Watson Discoveryが日本語に完全対応した、とのこと。
実際に社内にあるFAQを取り込んでみて、得られた知見は下記の通り。
※ 実際のデータの取込方法等は最下部の参考記事がとても分かり易いのでご覧ください。
実装したもの
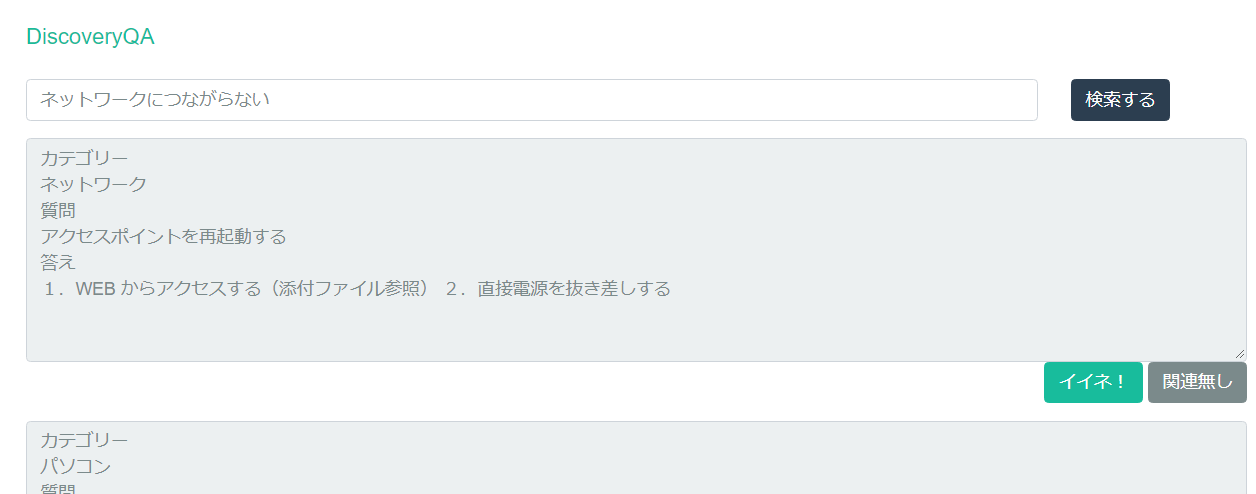
見た目
課内で使える簡単検索用Webサービスを作ってみました。UIが手抜きなのはご愛敬。
検索結果に「イイネ!」をすると、Discoveryに連携して評価をあげます。「関連無し」はその逆ですね。
この評価によって、scoreが変わりより自分たちの業務に沿った答えを得られるようになります。
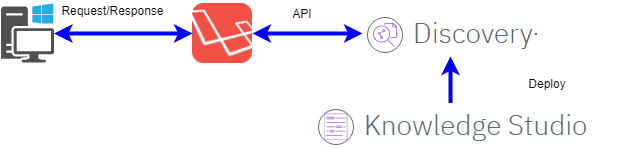
構成
LaravelからAPI経由でDiscoveryを利用。API通信には、使い勝手◎なGuzzleを利用。
STEP1 データを単純にDiscoveryに取り込んだだけの状態
この時点で出来る事
- アップロードするだけでお手軽簡単な全文検索エンジンとして使えます。
- Discoveryらしさとして「~~帳票が出なくなった」という自然言語での質問に対して、「~帳票が出ない場合、プリンタを確認して下さい」
という答えが得られるようになります。
(この場合、「帳票」というキーワードがヒットしてくれるようです)
このため、bot等にも組み込みやすいですね。また、Speech To Textでホームスピーカー的な使い方も面白いかもしれません。
この時点での課題
- 「帳票」ではなく、「紙が出ない」といった具合にキーとなる言葉が入らない場合には適切な検索結果を得る事は出来ませんでした。
- 全文検索なので余計な検索結果がヒットする事も多いです。「帳票が出ない」という質問に対して、「~~という項目が出ない」もヒットします。(出ないでヒットしまっている為)
STEP2 検索結果と回答の関連付けを教育する
Watsonが順位付けの学習を始めるためには49個以上の質問とその評価をする必要がある様です。
DiscoveryのUIツールからも評価をする事が出来ますし、APIからの評価を行う事も出来ます。
ちなみに、、、
-
APIからの評価の場合0(関連無し)~100(関連有り)の間で評価に自由に強弱をつける事が出来ます。
(例えば、UI上で★の数で評価を実現する事なんかも可能。★0⇒0,★1⇒20,★2⇒40,★3⇒60,★4⇒80,★5⇒100の様に。)
DiscoveryのUIツールからの評価は0 or 10の2択となります。
この時点で出来る事
- 若干の順位の調整は出来たような気がします…ただ、評価の基準を(0 or 10)としていたせいかあまり劇的な改善を感じる事は出来ませんでした…質問のサンプル数が100件以下と少なかったせいかもしれません…
STEP3 Watson Knowlege Studio(WKS)と連携してみる
Watson Knowlege StudioでDiscoveryのデータに新たなカスタムエンリッチを追加してみました。
