はじめに
ChatGPTなどのAIは毎日のように使っているけど・・・
- AIって中で何が起きているの? 気になる!
- ローカルで動かすってどういうこと? 気になる!
- 興味はあるけど難しそう… 気になる!
と思ったことはありませんか?
(思ったことが無い人は、一生チャッピーと一緒にキャッキャしておけばヨシ!)
この記事では、AndroidスマホだけでローカルLLMを動かす環境をほぼワンタップで構築する方法を紹介しようと思います。
マジで右も左も分からない人向けに、用語解説、内部構造の図解、実際に何が動いているか?を、なんとなーく分かりやすく説明してみます。
それでもよくわからない方は・・・ググってくださいw
この記事でできるようになること
お使いのAndroid端末(スマホ or ハンドヘルド)でAIを起動して、ブラウザから会話できるようにします。
[スマホ or ハンドヘルドの内部]
ブラウザを開いて
│
▼
ローカルのAIサーバにアクセスして(llama.cpp)
│
▼
ローカルのAIモデルに回答してもらう(Gemma)
ローカルLLMとは?
普段、皆さんがAIを使うときは下記のような感じだと思います。
[自分] → インターネット → AIのクラウドサーバ → AI
今回は何がどうなるのか? というと
[自分] → 自分のスマホ → AI
AIを「自分の端末で動かす」のがローカルLLMです。
つまりChatGPTみたいなのが自分の端末内で動作するということになります。
はぁ?なんでそんなことすんの?
いや、なんと言いますか・・・
「己の端末でAIが動いてやがるぜ感」 を感じてほしいからです!
ロマンですよ。ロ・マ・ン💫
用語解説
LLMとは
Large Language Modelの略
文章を理解して、文章を生成するAIをLLMと呼んでます。
- ChatGPT
- Geminiとか
普段慣れ親しんでいるAIたちのように、テキストベースな「チャット形式」によって対話することが前提になります。
画像や音声、動画など、テキスト以外の多様なデータ形式(モダリティ)を組み合わせて処理できるLLMも存在しており、それらを「マルチモーダルモデル(Multimodal Model)」と呼びます。
最近では、テキスト専用の「LLM」と区別して、「LMM(Large Multimodal Model)」と呼ぶことも増えています。
llama.cppとは
LLMを軽量に動かすためのプログラムであり、これによってスマホでもAIが動くようになります。
とりあえずこいつがなければ話が始まらないほど重要ナリ。
llama-serverとは
「AIをWebサーバとして起動する機能」のことを意味しており、ネットワークを使ってブラウザからアクセスしてチャット形式で会話することが可能になり、見た目のデザインはChatGPTを利用している感じと同じです。
え?やっぱりネットワーク使うの? と思った方!
はい、インターネットではなくて ネットワークを使います。
スマホが機内モードでも自分の端末だけでAIが利用可能です。
機内モードを解除すれば、同じWIFI環境にいるwindowsやmacosからも、Androidで動作しているAIにアクセスして利用することも可能です。
この辺は後ほど説明していきます。
モデルとは
ダイナマイトボデーのモデルさん。 だったらよかったのにねー。
ここでいうモデルとはAIの「脳みそ」と例えられており、今回使用するモデルは「gemma-3-4b-it-UD-Q6_K_XL.gguf」を利用します。
このモデルはGoogleが開発した最新(2025年前半)の軽量・超高性能モデルであり、このモデルでできること・特徴は下記の通りです。
- 高度な推論と対話
- Googleの最新技術が投入されており、論理的な思考や日常会話、要約などが非常にスムーズである
- プログラミング支援
- サイズの割にコード生成能力が高く、Pythonなどのスクリプト作成やデバッグに強い(らしい)
- 多言語対応
- 日本語の理解力も非常に高く、不自然な言い回しが少ないのが特徴(個人的には満足できる回答が多い印象)
- マルチモーダルモデル
- 最初から画像や音声を理解できるように設計された強力なマルチモーダルモデル
Gemma 3はマルチモーダル?
