Text Is All You Need: Learning Language Representations for Sequential Recommendation
published date: 26 May 2023,
authors: Jiacheng Li, Ming Wang, Jin Li, Jinmiao Fu, Xin Shen, Jingbo Shang, Julian McAuley
url(paper): https://arxiv.org/abs/2305.13731
(勉強会発表者: morinota)
どんなもの?
- KDD'23に採択されたAmazonの論文。読んだモチベーションは、twitterで流れきた事とタイトルに惹かれた事。
- ID-Freeでコールドスタートアイテムに強く、かつcross-domainに適用可能なsequential推薦モデル Recformer の提案を目的とした論文。
- Recformerの重要な特徴は、ID-freeでアイテムをテキストとして扱う点と、言語表現(i.e. 単語の埋め込みベクトル)とsequential推薦タスクを共同学習させる点。
- Amazonでのレビューデータセットによるオフラインでの実験にて、fine-tuning有りの推薦性能、zero-short(=fine-tuningなし)での推薦性能、コールドスタートアイテムに対する推薦性能で、他のsequential推薦手法よりもRecformerが優れた結果を出した。
- (本手法に限らず、やっぱりID-freeな推薦モデルの方が良いよなぁ...。コールドスタート問題への対応もそうだけど、学習を回すコストの観点からもbetterな気がする...
 )
) - (逆に、ID-basedな手法を有効活用するには、ID-basedな手法が強みを発揮する問題設定にしてあげるというか、得意なusecaseに適用する事が大事なのかも...!)
先行研究と比べて何がすごい?
Sequential推薦システムって?
- Sequential推薦システムは、過去のuser-itemのinteractionを時間的に順序付けられたsequenceとしてモデル化し、ユーザにアイテムを推薦する。(next-token-predictionならぬ、next-item-predictionタスク)
- Sequential推薦の利点は、ユーザの短期的嗜好と長期的嗜好の両方を捉える事ができること。
- Sequential推薦の既存研究では、マルコフ連鎖モデル[9, 25] -> RNN/CNNモデル[11, 17, 28, 34] -> self-attention型モデル[14, 19, 27]の順で、様々な手法が提案されてる。
Sequential推薦の既存手法の多くは、ID-basedな手法でありtransferable(移行可能)でない。
- 基本的にはID-basedな手法(もちろんいくつかの手法では、itemのcontextを特徴量としてID embeddingに組み込んでいる。)
- コールドスタートアイテムの理解や、**モデルを学習した後に異なる推薦シナリオに適用するcross-domain推薦(??)**の実施に難がある。
- アイテム固有のIDは、コールドスタートアイテムや新しいデータセットのトレーニングデータからモデルが移行可能な知識を学習することを妨げる。
- 結果として、アイテムIDはコールドスタートアイテムに対する逐次レコメンダーの性能を制限し、継続的に追加される新しいアイテムに対して逐次レコメンダーを再トレーニングしなければならない。
transferableな推薦システムは、cold-start itemや、cross domain推薦においても利益をもたらす。
- 最近の研究[7, 12]では、知識の効果的なcross-domain transferを行うために、異なるドメインで共通の知識を得るために自然言語テキスト(ex. タイトル、アイテムの説明文)の一般性を活用し、有効な性能を出している。
- 基本的な考え方: BERT [6]のような事前に訓練された言語モデルを採用してテキスト表現を取得し、テキスト表現からsequential推薦用のアイテム表現への変換を学習する。
しかし、言語からアイテムへの変換を学習するアプローチには、いくつかの限界がある:
- (1) 事前学習済みの言語モデルは、通常、一般的な言語corpus(ex. Wikipedia)で学習され、推薦タスク用のテキスト情報とは異なる言語domainの自然言語タスクに適している。
- (ex. 推薦タスク用のテキスト情報=本論文の手法のケースでは、item's attributeの連結)
- よって、事前学習済み言語モデルによるアイテムのテキスト表現は、通常、推薦タスクにおいて最適ではない。
- (2) 事前学習済みの言語モデルから得られるテキスト表現は、粗い粒度(文レベル)のテキスト特徴を提供するだけで、推薦のための細かい粒度(単語レベル)のユーザの好み(ex. 服の推薦のために最近のインタラクションで同じ色を見つける)を学習することができない。
- (3)事前学習済みの言語モデル(ex. 言語理解タスク)と変換モデル(ex. 推薦タスク)はindependent training。
- joint trainingできたほうが推薦タスクの為の言語理解モデルとして性能良くなるよね...!!
本論文の提案手法 Recformer は、言語理解タスクと推薦タスクのアプローチを統合、ID-freeのsequential推薦モデル。
基本的な考え方は、言語理解と逐次推薦のjoint trainingを通じて、言語モデルの汎用性を利用しtransferableな推薦システムを作る事。
技術や手法の肝は?