これを使う事により、Discoveryからの回答のEntityにWKSで定義したTypeが付与されている事が確認できるようになりました。
↓抜粋↓
"enriched_text": {
"keywords": [
{
"text": "質問",
"relevance": 0.673426,
"count": 1
},
],
"entities": [
{
"type": "network",
"text": "ネットワーク",
"disambiguation": {
"subtype": [
"NONE"
]
},
"count": 1
},
{
"type": "network",
"text": "アクセスポイント",
"disambiguation": {
"subtype": [
"NONE"
]
},
"count": 1
}
]
この時点で出来る事
- Entityの観点からDQL(Discovery Query Language)を使えるようになりました。これにより、通常の全文検索の更なる絞り込み条件(Filter)として
Entityが使えるようになります。(上記でいうと、type is networkURLだとfilter=enriched_text.entities.type::"network"で絞り込むことでノイズとなるデータを除外できます。 - 文書の分析に
Entityを使えます。例えばnetworkを含むQAは全体の何%を占めるのかを分析したいとき等に有効だと思われます。類似した書類を探す事にも使えそうです。
全体を通しての課題
- TextにセットされるJsonはアップロードしたファイルのテキスト全量ではない上、構成や添付されている画像については読み込まれないのでこれだけを回答にする事は出来ません。今回のサンプルの様に全文検索エンジンとして使う時にはあくまで、元ファイルへのとっかかりとして利用するのが良さそうです。
Watson Assistantとの棲み分け
自然言語にも対応しているとはいえ、Discoveryは検索を主な機能している為、Assistantに実装されている
- ランダムでジョークを返す
- 様々な挨拶に対応する
- botにキャラクタを持たせる
等にはあまり適していないと思います。また、Watson AssistantのIntent判定程、空気を読んでもくれませんでした。
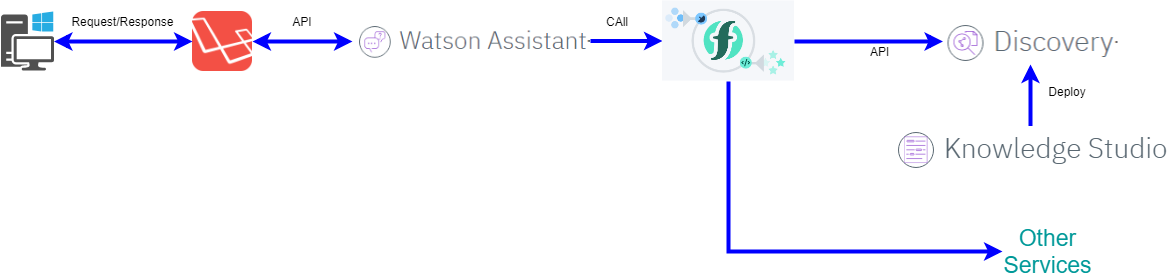
もし、DiscoveryをBotの機能の一部として使うのであれば下記の様にWatson Assistantをやり取りのフロントにして
何らかの情報検索を指示された時にはIBM Cloud Functionsを経由してDiscoveryを呼び出すのが面白いな、と感じました。
ユーザーとのI/Fには上記のWeb検索だけではなくSpeech To Textを経由したりすると自分専用のホームスピーカーっぽい物が実現できそうな気がします。
【参考記事】
Watson Discovery Serviceが日本語対応したので、触ってみた【何、それ?】編
Watson Knowledge Studio(WKS)のアノテーション作業手順