##はじめに
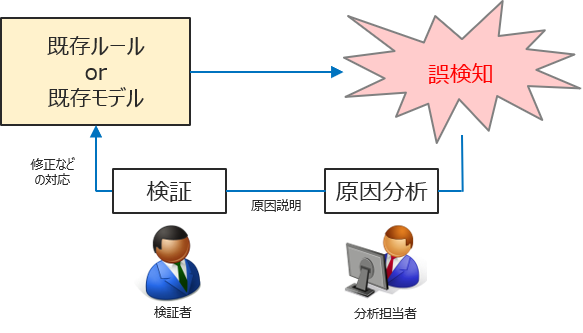
異常検知モデルの効率的な運用において、モデルが見落とした異常を調査し、次回見落とさないようにするためのモデル改善方法について検証者に分かりやすく説明すること(※)は非常に重要です。今回は、モデルが見落とした複雑な異常の原因を統計解析でどこまで追うことができるかを検証します。
※ 検証者への説明
■ 分析環境
Python 3.7.12
pandas 1.3.4
lightgbm 3.2.1 (version >= 3 が必要)
scikit-learn 1.0.1
plotly 5.3.1
##複雑な異常の定義
今回は「複雑な異常」を「異常レコードを含んだテーブルデータを入力とした時、LightGBMがテスト時に見過ごしてしまう異常レコード」と定義します(※)。
※これは、以下の2つの検証観点を意図したものです。
① LightGBM(決定木)モデルの内部で生成する詳細な分岐ルールに対し、統計分析がどこまで有効か
② LightGBMでは、どのような異常が見過ごされてしまうのか
##統計解析の手法
今回の検証で用いる統計解析の手法を以下に示します(この記事内でご紹介するものは、有効な分析結果となった一部です。手法は[1]などを参考にしました)。
■ 今回の分析で試した手法一覧
括弧内はpandas、matplotlib.pyplot、plotlyで使用するメソッド`
- 数行の表示(head, tail)
- 特徴量データタイプの確認(info)
- カラムの値を確認する(unique, value_counts)
- 外れ値の確認、統計量の実数値確認(describe)
- ヒストグラム(hist)
- 散布図(scatter_matrix)
- 有意差の検定:U検定
- 欠損値対応
- 相関確認
- その他可視化手法(parallel plot[2])
##検証データ
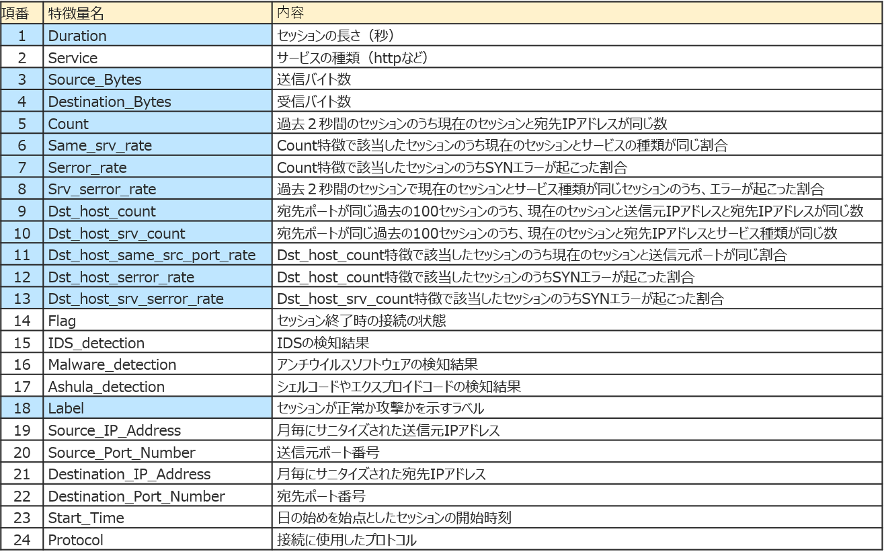
今回検証に使用するのは、Kyoto 2016 Dataset[3,4]です。これはネットワーク侵入検知の評価用データセットで、実際のトラフィック(ハニーポットデータ)から作成されているのが特徴です。特徴量数はラベル類含め24でレコード数は一か月ごとに数十万レコードです。
今回は、既存研究(以下、既存研究と呼ぶ)[5]を参考に12個の特徴量を選び、2006年11月から2015年12月までの約10年間分のデータのうち、2015年1月データ(381,105レコード)の正常10,000件、異常10,000件の計20,000件を使用します(ランダム抽出、正常か異常かはLabelカラムで判断)。
■ Kyoto 2016 Datasetの特徴量一覧(出典:[4])
