Empowering News Recommendation with Pre-trained Language Models
published date: 15 April 2021,
authors: Chuhan Wu, Fangzhao Wu, Tao Qi, Yongfeng Huang
url(paper): https://arxiv.org/abs/2104.07413
(勉強会発表者: morinota)
どんなもの?
- Pre-trained Language Model(PLM, 事前学習済み言語モデル)をニュース推薦モデルに組み込むことで、浅い言語モデルよりもニュース記事の特徴をより有効に表現できて、オンラインニュースサービスの推薦性能とUXを効果的に改善できたという話。
- 単言語&多言語のニュース推薦データセットによるオフライン実験と、Microsoft Newsプラットフォームでのオンライン実験で本手法の有効性を評価している。
- 最近の複数のニュース推薦モデル(=記事のテキスト情報を使用する、Content-based filtering的な手法達)をベースラインとする。各ベースライン手法のNews Encoder部分をPLMに置き換える事でnews embeddingの品質が向上し、オフライン/オンライン実験で推薦性能を改善できた、との事。
- 個人的には、t-SNEを用いたnews embeddingの品質の評価実験(図5)に興味を持った! 推論結果のモニタリングに活用できないだろうか...!
 (booking.comが採用してた応答分布分析と同様に、教師ラベルに依存してない評価方法なので、推論直後に評価できるし...!! )
(booking.comが採用してた応答分布分析と同様に、教師ラベルに依存してない評価方法なので、推論直後に評価できるし...!! )
先行研究と比べて何がすごい?
- ニュース推薦において News Modeling (=i.e. 推薦アイテムの特徴を抽出する、って認識)は重要なステップ。
- -> 推薦候補の内容を理解する為の核となる技術。user-news interactionログデータからUser Modeling (=i.e. ユーザの興味を推測する為の特徴抽出)する為の前提条件だから。
- -> 推薦候補の内容を理解する為の核となる技術。user-news interactionログデータからUser Modeling (=i.e. ユーザの興味を推測する為の特徴抽出
- 通常、ニュース記事は豊富なテキスト情報を持っているので、news textのmodelingは、ニュース推薦の為のnews modelingの鍵。
- 既存のニュース推薦手法では、伝統的なNLPモデルに基づいてニューステキストをモデル化。
- CNN, attention, etc.
- でも浅いモデルでは、ニューステキストに含まれる深い意味情報を理解することは難しい。
- また既存手法では、ニュース推薦タスクの教師データのみを使って0からnews modelingしているので、テキストの意味情報を捉えて意味空間にembeddingを投影する点では最適ではないかも...!
- 一方で、**Pre-trained language models (PLMs, 事前学習済み言語モデル)**は、自己教師あり学習によって普遍的なテキスト情報のencodeを試みている。
- -> PLMは下流タスクでfine-tunignをする為のより良いinitial pointを提供する。
- また、PLMは膨大な数のパラメータを持つ、より深いモデル。
- ->PLMはニューステキストに含まれる複雑なcontextをモデル化する能力が高い可能性があり、ニュース推薦の為のnews text modelingを改善し得るはず...!
- 本論文では、PLMを使ってnews text modelingし各ニュース推薦タスクに合わせてそれらをfine-tuningする事の有効性を調査した。(大規模なニュース推薦システムをPLMで強化する最初の取り組みらしい...!)
技術や手法の肝は?
