タイトルはAIとか書きましたが、まぁ、察してください。お願いします…
エンジニアたるものなにかのオタクであると思いますが、オタクの皆さんは一般人相手につい専門用語で喋って引かれたみたいな経験ありませんか?僕はあります。
そこで、今回は、自分の表現が
"伝わる"表現か?
よりわかりやすい表現とは?
というのを機械学習の力を借りて判定してみよう。という試みでございます。
TL;DR
BERT+CNNヘッドによる意味同値性解析と、教科書コーパスによる単語の難易度判定を組み合わせて、ある文章をやさしく、かつ意味が通るように言い換えられているかを判定するシステムを提案、実装しました。
github https://github.com/MosasoM/Aizen
に多分簡単に試せるソースを置いておいたので試してもらえると面白いと思います。
| 基準文章 | 言い換え文章 | score | 含意確率 | 難易度 |
|---|---|---|---|---|
| 次の会議のために議題を書類に要約しておいてください | 次の会議のためにアジェンダをレジュメにサマリーしといてください | 0.08641 | 0.744 | 9 |
| 次の会議のために議題を書類に要約しておいてください | 次の会議のために話し合うことを紙にまとめておいてください | inf | 0.994 | 0 |
この場合「次の会議のために話し合うことを紙にまとめておいてください」がより適切なやさしい言い換えという判定です。
ともすれば難しい言葉を使いがちな自らのコミュニケーションを見直す機会にしたいというのが一つありますし、改めてこの言葉はどういう意味なんだ?と考えることも大事だと思って作っています。
色んな所がガバガバなのですが、これをたたき台としてもっと良いものを作れれば良いなと考えています。
はじめに
ここ読まなくて良いです。
皆さん多かれ少なかれ専門用語をお仕事等で使用されているかと思います。確かに、専門用語は意味を大きく圧縮しているため、その知識を共有している人同士では非常に便利なものです。
しかし専門用語は、その用語を知らない人にとっては非常に大きな不快感となりうるということは周知の事実であると思います。ところが、専門用語の持つ情報量という魔力に取り憑かれ、相手の理解度合いを認識しないまま(そもそも相手の知識を全て確認しながらすすめるというのは非現実的です)、ついつい専門用語を多分に使ってしまいコミュニケーションに失敗するという経験がある方も多いのでは無いかと思います。
このような現象はむしろ基準語彙数の多い”優秀”と称される人に多いものですが、せっかく優秀な人がこのようなコミュニケーションの失敗によって周囲からの評判を落とすというのは社会全体の損失となりうると考えます。
ここにある文章の容易な言い換えというものの必要性が一つあります。当然この他にも子供に説明するときや、言語初学者に対して教えるときなど文章の容易な言い換えが必要とされる場面は多く考えられます。また、文章をやさしく言い換えようと試みることは、会話の受け手にとってだけでなく、発話者にとってもあるものの定義等を再確認することで思考をより深める事ができるなどのメリットがあると考えられます。
以上のような背景から、本記事ではある文章が、基準とする文章のやさしい言い換えとなっているかを判定し、フィードバックするシステムの構築を目的として行ったことをまとめます。
↑むずかしいことばじゃわかんないよ!かんたんにいいかえて!!!