実はGemma 3は本来、「画像も理解できるAI(マルチモーダル)」です。
ただし今回の環境では、軽量化されたモデル(GGUF)でかつ、llama.cppでの実行という制約があるため、テキスト専用AIとして動作します。
(残念ながらChatGPTのような画像入力はできません・・・無念)
モデルの名前の意味
「gemma-3-4b-it-UD-Q6_K_XL.gguf」という名前を分解しながら説明していきます。
- gemma-3
- 先ほど書いた通り、Googleが開発したモデルの名前
- 4b
- 4Bとは (4 Billion)、約40億個のパラメーター(脳細胞の接点のようなもの)で、8B (8 Billion)ならば約80億個のパラメーターがある
- スマホやハンドヘルド、または少ない容量の8GBメモリ搭載のPCで使う場合、この数字が使い勝手に直結するので、「速さ重視」か「賢さ重視」かを判断する目安になる
| サイズ | 知能のイメージ | 動作スピード | メモリ(RAM/VRAM)消費 |
|---|---|---|---|
| 1B 〜 3B | 簡単な要約や翻訳が得意 | 爆速 | 2〜3GB(超軽量) |
| 4B 〜 9B | 論理的で日常会話もいい感じ | 快適(推奨) | 4〜7GB(8GB環境に最適) |
| 12B 〜 14B | より深く複雑な思考ができる | 少し重い | 8GBだとギリギリ(工夫が必要) |
| 70B以上 | ChatGPT(GPT-4)に近い | 激重 | 40GB以上(一般PCではマジで無理) |
- it
- Instruction Tuned(指示学習済み) の略で、大きく分けて2つの段階があり、用途によって使い分ける
- Base(ベース)モデル
- 役割: ひたすら大量のテキストを読み込み、「次に来る単語」を予想する訓練だけをした状態
- 挙動: 質問に答えるのではなく、「文章の続き」を書こうとします
- 例:「富士山の高さは?」と聞くと、「エベレストの高さは?」「筑波山の高さは?」と問題集の続きのように書き続けてしまうことがあります
- it(インストラクション)モデル
- 役割: Baseモデルに対して、「人間との対話(チャット)」や「指示に従うこと」を追加で学習させた状態
- 挙動: ユーザーの質問を理解し、「回答」を返してくれます
- 例:「富士山の高さは?」と聞くと、「3,776メートルです」と答えてくれます
- Base(ベース)モデル
- Instruction Tuned(指示学習済み) の略で、大きく分けて2つの段階があり、用途によって使い分ける
- UD (Unsloth Dynamic)
- Unslothという高速化技術を用いて最適化されていること
- Q6
- モデルの重み(パラメーター)を何ビットで表現するかをQで表し、数字が小さいほど軽量ですが、頭脳(精度)は少し低下します
- 通常、4ビット(Q4)が標準ですが、Q6はほぼ無劣化に近い賢さを保つと言われている
- 4BモデルをQ6で動かすと、メモリ消費は約4GB〜5GB程度に収まるため、端末が 8GB VRAM(または普通のRAM)環境では「最高性能」を引き出せるベストな選択だと考える
- K
- K-Quants(手法)の意味で、llama.cpp で採用されている「K-Quants」という効率的な量子化アルゴリズムを使っていることを意味する
- 以前の方式(無印のQ4_0など)よりも、「同じファイルサイズなら、Kが付いている方が賢い」という改良版です
- K-Quants(手法)の意味で、llama.cpp で採用されている「K-Quants」という効率的な量子化アルゴリズムを使っていることを意味する
- XL
- 6ビット量子化の中でも、特に精度を落とさない「特大(Extra Large)」な設定になっている
- GGUF
- (GPT-Generated Unified Format)は、一言で言うと「個人のPCやスマホでAIモデルを動かすために最適化されたファイル形式」で、以前の形式(GGML)の欠点を改善し、2023年後半に登場してからローカルLLM界の世界標準になりました
GGUFが凄い理由とは
- 「量子化」でサイズを激減できる
- 元々16GBあるモデルを、賢さを保ったまま5GB〜8GBに圧縮(量子化)して保存できることにより、8GB VRAMやAndroid環境でも巨大なAIが動くようになる
- 「1つのファイル」にすべて入っている
- 他の形式(Safetensorsなど)は、モデル本体の他に設定ファイルや語彙データなどバラバラのファイルが必要ですが、GGUFは1ファイル(.gguf)だけダウンロードすれば動きます。
- CPUとGPUを「いいとこ取り」で使える(オフロード)
- これが最大の特徴で、VRAM(GPUメモリ)が足りない時、「入り切らない分だけをメインメモリ(CPU)に肩代わりさせる」という器用な真似が可能
- 「8GBしかないから動かない」ではなく「8GB分は爆速、残りは低速だけど動く」という柔軟な運用が可能なのは嬉しいゾ!