今回はこのうち青でハイライトした特徴を使用(Labelは目的変数)
##検証モデル
「はじめに」で述べたように、LightGBMを使用します。今回は本題ではないため、ハイパーパラメータを探索することはせず、num_leavesを5、n_estimatorsを1000と設定し、シンプルな二値分類タスク(0、1で1が異常)としています。サンプルコードは以下です。
# import文
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import train_test_split
# 列名設定
cols_name = [
'Duration', 'Service', 'Source_Bytes', 'Destination_Bytes',
'Count', 'Same_srv_rate', 'Serror_rate', 'Srv_serror_rate',
'Dst_host_count', 'Dst_host_srv_count', 'Dst_host_same_src_port_rate',
'Dst_host_serror_rate', 'Dst_host_srv_serror_rate', 'Flag', 'IDS_detection',
'Malware_detection', 'Ashula_detection', 'Label', 'Source_IP_Address',
'Source_Port_Number', 'Destination_IP_Address', 'Destination_Port_Number',
'Start_Time', 'Protocol'
]
# Kyoto 2016 Datasetの2015/1データを取得(_pathは201501データのパスを指定)
df = pd.read_table(_path, delimiter='\t', header=None, names=cols_name)
# 使用する12の特徴量を設定
use_cols = ['Duration', 'Source_Bytes', 'Destination_Bytes', 'Count',
'Same_srv_rate', 'Serror_rate', 'Srv_serror_rate', 'Dst_host_count',
'Dst_host_srv_count', 'Dst_host_same_src_port_rate',
'Dst_host_serror_rate', 'Dst_host_srv_serror_rate', 'Label']
df = df[use_cols]
# Labelカラムの01変更
df['Label'] = df['Label'].replace(-1, 0)
df['Label'] = df['Label'].replace(-2, 1)
# 正常10,000件、異常10,000件を抽出
df_0 = df[df['Label'] == 0].sample(10000)
df_1 = df[df['Label'] == 1].sample(10000)
df = pd.concat([df_0, df_1])
df = df.sample(len(df)).reset_index(drop=True)
# 訓練データとテストデータを分割(テストデータの割合は20%)
df_train, df_test = train_test_split(df, test_size=0.2)
# トレーニングデータ、テストデータの準備
X_train = df_train.drop('Label', axis=1)
y_train = pd.DataFrame(df_train['Label'])
X_test = df_test.drop('Label', axis=1)
y_test = pd.DataFrame(df_test['Label'])
# LightGBMモデルとテスト結果格納
clf = lgb.LGBMClassifier(num_leaves=5, n_estimators=1000)
clf.fit(X_train, y_train, eval_metric='auc')
preds_test = clf.predict_proba(X_test)[:, 1]
##LightGBMモデルのテスト結果
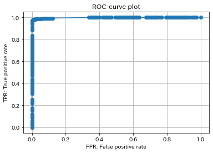
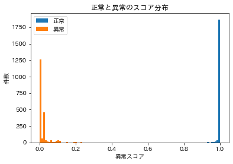
以下に結果を示します(異常判定のスコアの閾値は0.5)。既存研究の結果に近い結果となったためモデルは一旦これで良いとして、次はLightGBMが検知できなかった37件について統計解析を行っていきます。
【モデルのテスト結果】
・実行時間:0.84 sec
・ROC_AUC_score:0.986, recall_score:0.981, presicion_score:0.992
・混同行列:
・ROC_curve
・正常と異常のスコア分布
・異常スコアが0.5未満の分布(今回のターゲット)

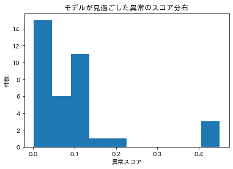
##複雑な異常の分析①
以下に上で述べた手法一覧ごとの分析結果を示します。結論として、10の手法のうち3では複雑な異常の一部について違和感が見られ、特にparallel plotではそのルールを発見することができました(正しいかどうかはさらに検証の必要があります)。簡単な可視化により仮説を立て、より高次元を対象とした可視化やデータ分析によって仮説を検証することは実用的な流れと考えます。
【分析結果】
- 数行の表示(head, tail)
・ 37件のレコード全体に0が多い印象。欠損は見られない- 特徴量データタイプの確認(info)
・ 全体が数値カラム(float64とint64)であり、特に違和感なし- カラムの値を確認する(unique, value_counts)
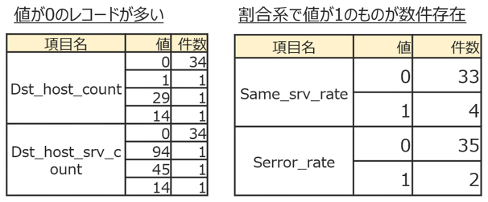
・ 1. で確認した通り、各特徴量で0が多い
・一部割合系の特徴(*_rate特徴量)が1であるレコードが数件あり、異常の特徴である可能性がある- 外れ値の確認、統計量の実数値確認(describe)
・ 特に違和感なし
- ヒストグラム(hist)
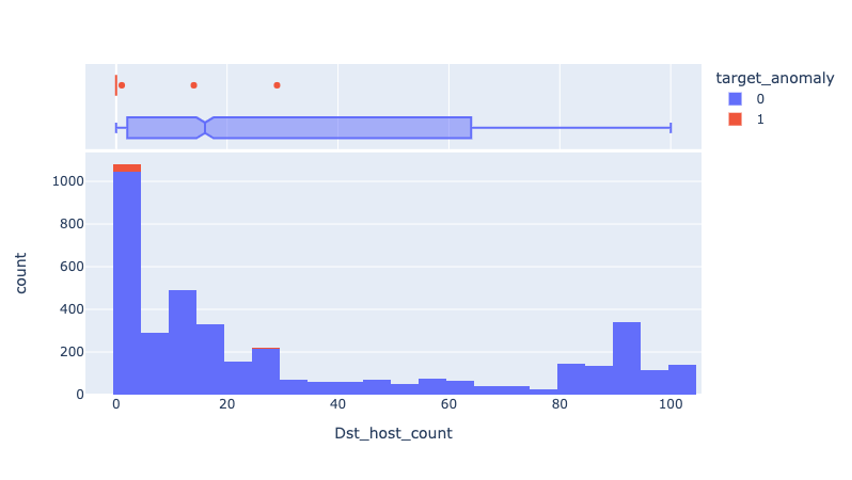
・ 偏りなど特に違和感なし - 散布図(scatter_matrix)
・ 3. で確認した通り、割合系の特徴(*_rate特徴量)が1であるレコードが外れ値的に可視化された
・ 分布の特有の偏りなどは見られず - 有意差の検定:U検定
・ 今回の検証では結論として有意差を確認したいケースは発生しなかった - 欠損値対応
・ 欠損なしのため対応なし - 相関確認
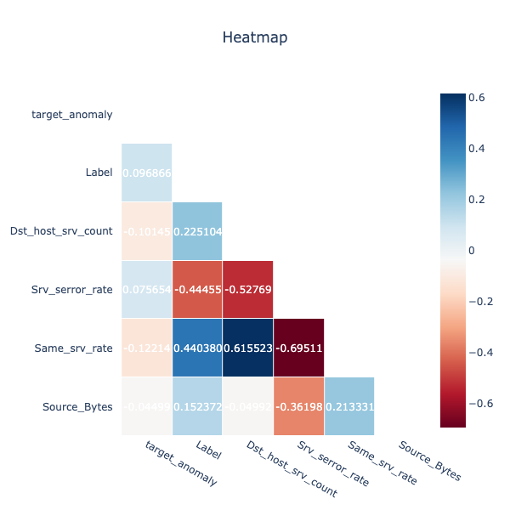
・ 異常ラベルと検証対象の37件の相関はほぼ見られなかった - その他可視化手法(parallel plot)
・ 1.、3.、6.での仮説「割合系の特徴(*_rate特徴量)が1のレコードに異常特徴がある」を検証
→ 異常特徴の抽出、可視化に成功
【分析結果イメージ】
3. 複雑な異常37件のカラムの値を確認:各特徴量で0が多く、割合系の特徴(*_rate特徴量)が1のものが散見
5. ヒストグラム:全体を通して偏りなし(以下は例)
6. 散布図:割合系の特徴(*_rate特徴量)が1であるレコード(黄色の点)が外れ値的に可視化
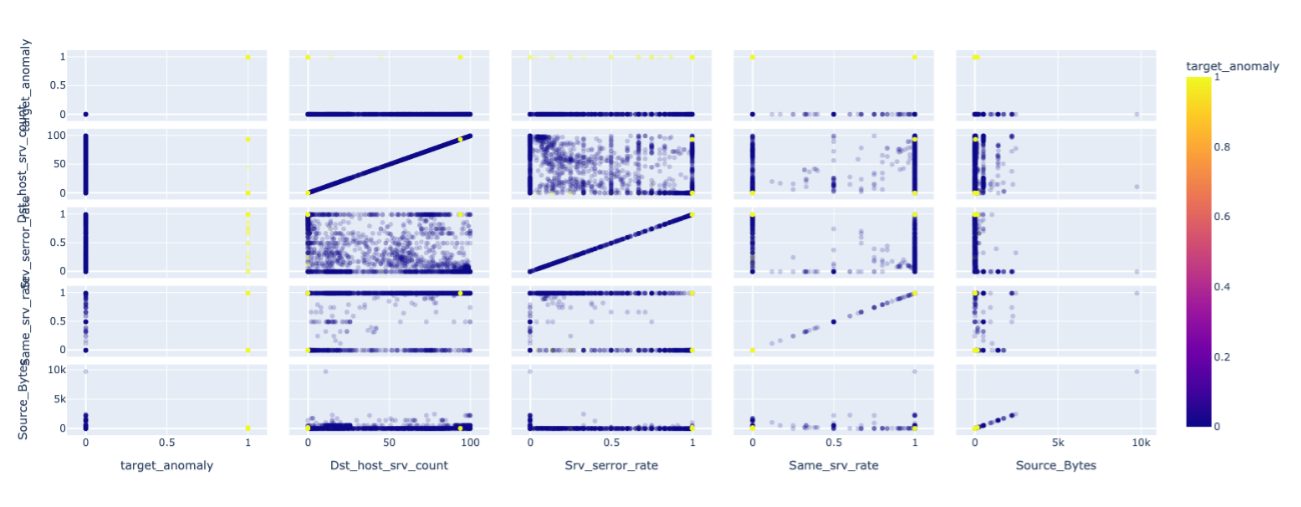
9. 相関確認:target_anomaly(複雑な異常)とLabel(異常)の相関は小さい
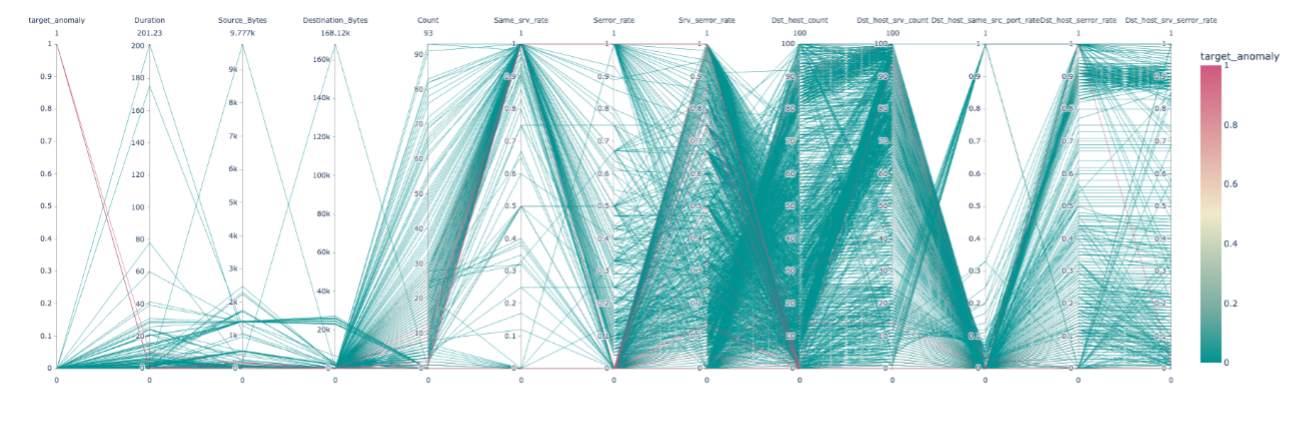
10. その他可視化手法(parallel plot[2])
- 全体(赤い線が複雑な異常、緑がその他のデータ)
- 割合系の特徴(*_rate特徴量)が1であることを含め、9つの特徴量の範囲(ピンクの線部分)を調整することで、一部の複雑な異常のルールを特定(詳細な分析を実施していないためあくまで可能性)
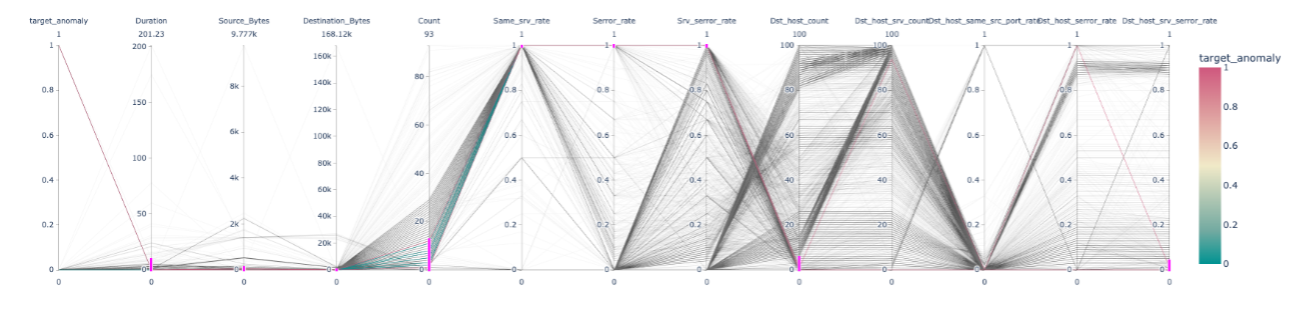
- ルール例:
Duration<10, Source_Bytes<100, Destination_Bytes<1000, Count<13, Same_srv_rate=Serror_rate=Srv_serror_rate=1, Dst_host_count<6, Dst_host_srv_serror_rate<0.06
##複雑な異常の分析②
ここでは、分析①で確認できた複雑な異常のもう一つの傾向である「値が0のレコードが多い」ということについて分析します。20,000件の検証データの内、使用した12個の特徴量すべてが0であるレコードを確認したところ、4,000件以上が該当し、Labelはほとんどが0(正常)でした(※)。また、複雑な異常の内、値がすべて0のレコードは、今回使用しなかったSource_IP_Addressなどの特徴量を見ると、明らかに異常レコードの前例があるIPであることが判明しました。
これらから、値が0のレコードはそれだけで判別可能な特徴にはなり得ないこと、別の有意な特徴量が存在し、それを追加しなければモデルでは判定できないものであった、ということが分かります。
※ 今回は詳しく検証できていませんが、Kyoto 2016 Datasetでは、冗長性や同一特徴量異ラベルデータの存在が指摘[6]されており、それに起因している可能性があります
##何故LightGBMは分析①のルールを発見できなかったか
LightGBMは決定木系のモデルであり、内部で複雑な分岐ルールを構築することが可能です。しかし、分析①で発見したルールには対応できず、複雑な異常の該当レコードの異常スコアは0.001010と低く見積もられていました。
これは、num_leavesを5に設定したことに主な原因があると考えられます。以下のコード(参考:[7])で出力させてみると分かる通り、今回のパラメータ指定では、if文数でいうと4つ程度しか対応していません。従って、9つの特徴量の範囲を指定することが必要であった今回のルールは発見できなかったと考えられます。
ax = lgb.plot_tree(clf, tree_index=0, figsize=(20, 20))
plt.show()
LightGBMで生成した分岐例(n_estimators=1000では、以下のような木を1000個生成)

■ 参考:以下のコードで分岐全体をテーブルで確認できます
clf.booster_.trees_to_dataframe()
■ 本件の仮説をより詳しく検証するには、以下の確認などが必要と考えられます
- 見落とした異常データと同じタイプの異常データは訓練データに含まれていたのか、含まれていたとしたら予測結果はどうなるのか
- num_leavesを大きくしてmax_depthを小さくしても再現するのか
- num_leavesもmax_depthも大きくすると検知できるのか
##まとめ
今回の検証を通して、LightGBMやルールベースなどの既存の検知システムが見過ごした異常を統計分析することで、少なくとも以下のアクションに繋げられることが分かりました。
- 既存のシステムよりも一段深いところを確認することで新しいルールを発見・対応
→ 今回の例では、LightGBMのハイパーパラメータの調整、発見ルールの追加などの対応 - 「現在の入力データでは判定が困難であること」を明らかにし、特徴量設計・追加を検討
→ 今回の例では、Source_IP_Addressという追加特徴量の必要性を確認
また、今回は検証者への説明のしやすさということを重視し、統計解析を行いましたが、見過ごした異常に対して他のモデルを用いて検証することで、違った角度から有効な知見が得られる可能性があります。今回の検証は、見過ごした異常に対する分析の一例として、参考にしていただければ幸いです。
改善点やご質問などあれば、コメントいただければ幸いです。
##参考
-
【データサイエンティスト入門編】探索的データ解析(EDA)の基礎操作をPythonを使ってやってみよう
https://www.codexa.net/basic-exploratory-data-analysis-with-python/ -
Parallel Coordinates Plot in Python
https://plotly.com/python/parallel-coordinates-plot/ -
Kyoto 2016 Dataset
Traffic Data from Kyoto University's Honeypots
http://www.takakura.com/Kyoto_data/ -
多田 竜之介,小林 良太郎,嶋田 創,高倉 弘喜,“NIDS評 価用データセット:Kyoto 2016 Dataset の作成”, 情報処 理学会論文誌 Volume 58 巻,No.9,pp1450-1463,(2017)
-
寺戸 綾佑 林田 守広,”勾配ブースティング木を用いた Kyoto 2016 Dataset に対する攻撃検知精度の向上に関 する研究”, 研究報告数理モデル化と問題解決 Volume 2019-MPS-122,No.14,(2019)
-
「Kyoto 2016 Dataset」における冗長性と同一特徴量異ラベルデータに関する報告
齊藤燎, 相川勝, 井上健太郎, 山森一人(宮崎大学, 大学院工学研究科, 工学部, 工学教育研究部)
https://www.jstage.jst.go.jp/article/jceeek/2019/0/2019_368/_pdf -
LightGBMの木の構造を可視化する
https://qiita.com/_jinta/items/d8984e5f5d328bb04304