ということで簡単な言い換えになってるかを判定してフィードバックするシステムを作ります。
プロトタイプなのでガバポイントがいっぱいあります。
気づいてる限りのガバポイントは各章におりたたみで入れておきます。
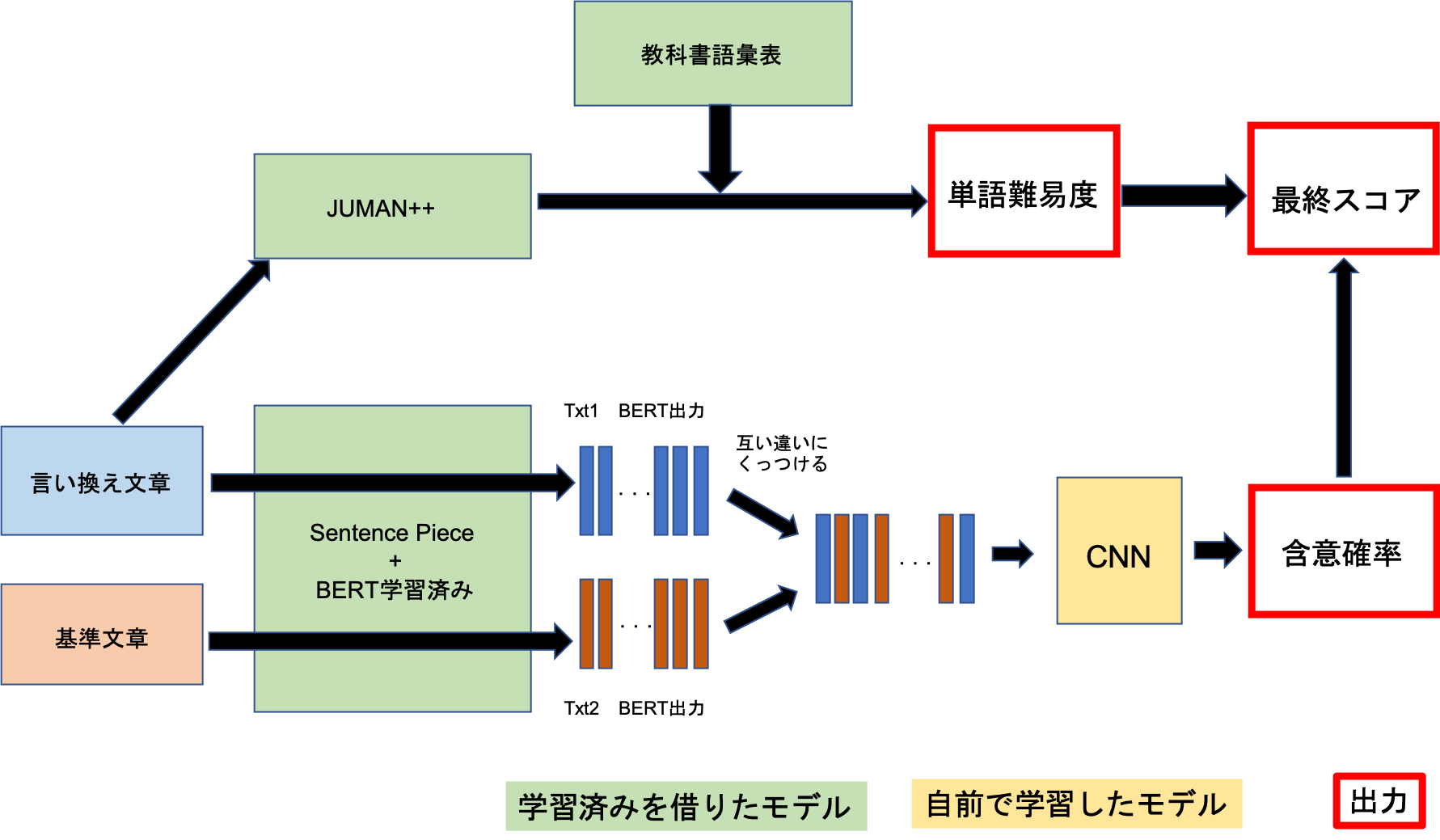
手法概要
“やさしい” 、“言い換え”となっていることが必要となるため、”やさしさ”の判定と”言い換え”の判定機を作成します。”やさしさ”に関しては簡易的に使用されている単語の難易度、”言い換え”の判定にはBERT+CNNによる含意判定タスクを利用しました。
ガバポイント1
単語の判定だけじゃなくて、呼応表現の判定なども本来は加えられると良い。 含意判定タスクについてもガバがあるが、これは後述。手法1:やさしさの判定
JUMAN++による形態素解析をして、形態素解析した結果の自立語(名詞、動詞、形容詞、副詞)について、それぞれ教科書コーパス語彙表における初出学年によって難易度判定する。
(黒橋・河原研究室様、及び国立国語研究所様、ありがとうございます)
(一応教育、研究目的にあたると思って語彙表をお借りしましたが、問題があれば別のものを使用します。)
今回は教科書コーパスに乗ってない自立語に関してはカウント対象外としています。
というのも〜するのようなサ変動詞が見つからなかったり、そもそも教科書コーパスに乗らないようなレベルの単語をわざわざやさしい言い換えに使うことはあまり無いとのことで実装上のわかりやすさを重視しました。
JUMAN ++ のインストールは現在Macならば
brew install jumanpp
で可能。今回はpythonバインディングから使用するので合わせてKNPもインストールするが、pipで入るので、
!pip install pyknp
で大丈夫です。古い情報ではそれぞれwgetしてたりしますが、現在はこれでいけます。
次に難易度判定辞書を作る。とはいってもそんなに難しくなく、語彙表をちょっと処理して辞書型として持つだけで、
vocab = pd.read_csv("./教科書.txt",encoding="utf8",sep="\t")
vocab = vocab[["語彙素","語彙素読み","初出学年"]]
grade_dif_dic = {"小_前":0,"小_後":1,"中":2,"高":3}
vocab_diff_dic = {}
for line in vocab.values:
if line[0] in vocab_diff_dic and grade_dif_dic[line[2]] < vocab_diff_dic[line[0]]:
vocab_diff_dic[line[0]] = grade_dif_dic[line[2]]
else:
vocab_diff_dic[line[0]] = grade_dif_dic[line[2]]
このように辞書を作っただけ。Pandasのmapもっとスマートにできるだろとか言うのは許してください。多分そんなに無いと思うのですが、もし見出し語がかぶった場合は良い方に解釈する(初出が早い方を採択する)ようにしておいています。
形態素解析はほとんど例の通りで
このうち品詞が自立語のものに対してのみ難易度を辞書から取得して和をとっていく。
具体的には、
test1 = "これはお試し用の文章であって、本実験に利用する文章とは異なります"
result = jumanpp.analysis(test1)
d1 = 0
d1_cnt = 0
for mrph in result.mrph_list(): # 各形態素にアクセス
if mrph.hinsi in indep:
if mrph.genkei in vocab_diff_dic:
d1 += vocab_diff_dic[mrph.genkei]
d1_cnt += 1
print(mrph.genkei,vocab_diff_dic[mrph.genkei])
print("難易度合計:{} 自立語数:{} 平均難易度:{}".format(d1,d1_cnt,d1/d1_cnt))
