Amazon Bedrock 生成AIアプリ開発入門 [AWS深掘りガイド]を使った社内ハンズオン手順です。
書籍の補助的な位置づけなので、書籍は買ってね!

書籍との違い
書籍使用する開発環境が異なります。以下の手順に従って開発環境を構築してください。
開発環境の準備
開発環境として、Visual Studio Code Server(VS Code Server)をインストールしたEC2を構築します。
Bedrockの使用リージョンの都合でバージニア北部とします。
複数人でハンズオンを実施する場合、クオーター制限に気をつけてください。
引っかかりそうなクオーター
- VPCs per Region (VPCのクオーター。デフォルトが5)
- EC2-VPC Elastic IPs (EC2のクオーター。デフォルトが5)
構築はAWS CloudFormationを使用します。
-
以下のリンク先の、CloudFormationテンプレートをローカルにダウンロードします
AWS提供のテンプレートから以下の点を修正しています
- WebSocket対応
- 同一リージョンで複数環境を構築できるように調整
-
CloudFormationの管理画面を開きます
リージョンが「バージニア北部」であることを確認してください
「スタックの作成」メニューの「新しいリソースを使用(標準)」をクリックします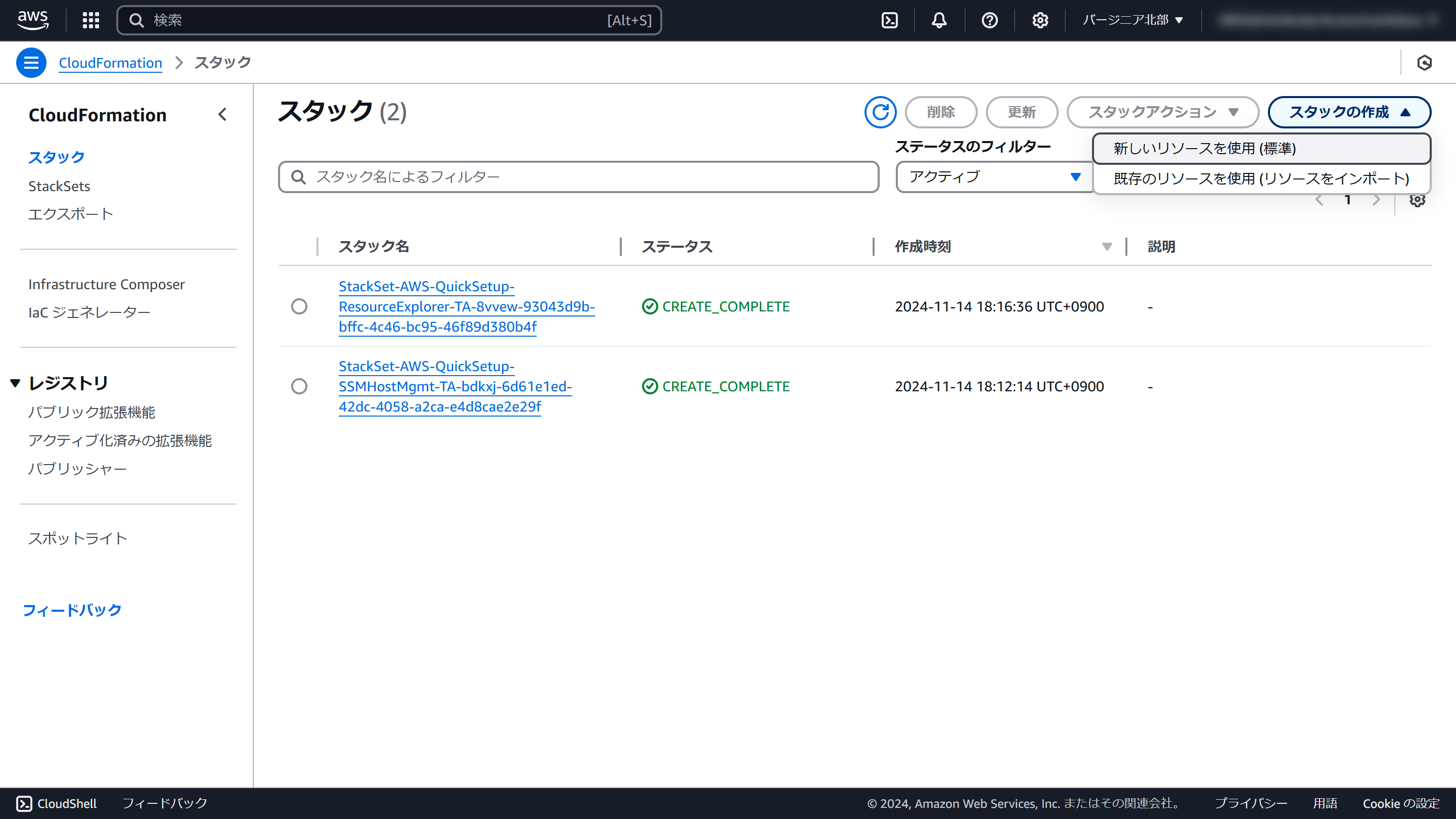
-
以下の手順を実施します
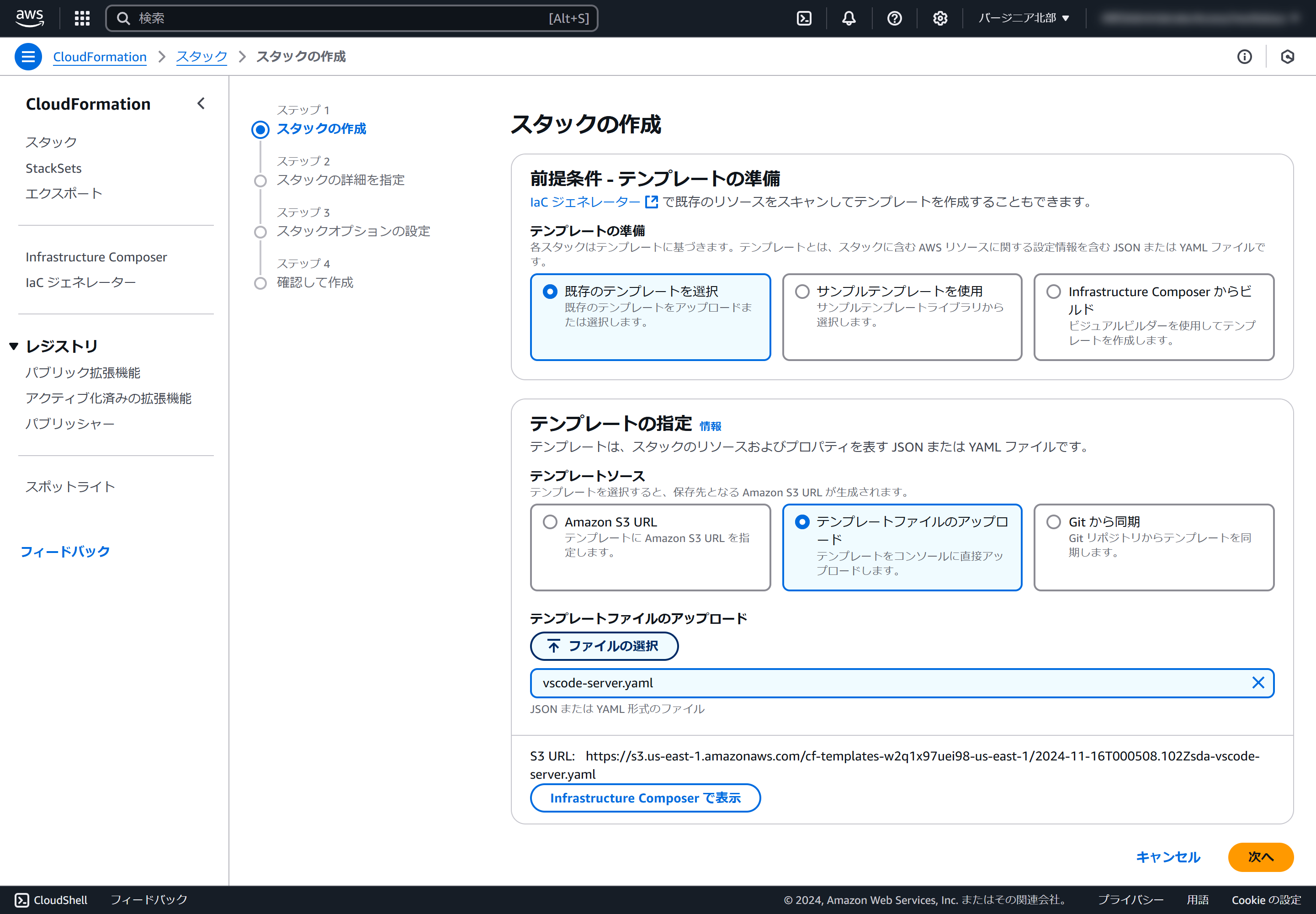
- テンプレートの準備は「既存のテンプレートを選択」を選択します
- テンプレートソースは「テンプレートファイルのアップロード」を選択します
- 先ほどダウンロードしたファイルを選択します
- 「次へ」をクリックします
-
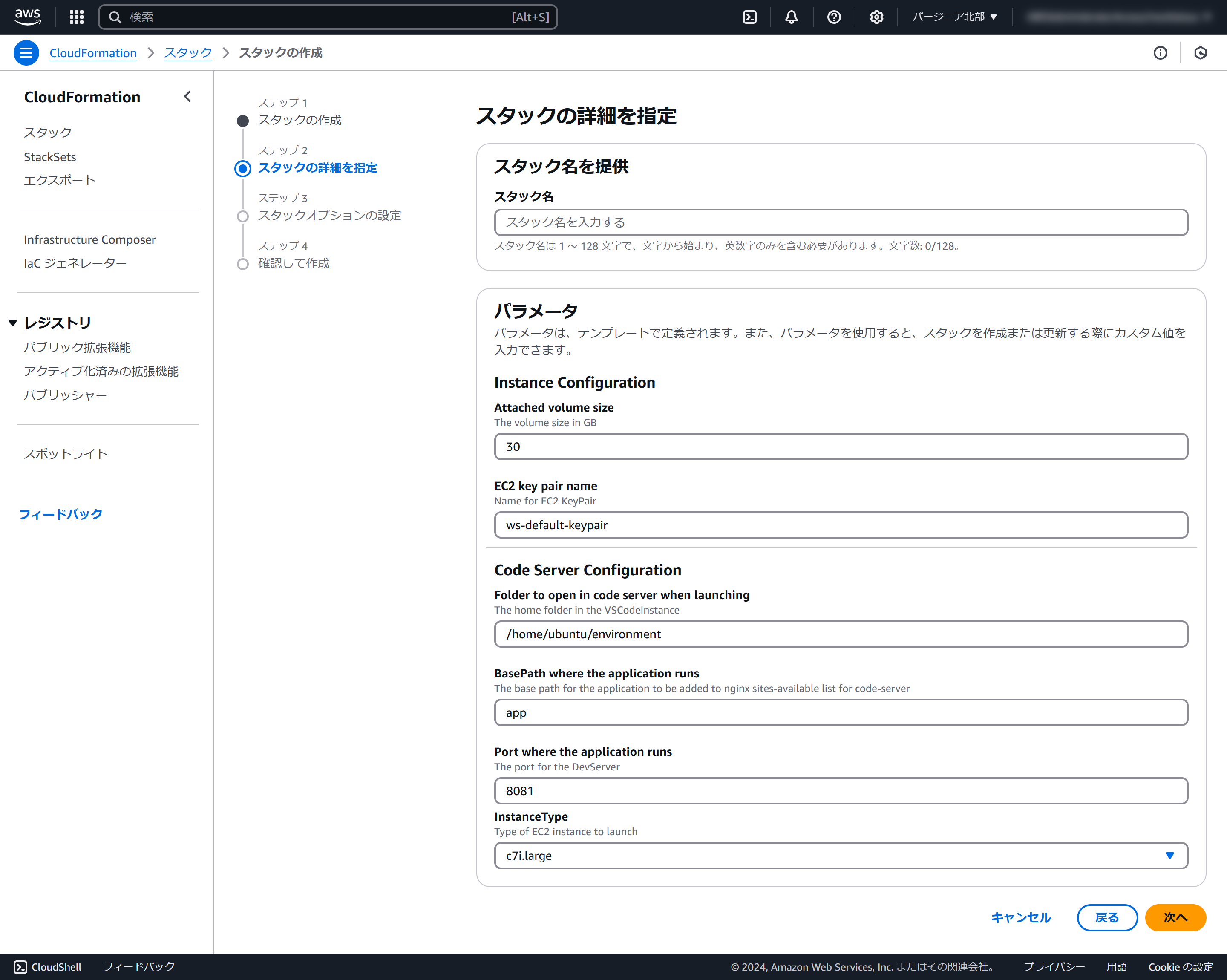
スタック名に「vscode-server-{ユーザー名}」を入力し、「次へ」をクリックします
-
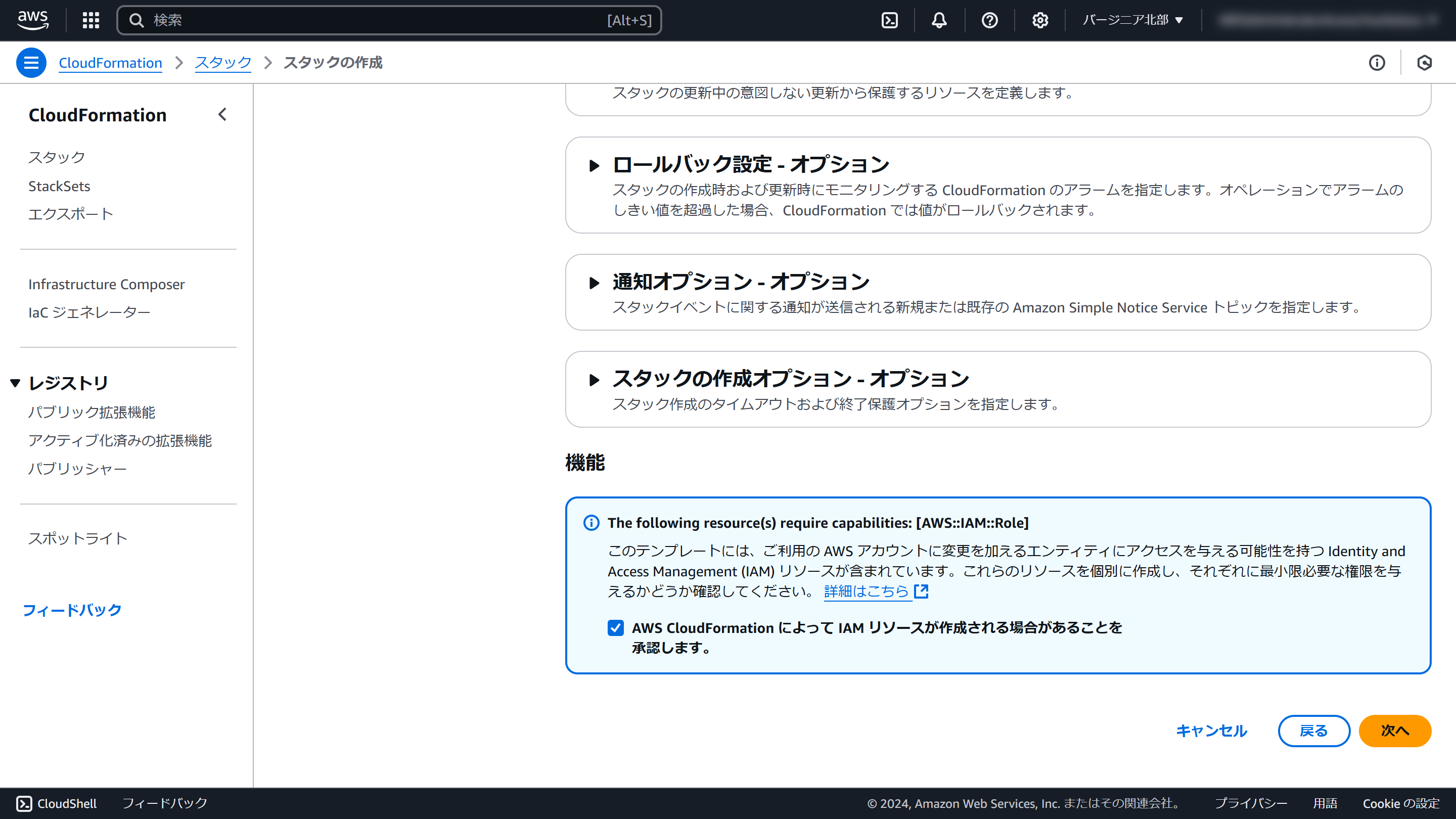
画面最下部の「AWS CloudFormation によって IAM リソースが作成される場合があることを承認します。」にチェックを入れ、「次へ」をクリックします
-
画面最下部の「送信」をクリックします
-
リソースの作成が始まります
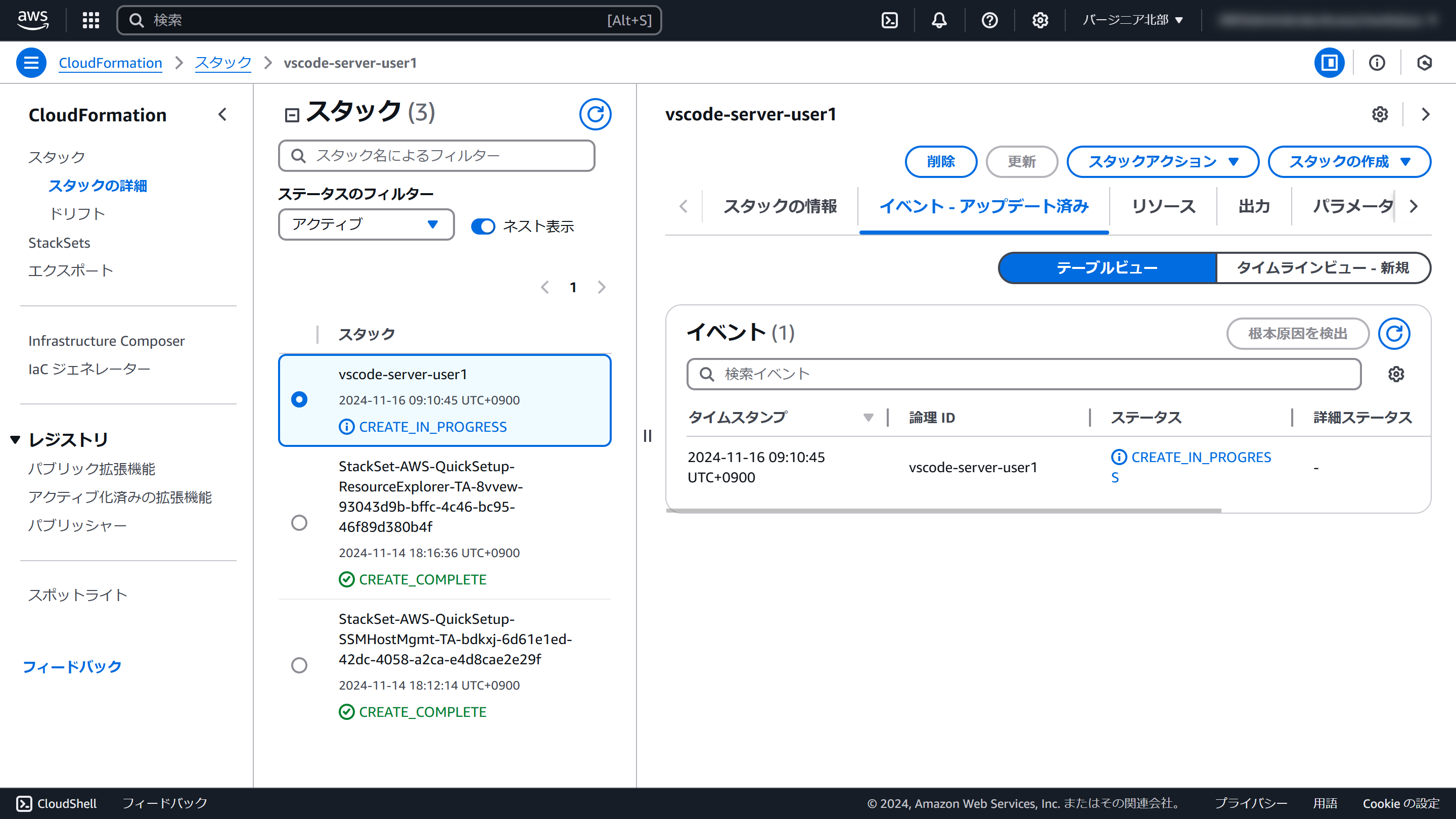
作成が完了すると、ステータスが「CREATE_COMPLETE」になると作成完了です。
-
「出力」タブに切り替えます
「PasswordURL」欄のリンクを新しいタブで開きます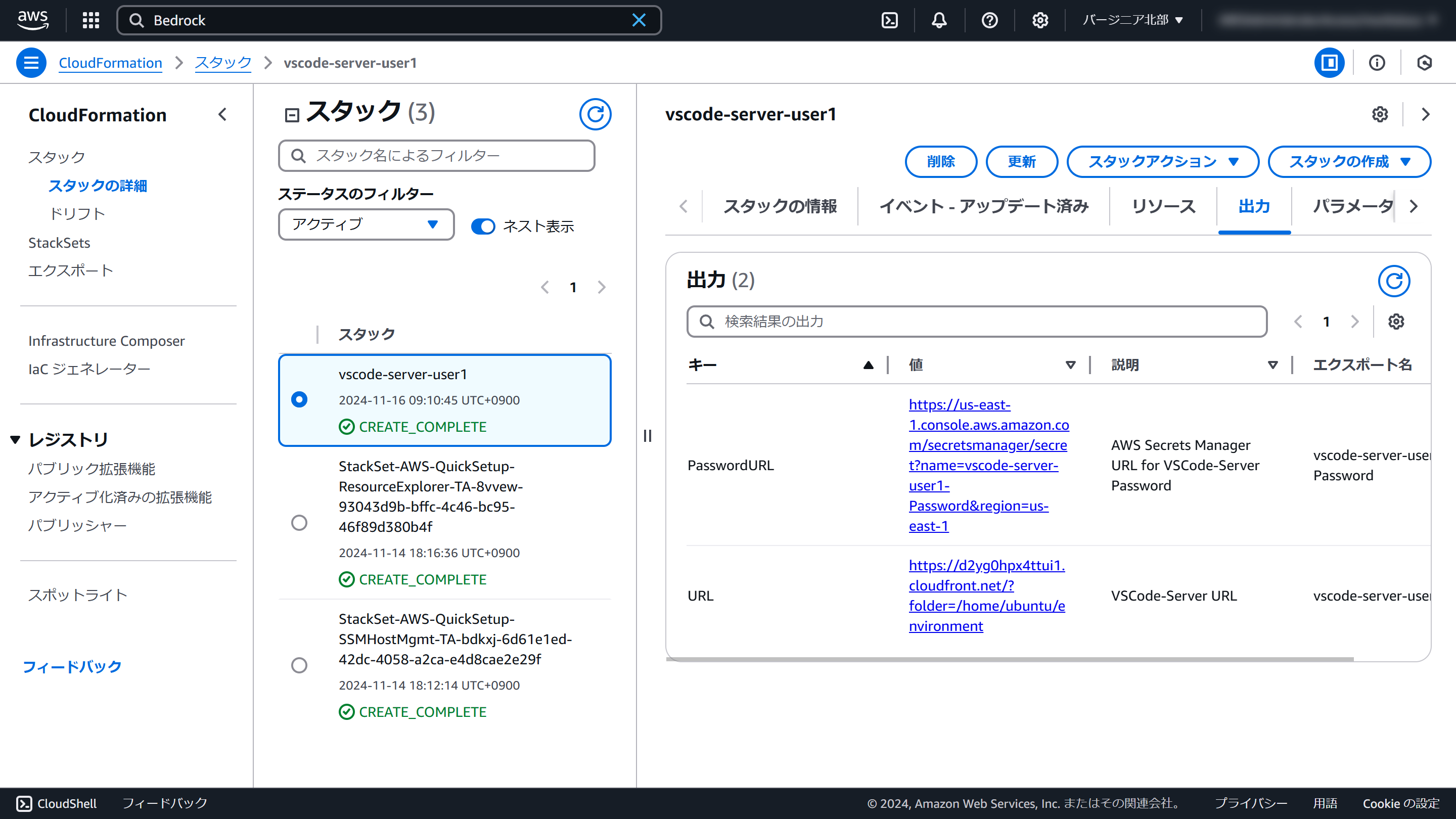
-
AWS Secrets Managerの管理画面が開きます
シークレットの値セクションにある「シークレットの値を取得する」をクリックします
