目的
SQLでカプランマイヤー推定量を計算します。
カプランマイヤー推定量とは、ざっくりいうと時間の経過に伴うイベントの非発生確率を表すものです。医療統計で主に使われる値で、時間経過に伴う患者の死亡確率や治癒確率を求めるために使われますが、機械の故障確率や、ゲームアプリにおけるユーザーの離脱率、SaaSにおける顧客の解約率などの算出にも同様に適用できます。
観測が最後まで完了したデータだけでなく、観測が最後まで完了していないデータ(「打ち切り」と呼びます)も情報源として利用した確率を表すことができます。すなわち、最新時点でまだ故障していない機械やまだ解約していない顧客のデータを、故障確率や解約確率の分析に組み込める(=精度が上がる)という利点があります。
統計学の一分野で、生存時間解析と呼ばれる領域の基本的な概念です。
カプランマイヤー推定量の詳しい説明や計算式は、以下のページなどを参考にしてください。
- https://istat.co.jp/sk_commentary/kaplan_meier
- https://www.jstage.jst.go.jp/article/dds/30/5/30_474/_pdf
なぜSQLで計算するのか
SASのような統計ソフトウェアでは昔から計算・描画可能でした。最近であればPythonであればlifelines, Rであればsurvivalのようなライブラリがあります。より専門的な計算を行いたい場合は、SQLではなくそういったツールを利用するべきでしょう。
ではなぜわざわざSQLでカプランマイヤー推定量を算出するかというと、MetabaseのようなBIツールで動的に計算結果を表示できるようにしたいからです。
MetabaseのSQLパラメータ機能と組み合わせることにより、動的に集計対象を変えて生存曲線を描画できます。統計やプログラムの知識がない人でも、任意の条件での生存率を一瞬で確認できるようになります。Metabaseのような基本無償の製品でここまでの統計計算を実現できるのはかなり嬉しいです。
またSQLで実装してみることにより、カプランマイヤー推定量についての数学的理解が深まります。また実装にあたってそこそこ複雑なSQLを書く必要があり、一般的なWebやアプリの開発ではまず触らないようなSQLの機能を学ぶことができます。
実装
環境
- SQLはPostgreSQL 11.2で動作確認しています。
- グラフは、SQLの出力結果をMetabase 0.32.10で描画したものです。
PythonのlifelinesからwaltonsのデータセットをSQLに取り込んでサンプルデータとして使用します。
https://github.com/CamDavidsonPilon/lifelines/blob/master/lifelines/datasets/waltons_dataset.csv
データ構造
t0という名前のテーブルに、以下のようなレイアウトでデータが入っているという前提で進めます。
CREATE TABLE t0 ("観測期間" INTEGER, "イベント発生" BOOLEAN);
SELECT * FROM t0;
| 観測期間 | イベント発生 |
|---|---|
| 5 | TRUE |
| 8 | FALSE |