- 本論文の手法の肝は、ニュース推薦の一般的なフレームワークにおけるnews encoderにPLMを組み込んでnews embeddingの品質を向上させた事
まずニュース推薦の一般的なフレームワーク
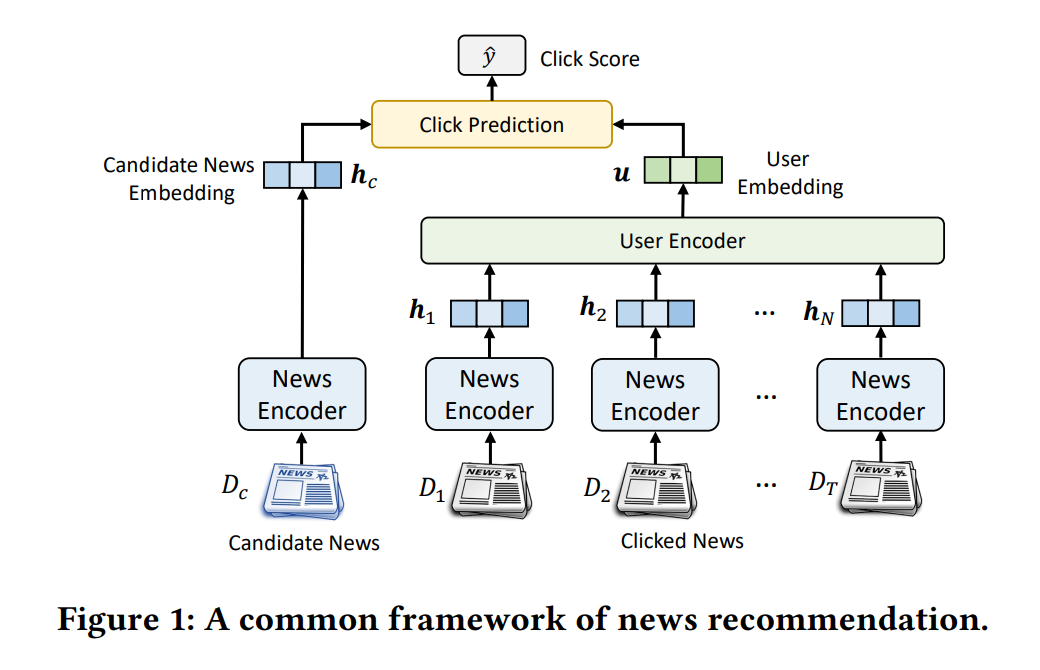
(論文より引用)
- 図1は、多くの既存手法で採用されるニュース推薦の一般的なフレームワーク
- news encoder:
- 役割 = news embeddingをテキストから学習してnews modelingする事。
- 成果物:
- ユーザが過去にinteractしたニュース $[D_1, D_2, \cdots, D_T]$ の news embedding $[\mathbf{h}_1, \mathbf{h}_2, \cdots, \mathbf{h}_T]$
- 各推薦候補ニュース $D_c$ のnews embedding $\mathbf{h}_{c}$
- user encoder:
- 役割 = news embeddingのinteraction sequence (or set)からuser embeddingを学習してuser modelingする事。
- 成果物:
- user embedding $\mathbf{u}$
- click prediction module:
- 役割 = user embeddingと推薦候補のnews embeddingの間の関連性に基づいて、おすすめニュースランキングを作る為のスコアを計算する。
- 成果物:
- ユーザとニュースのrelevance score $\hat{y}$
- 内積[15]、ニューラルネットワーク[20]、因数分解マシン[7]など、さまざまな方法で実装できる。(dot-product以外のclick prediction module気になる...!)
続いて提案手法: PLM Empowered なニュース推薦フレームワーク
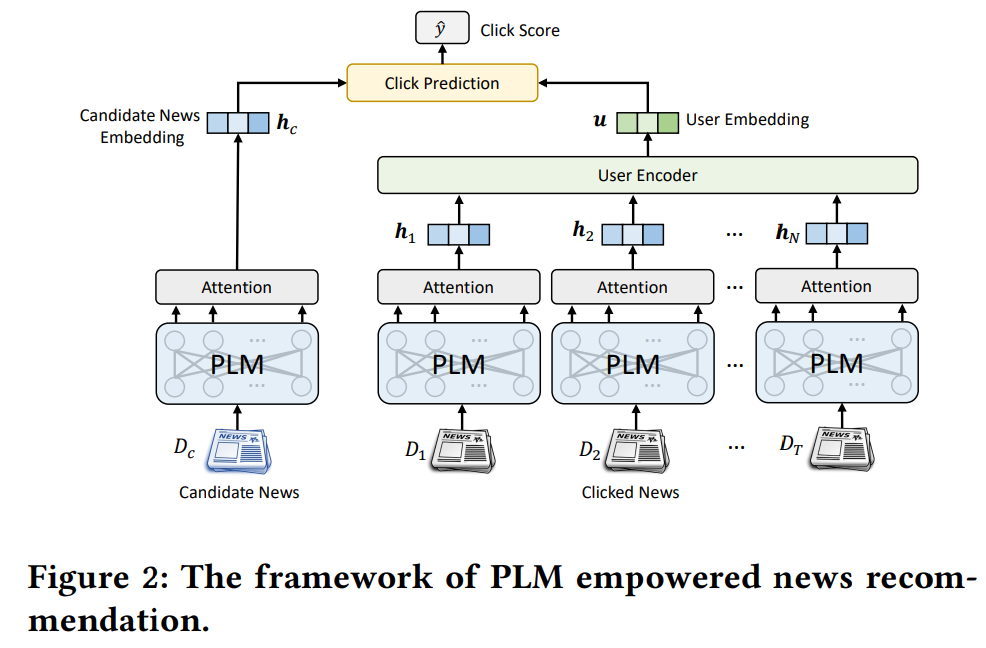
(論文より引用)
- 図2は、PLM Empowered なニュース推薦のフレームワーク。
- news encoderに、PLMとself-attentionネットワーク(たぶんmulti-head)を採用。
- PLMは、ニューステキストの深いcontextを捉える為。
- self-attentionネットワークは、PLMで出力される word embedding (ie. word hidden representation)達を集約してnews text embeddingを作る為という認識
- (この方法を採用した理由は実験セクションで後述されてた...!)