モデルの入力情報にitem_idを含めない
テキストとitem idの両方を入力データとして使用する既存研究のsequential推薦モデルとは異なり、recformerではsequential推薦にテキストのみを使用する。
- sequential推薦の問題設定では、アイテム集合 $I$ とユーザのinteraction sequence $s = {i_1, i_2, \cdots, i_n}$ が時間順に与えられ、$s$ に基づいてnext itemを予測する。
- $s$ 内の各 interacted item $i$ は、既存手法では一意のitem idと関連付けられるが、Recformerではその代わりに、属性辞書(attribute dictionary) $D_i$ と関連付けられる。
- $D_i$ は key-value型の属性情報 ${(k_1, v_1), (k_2, v_2), \cdots, (k_m, v_m)}$ を含む。
- ここで $k$ はあるattribute名(ex. Color), $v$ は対応する値(ex. Black)。
-
$k$ と $v$ は共に自然言語で記述され、単語のsequence $(k, v) = {w_1^{k}, \cdots, w_c^{k}, w_1^{v}, \cdots, w_c^{v}}$ を含む。
- ここで $w^{k}$ と $w^{v}$ は言語モデルの共有語彙(shared vocabulary)にある $k$ と $v$ の各単語、$c$ はテキストの切り捨て(truncated)長さ。
- アイテム $i$ の属性辞書 $D_i$ には、タイトル、説明文、色など、あらゆる種類のアイテムのテキスト情報を含めることができる。
- 図2で示す様に、$D_i$ を言語モデルに投入する為に、key-value attribute ペア達を $T_{i} = {k_1, v_1, k_2, v_2, \cdots, k_m, v_m}$ の様に平滑化して、**入力データとして item "sentence" $T_{i}$**を得る。
- $D_i$ は key-value型の属性情報 ${(k_1, v_1), (k_2, v_2), \cdots, (k_m, v_m)}$ を含む。
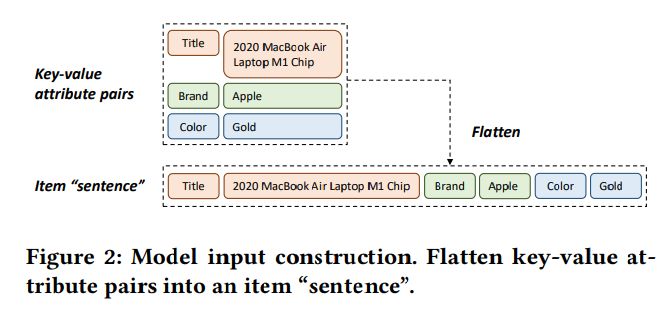
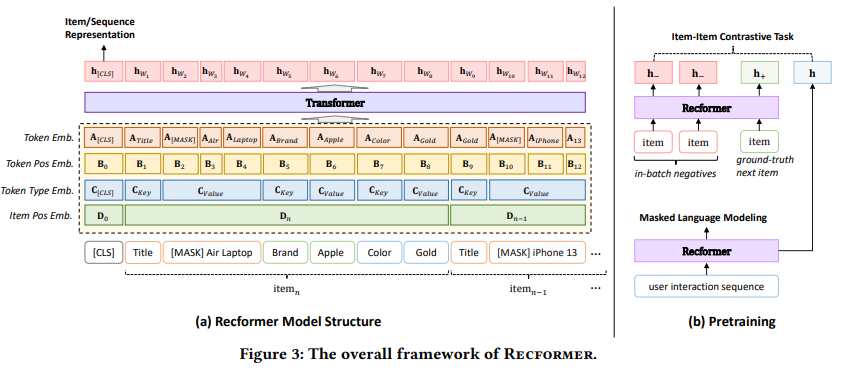
Recformer のモデルアーキテクチャ
図3(a)はRecformerのアーキテクチャ。Longformer(Long Document Transformer)[2]と同様の構造を持ち、多層双方向トランスフォーマー[30]を採用し、配列の長さに応じて線形にスケールする(=計算量が??)アテンションメカニズムを持つ。Longformerだけでなく他の双方向Transformer構造にも適用可能。
モデルの入力:
- ユーザのinteraction sequence $s = {i_{1}, i_{2}, \cdots, i_{n}}$ をモデル入力用にencodeする為に、まずsequenceのアイテムを ${i_{n},i_{n-1}, \cdots, $i_{1}}$ に逆変換する。
- これは直感的に最近のアイテム (i.e.$, i_n, i_{n-1}, \cdots$) の方が次のアイテム予測に重要であり、sequence逆変換により最近のアイテムが入力データに確実に含まれる様にしたいから。
- (i.e. sequenceを指定した最大長でtruncateするので、最新のinteractionが切れない様したいから!)