難易度合計:4 自立語数:6 平均難易度:0.6666666666666666
このような感じである。
手法2: 意味同値性の解析
ここが最もガバを含むポイントであるので心の準備をお願いします。
2-1:データの準備
今回はBERTを事実上データの前処理として使用するのでこの章ではどこからデータを借りたかのみを述べる。今回は意味が等しいかを判定するので、似たタスクとして含意性の判定用のデータセットを使用する。また、やさしい言い換えについても判定してほしいので以下のデータを使用した。
長岡技術科学大学 自然言語研究室 やさしい日本語コーパス
NTCIR-10 RITE2
京都大学 黒橋・河原研究室 Textual Entailment評価データ
このうちやさしい日本語コーパスは研究室閉鎖に伴い2020年3月末でサイトごと閉鎖してしまうのでダウンロードする方は早めにした方が良さそうです。
各データセットの作者様ありがとうございます。
- RITE2にはbc,mc,unittestとあるが、この内bc,mcを利用させていただいた。mcは2値正解不正解に変換している。
- Textual Entailment評価データは2値データバージョンをお借りした。
- やさしい日本語データセットは、言い換え語も変化しない(もともとやさしい日本語であったもの)が結構含まれているので、前後で変化するもののみを使わせていただいた。
ここまででデータを作ると、やさしい日本語データセットが含意のデータしかなく、かつデータ数も多い関係上含意データがかなり多い不均衡データとなって色々面倒である。
そのため最後に上のデータ群からランダムに異なる2文を選択し組み合わせて非含意のデータを水増しして無理やり均衡データとした。
以上のデータを作るコードはこちら
def data_load():
train_x = []
train_y = []
true_count = 0
entail_kyoto = ET.parse("/content/drive/My Drive/Aizen/Datas/entail_evaluation_set_label_conv.xml") #京大コーパス
entail_kyoto_root = entail_kyoto.getroot()
for child in entail_kyoto_root:
temp = []
if child.attrib["label"] == "Y":
train_y.append(1)
true_count += 1
else:
train_y.append(0)
for gchild in child:
temp.append(gchild.text)
train_x.append(temp)
RITE_names = ["dev_bc","dev_mc","testlabel_bc","testlabel_mc"]
pos = ["F","B","Y"]
neg = ["C","I","N"]
for name in RITE_names: #RITEを読み込み。testごと読んであとで分割
rite_file_path = "/content/drive/My Drive/Aizen/Datas/RITE2_JA_bc-mc-unittest_forOpenAccess/RITE2_JA_{}/RITE2_JA_{}.xml".format(name,name)
rite_tree = ET.parse(rite_file_path)
root = rite_tree.getroot()
for child in root:
temp = []
if child.attrib["label"] in pos:
train_y.append(1)
true_count += 1
else:
train_y.append(0)
for gchild in child:
temp.append(gchild.text)
train_x.append(temp)
