概要
データ、分析、AIを一つのプラットフォームで提供するDatabricks、それをAzureがマネージドサービスとして提供するAzure Databricksです。
あまりも事例として使われないかもしれませんが、Azure DatabricksでSQL Server ODBCドライバーをインストールする手順についてメモします。

リソース作成
Azureポータル画面からの関連リソース作成は画面が変わる可能性があるため、Azure CLIを使ってリソースを作成することとします。Azureクラウドシェルを使うとすぐ作成できます。シェルモードはPowerShellを使うこととします。
Azureログイン
PowerShellでAzureへログインします。単一のテナントとサブスクリプションをお持ちである場合は、一部省略できますが、下記のコマンドでどのような環境でもログインできます。
Connect-AzAccount -UseDeviceAuthentication -TenantId "テナントID"
Select-AzSubscription -SubscriptionName "サブスクリプション名"
リソースプロバイダー設定
初めてAzure Databricksリソースを作成するとまだ関連リソースプロバイダーが無効の状態である可能性がありますので、有効化します。
az provider register --namespace 'Microsoft.Databricks'
az provider register --namespace 'Microsoft.Compute'
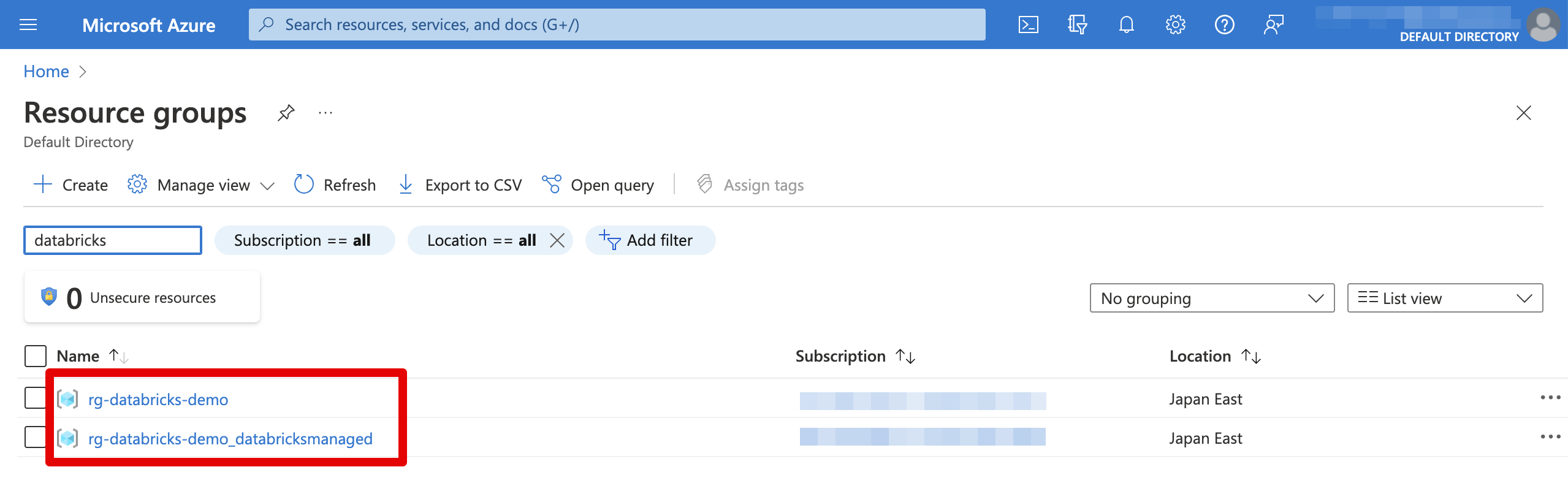
リソースグループ作成
東日本でリソースグループを作成します。
New-AzResourceGroup `
-Name rg-databricks-demo `
-Location japaneast
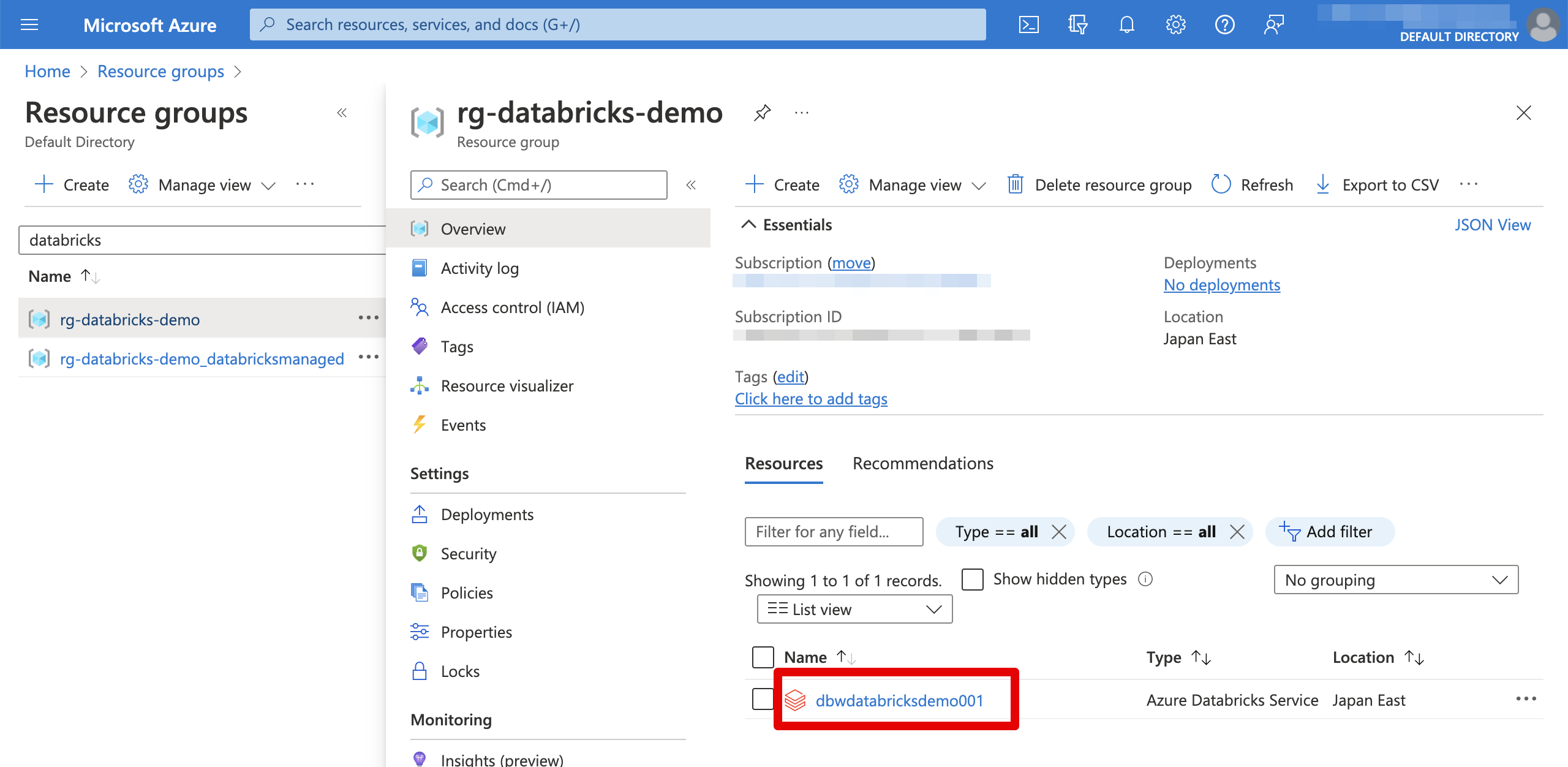
Azure Databricksワークスペース作成