表示される値をメモします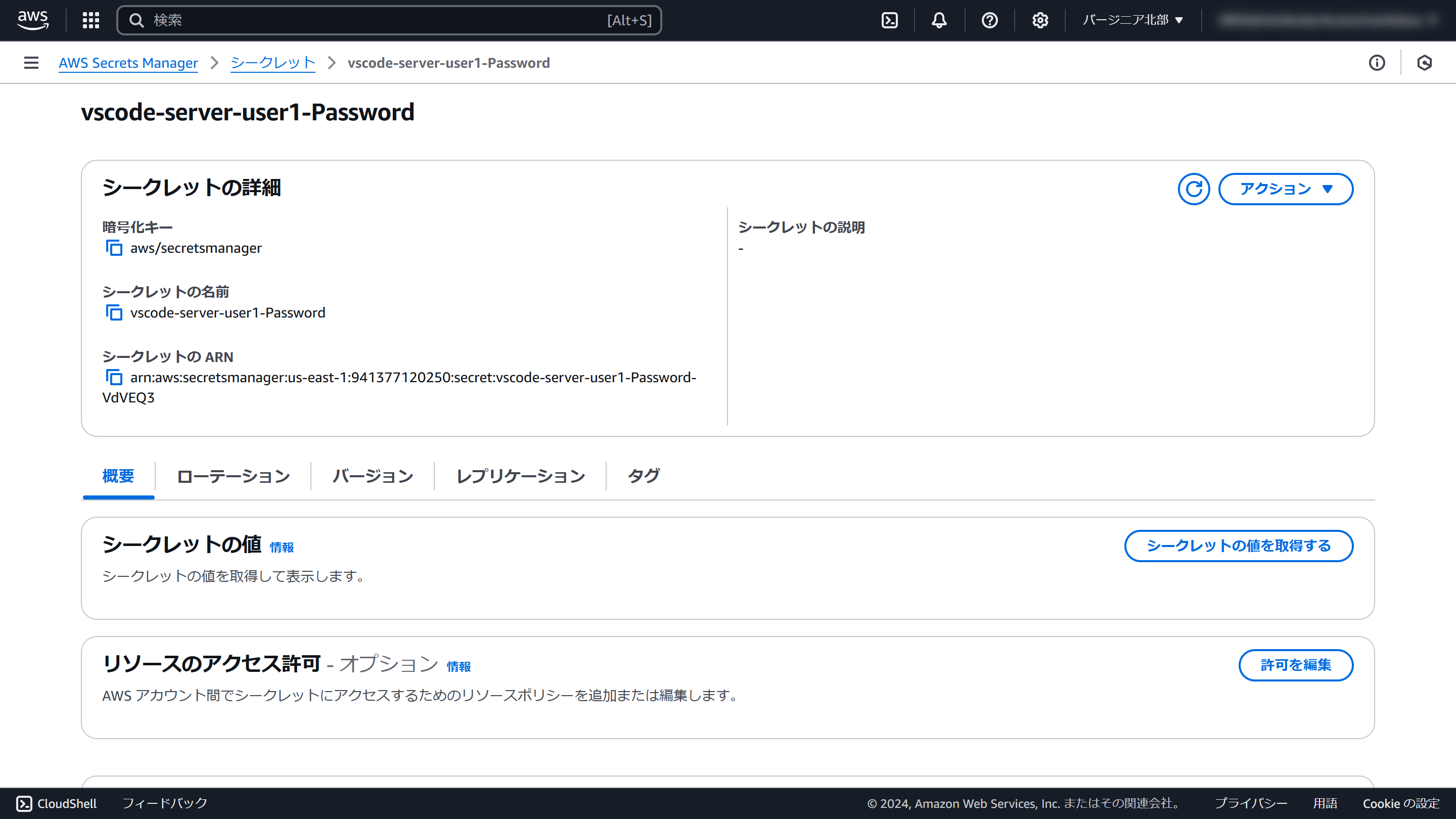
-
CloudFormationの画面に戻り、「URL」欄のリンクを新しいタブで開きます
-
VS Code Serverの画面が表示されます
先程のパスワードを入力し、「SUBMIT」をクリックします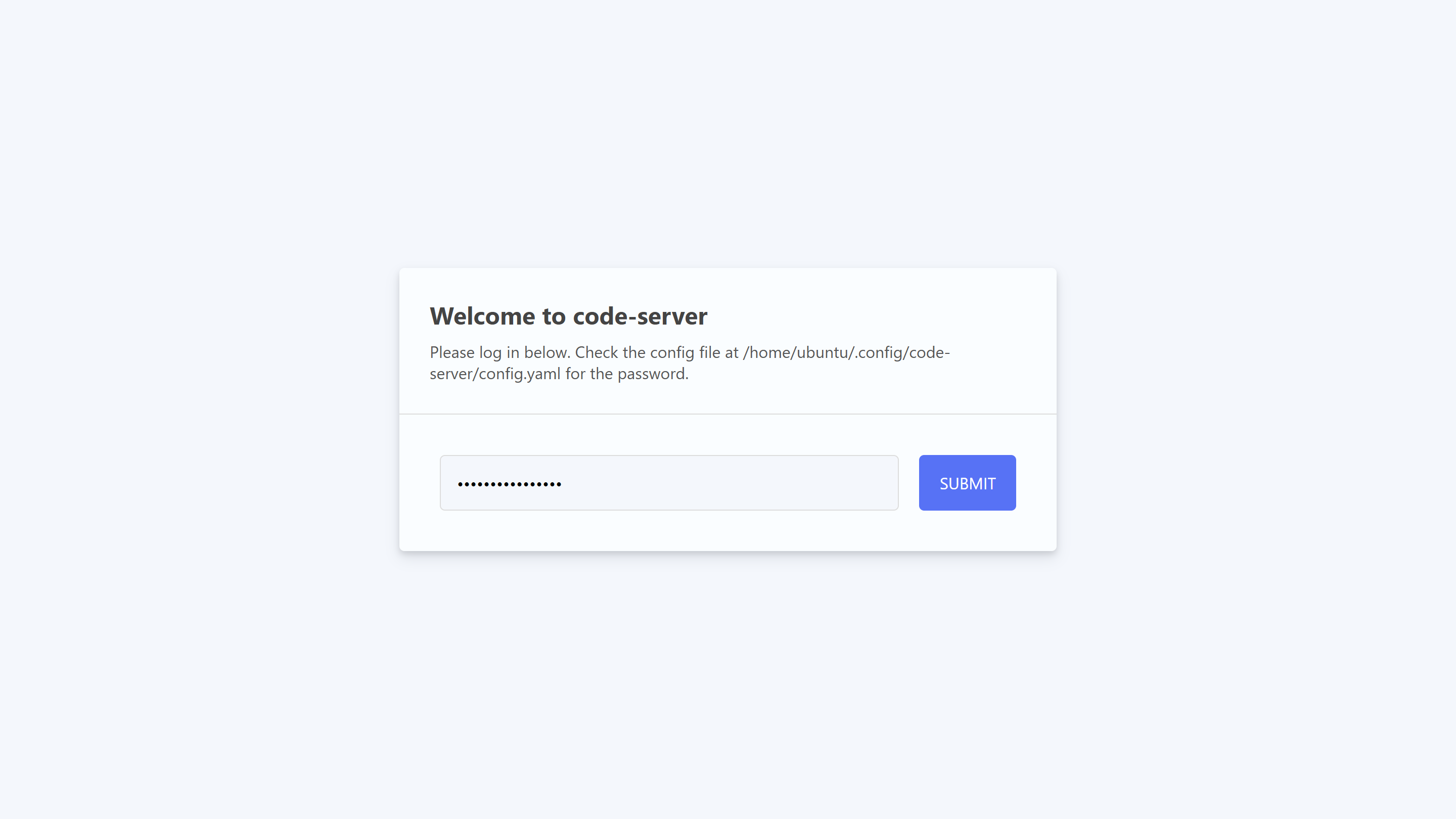
CloudFormationスタックのステータスが「CREATE_COMPLETE」に変わったあと、非同期でEC2内の環境セットアップが行われます。502エラーが表示される場合はしばらく待って再度アクセスを試みてください
ソースコードの取得
ハンズオンのソースコードはGitHubで公開しているので、取得します
git clone https://github.com/minorun365/bedrock-book.git
これで開発環境の準備は完了です。
ハンズオン1:2.11 Bedrockを実際に試してみよう
P.80以降を実施します。
2.11.1 プレイグラウンドを利用してGUI上で生成する方法
書籍を参考にマネジメントコンソールで実施します
2.11.2 AWS SDKを用いて各モデルのAPIへリクエストを行う方法
書籍を参考にVS Code Serverで実施します
貼り付けは Ctrl + Shift + V
cd ~/environment/bedrock-book/chapter2/