easy_jp = pd.read_csv("/content/drive/My Drive/Aizen/Datas/T15-2020.1.7.csv").values #やさしい日本語読み込み。
for line in easy_jp:
if line[1] != line[2]: #言い換えで変わったやつだけ
train_y.append(1)
train_x.append([line[1],line[2]])
true_count += 1
#ここから、正解不正解が同じになるまで、randomな2文をくっつけて不正解水増し
all_num = len(train_x)
for i in range(2*true_count-all_num):
left_raw = np.random.randint(all_num)
left_col = np.random.randint(2)
right_raw = np.random.randint(all_num)
while left_raw == right_raw:
right_raw = np.random.randint(all_num)
right_col = np.random.randint(2)
train_x.append([train_x[left_raw][left_col],train_x[right_raw][right_col]])
train_y.append(0)
return train_x,train_y
ガバポイント2
しかし、今回はやさしい言い換えが含意になっているかが判断できれば十分であるので、この目的に沿ったやさしい言い換えデータは十分含まれているため今回はそれでよしとしている。
2-2
モデルとしては最近(というより少し前?)、ホットな自然言語処理モデルであるBERTを利用する。BERTとは何たるかもよくわかっていなかったので、以下のサイトを参考にさせて頂いた。
https://udemy.benesse.co.jp/ai/bert.html
https://ainow.ai/2019/05/21/167211/
http://deeplearning.hatenablog.com/entry/transformer
今回利用するモデルはBERT+CNNのモデルである。
BERT部分は自力での訓練がかなり大変なので、どうしようかと思っていたところ以下の様な非常にありがたいものを見つけた。
https://yoheikikuta.github.io/bert-japanese/
神。ありがとうございます。
さて、これはSentence pieceなので学習用データ作らないとなぁ…ん…?
https://qiita.com/hideki/items/1ec1c21c33326ad5615f
え、便利すぎか?ありがとうございます。
ということで偉大な先人たちの積み重ねによって一瞬であのモンスターモデルであるBERTによるベクトル取得ができるようになってしまった。
ということで、head部を作っていく。今回貧困学生である自分にはBERTごとファインチューニングするだけの計算資源が用意できなかったので、head部のみをGoogle Colablatoryによってチューニングする。(google様ありがとうございます)
BERTによって得られるベクトルは単語ごとになっている。
2文書分のベクトルを入力して、意味が同じかそうでないかの2クラス分類として問題を解く。
ここで少し工夫した点は、入力ベクトルを、2文書のベクトルを交互に挿入して作成した点だ。
流石に並列に並べるよりは位置が近い単語を近くにおいた位置情報を持ったベクトルの方が良いだろうと考えたためである。
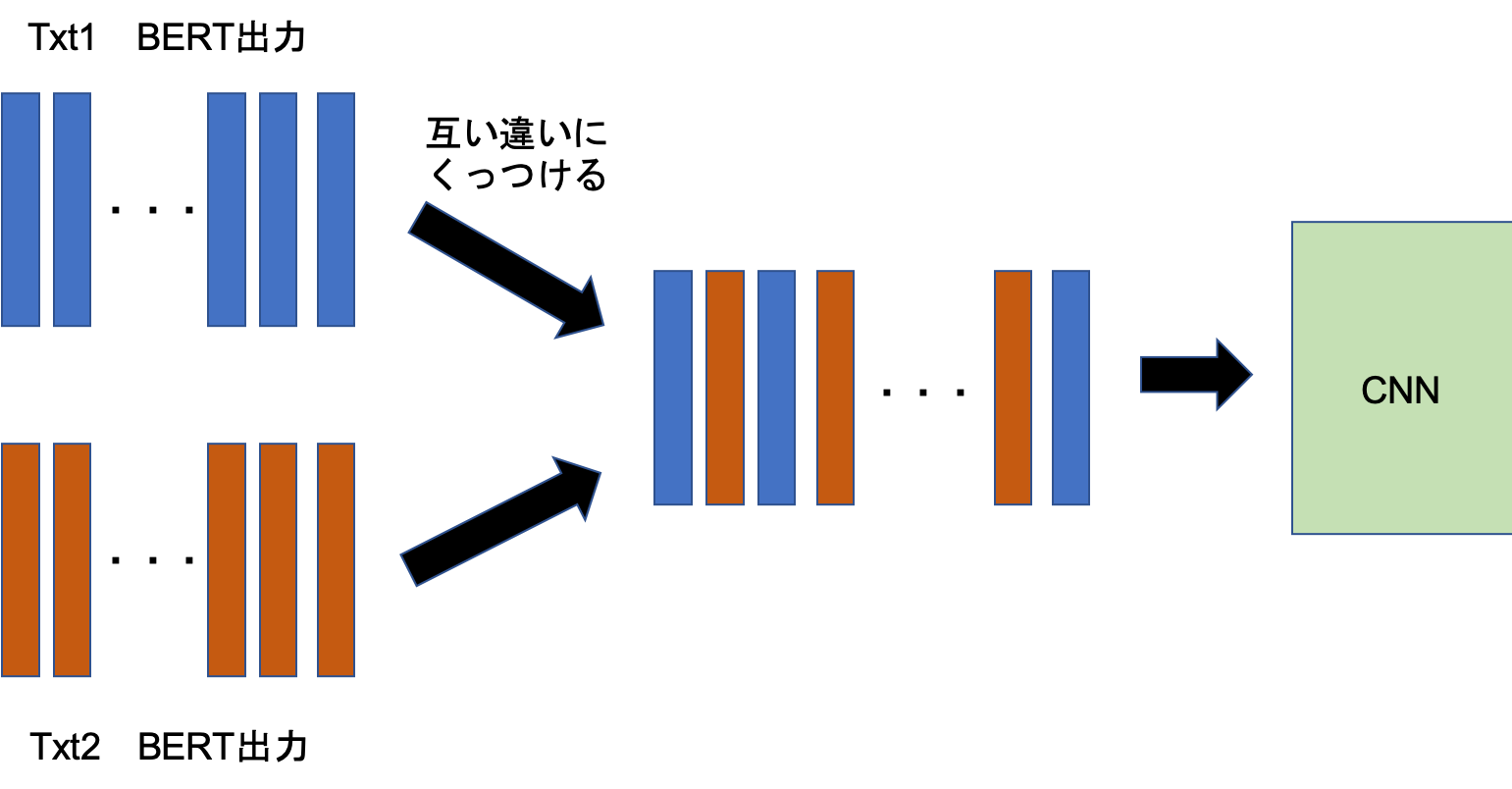
以上のベクトルをCNNで分類する。CNNの構成はkerasで行ってこんなかんじ。
def make_network():
x_in = Input((256,768,1))