Azure Databricksを作成するにはAzure Databricks Workspaceというリソースで作成します。マネージドで管理されるため、Azure側が管理するリソースグループを追加で指定します。こちらはDatabricks内でクラスターを作成するとマネージドリソースグループ配下で作られます。
プラン(SKU)はStandardとPremiumがあり、こちらのサイトで参考できます。こちらではPremiumで作成することとします。
New-AzDatabricksWorkspace `
-Name dbwdatabricksdemo001 `
-ResourceGroupName rg-databricks-demo `
-Location japaneast `
-ManagedResourceGroupName rg-databricks-demo_databricksmanaged `
-Sku Premium
完成したリソースです。ちなみに私は英語モードになっていますので、ご了承ください。
クラスター作成
Azure Databricksワークスペース画面を開いてクラスターを作成します。ここからはウェブ画面で操作することとします。
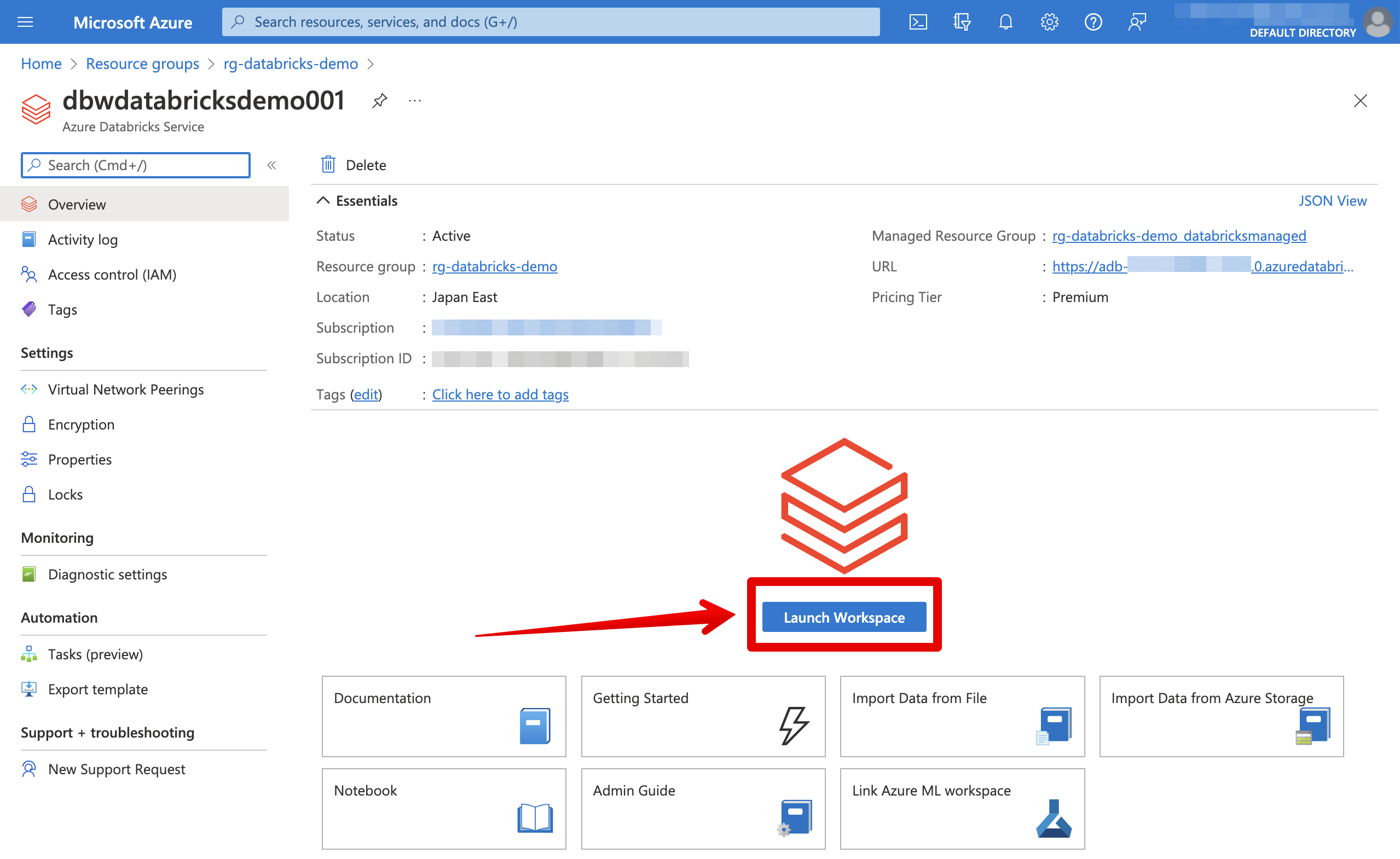