| ... | ... |
機械の故障を例にして説明すると、
1行目は、稼働開始から5日目に機械が故障した、ということを表します。
2行目は、稼働開始から8日目まで機械は故障せず、その後の状況は不明である、ということを表します。このようなデータを「(右側)打ち切り」と呼びます。例えば、機械が紛失した場合もそうですが、よくあるのは、その8日目というのは今日現在であって、9日目=明日という未来の情報はまだ得られていない、という場合です。
"観測期間"はこの例では日数ですが、用途に応じて時間、月、年などに読み替えてください。
集計したい元データが最初からこの形式になっているということはまずないと思います。実際にMetabaseなどで扱う場合には、WITHやJOINやCASE文などを駆使して元データをこのレイアウトに変換し、以降で解説する後続のクエリに渡すといいと思います。
バージョン1 - 累積生存率の計算
まずは生存関数 S(t)のみを計算する例です。
計算にあたってはWITH句をフル活用し、テーブルを何段階も変換しながら計算を進めていきます。Webエンジニア風に説明すると、二次元配列をメソッドチェーンで引き回しながら計算しているイメージです。
以下では可読性を重視して3段階のテーブルを使っていますが、より少ないテーブル数で記述することも可能です。
SQLだけだと何をしているかイメージがつきにくいので、途中の計算結果を適宜
SELECT * FROM 内容を確認したいテーブル名;
で確認しながら実装を進めていくことをお勧めします。
WITH
/* t1 各時点ごとのリスク集合数、観測終了数、イベント発生数 */
t1 AS (
SELECT "時点t",
SUM(COUNT("観測期間")) OVER(ORDER BY "時点t" DESC) AS "リスク集合数",
COUNT("観測期間") AS "観測終了数",
COALESCE(SUM("イベント発生"::integer), 0) AS "イベント発生数"
FROM t0
/*
イベント発生も打ち切りも発生していない時点を描画するため、GENERATE_SERIESで
整数列を生成しRIGHT JOINする。それらの点が不要であれば省略可能。
*/
RIGHT JOIN (
SELECT *
FROM GENERATE_SERIES(
0,
(SELECT MAX("観測期間") FROM t0)
) AS "時点t"
) "s" ON "時点t" = "観測期間"
GROUP BY "時点t"
ORDER BY "時点t"
)
/* t2 区間生存率の算出 */
,t2 AS (
SELECT "時点t",
"リスク集合数",
"観測終了数",
"イベント発生数",
CASE
WHEN "リスク集合数" = 0 THEN NULL
ELSE 1 - ("イベント発生数" / "リスク集合数")::double precision
END AS "区間生存率"
FROM t1
ORDER BY "時点t"
)
/* t3 累積生存率の算出 */
,t3 AS (
SELECT "時点t",
"リスク集合数",
"イベント発生数",
"観測終了数" - "イベント発生数" AS "打ち切り数",
1 - "区間生存率" AS "イベント発生率",