- (この方法を採用した理由は実験セクションで後述されてた...!
- PLMとself-attentionネットワークを持つnews encoderで得られたnews embeddingは、user encoderとclick prediction moduleで使用される。
PLM Empowered なニュース推薦フレームワークの学習
- negative sampling(=教師あり学習におけるnegative exampleを作る手法)を用いて生のニュースimpression (i.e. interaction?)ログから教師ラベル付きサンプルを作成する。
- どの候補のニュースがクリックされたかの分類問題を解かせる事で、モデルの学習にクロスエントロピー損失関数を用いる。(=next item prediction的なタスクを学習させる想定なのかな??)
- 逆誤差伝搬によって損失関数を最適化することで、推薦モデル(=news encoderのself-attentionネットワーク と user encoderと click prediction module) とPLMのパラメータをニュース推薦タスクに合わせてfine-tuningできる。
どうやって有効だと検証した?
- 大きく二種類の実験:
- 単言語及び多言語のニュース推薦データセットを用いたオフライン実験。
- microsoftのニュース機能でのオンライン実験。
オフライン実験の方法:
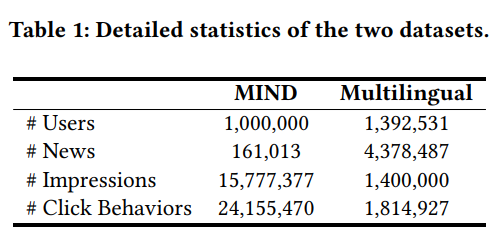
- データセットについて(表1):
- 単言語ニュース推薦データセット(MIND)
- 多言語ニュース推薦データセット(Multilingual)
- 直近1週間のログをtestに使用し、残りをtrainとvalidationに分割(9:1の割合)
- モデルの学習について:
- PLMは、基本的にbase versionを使用。
- ニュースのタイトルのみをnews modelingに使用。
- 最適化アルゴリズムにはAdam [3]を使用し、学習率は1e-5。
- 実験の評価指標:
- すべてのimpressionの平均AUC、MRR、NDCG@5、NDCG@10。
- 各実験を独立に5回繰り返し、その平均値を報告。
- ベースライン:
- 最近のニュース推薦手法達(EBNR [15], NAML [21], NPA [22], LSTUR [1], NRMS [23])
- ↑の手法達を、複数の種類のPLMで強化したvariant ver.(news encoderをPLMにしたver.)
オフライン実験の結果:
PLM有り vs PLM無しの推薦性能の比較結果
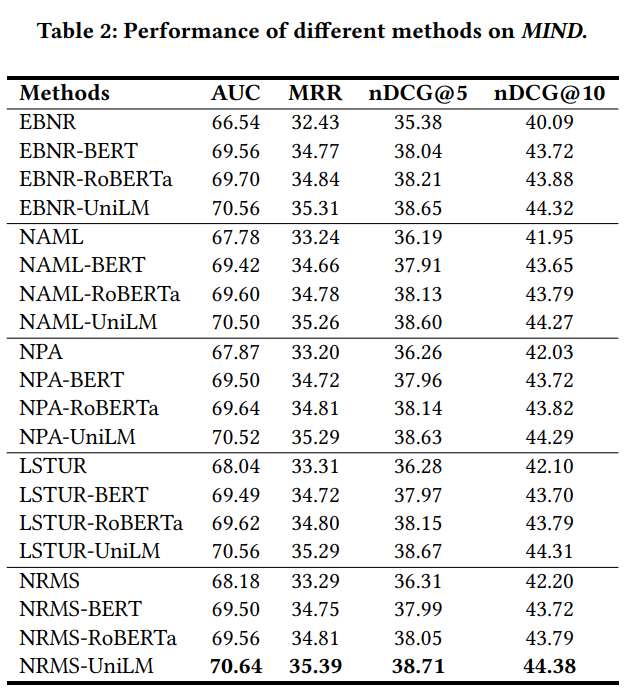
- 単言語データセットの結果(表2):
-
news encoderにPLMを組み込むことで、基本モデルの性能を一貫して向上できた。
- -> PLMがニュース推薦でゼロから学習された浅いモデルよりも強力なtext modeling能力を持つから?