他の形式との違い
よく比較される「Safetensors」形式との違いは以下の通りです。
| 特徴 | GGUF | Safetensors (標準) |
|---|---|---|
| 主な実行ツール | llama.cpp, Ollama, LM Studio | PyTorch, vLLM, TGI |
| 得意な環境 | 家庭用PC、スマホ、Mac | 高性能サーバー、NVIDIA GPU |
| メモリ管理 | CPUとGPUで分割して動かせる | 基本はGPUメモリに全部載せる |
Android端末や8GB RAM環境でもLLMを楽しめるのは、この GGUF形式がモデルを軽量化し、限られたリソースで動くように設計されているおかげでございます。 ありがたや〜!
閑話休題 Androidで行うこと
① Termux準備
② llama.cppダウンロード
③ ビルド
④ モデルダウンロード
⑤ サーバ起動
⑥ URL表示
「1. Termux準備」以外は全自動でやってくれるようにしました。
簡単ダヨ!
内部の流れ
インストールスクリプト実行
▼
apt install
▼
git clone
▼
cmake build
▼
モデルDL
▼
server起動
▼
ブラウザ接続
ローカルLLMを構築するにあたって、なんとなくAndroidの内部ではこんなことするだよ というのを知って頂きたい。
⚠️ 注意
- 想定しているAndroid端末のスペックは「ストレージ空き容量10GB以上、メモリ12GB以上搭載の機種」
- おそらく8GBメモリの端末でも動作すると思われ(未確認)
- 自分はAYN Thor Pro(12GBメモリ)で動作させています
- AIを動作させている最中は超フルパワーで動作するので発熱あり、バッテリー消費も大きいですので電源を接続しつつ、FAN回転数最大&ハイパフォーマンスモードで利用してくださいませ。
ローカルLLMのインストール方法
① Termuxをインストール
Termux はAndroidデバイス上で Linux環境 を直接実行できるようにする強力なターミナルエミュレーター・アプリです。
通常のAndroidアプリとは異なり、root化(改造)せずに本格的なプログラミングやシステム操作ができる「Androidの中のLinuxマシン」のような存在です。
次にtermux-widgetもインストールしてください。
これはローカルLLMを起動・終了させたりするためのウィジェット(ショートカット)を利用可能にするアプリです。
とりあえずインストールしてもらい、設定は最後の方で行います。
これらのアプリを使って、ローカルLLMが動作する環境を構築していきます。
全自動でね!💫
② ワンタップセットアップ
bash <(curl -fsSL https://raw.githubusercontent.com/game-de-it/easy-local-llm/main/easy-llm.sh)
Termuxアプリを開いて、上記の1行を貼り付けてエンターキーを押してください。
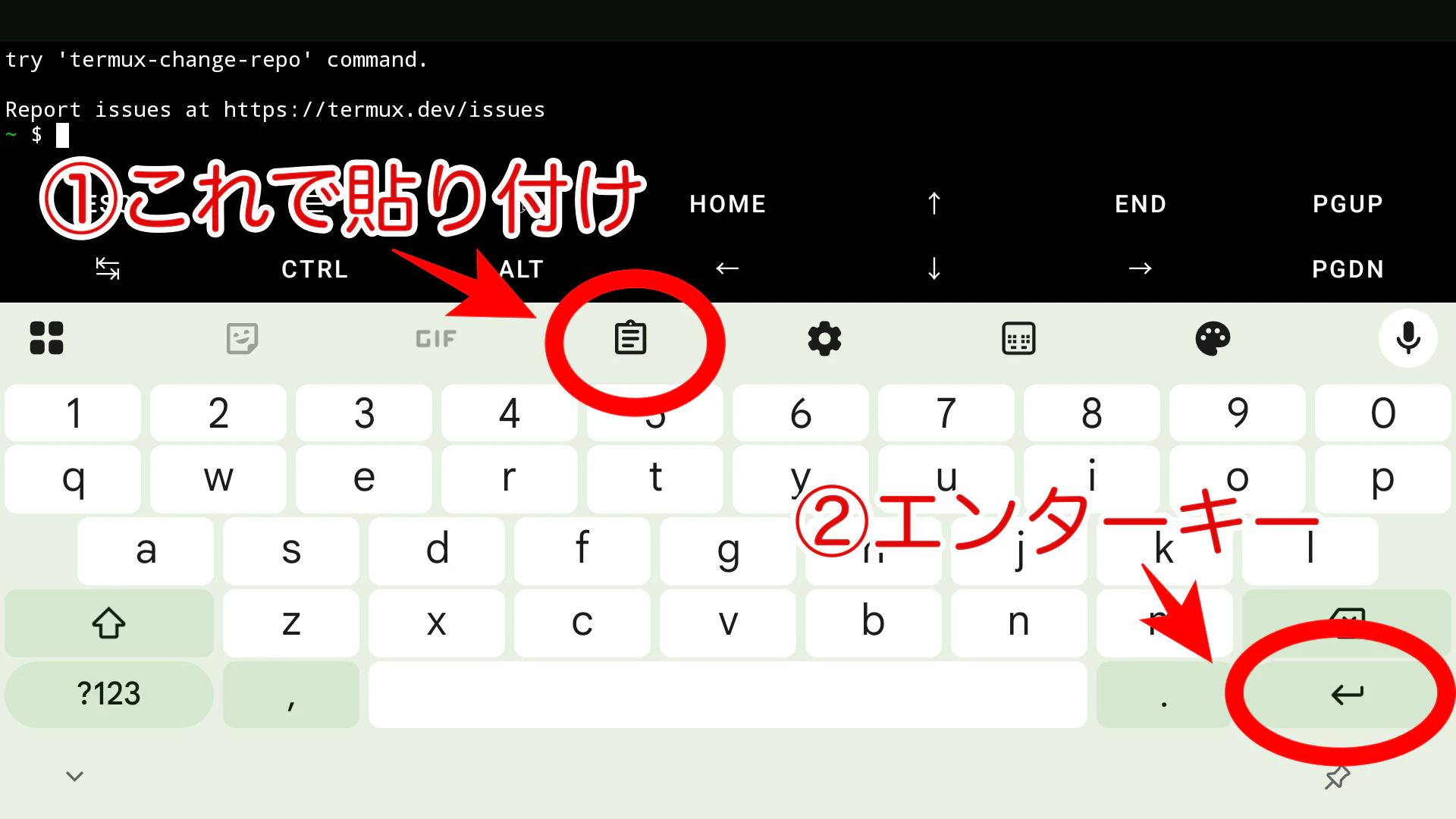
インストールの実行中に
なんちゃら〜[default=N] ?
と表示されたら全てエンターキーを押してください。
あとは全自動でやってくれます。
なんやかんやで5GB以上のファイルをダウンロードしてくるので、WIFI接続した状態でお願いしますね。
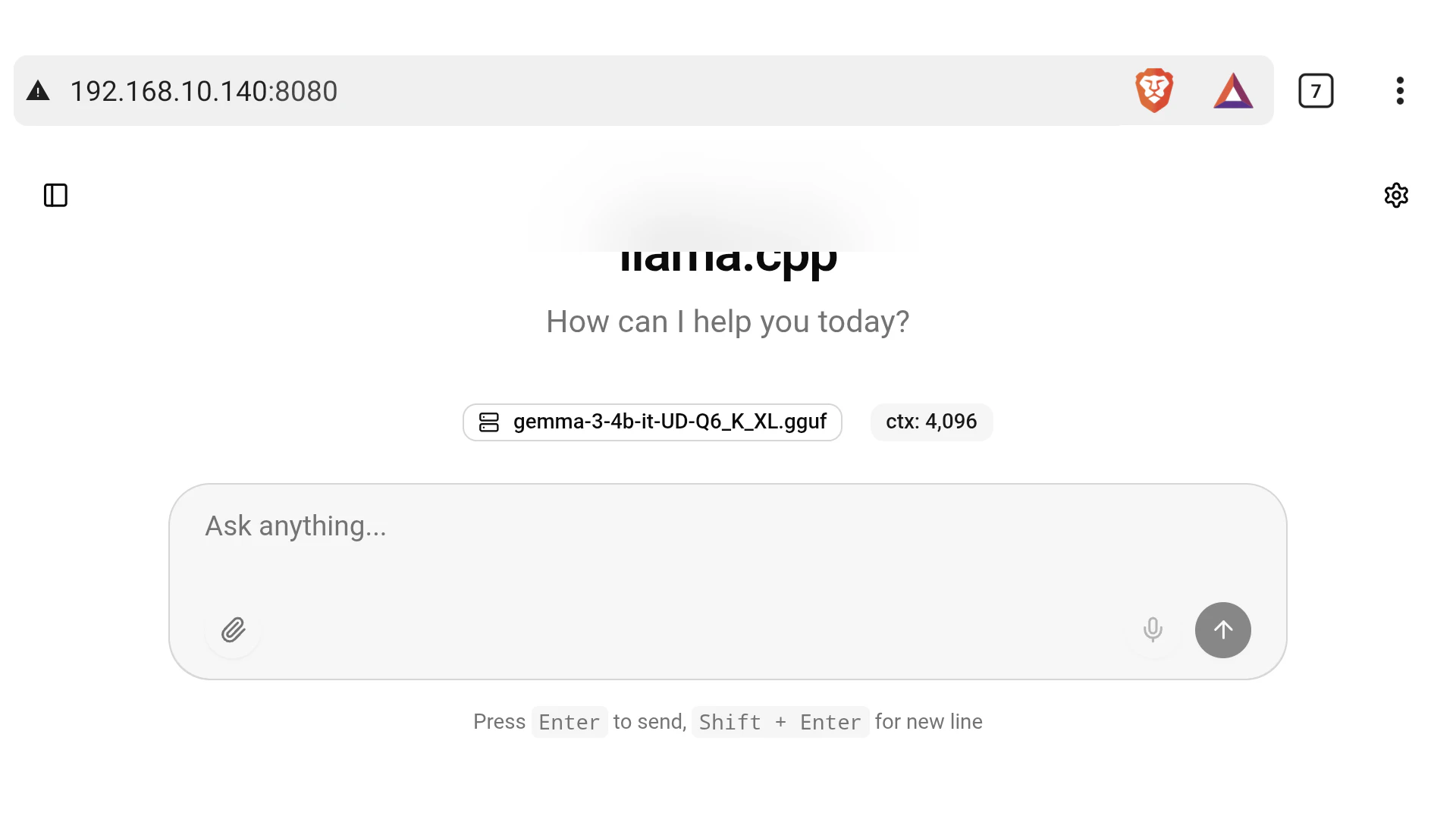
インストールが正常に完了するとデフォルトブラウザが自動的に開き、「llama.cpp」が表示されてローカルLLMを利用可能になります。
termux-widgetの設定
ローカルLLMを起動・終了させたりするためのウィジェット(ショートカット)を利用可能にします。
-
TOP画面の空いている場所を長押しして「ウィジェット」をポイント

-
termux-widgetのウィジェットを長押しして、TOP画面に移動させます

-
TOPのウィジェット画面に「LLM停止」と「LLM起動」が表示されるようになります。

スクリプトの使い方
Termuxで~/easy-llm.sh helpを実行すると使い方が表示されます。
~/easy-llm.sh help
Easy Local LLM
使い方:
/data/data/com.termux/files/home/easy-llm.sh install 初回セットアップ + ビルド + モデルDL + 起動
/data/data/com.termux/files/home/easy-llm.sh start サーバ起動
