
(※ 画像はstable diffusionで作成)
なぜこの本を読んだのか?
- 本書の著者の乾先生が出ていたポッドキャスト(a scope)の内容が非常に面白かったからです
読んでみて
- 🧠知覚/運動/👆意思決定/💕感情/🤓好奇心といった人の様々な側面がすべて 推論 をベースとする仕組みでできているという内容は非常に刺激的で面白かったです
- なにより、機械学習関連(特にベイズ推定/強化学習など)を学んだことのある人なら「これ、進研ゼミで見たやつだ!」となる内容が非常に多いです
- 私の場合、頭で理解してたつもりの「ニューラルネットワーク(以降NN)ベースの機械学習が人の脳の仕組みをベースにしている」という事に改めて気づき、素直に腹落ちでき、テンションが爆上がりしました
内容
※まえがきは書籍の試し読みで読めます。本記事の雑なまとめよりもそっちを読んでもらったほうが良いかもです
はじめに
本書では「 自由エネルギー原理 (カール・フリストン)」についていろんな側面から解説します。
書籍のタイトルにあるように、この自由エネルギー原理が大統一理論に該当します。
大統一理理論 とは、物理学における言葉で電磁力、重力といった様々な力を1つの理論で統一して表せられるまだ実現していない 理想的な理論 のことを指します。地図で例えるならば「違う種類の地図(路線マップ/山岳地図/街歩きマップなど)を1つの地図で表現する」ようなものです。不可能ではないかもしれませんが、スマートな形でそれを実現するとなるとそれが非常に難しい課題だという事が容易に想像できるかと思います。それの脳科学版という事で、この自由エネルギー原理の偉業っぷりが伺えます。
で、肝心の理論の中身はというと、
従来の脳科学では知覚、認知、行動といったものは個別の独自の仕組みで構成されているものと考えられてきました。
それが脳科学がほかの分野との連携を深めて研究が進んでいった結果、
「これらの機能って全部NNベースの処理なんじゃね?」という事が見えてきて、
その集大成が自由エネルギー原理というわけです。
🧠知覚の仕組み
脳は「推論」を行っています。
要は脳にはでっかいNNモデルがあるということですね。
入力となるのは体から発せられた各種信号です。いわゆる五感ですね。
- 👀視覚:眼のカメラセンサー(錐体(RGB画像)・桿体(暗所用白黒画像))から得られた2次元画像 × 2枚(左右)
- 👂聴覚:鼓膜から得られた音情報 x 2ch(左右)
- 👅味覚:下から得られた味覚情報(詳しく知りません)
- ✋触覚:体の各部位から得られた接触情報(これには皮膚への刺激だけではなく内臓からの反応(腹痛等)も含まれます)
- 🐽嗅覚:鼻から得られた臭い情報(詳しく知りません)
あと第六感というものがあればそれも入力信号となるのでしょうね。
例えば視覚であれば網膜から入った2次元画像を元に3次元情報を推論しているわけです
脳というコンピューター (内部にAIエンジン搭載)に対して 体の各部位が入出力デバイス として接続されていると考えてもよいかもですね。
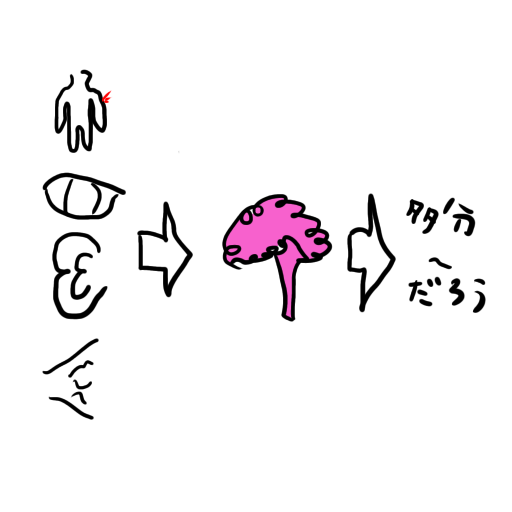
この推論処理がどのようになっているかというと下図のようになっています(ベイズ推定を学んだことがある人ならば既視感があるでしょう)。
まず、人には外環境(もしくは内環境)に対する多分こうだろう考えがあります。これはある意味、信念とも言っていいかと思います。それに対して実際に入力されてきた感覚信号(例えば視覚なら網膜画像)が入ってきます。
この時「○○という入力が入ってきたという事は現状がAである確率は×%、現状がBである確率は◎%、現状がCである確率は。。。。。」といった感じにあり得る現状に対してそれぞれ確率が推論されます。そのうえで最も確率が高いものを選び、さらにその確率がより小さくなるように信念を補正(逆誤差伝搬)するのです。