x = Conv2D(64,(3,3),padding="valid")(x_in)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(64,(3,3),padding="valid")(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(3,3),strides=2,padding="same")(x)
x = Conv2D(64,(2,2),padding="valid")(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(128,(2,2),padding="valid")(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(3,3),strides=2,padding="same")(x)
x = GlobalAveragePooling2D()(x)
x = Dense(2)(x)
x = Activation("softmax")(x)
model = Model(x_in,x)
return model
まぁ特に変わったところは無いただのCNNである。
ガバポイント3
横方向のみを考えるなら、3*3のフィルタよりも1*5とかのフィルタを使ったほうが、比較的遠くまで見れるのに加えてパラメータ数も減らせた気がする。上記のデータをモデルに投げ入れるgeneratorはこんな感じ。
def data_gen(data_X,data_y,vectorian,batchsize=32):
d_cnt = 0
x = []
y = []
while True:
for i in range(len(data_X)):
t_l = str(data_X[i][0])
t_r = str(data_X[i][1])
t_l = vectorian.fit(t_l).vectors
t_r = vectorian.fit(t_r).vectors
itp = range(t_l.shape[1])
in_x = np.insert(t_r,itp,t_l[:,itp],axis=1)
x.append(in_x)
if data_y[i] == 1:
y.append([0,1])
else:
y.append([1,0])
d_cnt += 1
if d_cnt == batchsize:
inputs = np.array(x).astype(np.float32)
inputs = inputs.reshape(batchsize,256,768,1)
targets = np.array(y)
x = []
y = []
d_cnt = 0
yield inputs,targets
まぁ別に面白くない。
ということで学習開始ー
なんと1epoch1時間かかるのでGoogleColablatoryでの学習は骨が折れた。
3〜5epochの精度はこんな感じ(途中でGPU制限されてランタイムを新しくした関係上1〜2epochの出力を消しちゃいました。)
Epoch 1/1
1955/1955 [==============================] - 3846s 2s/step - loss: 0.1723 - categorical_accuracy: 0.9396 - val_loss: 0.1632 - val_categorical_accuracy: 0.9398
Epoch 1/1
1955/1955 [==============================] - 3852s 2s/step - loss: 0.1619 - categorical_accuracy: 0.9436 - val_loss: 0.1477 - val_categorical_accuracy: 0.9487
Epoch 1/1
1955/1955 [==============================] - 3835s 2s/step - loss: 0.1532 - categorical_accuracy: 0.9466 - val_loss: 0.1462 - val_categorical_accuracy: 0.9482
