xxxx",
"val": "value" // 採用率、パーセンテージ
},
...
],
// 一緒にバトルチームに入れられているポケモンTOP10
"pokemon": [
{
"id": "xxxx",
"form": "value" // フォルム
},
....
]
},
"lose": {
// このポケモンを倒した技TOP10
"waza": [
{
"id": "xxxx",
"val": "value" // パーセンテージ
},
...
],
// このポケモンを倒したポケモンTOP10
"pokemon": [
{
"id": "xxxx",
"form": "value" // フォルム
},
...
],
},
"win": {
// このポケモンが倒した技TOP10
"waza": [
{
"id": "xxxx",
"val": "value" // パーセンテージ
},
...
],
// このポケモンが倒したポケモンTOP10
"pokemon": [
{
"id": "xxxx",
"form": "value" // フォルム
},
...
]
}
}
}
}
ポケモンHOMEでは得られない、TOP10外のポケモンについても採用されている技や一緒に採用されているポケモンなどの諸情報が得られるようだ。
まとめると、取得できるデータは以下の通り
- 採用されている技TOP10
- 採用されている特性
- 採用されている持ち物に入れられているポケモンTOP10
- 一緒にバトルチームに入れられているポケモンTOP10
- このポケモンを倒した技TOP10
- このポケモンを倒したポケモンTOP10
- このポケモンが倒した技TOP10
- このポケモンが倒したポケモンTOP10
これらのデータを駆使してできるだけ尤もらしいTierの算出を試みる。
ただ今回はTier算出方法は本題ではないのでそれっぽい結果が得られそうな指標を適当に考えることにする。
3. Tier選定
- 問題:パーティ採用率が高く、選出率も高いポケモンが上位にくるようにしたい
- 課題:選出率や採用率のデータがないため、何かしらの指標で代替する必要がある
メタをどのように算出するか
メタから考えてみる
Tier1、つまり環境トップメタは、今一番強くて流行っているポケモンを指しているので、”強い”と”流行っている”を軸に指標を作成することにする。
"強い"
今回持っているデータには「このポケモンを倒したポケモンTOP10」が含まれてる。倒した回数・倒せる相手の数はそのポケモンの環境における強さを代替していると考えられる。
"流行っている"
"流行っている"かどうかの基準に対して最も直感的な指標はパーティ採用率であるが、今回はそのデータを入手できないため、他の基準で代替する必要がある。今回のデータでは「このポケモンと一緒に採用されているポケモンTOP10」が含まれているため、このデータをもとに幅広いパーティで採用されていると考えられるポケモンを順位データから算出することとした。
また、選出回数は先述した倒した回数の多さはの多さに比例して大きくなる考えられるため、あくまでパーティ採用率のみで"流行っている"かどうかの指標とする。
試行
ライブラリインポート
import json
import csv
import pandas as pd
from sklearn import preprocessing
データ読み込み
pokedex = "";
with open('.//Datachunk//bundle.json', 'r', encoding='utf-8') as json_open:
pokedex = json.load(json_open)
pokedex = "";
with open('.//Datachunk//bundle.json', 'r', encoding='utf-8') as json_open:
pokedex = json.load(json_open)
pdetail = "";