-
news encoderにPLMを組み込むことで、基本モデルの性能を一貫して向上できた。
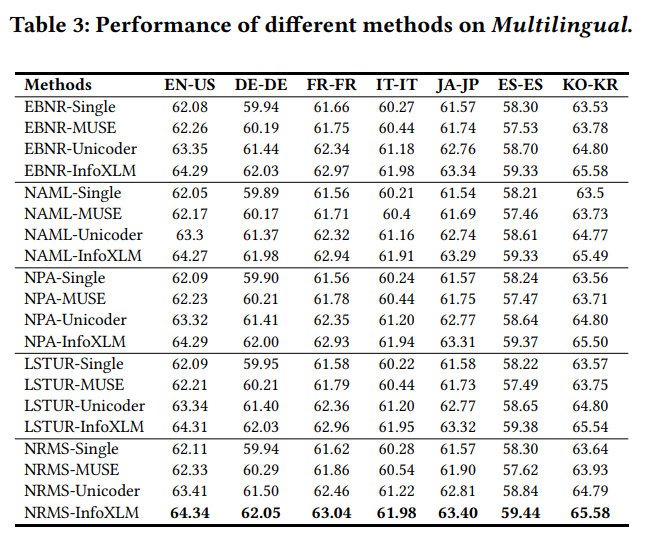
- 多言語データセットの結果(表3):
- 多言語モデルは、各言語のみのinteractionデータで学習された単言語モデルよりも優れた結果だった。
- 多言語データを用いてモデルを共同学習することで、より精度の高い推薦モデルを学習できる?? (interactionデータが増えたから??)
- また、異なるmarket(=異なる言語域)で統合された推薦モデルを使用することで、多様な言語(例えば、印欧語とアルタイ語)を使用するさまざまな国のユーザにサービスを提供できる可能性があり、オンライン・サービスの計算コストとメモリー・コストを大幅に削減できる。(各market毎に、言い換えれば異なるusecase毎に異なるモデルを運用するよりも...!)
- 多言語データを用いてモデルを共同学習することで、より精度の高い推薦モデルを学習できる?? (interactionデータが増えたから??
- 多言語PLMに基づく方法は、MUSE埋め込み(=単言語PLMだっけ?)に基づく方法よりも性能が良かった。
- これは、PLMが複雑な多言語の意味情報を捉える上で、単語埋め込みよりも強いからかもしれない。(MUSEがどんな手法なのか良くわかってない...!)
- これは、PLMが複雑な多言語の意味情報を捉える上で、単語埋め込みよりも強いからかもしれない。(MUSEがどんな手法なのか良くわかってない...!