AzureポータルからAzure Databricksワークスペースに繋がると認証が自動で行われるので、下記のようなワークスペース画面が開かれます。最初接続はパーソナライズ設定画面が現れますが、適当に選択してください。

Computeメニューを選択します。

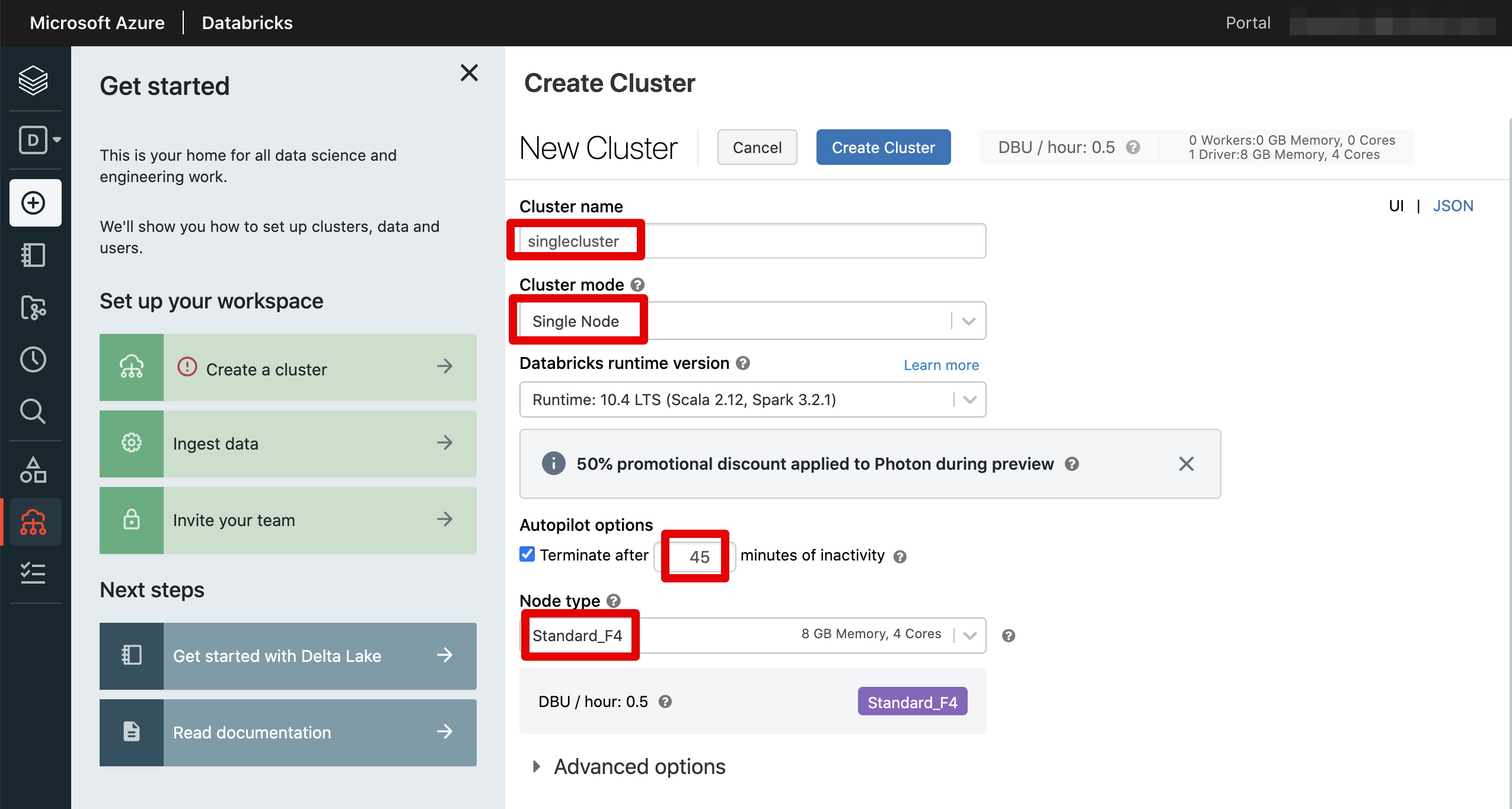
Create Clusterをクリックします。

クラスターの設定情報を入力します。特に重い処理をすることはないため、クラスターモードはシングルノードとし、ノードタイプも一番安いStandard_F4としました。そして45分使わないと自動解放するように設定しました。他にはデフォルトのままです。
作られるまで待ちます。
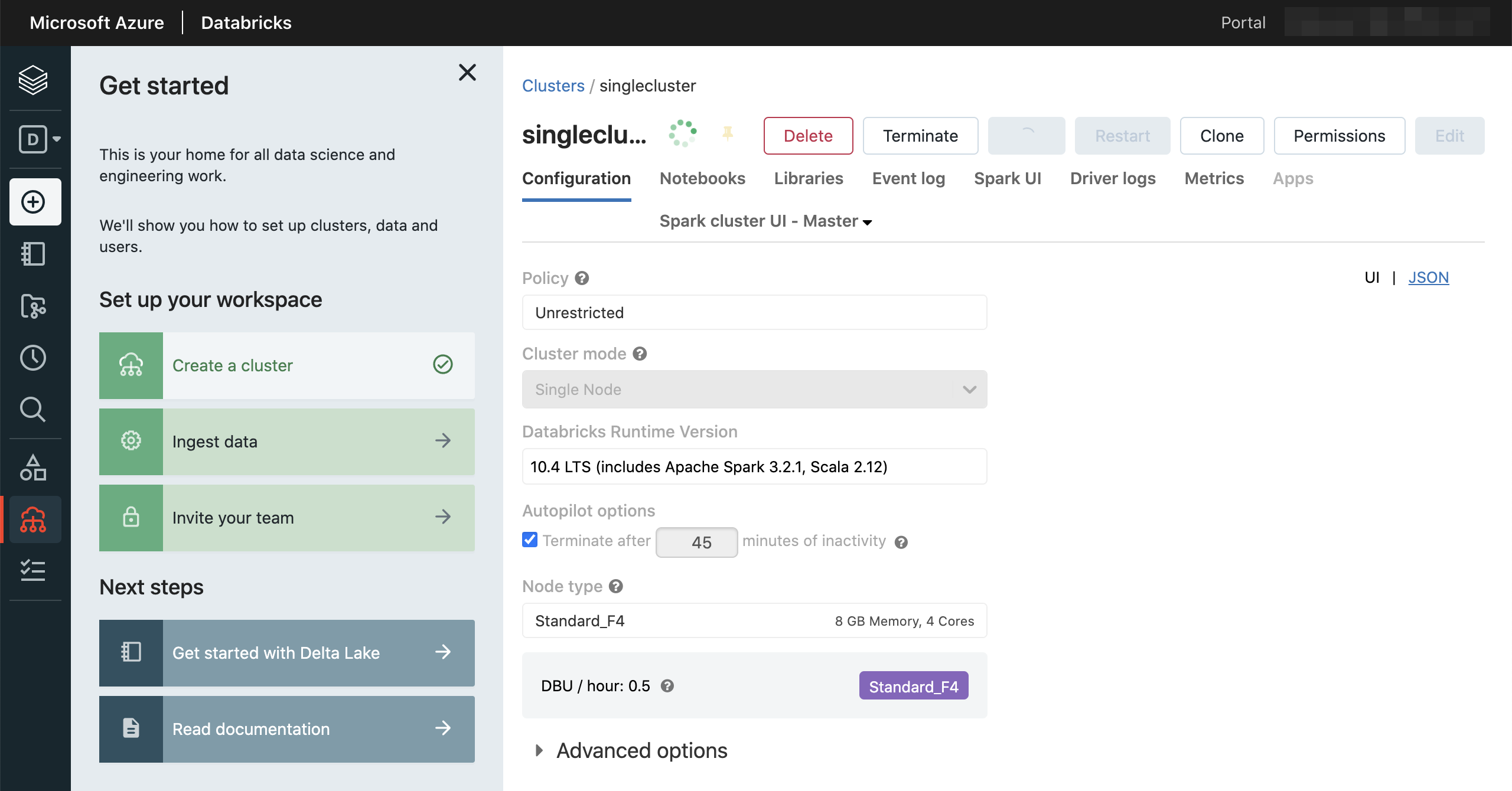
作られたら停止状態となるため、起動します。
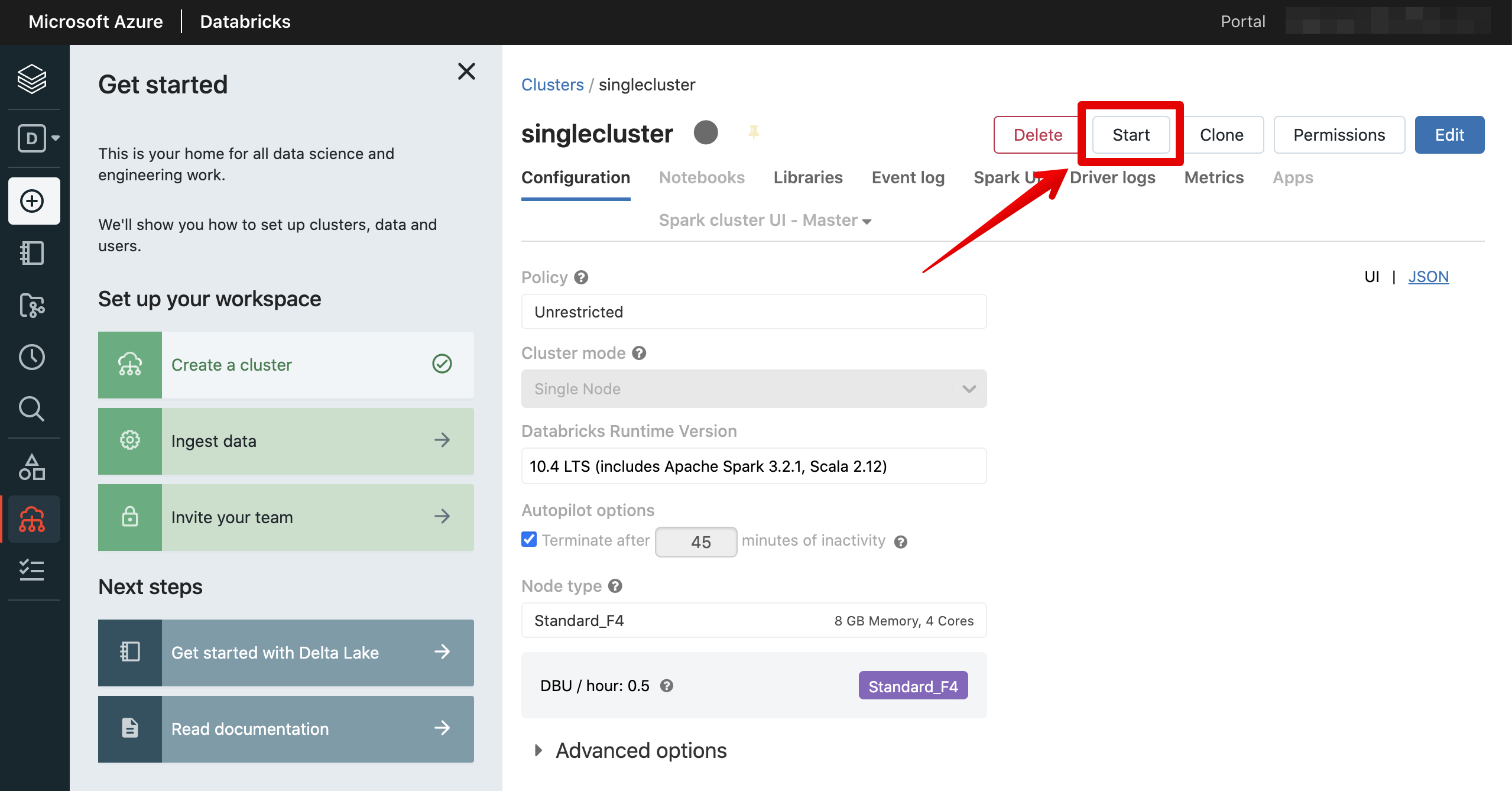
起動できました。

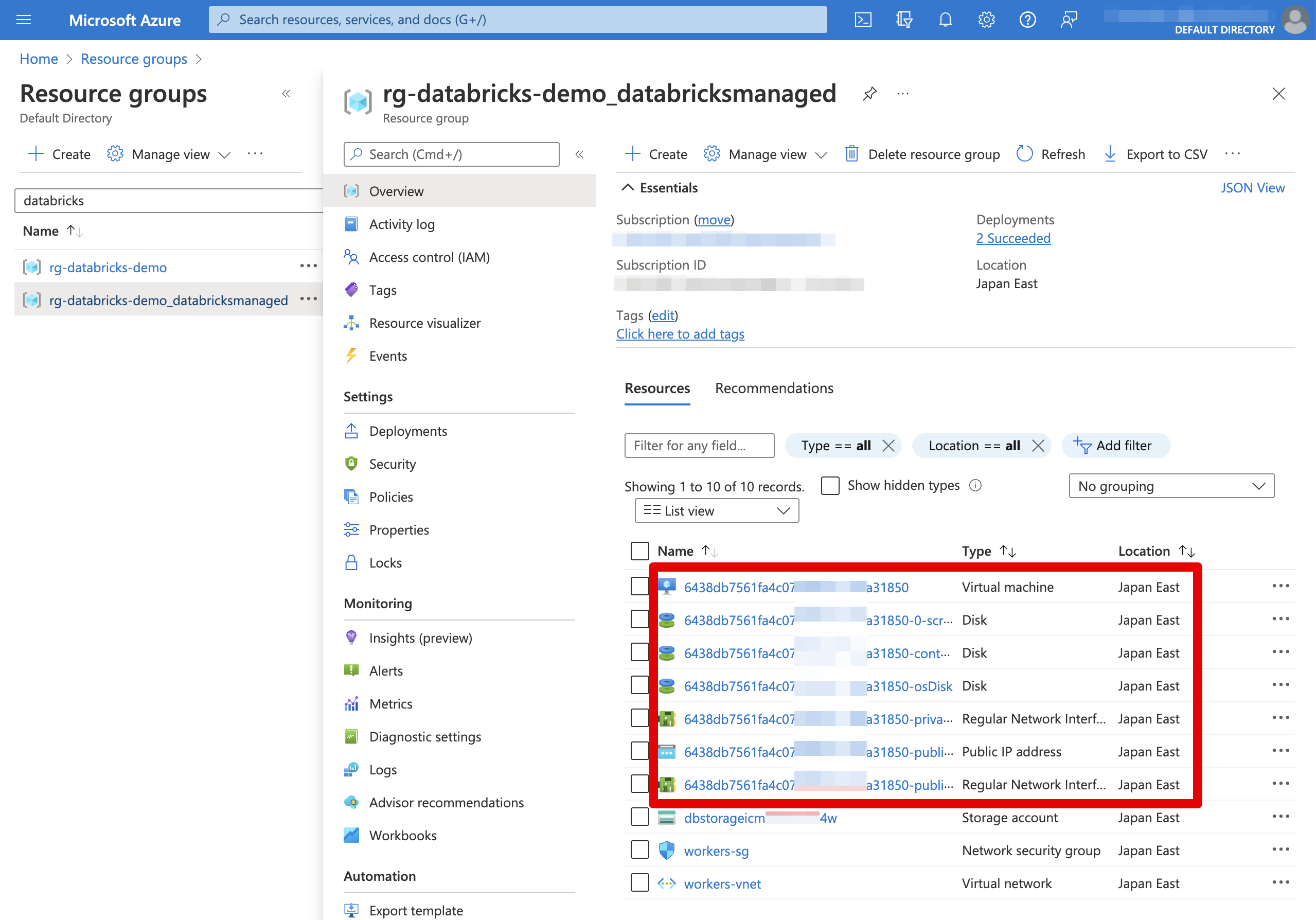