with open('.//Datachunk//pokemon.json', 'r', encoding='utf-8') as json_open:
pdetail = json.load(json_open)
ファイル出力用関数
def make_csv(pdetail, filename, method = 'temoti'):
# method = 'temoti', 'win', 'lose'
write_csv(["Book Number","Pokemon", "component", "value_or_rank"], filename, "w")
for pokenum in list(pdetail.keys()):
for p_detail_id in list(pdetail[pokenum].keys()):
t_name = get_pokemonname(pokenum, p_detail_id)
for rank, poke_associations in enumerate(list(pdetail[pokenum][p_detail_id][method]['pokemon'])):
a_name = get_pokemonname(poke_associations['id'], poke_associations['form'])
write_csv([pokenum, t_name, a_name, rank+1] , filename, "a")
流行指数計算&出力用関数
def make_index(filename):
df = pd.read_csv(filename, encoding='utf-8')
concated_df1 = df.groupby('component', as_index=False)['value_or_rank'].mean()
concated_df1.columns = ['Pokemon', 'RankAverage']
concated_df2 = df.groupby('component', as_index=False)['value_or_rank'].sum()
concated_df2.columns = ['Pokemon', 'Top10Count']
concat_df = pd.concat([concated_df1,concated_df2], axis = 1, join = 'inner')
concat_df =pd.concat([concated_df1[concated_df1.columns[0]], \
concat_df.drop(concat_df.columns[2], axis =1)], axis = 1)
concat_df['RankAverage_std'] = preprocessing.minmax_scale(concat_df['RankAverage'])
concat_df['Top10Count_std'] = preprocessing.minmax_scale(concat_df['Top10Count'])
concat_df['Crt'] = concat_df["RankAverage"] * concat_df["Top10Count"]
concat_df['Crt_by_std'] = concat_df['RankAverage_std'] * concat_df['Top10Count_std']
return concat_df.sort_values('Crt', ascending = False)
実行
make_csv(pdetail, "test1.csv", 'lose')
make_index('test1.csv').to_csv('test2.csv', index=False)
| ポケモン | 平均採用順位 | 採用順位TOP10カウント | RankAverage_std | Top10Count_std | Crt Crt_by_std |