そして、補正した信念で再推論して。。。というループを回して誤差がなくなるまで推論と信念更新を行ったら人は隠れ状態(外世界(体の外側の世界)or内世界(体の内側、つまり内蔵の状態)の本当の状態)に対して「多分~だろう」という認識を確定するわけです。
これは 事後確率そのもの です「これまでの経験(信念)に対し体験(入力)が発生したときの仮説(予測信号)の確率」(ちなみに事前確率は経験(信念)だけから求めた仮説の確率です)。
最も事後確率が高いものを選択するため、この一連の処理は「最大事後確率推定」と呼ばれます。
これらの信念の更新をもう少し深堀りしてみましょう。
先ほどの感覚信号の知覚処理の中で出てきた予測誤差ですが、これは言い換えると「予測誤差=びっくり度合い」といえるかと思います。
つまり、予測誤差=0ならば(例:日中に空に太陽がある)何も信念を変えることがない、つまり「当たり前の現象😑」となります。
逆に予測誤差が非常に大きければ(例:気づいたら異世界転生していた)、「めちゃくちゃびっくり🤯」となります。
とはいえ、ずっとびっくりし続けるわけではありません。状況を確認し「私は異世界転生したんだ」という知覚認識をして信念を更新する事で、自分が異世界にいることは次第に当たり前のことになっていくのです。
この「びっくり度合い」がヘルムホルツの自由エネルギー(情報理論的にはシャノンサプライズ)となります。
ようやく「自由エネルギー」という用語の回収ですね。
まとめますと、感覚信号を知覚認識するという働きはびっくりすることが少なくなるように世界の認識を更新していく、つまり入力として世界に対する認識(信念)と環境からのセンシング情報(感覚信号)を元に本当の環境の状態(隠れ状態)を推論し、信念からの出力の誤差を補正することによって信念の更新を行うことです。
更新後の信念においては、同じ入力値が入った時に誤差がより少なくなる。これはヘルムホルツの自由エネルギー(情報理論的にはシャノンサプライズ)を最小化(エンドロビー増大化)する働きとみなせます。
もう少し砕けた言い方をすると一番それっぽい理由付けを行うということですね。
[参考資料] ベイズ推定を人の信念の更新として分かりやすく説明した書籍には下記の本があります
(最初の章を読むだけでもかなり理解が深まります)
あと、動画だとこのシリーズでしっかり学べます
😶注意の仕組み
前章では信念の更新について述べられてきましたが、更新できるのは信念だけではありません。
入力となるセンシング情報の精度(感度)を変更することが可能です。
有名な例としてカクテルパーティー効果というのがありますが、これは注目する人に関する感覚信号の重みを大きくして知覚しやすくしていると言えます。
この感度調整は脳が意識的に行います。そのためこのような推論を能動的推論と呼びます。
本章が注意の仕組みとなっているのは「重みを大きくして感度を上げる=注意を向ける」という意味だからです。注意は意識的に行います。
🏃♂️運動の仕組み
運動も感覚です。推論行為であることには変わりありません。
運動は脳からの信号に従って筋繊維を収縮させる行為という事はご存じかと思います。
運動の仕組みは下図のようになっています。
筋肉から現在の状態が送られてくるのは近くの時の感覚信号と同じです。
また脳からは「体を~の状態にしたい」という要求が送られてきます。
この筋肉及び脳からの信号を処理するのが脊髄αニューロンです。
脊髄αニューロンではこれら2入力に対して誤差を計算して誤差分だけ筋繊維に動くよう指示します。
例えば腕を伸ばすという命令が脳から出たとします。
筋肉からその時の手の筋肉の状態(曲がっている等)が渡されてきます。
αニューロンではその2つの信号の誤差を算出し、筋繊維に「〇〇だけ伸びろ(or縮め)」という命令を出します。