- 多言語モデルは、各言語のみのinteractionデータで学習された単言語モデルよりも優れた結果だった。
PLMのサイズが推薦性能に与える影響
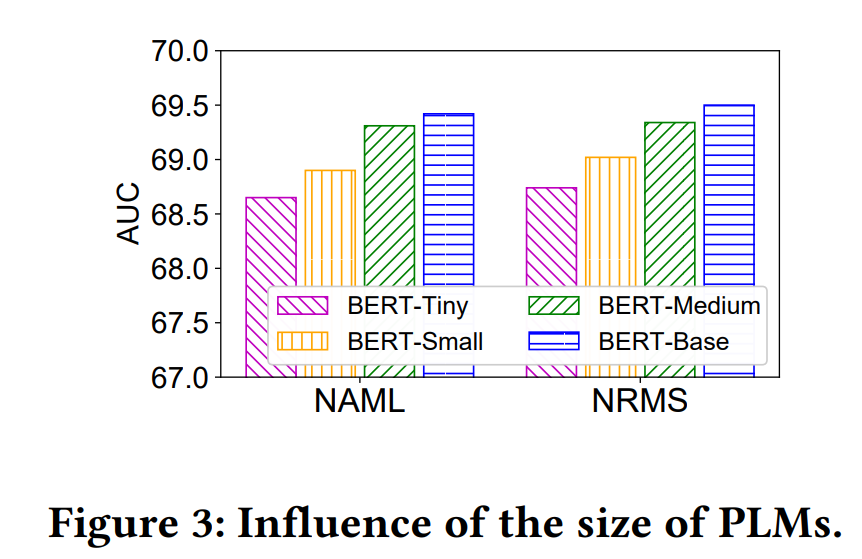
- PLMのサイズが推薦性能に与える影響の実験:
- BERT-Base(12層)、BERT-Medium(8層)、BERTSmall(4層)、および BERT-Tiny(2層)を含む BERT の様々なversionと、代表的な2つのニュース推薦手法(NAMLおよびNRMS)を組み合わせて、各性能を比較した。
- 結果(図3):
- 通常、より大きなPLMとより多くのパラメータを使用することで、より良い推薦性能が得られる。
- これは通常、大型のPLMの方が、ニュースの深い意味情報を捕捉する能力が高いためであり、より巨大な PLM(BERT-Large等)を組み込めば、パフォーマンスがさらに向上する可能性がある
- しかし、巨大なPLMはオンラインアプリケーションには面倒なので、著者達はbase versionを採用。
- 通常、より大きなPLMとより多くのパラメータを使用することで、より良い推薦性能が得られる。
PLMによるNews EmbeddingのPooling方法の影響
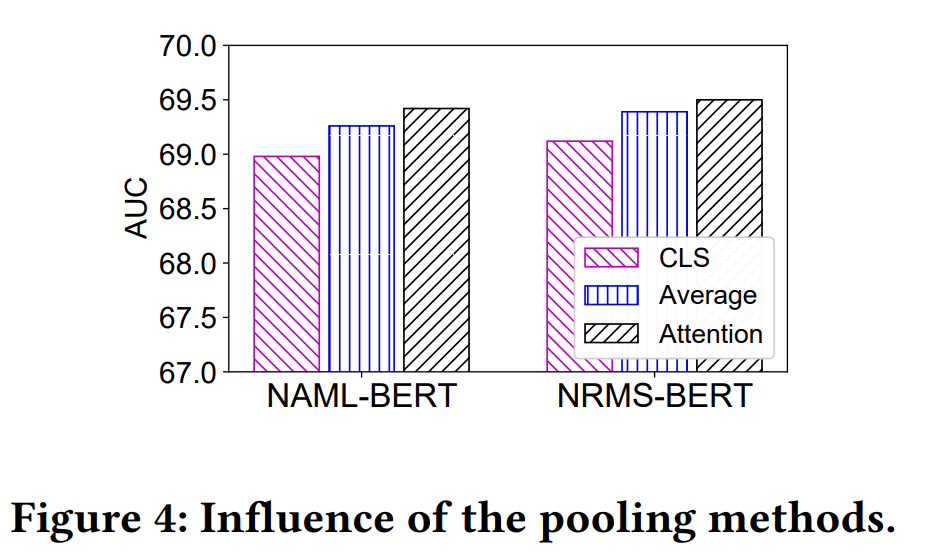
- 異なるpooling方法(=word embeddingをsentence embeddingに集約する方法)の影響の実験:
- PLMの隠れトークン表現のsequenceからニュースの埋め込みを学習するために、異なるプーリング方法を使用することも検討する。(最終的に本論文では、PLMの出力をattentionで集約するやつを採用してる)
- 以下の3つの方法を比較した:
- CLS: ニュース埋め込みとして"[CLS]"トークンの表現を用いる。これは、sentence embeddingを得るために広く使われている方法。(=PLMを使う方法として真っ先にこれを想像した!)
- Average: PLMのword embedding(i.e. hidden representation, hidden state)の平均を使用する方法。
- Attention: attention-networkを使って、word embeddingsからnews embeddingを学習する方法。
- CLS: ニュース埋め込みとして"[CLS]"トークンの表現を用いる。これは、sentence embeddingを得るために広く使われている方法。(=PLMを使う方法として真っ先にこれを想像した!