|:------------:|------------:|------------:|------------:|------------:|------------:|------------:|
| ドリュウズ | 4.863158 | 462 | 0.429240 | 0.956432 | 2246.778947 | 0.410538 |
| ローブシン | 5.742424 | 379 | 0.526936 | 0.784232 | 2176.378788 | 0.413240 |
| サマヨール | 4.747368 | 451 | 0.416374 | 0.933610 | 2141.063158 | 0.388731 |
| ... | ... | ... | ... | ... | ... | ... |
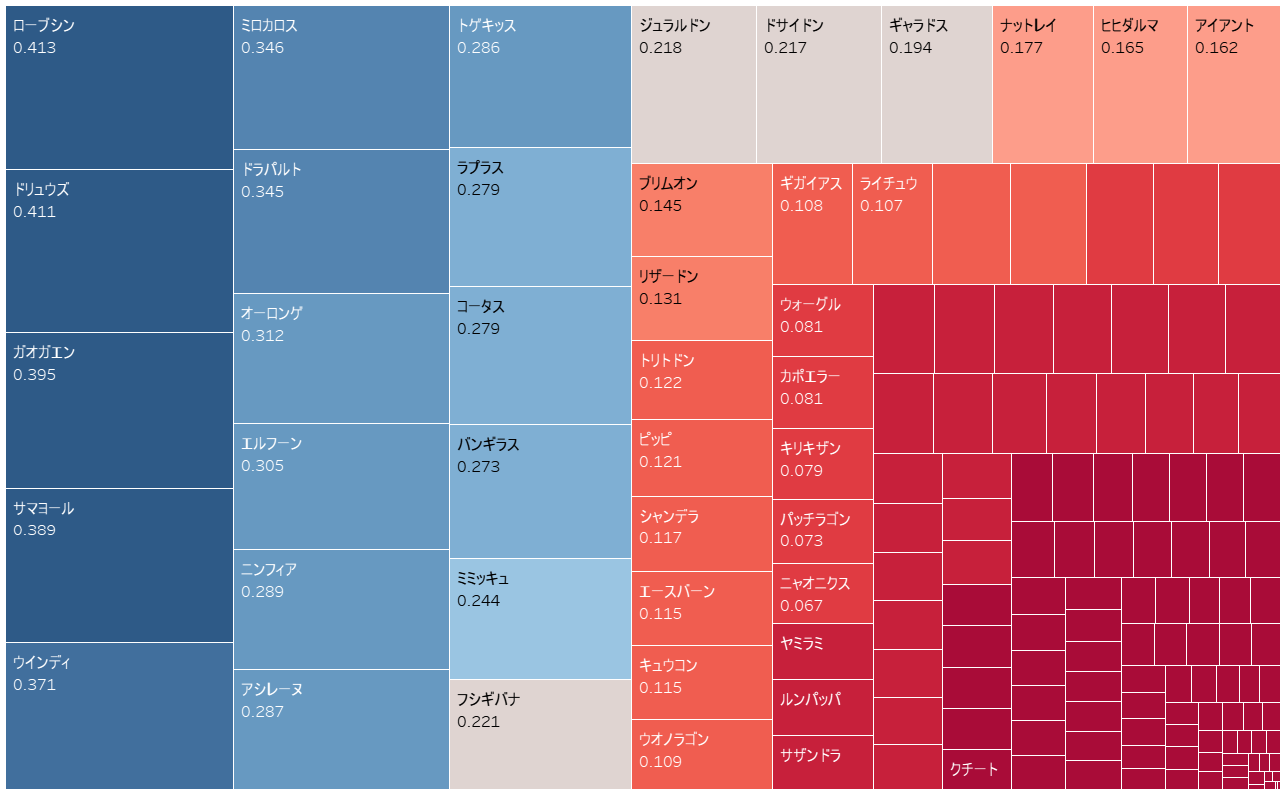
※注:上記はダブルバトルのデータから作成しています
このシーズンは格闘はローブシン一択だったようだ。
おおよそは反映できるているような気がする。
メタ指数の算出
メタ指数の算出は正規化した [倒せる敵の数] * [順位] から計算をする。
先ほどと同様の関数から結果を出力した。
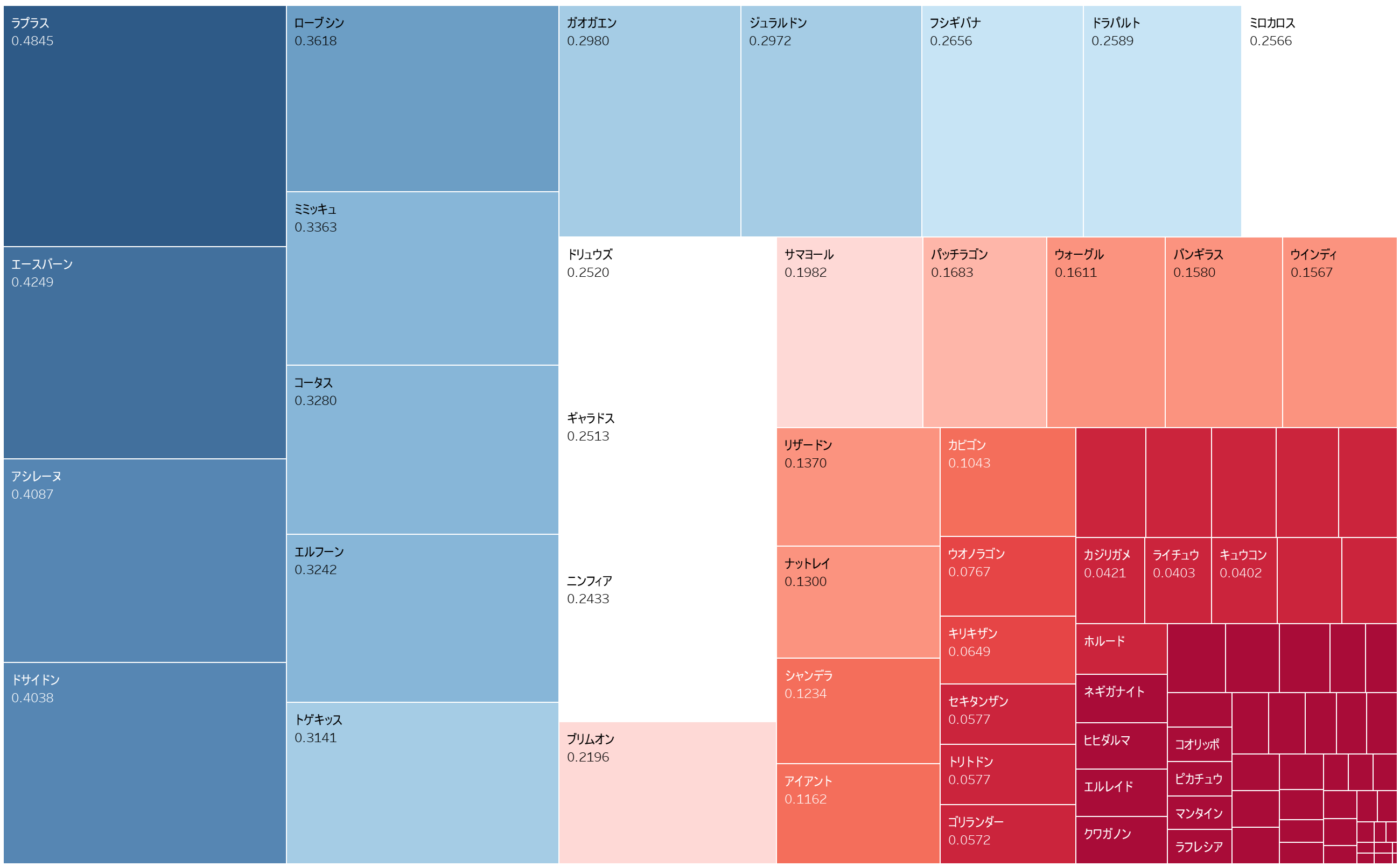
ランキングに挙がったポケモンは採用ランキングよりも少なくなった。ラプラスが最大となったのはやや意外だが、ダブルらしさを感じる。
雑過ぎる算出法だがモノは試しなのでとりあえず今回はこの二つの指標を採用することにした。
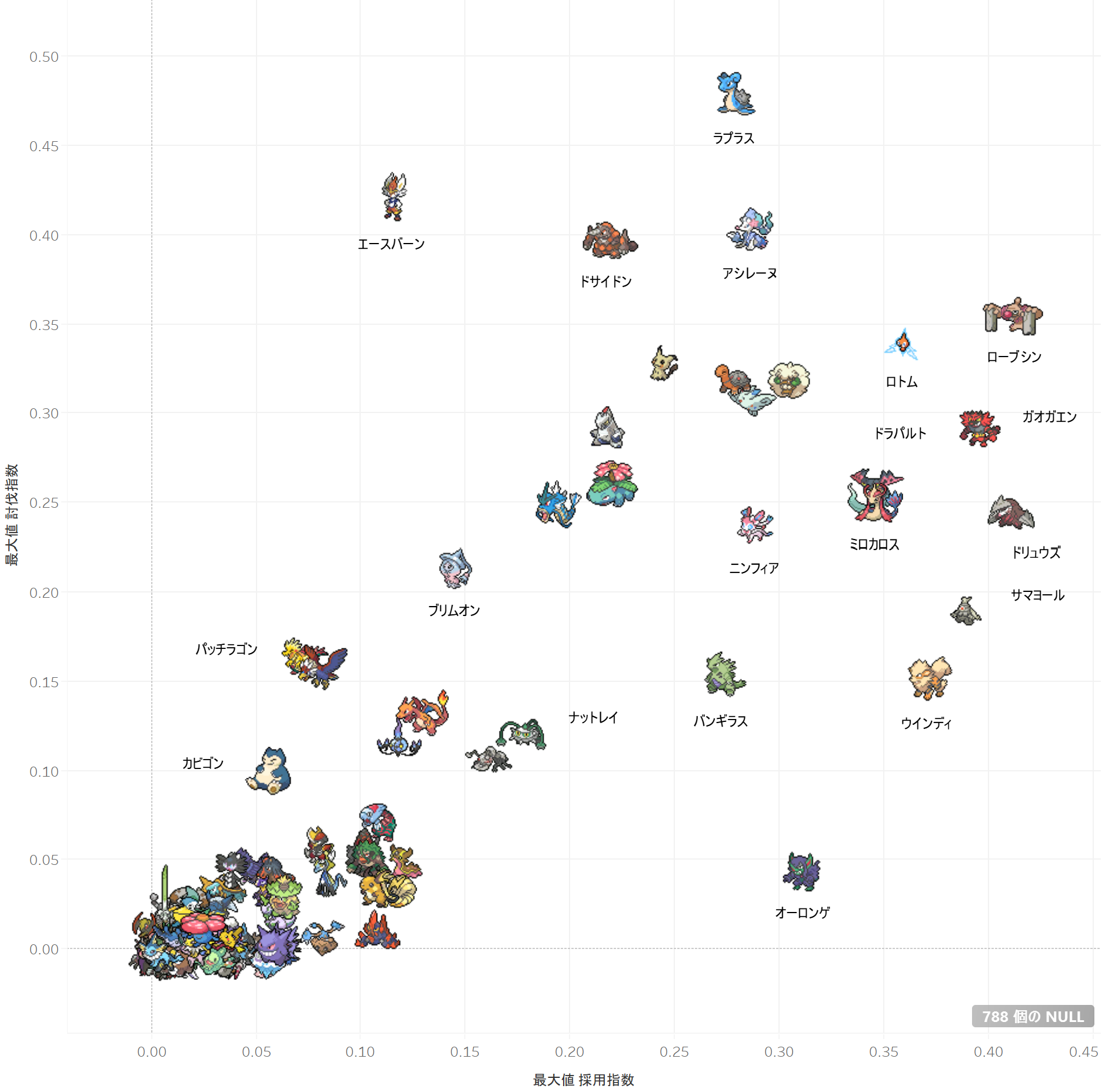
可視化
散布図
散布図上の形状を任意の形にする方法については、本題からそれるのでいつかまた記事にする。
取り急ぎはこちらを参照ください。
またポケモンのアイコンはこちらを拝借しました。
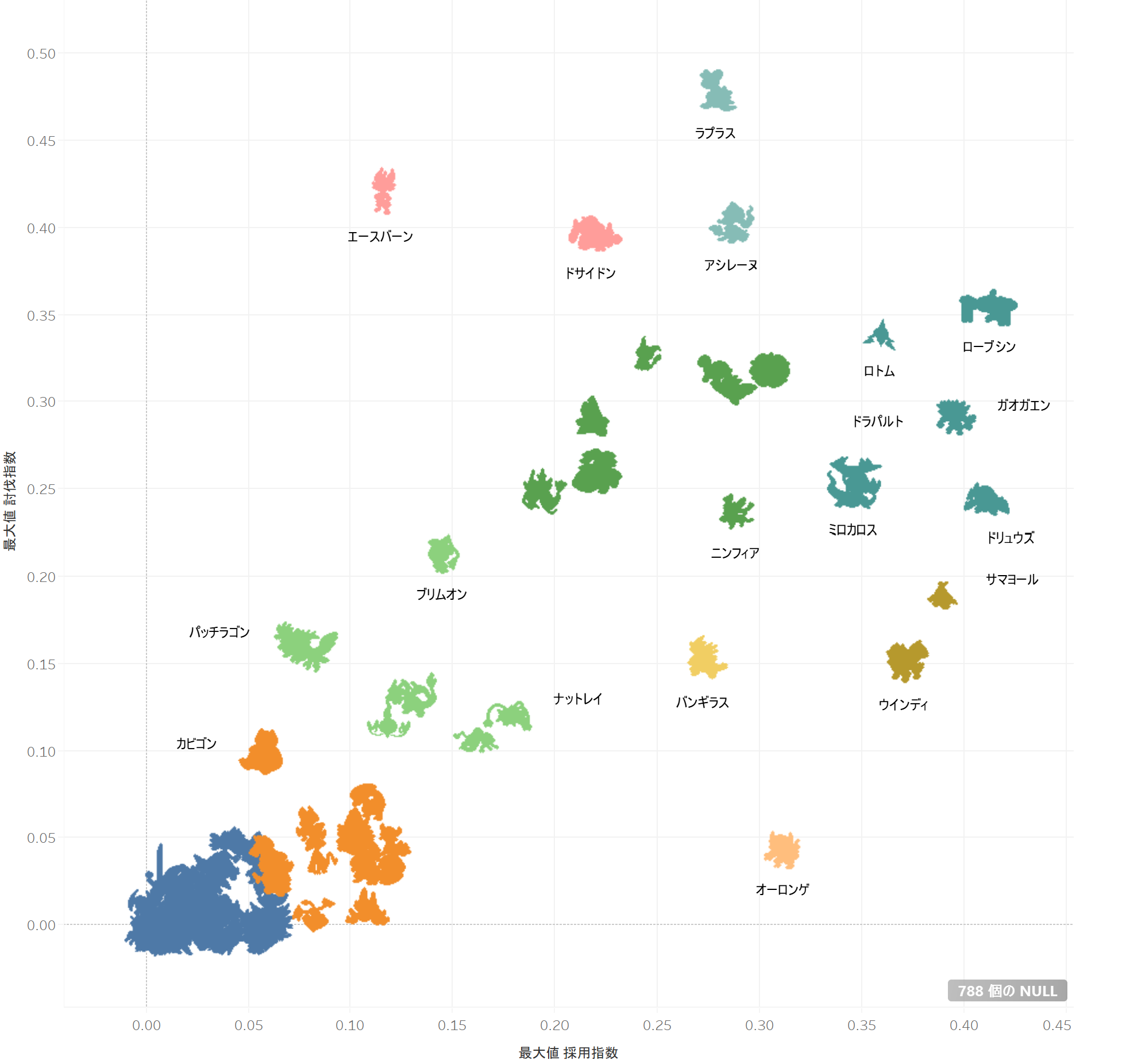
クラスタリング
クラスター数を10個に設定してクラスタリングしてみた。それとなくTier付けできそうな(な気がする)。
| シーズン | ルール |ポケモン | 平均採用順位 | 採用順位TOP10カウント | RankAverage_std | Top10Count_std | Crt Crt_by_std |
|:------------:|:------------:|:------------:|------------:|------------:|------------:|------------:|------------:|------------:|
| シーズン1 | シングル | ドリュウズ | 4.863158 | 462 | 0.429240 | 0.956432 | 2246.778947 | 0.410538 |
| シーズン1 | シングル | ローブシン | 5.742424 | 379 | 0.526936 | 0.784232 | 2176.378788 | 0.413240 |
| シーズン1 | ダブル | サマヨール | 4.747368 | 451 | 0.416374 | 0.933610 | 2141.063158 | 0.388731 |
| シーズン2 | シングル | ... | ... | ... | ... | ... | ... | ... |
データの生成
先ほどの指数を全シーズンのシングル・ダブル両方について出力する。手作業でひとつひとつやってもいいが面倒なのでプログラムを用意する。
def Rename(x):
for key in rename_dict.keys():
if x[2] == key:
x[2] = rename_dict[key]
return x[2]
rename_dict = {'ニャオニクス':'ニャオニクス♂',
'ギルガルド':'ギルガルド盾',
'ヒヒダルマ':'ヒヒダルマN',
