(2022/12/17更新)過去に作成していた障害の履歴を確認するサイトが見れなくなっていたので、改めて作成しました。AWSとGCPの障害情報が確認できます。
サイトの実現方法の解説は個人ブログをご参照ください。
(2020/6/13更新)後半に記載しているJSONですが、どうも更新にタイムラグがあるようで、状況が[RESOLVED]になってから登録されるようです。
4/20の夜にAWSの東京リージョンでSQSやLambdaに障害があったようです。
AWSも無敵ではありません。
障害があった際にすぐに気づきたいですね。
Service Health Dashboardをチェック
AWSに障害が発生した場合には、こちらのサイトでアナウンスされます。
https://status.aws.amazon.com/
こちらのサイトにはRSSも配信されているので、RSSリーダーでチェックしておくと良いですね。
しかし、、、
サービスごとにチェックするRSSファイルが分かれている!!!
「Tokyo」で検索しても120件。。。全件手動で登録するのは無理ですね。
(Slackに通知を行うとか今どきのものを考えたのですが、手動で120件も登録できません。。。)
全RSSファイルをまとめたRSSファイルを作る
Lambdaで定期的にスクレイピングする作戦です。やってやれんことはない。
できたファイルはS3にでも格納して外から見れるようにしましょう。
この例ではService Health Dashboardのタブを一つ指定して処理をするようにしました。
Asia Pacificタブは数が多く、1回に5分ほど時間がかかります。
import os
import requests
from bs4 import BeautifulSoup
base_url = 'https://status.aws.amazon.com'
rss_template = ('<?xml version="1.0" encoding="UTF-8"?>'
'<rss version="2.0">'
' <channel>'
' <title><![CDATA[AWS Service Status]]></title>'
' <link>http://status.aws.amazon.com/</link>'
' <description><![CDATA[AWS Service Status]]></description>'
' </channel>'
'</rss>'
)
def get_rss_list(block):
print('start get_rss_list')
res = requests.get(base_url)
aws_soup = BeautifulSoup(res.text, 'lxml')
tables = aws_soup.find(id=block).find_all('table')
links = []
for tr in tables[1].find('tbody').find_all('tr'):
tds = tr.find_all('td')
links.append({'service': tds[1].text, 'url': tds[3].find('a').get('href')})
return links
def get_rss_item(rss_url):
print(rss_url)
response = requests.get(rss_url)