まだloss下がりそうですが、PCの前に張り付いてるのも厳しいので勘弁していただきたく…
ちなみに今回は無理やりですが均衡データにしたのでF1は計算しません~~(面倒くさい)~~
均衡データならaccuracyでもそこまで変な結果にならないのでは無いかなと考えています.
出力
以上のモデルと辞書を利用していよいよ文章の言い換え判定と難易度スコアを出していく。
適当に出力用関数を用意する。
def texts_to_inputs(text1,text2):
t_l = text1
t_r = text2
t_l = vectorian.fit(t_l).vectors
t_r = vectorian.fit(t_r).vectors
itp = range(t_l.shape[1])
in_x = np.insert(t_r,itp,t_l[:,itp],axis=1).reshape(1,256,768,1)
return in_x
def easy_trans_scores(test1,test2,vocab_diff_dic):
test_x = texts_to_inputs(test1,test2)
p = model.predict(test_x)
result = jumanpp.analysis(test1)
d1 = 0
d1_cnt = 0
for mrph in result.mrph_list(): # 各形態素にアクセス
if mrph.hinsi in indep:
if mrph.genkei in vocab_diff_dic:
d1 += vocab_diff_dic[mrph.genkei]
d1_cnt += 1
print("含意確率:{:.3g} 難易度合計:{} 自立語数:{} 平均難易度:{}".format(p[0][1],d1,d1_cnt,d1/d1_cnt))
print("total score:{:.5g}".format(p[0][1]/d1))
ひとまず、含意/(難易度合計)をスコアとして採用してみます。
平均難易度でなく合計なのは、短く簡潔な文章をよく評価したほうがよいと考えたからです。
まぁ難易度合計が0のときに必ず値がinfになって含意関係なくなるっていうバグが存在するのですが…
今回はまぁいいです…
結果
| 基準文章 | 言い換え文章 | score | 含意確率 | 難易度 |
|---|---|---|---|---|
| これはお試し用の文章であって、本実験に利用する文章とは異なります | これはお試し用の文章です | 0.88207 | 0.882 | 1 |
| これはお試し用の文章であって、本実験に利用する文章とは異なります | この文章はあくまで試験用に用意されたものであって、実際に使用するものとは異なります | 0.20793 | 0.832 | 4 |
| これはお試し用の文章であって、本実験に利用する文章とは異なります | これはテストです | 0.53867 | 0.539 | 1 |
| 次の会議のために議題を書類に要約しておいてください | 次の会議のためにアジェンダをレジュメにサマリーしといてください | 0.086415 | 0.744 | 9 |
| 次の会議のために議題を書類に要約しておいてください | 次の会議のために話し合うことを紙にまとめておいてください | inf | 0.994 | 0 |
| 解放の瞬間を一度でも見た相手の五感・霊圧知覚を支配し、対象を誤認させることができる完全催眠. | 解法の瞬間を一度でも見たら,対象を必ず誤認させてしまう. | 0.063651 | 0.287 | 5 |
| 解放の瞬間を一度でも見た相手の五感・霊圧知覚を支配し、対象を誤認させることができる完全催眠. | 解法の瞬間を一度でも見た相手を操って,対象を間違って感じさせることができる. | 0.11004 | 0.654 | 7 |
最もスコアが高いと判定された言い換えを太字にしています。
そこそこ納得感のある結果では無いでしょうか?