'バスラオ':'バスラオ赤',
'ルガルガン':'ルガルガン昼',
'メテノ':'メテノ(流星)',
'イエッサン':'イエッサン♂'}
余談だが、この関数を使って名前を変更しているのは、Tableau上で可視化するにあたって少々厄介なことになるためです。今回は触れないので、「なんか名前変えてるな」くらいに思っていただけると良いかと。
def cal_crt(df, method='temoti'):
if method == 'temoti':
row_name = "流行指数"
elif method == 'win':
row_name = 'メタ指数'
concated_df1 = df.groupby('B', as_index=False)['value'].mean()
concated_df1.columns = ['Pokemon', 'RankAverage']
concated_df2 = df.groupby('B', as_index=False)['value'].sum()
concated_df2.columns = ['Pokemon', 'Top10Count']
concat_df = pd.concat([concated_df1,concated_df2], axis = 1, join = 'inner')
concat_df =pd.concat([concated_df1[concated_df1.columns[0]], \
concat_df.drop(concat_df.columns[2], axis =1)], axis = 1)
concat_df['RankAverage_std'] = preprocessing.minmax_scale(concat_df['RankAverage'])
concat_df['Top10Count_std'] = preprocessing.minmax_scale(concat_df['Top10Count'])
concat_df['Crt'] = concat_df["RankAverage"] * concat_df["Top10Count"]
concat_df[row_name] = concat_df['RankAverage_std'] * concat_df['Top10Count_std']
df = concat_df.sort_values('Crt', ascending = False)
return df.drop(['RankAverage', 'Top10Count', 'RankAverage_std', 'Top10Count_std', 'Crt'], axis=1)
def get_name(num, p_detail_id, method='pokemon'):
if method == 'pokemon':
name = ''
if num == "876":
if p_detail_id == "0":
name = "イエッサン♂"
else:
name = "イエッサン♀"
elif num == "479":
if p_detail_id == "0":
name = "ロトム(デフォ)"
elif p_detail_id == "1":
name = "ロトム(火)"
elif p_detail_id == "2":
name = "ロトム(水)"
elif p_detail_id == "3":
name = "ロトム(氷)"
elif p_detail_id == "4":
name = "ロトム(飛行)"
elif p_detail_id == "5":
name = "ロトム(草)"
else:
name = pokedex['poke'][int(num) -1]
elif method == 'motimono':
name = pokedex['item'][num]
else:
name = pokedex[method][num]