すでに腕がまっすぐに近い状態であれば、誤差が小さくなり筋繊維への伸縮命令の量は小さめになるでしょうし、
逆に腕が曲がっていれば、誤差が大きくなり筋繊維への伸縮命令の量は大きくなるでしょう。
計測値と予測値(期待値)との誤差を求めるという点で知覚と運動は同じですが、違いもあります。
知覚では誤差を基に信念の更新を行っていましたが、運動では信念の更新は行いません。
つまり、脳へのフィードバックがないのです。
フィードバックがないのは運動時には脳からの期待値が、頻繁に更新されてしまうとちゃんと運動が行えない恐れがあるためです。
例えるなら現場の状況が激しく変わるような職場において、現場を分かっていない上司が上からあれこれ言ってきてメテオフォール化してしまうといった感じでしょうか。
そんなわけで、運動の推論は半自動モードになっているのです。
👆意思決定の仕組み
続いては意思決定の仕組みを扱います。
大統一理論なので意思決定も推論ベースの処理という事は変わらないのです。
仕組みとしては強化学習そのものといった感じです。
意思決定は目標指標行動です。
目指すべき状態があり、それに近づくために現在の状態を推定と状態間の遷移条件を予測し、次にとるべき行動をポリシー(方策/行為系列) に従って決定していきます(強化学習そのものですね)。
脳内でシミュレーション(仮想制御ユニット)を行い、最も成果の不確実性を低下させる行動を選択していきます。
人が取る行動は2種類に大別できます。
「探索行動 : 不確実性を低減するように=エントロピー最大になるようにする行動」
「利用行動 : 得られた知見をもとに利益を最大化するにする行動」
探索行動の一般的な流れは以下の通りです。
最初は不確実性が高いためまず探索行動を行い状況を把握し不確実性を低減させます。
その後、不確実性が低減したらその情報をもとに利用行動を行います。
そしてまた状況が変わったらまた探索行動を行います。。。
そうやって目的の状態に近づこうとするのです。
昔「🐁🧀チーズはどこに消えた」という本が流行りましたが、あの本はこれら2つの行動の話ですね。
小人とネズミが出てきて、ネズミはひたすら探索行動を実行(=毎日チーズを探し続ける)
小人は最初は探索行動を行うものの一度チーズを見つけるとその場所に引っ越してチーズの利益を最大化することを選択、つまり利用行動に移行しました。
ある日チーズが消えた際、ネズミは普段と同じように探索的にチーズを探すことですぐに次のチーズを見つけられました。
一方の人は過去のチーズに固執しすぐには探索行動に移れなかったという話でしたね。
探索行動の重要さを強調した本でした。
それぞれの行動のどちらが完全に良い/悪いという事ではなく、
- 変化が無い状況では利用行動が優位
- 変化が多い状況では探索行動が優位
という事だと思います。
とはいえ、情報爆発が加速し続けるこの時代、探索行動の方が重要な状況はしばらく変わりそうにありません。
それを表しているのがこの20年間のアジャイルブームだと思います。
アジャイルとは言い換えれば「変化に対応するための価値観」です。
細かいイテレーションで随時方向修正し価値を最大化する姿勢は探索行動そのものです。
💕感情の仕組み
「内臓にも感情がある」
感情は内環境(内臓の状態)に大きく影響を受けています。
ちなみにこの本では以下の2つを区別しています
「情動 : 外刺激等に起因する内臓の状態変化」
「感情 : 情動を受けて脳が行う主観的な意識体験」
自律神経の重要な2つの働きを確認しましょう。
「ホメオスタシス:内環境(体温など)を一定に維持する機構(自律神経)自律神経には内臓から脳に信号を送る系とのうからない」
「アロスタシス:ホメオスタシスのバランスが崩れそうなときに事前に自律神経の設定を変更する機構(例:大きなプレゼンの前に脈拍が上がる等)
注意の仕組みの章でシナプスの感度を変えるという機構の話をしましたが、それの自律神経版がアロスタシスといったところでしょうか。
内臓状態の認識(おなかが痛いなど)といった内臓の感覚も脳による推論で把握されます。
これが感情を作る基盤となっています。
人の感情は基本6種類です(🤬怒り、🥶恐れ、😭悲しみ、😊幸福、😮驚き、😒嫌悪)
感情は「情動」と「情動を作る基となった内臓の隠れ状態に対する推論結果」の2つを基に生成されます。
つまり、「情動≠感情」という事です。
また、感情は推論結果でもあるので、推論の仕方を変えれば感情も変えることができます
この情動に流されず、好ましい感情に自分をコントロールするという考え方は以下のような自己啓発メソッドで使われていますね。
- 「仏教(とくに原始仏教・禅など):座禅をしているときは色んな気持ち(情動)が沸き起こってきます(例:仕事がうまくいかなかったなぁ/足がしびれた/腰痛い)。それをただ観察し感情をフラットな状態に保ちます。そうする事で、問題を抱えていてもそれに心を惑わされる無く冷静に状況を判断し、改善のための最善の行動を淡々と実行できるというわけです。 参考書籍」
- 「マインドフルネス:詳しく知りませんが、座禅と同じように情動を言語化する事で距離を置きフラットな状態を保つみたいです」
- 「アドラー心理学:同じく詳しく知りませんが、トラウマを否定し自己決定権を大前提に置く考え方と認識しています。情動に惑わされずパフォーマンスを高めて問題に取り組めるという点で禅やマインドフルネスと同じかと思います」
- 「7つの習慣:情動に流されてしまうことを"反応"と呼び、一方で情動に流さず自分の価値観に沿ったベストな感情を選び取っていくことを"主体"と呼び、主体的に生きることの重要性を説いています。例えるならば宝探しの航海をしているとして、反応的に生きるということは、潮の流れに身をまかして宝の島(自分の価値観にとって一番望ましい状態)に着くことを待っているようなものです。主体的に自ら漕ぎ出さないと宝の島に着く可能性は限りなく低いです」
- 「ストア派(古代ギリシャ哲学):理性の力で表象(情動)をに飲み込まれないようコントロールする必要があり、それを完全に成し遂げた状態を"アパテイア"といいそれを成し遂げた人物を"賢者"呼びます(詳しくは下記動画をご覧ください。動画を掲載している哲学チャンネルにはストア派に関する動画がほかにも多数あります。興味を持ったら探してみてください)」
🤓好奇心と🤔洞察の仕組み
ここまで信念(世界の隠れ状態に対する認識)は既知のものとして扱ってきましたが、
この章ではどうやってこの信念を(意識的に)構築していくのかを扱っていきます。
これまで隠れ状態に対する認識を信念といってきましたが、ここでは仮説といったほうが良いかと思います。
なぜならこれらの構築は仮説の立案・検証という作業行為の繰り返しによってなされるからです。
また、ポイントとなるのは「人間は世界に対する不確実性の最小化を目指して仮説を立てる」「仮説をできるだけシンプルにしようとする」という事です。
仮説(信念)は以下の2ステップで作られます。これには行動を伴います。
- 仮説モデルの学習
- 情報を求めて探索(認識的行動)
- ゴールを求めて探求(実利的行動)
- 新規性を求める(新規的行動)
モデルの学習では3.が重要(シャノンサプライズが大きい行動が重要)
- モデルを極力シンプルにする
- モデルを単純しつつ精度を高める事を目指すことでより良いモデルを目指します。そのため、誤差を低減しつつシンプルなモデルを求めることになりますが、実際にはトレードオフ関係にあります(「正確さと複雑さのトレードオフ」)
- シンプル化の働きとしては、例えば睡眠中に重みの低いシナプスの接続を切ってモデルを単純化するという働きがあるとのことです
-やり方は微妙に異なりますがDropoutのようなアプローチですね。おもしろい。
参考資料