return response.text
def add_rss_item(rss_text, rss_path, service_name, output_soup):
rss = BeautifulSoup(rss_text, 'xml')
items = rss.find_all('item')
for item in items:
category = rss.new_tag('category')
category.append(service_name)
item.append(category)
output_soup.find('channel').append(item)
def put_object(rss_string, block):
import boto3
client = boto3.client('s3')
client.put_object(
ACL='public-read',
Body=rss_string.encode('utf-8'),
Bucket=os.getenv('S3_BUCKET'),
Key='aws-status'+block+'.rss',
ContentType='application/rss+xml'
)
def lambda_handler(event, context):
block = event['block']
print(block)
output_soup = BeautifulSoup(rss_template, 'xml')
for rss in get_rss_list(block):
url = base_url + rss['url']
text = get_rss_item(url)
add_rss_item(text, url, rss['service'], output_soup)
put_object(str(output_soup), block)
全リージョンの障害情報が取得できるJSONの存在
ここまで頑張って作ったあとに、全リージョンの障害情報が取得できるJSONファイルがあることを知りました。さすがClassmethodさん。憧れる。
【小ネタ】AWSで過去に発生した障害の履歴を確認する方法 | Developers.IO
https://dev.classmethod.jp/articles/service-health-status-history/
https://status.aws.amazon.com/data.json
がそのJSONです。RSSとだいたい同じ情報が取得できます。
これをRSSにしてやれば、良さそうですね。
処理時間も30秒以内に終わるので、API GatewayでRSSを配信できます。
import requests
from bs4 import BeautifulSoup
from bs4.element import CData
from datetime import datetime, date, time, timezone, timedelta
rss_template = ('<?xml version="1.0" encoding="UTF-8"?>'
'<rss version="2.0">'
' <channel>'
' <title><![CDATA[AWS Service Status]]></title>'
' <link>http://status.aws.amazon.com/</link>'
' <description><![CDATA[AWS Service Status]]></description>'
' </channel>'
'</rss>'
)
item_template = ('<item>'
' <title></title>'
' <link>http://status.aws.amazon.com/</link>'
' <pubDate></pubDate>'
' <guid isPermaLink="false"></guid>'
' <description></description>'
' <category></category>'
'</item>')
def lambda_handler(event, context):
soup = BeautifulSoup(rss_template, 'xml')
r = requests.get('https://status.aws.amazon.com/data.json')
json = r.json()
JST = timezone(timedelta(hours=+9), 'JST')
for item in json['archive']:
title = item['summary']
pubDate = item['date']
pubDate = datetime.fromtimestamp(int(item['date']),JST).strftime('%a, %d %b %Y %H:%M:%S %Z')
guid = item['service'] + item['date']
description = item['description']
category = item['service_name']
item = BeautifulSoup(item_template, 'xml')
item.title.append(title)
item.pubDate.append(pubDate)
item.guid.append(guid)
item.description.append(CData(description))
item.category.append(category)
soup.find('channel').append(item)
response = {
'statusCode': 200,
'isBase64Encoded': False,
'headers': {'Content-Type': 'text/xml;charset=UTF-8'},
'body': str(soup)
}
return response
Webサイトにもしてみました。
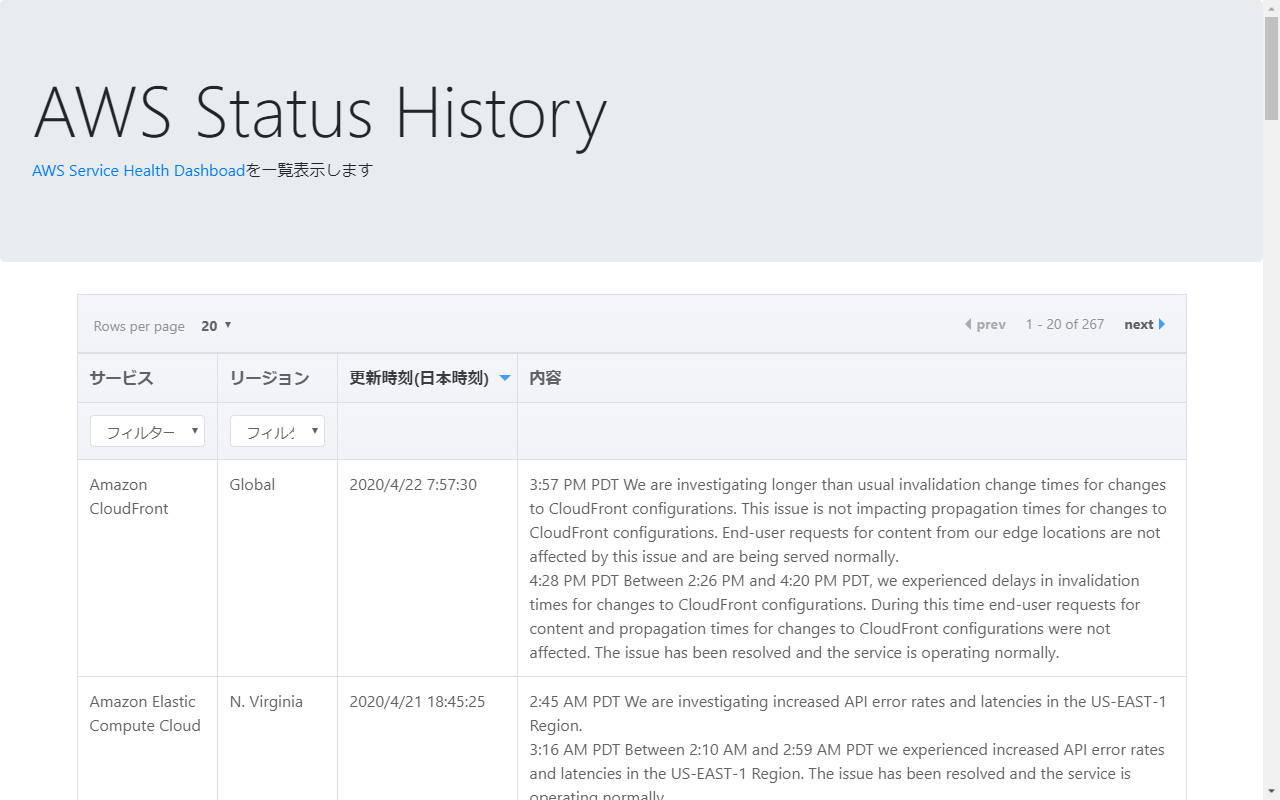
data.jsonを使って履歴を確認するWebサイトにしてみました。
4/20の東京リージョンの障害のあとにもバージニアのEC2、4/22のCloudFrontにも障害があったようです。
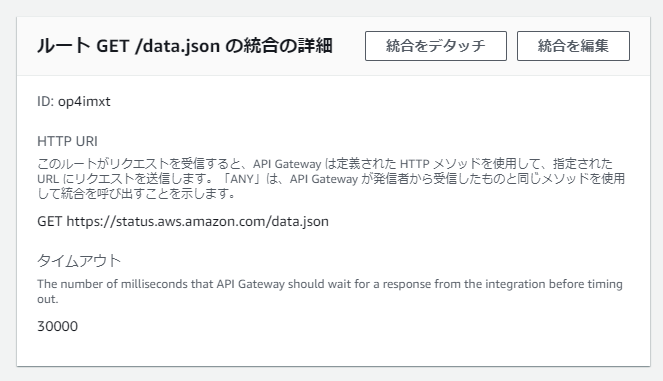
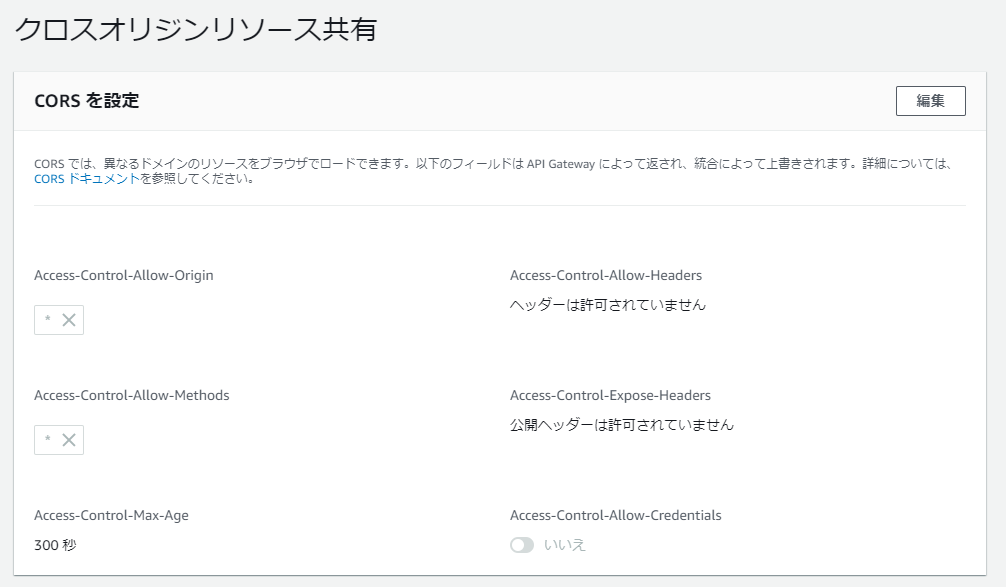
JSONを取得して整形しているだけですが、data.jsonの取得はCORSに引っかかるため、API GatewayのHTTP APIにてCORSを有効にしたHTTP プロキシ統合を作って回避しました。