起動されたら、マネージドリソースグループ配下を見るとクラスター関連リソースが作られていることも確認できます。
DBFSへ起動スクリプトファイル追加
Databricksファイルシステム(DBFS)は、Databricksワークスペースにマウントされる分散ファイルシステムです。クラスターで利用することができてクラスターが終了してもDBFSに格納されているファイルはそのまま保存されます。
詳しい内容はデータブリックス・ジャパン株式会社さんで投稿されるQiita記事をご参考ください。
SQL Server ODBCドライバーをインストールする起動スクリプトファイルはDBFSへ作成して格納するため、ノートブックを作成します。


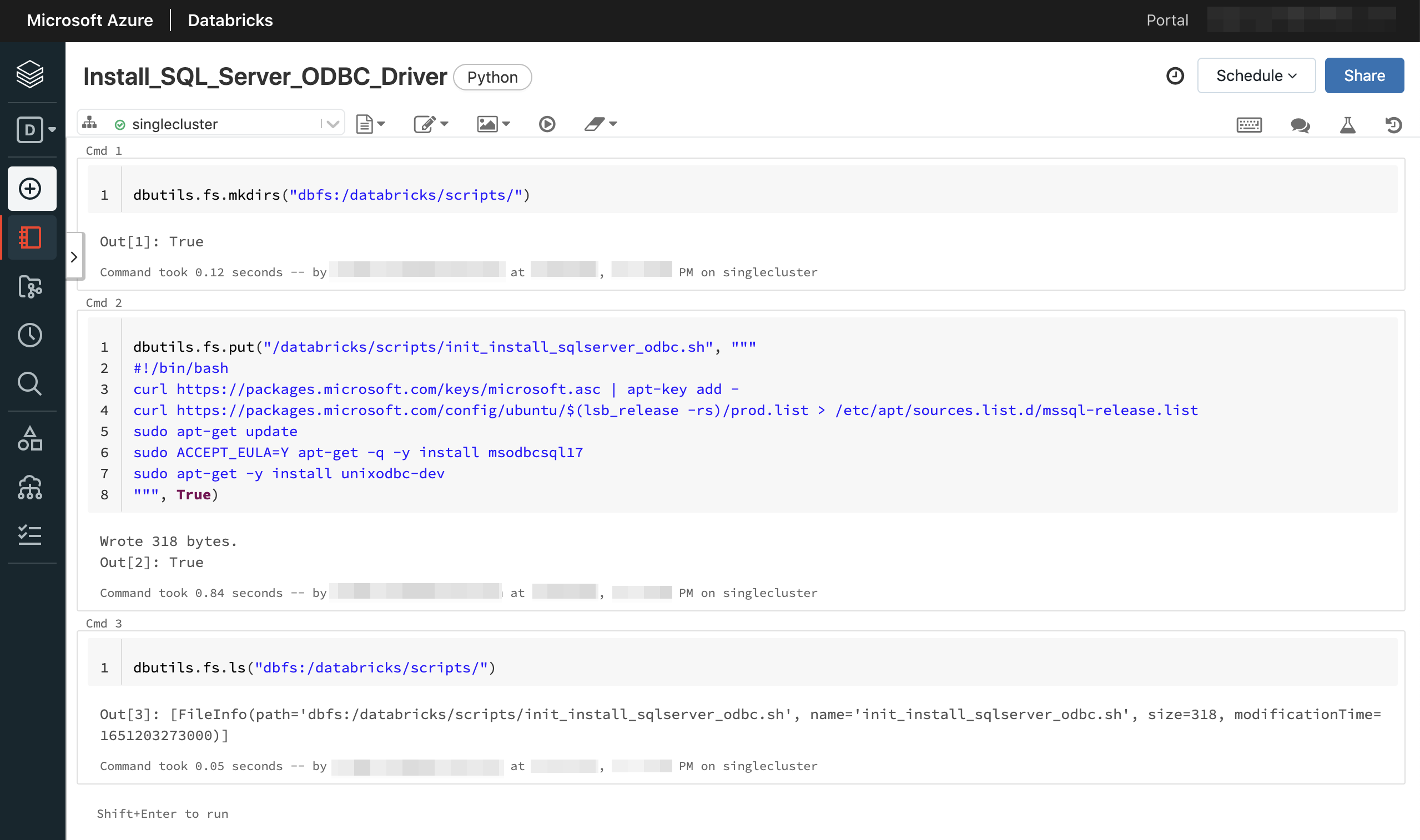
スクリプト内容を以下となります。SQL Server ODBCドライバーと関連パッケージをインストールする内容となります。最新はバージョン18ですが、こちらではバージョン17を使用します。詳しい内容はこちらのサイトをご参照ください。