return name
def data_trans(pdetail, method1 = 'temoti', method2='pokemon', column = ["A", "B", "value"]):
t_names = []
a_names = []
ranks = []
for pokenum in list(pdetail.keys()):
for p_detail_id in list(pdetail[pokenum].keys()):
t_name = get_name(pokenum, p_detail_id, method='pokemon')
for rank, component in enumerate(list(pdetail[pokenum][p_detail_id][method1][method2])):
a_name = get_name(component['id'], component[list(component.keys())[1]], method=method2)
t_names += [t_name]
a_names += [a_name]
ranks += [rank+1]
return pd.DataFrame(
data = {column[0]: t_names,column[1]: a_names, column[2]: ranks},
columns = column
)
from pathlib import Path
import os
import re
# ご自身のディレクトリを選択
file_dir = ".//resources"
p = Path(file_dir)
files = sorted(p.glob("*"))
Seasons = []
Rules = []
df_master = pd.DataFrame(columns = ['Season', 'Rule', 'Pokemon','流行指数', 'メタ指数'])
for rule in ['Single', 'Double']:
for season_num in range(1,12,1):
for method in ['temoti', 'win']:
with open(f'{file_dir}//Season{season_num}_{rule}_master.json', 'r', encoding='utf-8') as json_open:
data = json.load(json_open)
if method == 'temoti':
df_fashion = cal_crt(trans_data(data, method=method), method=method)
elif method == 'win':
df_meta = cal_crt(trans_data(data, method=method), method=method)
df = pd.merge(df_fashion, df_meta, on='Pokemon', how='outer').fillna(0)
df['Season'] = season_num
df['Rule'] = rule
df_master = pd.concat([df_master, df], axis = 0)
df_master['Pokemon'] = df_master.apply(Rename,axis=1)
df_master.to_csv(f'ALL_SEASON_METAVALUES.csv', index=False)
4. ダッシュボード化
上記の散布図上のポケモンにマウスオーバーすると一緒に採用されやすいポケモン等の情報が表示されるようなダッシュボードをつくることにした。
仕様検討
とりあえずロウデータから読み取れる以下のデータが表示されるようにしたい。
- 採用されている技TOP10
- 採用されている特性
- 採用されている持ち物に入れられているポケモンTOP10
- 一緒にバトルチームに入れられているポケモンTOP10
- このポケモンを倒した技TOP10
- このポケモンを倒したポケモンTOP10
- このポケモンが倒した技TOP10
- このポケモンが倒したポケモンTOP10
データの生成
データの生成にあたってcsvを作成して扱いやすくする。
new_dict = {}
for n in pokedex['item'].keys():
n = int(n)
if n < 148:
pass
elif n < 260:
id_ = n-143
new_dict[id_] = pokedex['item'][str(n)]
elif 264 < n:
id_ = n-148
new_dict[id_] = pokedex['item'][str(n)]
pd.DataFrame(new_dict.values(), index=new_dict.keys(), columns = ['item']).to_csv('item_index.csv')
pd.DataFrame(pokedex['waza'].values(), index=pokedex['waza'].keys(), columns = ['waza']).to_csv('skill_index.csv')
pd.DataFrame(pokedex['tokusei'].values(), index=pokedex['tokusei'].keys(), columns = ['tokusei']).to_csv('tokusei_index.csv')
手持ち
%%timeit
Seasons = []
Rules = []
column_a = {'waza': '採用率の高い技','pokemon':'併用率の高いポケモン' , 'tokusei':'採用率の高い特性' , 'motimono':'採用率の高い持ち物'}
file_names = {'waza':'ALL_SEASON_SKILL.csv','pokemon':'ALL_SEASON_COMBIND_PARTNER.csv', 'tokusei':'ALL_SEASON_IDIOSYNCRASY.csv', 'motimono':'ALL_SEASON_ITEM.csv'}
for method in column_a.keys():
df_master = pd.DataFrame(columns = ['Season', 'Rule', 'Pokemon', column_a[method], f'Rank_{column_a[method]}'])
for rule in ['Single', 'Double']:
for season_num in range(1,12,1):
with open(f'{file_dir}//Season{season_num}_{rule}_master.json', 'r', encoding='utf-8') as json_open:
data = json.load(json_open)
df = data_trans(data, method2 = method, column = ['Pokemon', column_a[method], f'Rank_{column_a[method]}'])
df['Season'] = season_num
df['Rule'] = rule
df_master = pd.concat([df_master, df], axis = 0)
df_master['Pokemon'] = df_master.apply(Change_Name,axis=1)
df_master.to_csv(file_names[method], index=False)
53.9 s ± 3.33 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
倒された技と倒されたポケモン
まずはこのポケモンを倒した技とポケモンから。