- PLMの隠れトークン表現のsequenceからニュースの埋め込みを学習するために、異なるプーリング方法を使用することも検討する。(最終的に本論文では、PLMの出力をattentionで集約するやつを採用してる
- 結果(図4):
- 興味深い事に、CLSが最悪のパフォーマンスをもたらした。
- Attentionはaverageを上回った。
- これは、self-attentionネットワークがhidden stateの情報性を区別することができ、より正確なニュース表現を学習するのに役立つからかも。
- 本実験の結果から、論文ではAttentionをpooling方法として採用。
PLMがnews embeddingの品質に与える影響
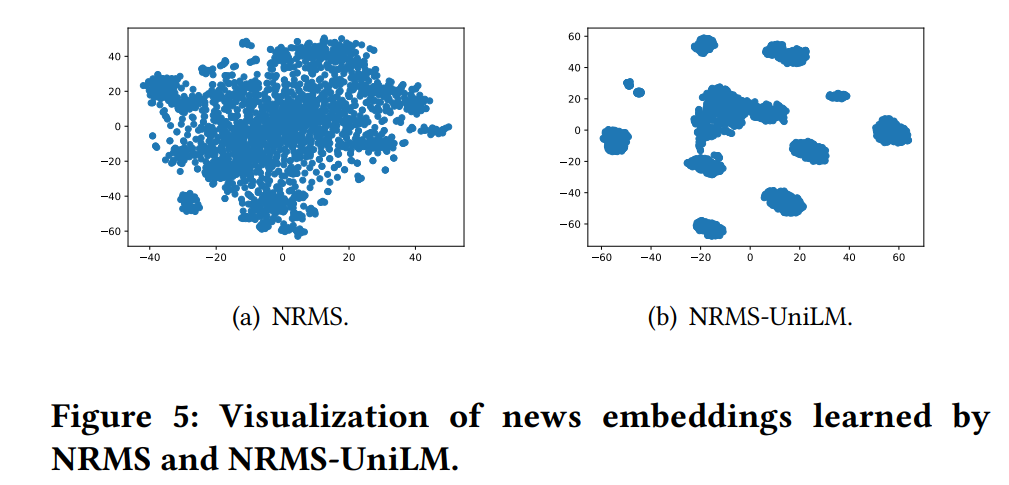
- PLMをnews encoderに使うver.と使わないver.のnews embeddingの品質の比較実験:
- NRMS(=PLM使わないver.)とNRMS-UniLM(=PLM使うver.)によって学習されたnews embeddingを可視化するためにt-SNE [17]を用いた。(t-SNEが気になる...!!)
- NRMS(=PLM使わないver.)とNRMS-UniLM(=PLM使うver.)によって学習されたnews embeddingを可視化するためにt-SNE [17]を用いた。(t-SNEが気になる...!!
- 結果(図5):
- NRMS-UniLMによって学習されたニュース埋め込みは、NRMSよりもはるかに識別性が高い。
- (=この埋め込みベクトルの識別性の高さの評価は、モデルの推論結果のモニタリングとか評価とかに良いかも...! booking.comが採用してた応答分布分析と同様に、教師ラベルに依存してない評価方法だし...!!)
- ユーザの興味はクリックされたニュースの埋め込みからも推測されるため、NRMSのはっきりと識別できてないニュース表現からユーザの興味を正確にモデル化することは難しい(user modelingはnews modelingの影響を強く受けるから...)
- (=この埋め込みベクトルの識別性の高さの評価は、モデルの推論結果のモニタリングとか評価とかに良いかも...! booking.comが採用してた応答分布分析と同様に、教師ラベルに依存してない評価方法だし...!!
- さらに、NRMS-UniLMによって学習されたニュース埋め込みは、いくつかの明確なクラスターを形成していた。
- これらの結果は、ディープPLMが浅いNLPモデルよりも識別的なテキスト表現を学習する能力が高いことを示しており、これは通常、正確なニュース推薦に有益である。(うんうん確かに...!)
- NRMS-UniLMによって学習されたニュース埋め込みは、NRMSよりもはるかに識別性が高い。
オンライン実験の結果:
- PLMを活用したニュース推薦モデルをMicrosoft Newsプラットフォームに導入した。
- 実験1: NAML-UniLMモデルを、英語圏市場のユーザに対して適用。
- 結果:
- PLMを使用しない従来のニュース推薦モデルに対して、クリック数で8.53%、ページビューで2.63%の改善を示した。
- 結果:
- 実験2: NAML-InfoXLMモデルを、言語の異なる他の43の市場のユーザに対して適用。
- 結果:
- クリック数で10.68%、ページビューで6.04%の改善を示した。
- 結果: