SparkでExcelファイルを扱うためのライブラリであるspark-excelを紹介します。
ライブラリの概要と利用用途
ExcelファイルをSparkデータフレームとして読み込んだり、また逆に出力したり、さらには既存のExcelファイルの特定の部分にSparkデータフレームのデータを上書きして保存するということもできます。Spark自体がビッグデータを扱うものなので、可視化という意味ではBIツールを使うことがほとんどで、Excelを使うことは多くはないと思いますが、どうしても使わなければいけない場合はこのライブラリを使うことで簡単に実現できます。
以下、Databricks環境を例にとって説明します。
インストール
Mavenからパッケージをクラスターにインストールします。2022年12月現在最新安定版の以下のバージョンを指定します。
com.crealytics:spark-excel_2.12:3.3.1_0.18.5

SparkデータフレームをExcelファイルとして出力する
databricksサンプルデータセットのフライトデータから20行とって、出力用のSparkデータフレームを作成します。
df_output = ( spark
.read
.option( "header","true" )
.csv( "dbfs:/databricks-datasets/flights/departuredelays.csv" )
.limit(20) )
このデータフレームを以下のようにして、save()で指定したファイルパスにExcelファイルを出力します。format()で com.crealytics.spark.excelを指定します。
( df_output.write
.format( "com.crealytics.spark.excel" )
.option( "header", "true" )
.mode( "overwrite" )
.save( xlsx_file_path ) )
フライト情報のExcelファイルができました!

ExcelファイルをSparkデータフレームとして読み込む
上で出力したファイルをSparkデータフレームとして読み込んでみます。読み込みも同様にformat()でcom.crealytics.spark.excelを指定します。
df_input = ( spark.read.format( "com.crealytics.spark.excel" )
.option( "header", "true" )
.option( "dataAddress", "Sheet1" )
.option( "inferSchema", "false" )
.load( xlsx_file_path ) )
display()で中身を確認すると、確かにExcelファイルの中身がSparkデータフレームとして読み込まれていることがわかります。
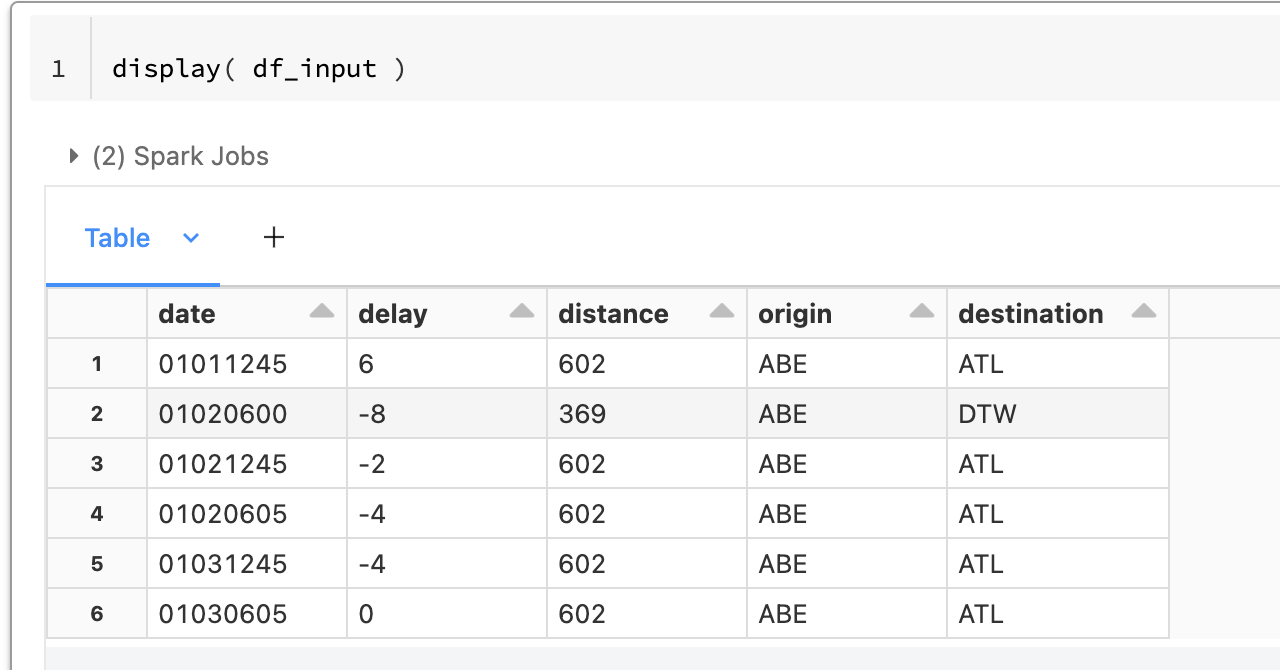
既存のExcelファイルにSparkデータフレームのデータを追加する
既存のExcelファイルの任意のセルに、Sparkデータフレームのデータを追加して上書きするということもできます。
3便のフライト情報(3行x2列)を、シートのD5の位置に挿入してみます。
df_flight = spark.createDataFrame( [["HND","SFO"],["HND","CDG"],["CDG","HND"]] )
( df_flight.write
.format( "com.crealytics.spark.excel" )
.option( "dataAddress", "'Sheet1'!D5" )
.option( "header", "false" )
.mode( "append" )
.save( xlsx_file_path ) )
-
.option( "dataAddress", "'Sheet1'!D5" )で、Sheet1シートのD5セルという位置を指定しています。 - 上書きなので、
mode( "append" )を指定しているのがポイントです。
出力されたExcelを確認すると、確かにデータが追加されていました!
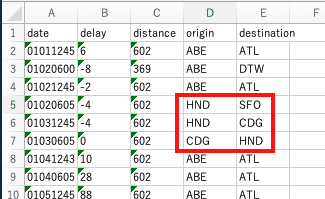
罫線とか背景色とかマクロとか色々盛り込んだExcelファイルを用意しておいて、データだけを差し込むという使い方ができて便利そうです。
最後に
今回使用したノートブックは、Repo機能を使って簡単にDatabricksにクローンして試してみることができます。