%%timeit
Seasons = []
Rules = []
column_a = {'waza': '倒された技','pokemon':'倒されたポケモン'}
file_names = {'waza':'ALL_SEASON_KNOCKED_SKILL.csv','pokemon':'ALL_SEASON_KNOCKED_BY.csv'}
for method in column_a.keys():
df_master = pd.DataFrame(columns = ['Season', 'Rule', 'Pokemon', column_a[method], f'Rank_{column_a[method]}'])
for rule in ['Single', 'Double']:
for season_num in range(1,12,1):
with open(f'{file_dir}//Season{season_num}_{rule}_master.json', 'r', encoding='utf-8') as json_open:
data = json.load(json_open)
df = data_trans(data,method1='lose', method2 = method, column = ['Pokemon', column_a[method], f'Rank_{column_a[method]}'])
df['Season'] = season_num
df['Rule'] = rule
df_master = pd.concat([df_master, df], axis = 0)
df_master['Pokemon'] = df_master.apply(Change_Name,axis=1)
df_master.to_csv(file_names[method], index=False)
17.6 s ± 1.14 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
倒した技と倒した敵
%%timeit
Seasons = []
Rules = []
column_a = {'waza': '倒した技','pokemon':'倒したポケモン'}
file_names = {'waza':'ALL_SEASON_KNOCKING_SKILL.csv','pokemon':'ALL_SEASON_KNOCKING.csv'}
for method in column_a.keys():
df_master = pd.DataFrame(columns = ['Season', 'Rule', 'Pokemon', column_a[method], f'Rank_{column_a[method]}'])
for rule in ['Single', 'Double']:
for season_num in range(1,12,1):
with open(f'{file_dir}//Season{season_num}_{rule}_master.json', 'r', encoding='utf-8') as json_open:
data = json.load(json_open)
df = data_trans(data,method1='win', method2 = method, column = ['Pokemon', column_a[method], f'Rank_{column_a[method]}'])
df['Season'] = season_num
df['Rule'] = rule
df_master = pd.concat([df_master, df], axis = 0)
df_master['Pokemon'] = df_master.apply(Change_Name,axis=1)
df_master.to_csv(file_names[method], index=False)