-
ライブラリーのインストール
pip install boto3==1.34.87 -
モデル一覧の出力
python3 1_list-models.py -
モデル呼び出し
python3 2_invoke-model.py
Converse API版
python3 2-1_invoke-converse.py
-
モデル呼び出し(ストリーミング)
python3 3_streaming.py
Converse API版
python3 3-1_streaming-converse.py
-
モデル呼び出し(マルチモーダル)
python3 4_multimodal.py
ハンズオン2:3.5 LangChainとStreamlitを使った生成AIアプリ開発
P.143以降を実施します。
cd ~/environment/bedrock-book/chapter3/3_with_langchain_streamlit/
3.5.1 開発環境の準備
pip install -r requirements.txt
書籍に記載の方法
pip install boto3==1.34.87 langchain==0.2.0 langchain-aws==0.1.4 langchain-community==0.2.0 streamlit==1.33.0 python-dateutil==2.8.2
3.5.2 【ステップ1】 LangChainの実装
python3 1_langchain.py
3.5.3 【ステップ2】ストリーム出力
python3 3_langchain-streaming.py
3.5.4 【ステップ3】Streamlitとの統合
streamlit hello --server.port 8081 --server.baseUrlPath app
Cloud9とVS Code Serverの違いがあるため、書籍とコマンドが異なります。
--server.port 8080の部分を--server.port 8081 --server.baseUrlPath appに変更してください。
ブラウザで「https://{VS Code Serverのドメイン}/app」にアクセスします。
EC2の内部ではVS Code Serverの前段にNginxがリバースプロキシとして配置されています。
「/」へのリクエストがVS Code Serverへ転送され、「/app」へのリクエストが8081番ポートに転送されるように設定されています。
Streamlitで構築したアプリを起動
streamlit run 4_streamlit.py --server.port 8081 --server.baseUrlPath app
3.5.5 【ステップ4】チャット形式の継続したやり取り
streamlit run 5_streamlit-session.py --server.port 8081 --server.baseUrlPath app