ところで愛染様…もう少しやさしい言葉をお願いします…
結果2(追記) 言い換え上手バトルと金・ロジャーのパワー
このシステムを使って友人と言い換え上手王決定戦を行いました(1vs1の勝負ですが勝ったら王です。)
ゲーム化するとこんな感じになるよ?という感じです。
お題はこちら。
富、名声、力、この世の全てを手に入れた男’海賊王ゴールドロジャー’彼の死に際に放った一言は人々を海へ駆り立てた。
皆さんご存知某国民的アニメのOPの口上でございます。
先手(私) 1ターン目
お金,立場、力この世界の全てをてにいれた男、海賊王ゴールドロジャー彼が死ぬ前に言った言葉で人々は海へと行きたくなった
スコア: 含意確率:0.696 難易度合計:8 total score:0.087022
まぁまぁ初手としては良いんじゃないでしょうか。少々含意確率が低いので難易度を下げるために攻めすぎた感じがあります。
後手(相手) 1ターン目
"お金,人気,力,この世の全てを手に入れた男'海賊王ゴールド・ロジャー'彼が死ぬ間際に言った一言は人々を海へ向かわせた"
スコア: 含意確率:0.974 難易度合計:14 total score:0.069588
含意確率で大きく話されていますが、total scoreでは私がまだ勝っています。単語の言い換えで攻めないとこうなるんですね。意外と戦略性があります。
先手(私) 2ターン目
お金,人気,力,世界の全てを手にいれた男、'海賊王ゴールドロジャー'彼が死ぬ前に言った言葉で人々は海へと行きたくなった
スコア: 含意確率:0.917 難易度合計:9 total score:0.10194
相手の方が含意確率が高かったので、それをお手本に取り入れて大きく含意確率及びtotal scoreを改善する事ができました。これは勝った(フラグ)
後手(相手) 2ターン目(優勝文)
お金,人気,力,世界の全てを手に入れた男'海賊王金・ロジャー'彼が死ぬ時に言った一言はみんなを海へ向かわせた
スコア: 含意確率:0.952 難易度合計:9 total score:0.10581
え・・・?
負けました。僅差ではありますが負けは負けです。
おそらく勝敗を分けたのは金・ロジャー。これによって大きく難易度を下げつつ含意確率を維持しています。(結果見たときはゲラゲラ笑ってました)
とまぁこんな感じに楽しい言い換え上手王決定戦ができるのも本システムの面白いところです。
ところどころガバガバなのでこのシステムはどう解釈するだろうか?みたいなメタの張り合いを含めたガチ競技的な点の取り合いも、良識の範囲内の点の取り合いもできて、それぞれに面白さがあります。
まとめと今後の展望
なんやかんやガバガバなところがありながらも、含意判定と難易度判定を組み合わせてやさしい言い換えができているかを判定する事がなんとなくできました。
これ、結構自分でやってて面白い
(うまく言い換えられているか?とかこんな文章は難しいんじゃないか?という問題設定も面白い)
ので、これをなんとかゲーム化なりサービス化なりとかしたいです。
(オンラインランキングを実装するなどしたい)(サービスを構築する知識がなくて今はできていません)
最初に述べたとおりこれをゲームとして楽しんで貰えれば楽しんでもらうと同時に、人々が作ったやさしい言い換えのデータセットを作ることもできるかもしれなく、そのデータを用いることで更に面白い考察ができたりしないかなと考えています。
今回のモデル等(試して見たい人向け)
においておきました。リポジトリにも書きましたが、
- JUMAN++
- text-vectorian
- BERT日本語学習済みモデル(https://yoheikikuta.github.io/bert-japanese/)
をご用意の上、Aizen.ipynbを見ていただければ(多分)結構簡単にお試しいただけると思います。
面白い結果とか、このスコア方式がいいよなどありましたらコメントいただければ幸いです。
謝辞
本記事は、BERT学習済みモデルや様々なデータセット等をお借りした上で成り立っています。
本文中でも言及しましたが、これらを整備してくださった方々ありがとうございます。