/data/data/com.termux/files/home/easy-llm.sh stop サーバ停止
/data/data/com.termux/files/home/easy-llm.sh restart サーバ再起動
/data/data/com.termux/files/home/easy-llm.sh status 状態確認
/data/data/com.termux/files/home/easy-llm.sh urls 現在のURL表示
/data/data/com.termux/files/home/easy-llm.sh logs サーバログ表示
/data/data/com.termux/files/home/easy-llm.sh uninstall 環境削除
/data/data/com.termux/files/home/easy-llm.sh help このヘルプ
主な環境変数:
HOST=0.0.0.0
PORT=8080
CTX_SIZE=2048|4096
THREADS=<number>
OPEN_BROWSER=1|0
USE_WAKELOCK=1|0
例:
/data/data/com.termux/files/home/easy-llm.sh install
CTX_SIZE=2048 /data/data/com.termux/files/home/easy-llm.sh start
PORT=9000 /data/data/com.termux/files/home/easy-llm.sh restart
/data/data/com.termux/files/home/easy-llm.sh uninstall
ローカルLLMへのアクセス方法
http://192.168.x.x:8080
Android端末のブラウザで上記のURLにアクセスします。
IPアドレスはAndroid端末に割り当てられているアドレスに置き換えてください。
android端末自身だけではなく、同じネットワーク内にあるwindowsやmacosのブラウザからもアクセスができるはずです。
🔗 easy-local-llmのGitHub
https://github.com/game-de-it/easy-local-llm
シェルスクリプトの詳細はこちらから確認してください。