/*
区間生存率の総積を求める。
SQLにはSUM(n)のようなPRODUCT(n)関数が存在しないため、
EXP(SUM(LN(n)))で代用する。
*/
CASE
WHEN "区間生存率" = 0 THEN 0
WHEN "区間生存率" IS NULL THEN NULL
ELSE EXP(
SUM(
CASE
WHEN "区間生存率" > 0 THEN LN("区間生存率")
ELSE NULL
END
) OVER(ORDER BY "時点t")
)
END AS "累積生存率"
FROM t2
ORDER BY "時点t"
)
SELECT * FROM t3;
時点tでの累積生存率S(t)は、時点tまでの区間生存率の総積です。これが総和であればウィンドウ関数 SUM() OVER() が使えるのですが、標準SQLには総積を返す集約関数 PRODUCT() が存在しません。そこで EXP(SUM(LN(n))) で代用します。
※ EXP(LN(X)) = X 、LN(X*Y) = LN(X) + LN(Y) という数学的性質から、 EXP(SUM(LN(n))) で総積が求まることが分かります。
これにウィンドウ関数を適用すると EXP(SUM(LN(n)) OVER()) という形になります。ただし LN() に0を渡すとエラーになるため、CASE文で場合分けをする必要があります。またnが負の数になってもダメですが、区間生存率は0以上1以下の値しか取らないため、カプランマイヤー推定量を計算する上では問題ありません。
出力結果は以下のようになります。

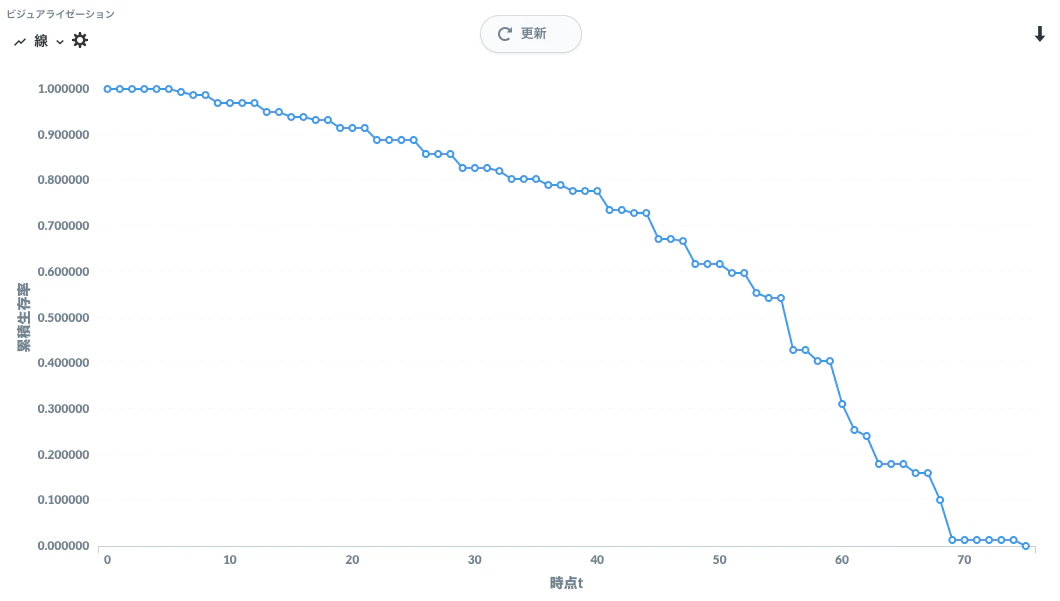
バージョン2 - 信頼区間の計算
次に、累積生存率のみでなく信頼区間も同時に算出する例です。
今回はlog-log法(二重対数生存関数)による信頼区間を算出します。Pythonのlifelinesでも信頼区間の算出に同じ方法を使っており、一般的な方法のようです。
以下ではt1〜t5の5段階のテーブルを使っていますが、より少ないテーブル数で書くことももちろん可能です。
また、有意水準αを動的に指定できるように t_sd というテーブルも追加しています。
{{alpha}} の部分はMetabaseのSQLパラメータの記法です。Metabaseを使わない場合は任意の値(例えば0.05)に置換してください。
WITH
t_sd AS (
/*
正規分布のパーセント点の近似値を返す。
0.10 => 1.65, 0.05 => 1.96, 0.01 => 2.58 くらいを返す。
参考:
http://nakano-tomofumi.hatenablog.com/entry/2018/01/19/130717
https://www.jstage.jst.go.jp/article/jappstat1971/22/1/22_1_13/_article/-char/ja/
*/
SELECT SQRT(
-LN(4.0 * (1 - {{alpha}} / 2.0) * ({{alpha}} / 2.0)) * (2.0611786 - 5.7262204 / (
-LN(4.0 * (1 - {{alpha}} / 2.0) * ({{alpha}} / 2.0)) + 11.640595))
