こんにちは!
マナビDXクエスト参加中の非エンジニア44歳です。
マナビDXクエスト、およそ2000人が参加してるわりにはTwitterでそれほど盛り上がってる感が無きにしも非ずでして、データサイエンスを志すおっさんのはしくれとして、軽く勉強も兼ねてTweet具合を可視化してみました。
やっぱり入学式があった9月がピークなんですね。
しかし3月のピーク、これなんでしょかしら??
Tweet取得に使用したのはsnscapeです。
基本的にローコードしかできない人間なので、一つ一つ薄氷を踏むように
あれこれやっていますから、カタカタカタッターン!ってキーボードたたいて
魅せ映えチャートがドドーンっと出るこたぁありません。
Tweet取得から可視化まではこんな感じ。
こちらのQiita記事を参考にさせていただいています。
snscapeで** マナビDX を含むTweetを取得。
!pip install snscrape
import pandas as pd
import snscrape.modules.twitter as sntwitter
#検索するキーワード
search = "マナビDX"
#Twitterでキーワードをスクレイピング
scraped_tweets = sntwitter.TwitterSearchScraper(search).get_items()
#データフレームに変換する
df = pd.DataFrame(scraped_tweets)
スプレッドシートを手作業で新規作成
※GoogleColabから新規作成できるけど、1つのファイルに検索結果をシート分けしたいからこれは手作業で。
スクレイピングのたびにファイルができるとうざい。
これからColabに指示する用にスプレッドシートのURLを取得というかコピー。
スプレッドシートに新規シート作成、dfを入力する。
# シートを新しく挿入する。
st_name = "マナビDX_scrape"
st = ss.add_worksheet(title=st_name, rows=len(df_manabiDX), cols=5)
set_with_dataframe(ss.worksheet(st_name), df_manabiDX, include_index=False)
#行列を入れる意味があるのかはよくわからんけど。
ここまでがTweet取得からスプレッドシートへの反映
こっからはクエリ関数で集計可視化
クエリ関数便利よね。
詳しくはこちら。SQL書ける人は超重宝するはず。
スプシの集計をピボットテーブルでやると見た目が雑くてスッキリしないんですよね。
クエリ関数なら、importrangeと組み合わせて他のファイルからの集計にもつかえて重宝します。
今日は基本的なカウント集計だけですが。
ここで問題が
Colabからスプシに書き込んだ日付列が文字列扱いで使いにくいので一度分解してからdate()関数で日付に仕立て直す手間がかかる。
Colab側で年月日のカラムに分解してからスプシ上でdate()関数に渡してもいいけどあんまり手間はかわらん。好みの問題。
また別の機会に書きますが、こういうときはarrayformula関数いいよarrayformula。
大事なことだから2回言いました。
気を取り直してグラフを作る。
日付とTweetの2列にした縦型の表を選択します。
今回はA列とB列、1行目にヘッダ入れてます。
あとは、適当なセルに以下の関数を書きましょう・
=query(A:B,"select A,COUNT(B) group by A")
年月日でまとめられたTweet数カウントの表ができると思います。
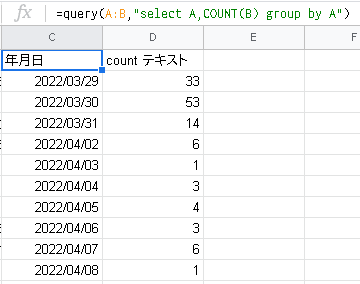
あとはこの2列を選択してグラフを作成。
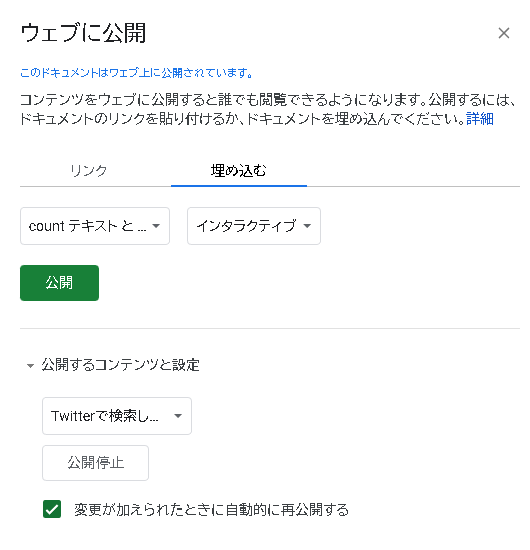
グラフ設定から、このグラフを公開をクリックして埋め込み用のコードを取得すれば、あとは好きなところに埋め込むだけです。
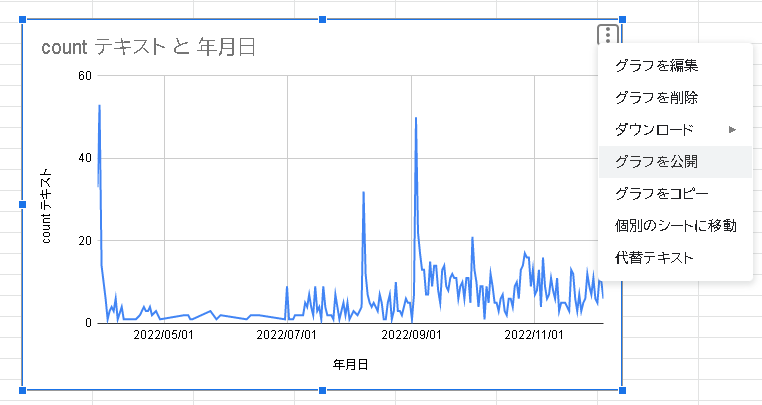
改めてみてみると、2000人規模で参加してる割には寂しいなぁ。
やっぱり身バレ意識してつぶやかない勢が多数なんでしょうね。
以上です。
データの可視化はPowerBIデスクトップやLookerStudioみたいなBIツールでダッシュボード作るのも楽しいけれど、スプレッドシートでもインタラクティブなものを作ることもできるのでまた後日記事化しようと思います。