dbutils.fs.mkdirs("dbfs:/databricks/scripts/")
dbutils.fs.put("/databricks/scripts/init_install_sqlserver_odbc.sh", """
#!/bin/bash
curl https://packages.microsoft.com/keys/microsoft.asc | apt-key add -
curl https://packages.microsoft.com/config/ubuntu/$(lsb_release -rs)/prod.list > /etc/apt/sources.list.d/mssql-release.list
sudo apt-get update
sudo ACCEPT_EULA=Y apt-get -q -y install msodbcsql17
sudo apt-get -y install unixodbc-dev
""", True)
dbutils.fs.ls("dbfs:/databricks/scripts/")
起動スクリプト設定
Computeメニューに移動します。

起動スクリプトを設定するには終了状態でなければ変更できないため、クラスターを終了します。終了されたらクラスターをクリックして詳細画面に入ります。

編集をクリックします。
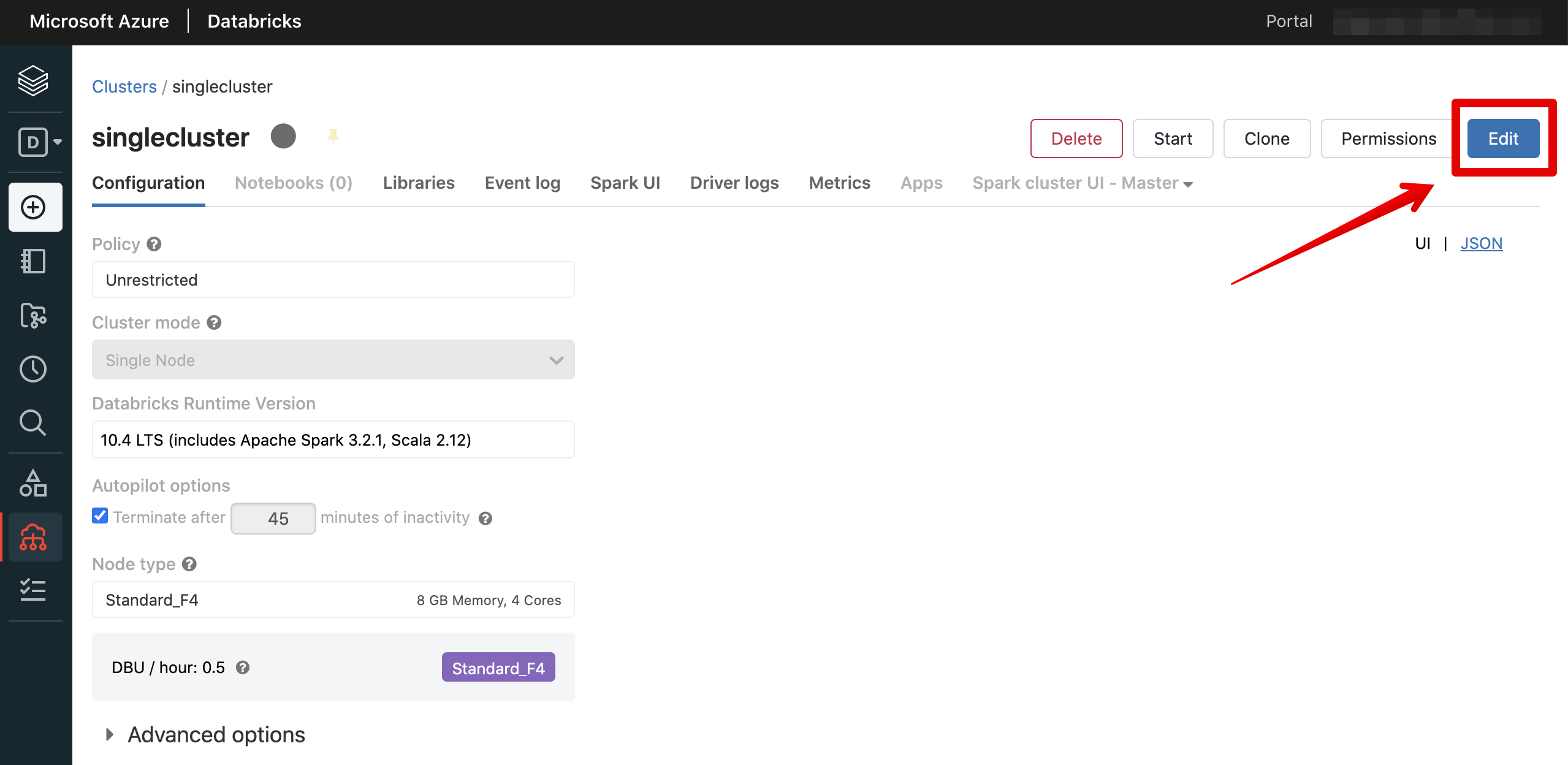
詳細設定を開いてInit Scriptsサブメニューを選択した上で、起動スクリプトの格納先を追加して保存します。

動作確認
クラスターを起動します。設定した起動スクリプトの方で特に不具合など発生しない限り問題なく起動できると思います。

PythonでODBCを使うため、パッケージをインストールします。
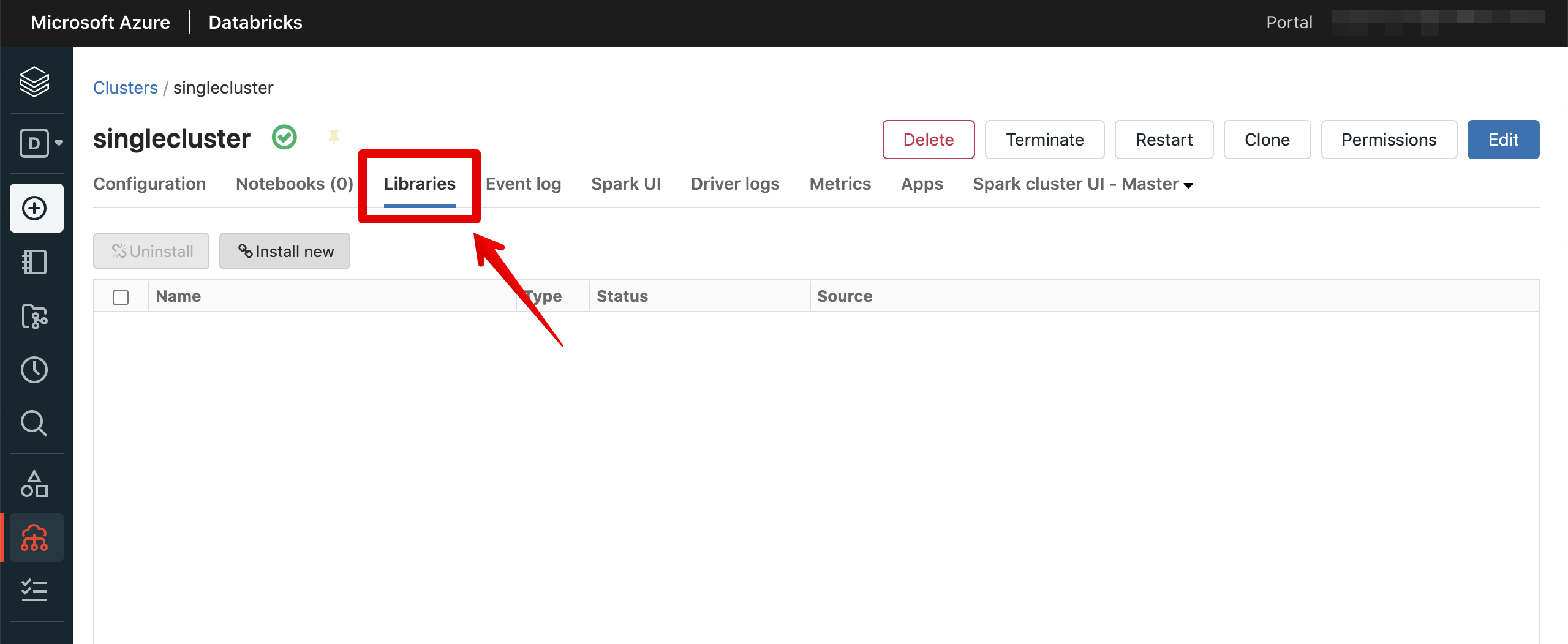
pyodbcを入力した上、インストールします。
インストール完了しました。
SQL ServerのODBCドラバー確認向けのノートブックを作成します。

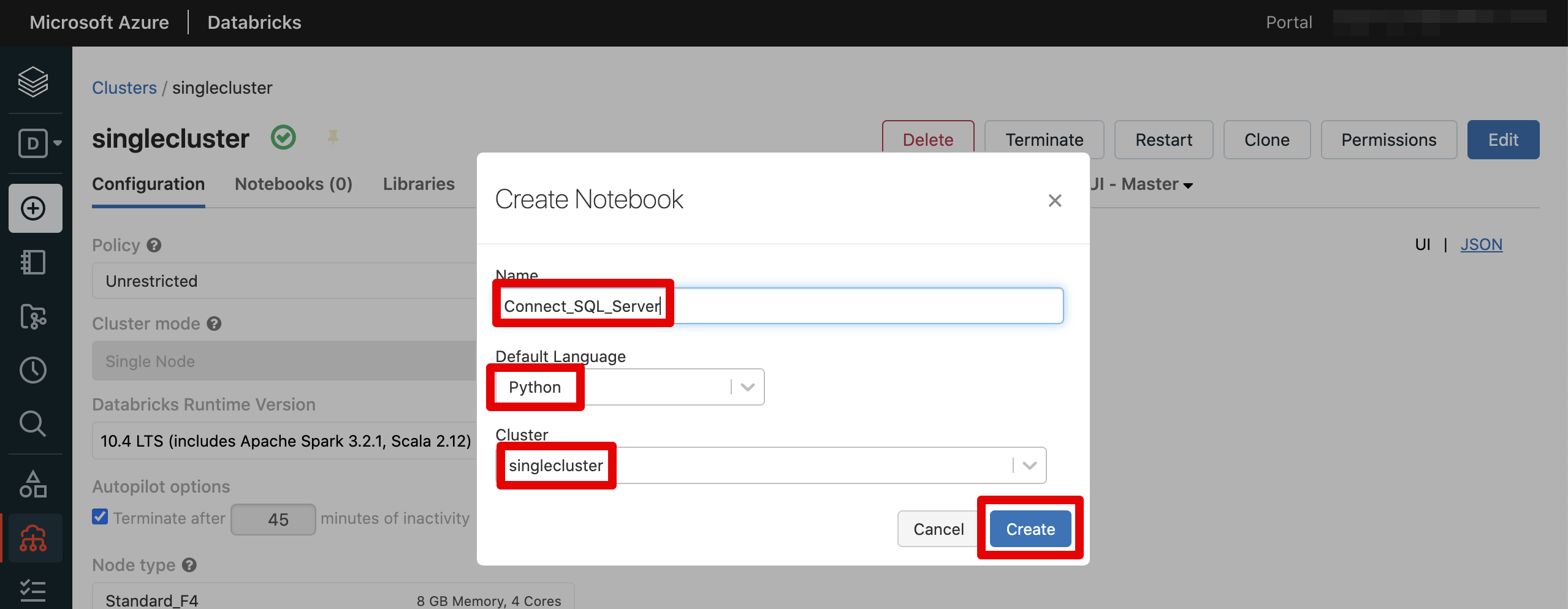
Azure SQL DatabaseまたはSQL Server仮想マシンへ接続確認を行います。
import pyodbc
sql_connect_string="Driver={ODBC Driver 17 for SQL Server};SERVER=tcp:SERVERADDRESS,1433;Database=DATABASE;Uid=USERNAME;Pwd=PASSWORD;Encrypt=yes;TrustServerCertificate=no;ConnectionTimeout=30;"
with pyodbc.connect(sql_connect_string) as conn:
with conn.cursor() as cursor:
cursor.execute(f"SELECT 'Hello World!'")

まとめ
SQL Server ODBCドライバーをインストール手順をご紹介だったですが、他のDBFSへ起動スクリプト設定の方法などご活用できます。
Azure IoT Edge専門で関連内容を投稿していますが、テレメトリーデータを分析するため関連内容も紹介して参りたいと思います。