) AS "z"
)
/* t1 各時点ごとのリスク集合数、観測終了数、イベント発生数 */
,t1 AS (
SELECT "時点t",
SUM(COUNT("観測期間")) OVER(ORDER BY "時点t" DESC) AS "リスク集合数",
COUNT("観測期間") AS "観測終了数",
COALESCE(SUM("イベント発生"::integer), 0) AS "イベント発生数"
FROM t0
/*
イベント発生も打ち切りも発生していない時点を描画するため、GENERATE_SERIESで
整数列を生成しRIGHT JOINする。それらの点が不要であれば省略可能。
*/
RIGHT JOIN (
SELECT *
FROM GENERATE_SERIES(
0,
(SELECT MAX("観測期間") FROM t0)
) AS "時点t"
) "s" ON "時点t" = "観測期間"
GROUP BY "時点t"
ORDER BY "時点t"
)
/* t2 区間生存率の算出 */
,t2 AS (
SELECT "時点t",
"リスク集合数",
"観測終了数",
"イベント発生数",
CASE
WHEN "リスク集合数" = 0 THEN NULL
ELSE 1 - ("イベント発生数" / "リスク集合数")::double precision
END AS "区間生存率",
CASE
WHEN "リスク集合数" = 0 OR "リスク集合数" = "イベント発生数" THEN NULL
ELSE "イベント発生数" / ("リスク集合数" * ("リスク集合数" - "イベント発生数"))::double precision
END AS "d/n(n-d)"
FROM t1
ORDER BY "時点t"
)
/* t3 累積生存率の算出 */
,t3 AS (
SELECT "時点t",
"リスク集合数",
"イベント発生数",
"観測終了数" - "イベント発生数" AS "打ち切り数",
1 - "区間生存率" AS "イベント発生率",
CASE
WHEN "区間生存率" = 0 THEN 0
WHEN "区間生存率" IS NULL THEN NULL
ELSE EXP(
SUM(
CASE
WHEN "区間生存率" > 0 THEN LN("区間生存率")
ELSE NULL
END
) OVER(ORDER BY "時点t")
)
END AS "累積生存率",
SUM("d/n(n-d)") OVER(ORDER BY "時点t") AS "SUM(d/n(n-d))"
FROM t2
ORDER BY "時点t"
)
/* t4 信頼区間の算出1 */
,t4 AS (
SELECT "時点t",
"リスク集合数",
"イベント発生数",
"打ち切り数",
"イベント発生率",
"累積生存率",
CASE
WHEN "累積生存率" IN (0, 1) THEN NULL
ELSE LN(-LN("累積生存率"))
END AS "LN(-LN(S(t))",
CASE
WHEN "累積生存率" IN (0, 1) THEN NULL
ELSE SQRT("SUM(d/n(n-d))") / LN("累積生存率")