3.5.6 【ステップ5】チャット履歴の永続化
DynamoDBのテーブル名は「BedrockChatSessionTable-{ユーザー名}」としてください。
そのうえで、Pythonのコードも以下のように修正してください。
# セッションに履歴を定義
if "history" not in st.session_state:
st.session_state.history = DynamoDBChatMessageHistory(
- table_name="BedrockChatSessionTable", session_id=st.session_state.session_id
+ table_name="BedrockChatSessionTable-{ユーザー名}", session_id=st.session_state.session_id
)
streamlit run 6_streamlit-dynamodb.py --server.port 8081 --server.baseUrlPath app
ハンズオン1:4.2 Knowledge basesでRAGを実装してみよう
P.192以降を実施します。
4.2.1 Knowledge basesの仕組み ~ 4.2.6 ナレッジベース単体での動作を確認する
書籍を参考にマネジメントコンソールで実施します
複数人で同時に実行する場合APIの同時実行制限に掛かる可能性があるので、少しずつ時間をずらして実行してください。
- ナレッジベース作成APIは2リクエスト/秒が上限
- 同期は同時に5リクエストが上限
など
4.2.7 フロントエンドを実装する ~ 4.2.8 RAGアプリケーションを実行する
書籍を参考にVS Code Serverで実施します
cd ~/environment/bedrock-book/chapter4/
knowledge_base_idを指定します
# 検索手段を指定
retriever = AmazonKnowledgeBasesRetriever(
- knowledge_base_id="XXXXXXXXXX", # ここにナレッジベースIDを記載する
+ knowledge_base_id="{ナレッジベースID}", # ここにナレッジベースIDを記載する
retrieval_config={"vectorSearchConfiguration": {"numberOfResults": 10}},
)
streamlit run 1_rag.py --server.port 8081 --server.baseUrlPath app
コラムの内容
# ナレッジベースを定義
response = kb.retrieve_and_generate(
input={"text": question},
retrieveAndGenerateConfiguration={
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
- "knowledgeBaseId": "XXXXXXXXXX", # ナレッジベースID
+ "knowledgeBaseId": "{ナレッジベースID}", # ナレッジベースID
"modelArn": "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-sonnet-20240229-v1:0",
},
},
)
streamlit run 2_rag-boto3.py --server.port 8081 --server.baseUrlPath app
お疲れ様でした!
まとめ
今回は短縮版としてお届けしました。書籍では他にも色々取り扱っていますのでぜひ実施してください。
今回のハンズオンをやりきっていれば他の部分も実施できると思います。
目次
- 生成AIの基本と動向
- Amazon Bedrock入門
- 生成AIアプリの開発手法
- 社内文書検索RAGアプリを作ってみよう
- 便利な自律型AIエージェントを作ってみよう
- Bedrockの機能を使いこなそう
- さまざまなAWSサービスとBedrockを連携しよう
- 生成AIアプリをローコードで開発しよう
- Bedrock以外の生成AI関連サービスの紹介
- Bedrockの活用事例
- お勧めの最新情報のキャッチアップ方法
不明点があれば気軽に質問してください。