15.7 s ± 1.14 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
可視化
先述のリストに対応する8つのファイルが出力できたのでTableauワークブックに突っ込んで表示されるようにしてみる。
先ほど作成した9つのcsvファイルをユニオンして種族値等が記録されているファイルと結合。後者のファイルは急に出てきたが、これはカスタム形状を機能を使って散布図上にポケモンのミニアイコンを表示するのに必要となる。単に散布図を作るだけなら不要なので今回は深く触れません。

データを読み込めたらあとは設置していくだけ。Tableauは操作性に優れていてとても良い(ダイレクトマーケティング)。
Tableau Public上にアップロードしておいたので完成品をご覧になりたい方はぜひ。
デザインがほぼ初期設定なのについてはご勘弁を。
でき上げったものを触るとこんな感じ。
ダッシュボード化するにあたってアクション機能を多様した。Tableauのマウスオーバーアクションについてはこちらを参照されたい。
※余談だが技や持ち物、特性などにIDを紐づける(先ほど作成した~_index.csv)ことができるので、マウスオーバーで外部のウェブサイトから情報を取得する、なんてこともできる。可能性は無限大。
5. ゴールの確認
- APIから得られたデータに加工を加えて、公式が出している以上の示唆を得る
- Tableauにより可視化し、データを見やすくする
今回流行指数とメタ指数という指標をザックリと定義して散布図にすることで時系列やシングル・ダブルの対戦環境の移り変わりを図示することに成功した。
上記の2つの目標は概ね達成できたと言っても良いだろう。
一方で先述した指標には以下の点で問題がある。
-
公式が出している採用率ランキングと相違がある(例:パッチラゴンのランクが低い)
-
ユーザーが出しているTier表と相違がある(例:パッチラゴンのランクが低い)
-
見えない貢献をしているポケモンが過小評価されてしまう(敵を倒さないとメタ指数は低くなるのでサポート型ポケモンのランクが低くなりやすい、手持ちにいるだけで相手の選出を縛れるポケモンが反映されないなど)
-
明確なTier算出を行えていない(今回は非階層クラスタリングを使っているが、Tier〇かまでを明示することはできていない)
などなど他にも様々な問題があると思う。この指標は今後改善していくとして、ランクバトルの対戦データを可視化できたのは有意義だったのではないだろうか。
気が向いたらgihubに上げたいと思います。
→アップしました(2020/11/03)
それではまた。
追記
2020/11/03 Githubにて全コードを公開しました。
環境
-
Windows10 Home 1903
-
Python 3.7.6
-
Pandas 1.0.1
-
Sklearn 0.23.2
-
Tableau Desktop 2020.1.20.0427.1803
出典
- エレキブル - Pokédex(Pokémon公式)
- ポケモンHOMEとは - Pokémon Home公式サイト
- メタ - Wikpedia
- ポケモンホームのバトルデータ(ランクバトル)のJSONを解析する。 - return $lock
- ポケモン剣盾のランクバトルのバトルデータをMetabaseで可視化する。- Qiita
- トップメタ - MTGWiki
- ビュー内のマークの表示を制限する - Tableau
- PokéSprite - Github
- アクション - Tableau
- アクションとダッシュボード - Tableau
- データの集計、結合またはユニオン - Tableau
©2020 Pokémon ©1995-2020 Nintendo/Creatures Inc./GAME FREAK inc. ポケットモンスター・ポケモン・Pokémonは任天堂・クリーチャーズ・ゲームフリークの登録商標です。