END AS "SE(LN(-LN(S(t)))"
FROM t3
ORDER BY "時点t"
)
/* t5 信頼区間の算出2 */
,t5 AS (
SELECT "時点t",
"リスク集合数",
"イベント発生数",
"打ち切り数",
"イベント発生率",
"累積生存率",
CASE
WHEN "累積生存率" = 1 THEN 1
ELSE EXP(-EXP("LN(-LN(S(t))" - ("z" * "SE(LN(-LN(S(t)))")))
END AS "信頼区間上限",
CASE
WHEN "累積生存率" = 1 THEN 1
ELSE EXP(-EXP("LN(-LN(S(t))" + ("z" * "SE(LN(-LN(S(t)))")))
END AS "信頼区間下限"
FROM t4,
t_sd
ORDER BY "時点t"
)
SELECT * FROM t5;
zは正規分布の%点です。例えば95%信頼区間を得たい場合、zの値は約1.96になります。ここではMetabaseのSQLパラメータ機能を利用して任意のαを与えられるようにしています。
有意水準αから正規分布の%点を求めたいのですが、SQLにはそのための関数が無いため近似値を計算しています。専用の関数があるPythonやExcelと比べるとわずかながら誤差があるので、厳密な計算結果を得たい場合には向きません。
SEは標準誤差(Standard Error)です。元の生存関数S(t)に二重対数関数 LN(-LN()) で変換して標準誤差を加減したのち、二重指数関数 EXP(-EXP()) で元のスケールに復元するのがlog-log法(二重対数生存関数)です。
LN()には0を渡せないためCASE文で場合分けをする必要があります。また、LN(1) = 0のため、LN(-LN(1)) = LN(-0) で、これもエラーになります。よって累積生存率S(t)が0または1の場合にCASE文で特別対応をする必要があります。
出力結果は以下のようになります。
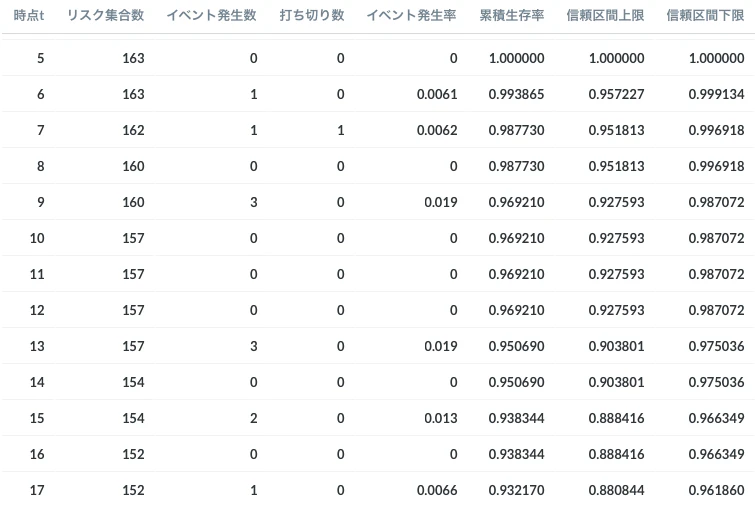

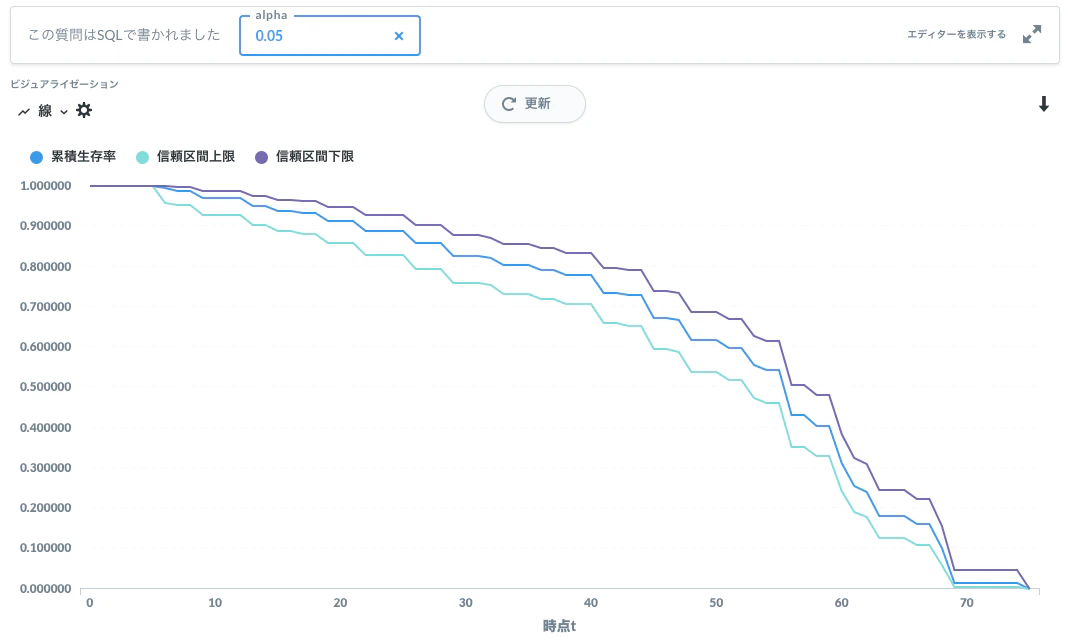
検算
かなり込み入ったSQLを書いているので、計算ミスが怖いところです。
Pythonのlifelinesで計算した結果と比較し、同じ結果であることを確かめてみます。
from lifelines import KaplanMeierFitter
from lifelines.datasets import load_waltons
df = load_waltons()
kmf = KaplanMeierFitter()
kmf.fit(df['T'], df['E'])
# 累積生存率
kmf.survival_function_

SQLでの計算結果と一致しています。
# 95%信頼区間
kmf.confidence_interval_
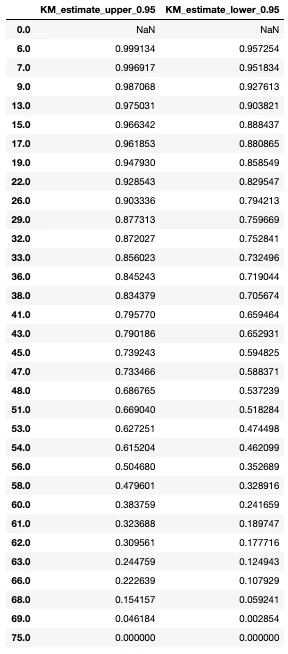
こちらもSQLでの計算結果と(ほぼ)一致しています。
参考文献
生存時間解析入門 [原書第2版]
https://www.amazon.co.jp/dp/4130623125/