- 続いて、$s$ 内のアイテム $i$ を対応する item sequence $T_{i}$ で置換する。
- 最後にsequenceの先頭に特別なトークン[CLS]を追加する。
したがって、モデルの入力は次のように表記される:
$$
X = {[CLS], T_n, T_{n-1}, \cdots, T_{1}}
\tag{1}
$$
ここで $X$ は、過去のinteraction sequence $s$ の中でユーザがinteractしたすべてのアイテムに対応する属性辞書 を含む単語達 $T_{i}$ のsequence(=sequence of sequences) である。(各 $T_{i}$ を平滑化して、sentence of wordsになる、という認識![]() )
)
$X$ は後述する埋め込み層に入力される。
4種類の埋め込み層
Recformerの目標は、言語理解と推薦のsequentialパターンの両面からモデル入力 $X$ を理解すること。
本手法での重要なアイデアは、言語モデルとself-attention型seuquential推薦モデルの埋め込み層を組み合わせること。
その為にRecformerは、以下の4種の埋め込みを含む:
(ちなみに最終的なTransformerへの入力は、4種の埋め込みベクトルのlayer Normalization後の和になる。)
-
トークン埋め込みベクトル(Token embedding):
- 各単語tokenの意味を表現する。
- 言語モデル由来の埋め込み。
- $A \in \mathbb{R}^{V_w \times d}$
- ここで、$V_w$ はvocabularyに登録されている単語数、$d$ は埋め込み次元。
- $A$ のサイズはアイテム数に依らない。
-
トークン位置埋め込みベクトル(Token position embedding):
- sequence内のトークンの位置を表現する。
- これも言語モデル由来の埋め込み。
- $B_{i} \in \mathbb{R}^{d}$
- 通常のTransformer論文と同様に、tokenの連続パターンを理解するのを助ける為の埋め込み。
-
トークンタイプ埋め込みベクトル(Token type embedding):
- 各tokenの種類を表現する。
- この埋め込みベクトルは、Recformerの入力データの形状ゆえに必要!
- 具体的には、token type embedding は、3つのベクトル $C_{[CLS]}, C_{Key}, C_{Value} \in \mathbb{R}^{d}$ を含み、tokenがそれぞれ[CLS]、属性key、属性valueのどれかを表す。
-
アイテム位置埋め込みベクトル(Item position embedding):
- interaction sequence内のアイテムの位置を表現する。
- sequential推薦モデル由来の埋め込み。
- sequence $X$ の $k$ 番目のアイテムの属性からの単語は、$D_{k} \in \mathbb{R}^{d}$ と $D \in \mathbb{n \times d}$ として表現される ($n$ はユーザのinteraction sequence $s$ の最大長)。
入力sequence $X$ から各単語token $w$ が与えられると、token $w$ の埋め込みベクトルは、4つの異なるembeggings の和のLayer Normalizationとして計算される:
(ここでのword $w$ は、itemを意味するのではなく、あるitemの"item sentence" $T_i$ に含まれる一つの単語、という認識![]() )
)
\mathbf{E}_{w} = LayerNorm(\mathbf{A}_{w} + \mathbf{B}_{w} + \mathbf{C}_{w} + \mathbf{D}_{w})
\tag{2}
ここで、$\mathbf{E}{w} \in \mathbb{R}^{d}$。
よってモデル入力 $X$ の埋め込みベクトルは、$\mathbf{E}{w}$ のsequenceになる:
\mathbf{E}_{X} = [E_{[CLS]}, E_{w_1}, \cdots, E_{w_l}]
\tag{3}
ここで、$\mathbf{E}_{X} \in \mathbb{R}^{(l+1) \times d}$ であり、$l$ はユーザのinteraction sequence におけるtokenの最大長。($s$ の最大長ではなく、$X$ の最大長である点に注意...! $+1$ は[CLS]の意味。)
Transfomerに通して、アイテム表現またはSequence表現を得る。
$E_{X}$ を符号化するために、双方向トランスフォーマー構造Longformer(Longformer = Long Document Transformer...!) をencoderとして採用する。(Longformerだけでなく他の双方向Transformer構造にも適用可能。)
$X$ は通常長いsequenceなので、Longformerのlocal windowed attention(=対象tokenのすぐ近くのtoken達に対するattention weightのみを保持するattention pattern。)は、$E_{x}$ を効率的にencodeするのに役立つ。
特別なトークン[CLS]はグローバルなattentionを持たせるが、他のトークンはlocal windowed attentionを使う。
よって、Recformerは以下の様な $l+1$ 個の $d$ 次元の単語token表現 $\mathbf{h}_{w}$ を計算する:
[\mathbf{h}_{[CLS]}, \mathbf{h}_{w_1}, \cdots, \mathbf{h}_{w_l}]
= Longformer([E_{[CLS]}, E_{w_1}, \cdots, E_{w_l}])
\tag{4}
ここで $\mathbf{h}_{w} \in \mathbb{R}^{d}$ である。
言語モデルが[CLS]のtoken表現をsentence表現として使用するのと同様に、最初のトークン[CLS]の表現 $\mathbf{h}_{[CLS]}$ がFsequence表現として使用される。
また、Recformerでは、アイテムの埋め込みテーブルを保持しない。(RecformerはID-freeなモデルだから...!![]() )
)
その代わりに、各アイテムを「interaction sequence $s$ にitemが一つしか無い」特別なケースとみなす。
よってRecformerのアイテム表現は、各アイテム $i$ について、そのitem sequence $T_i$ を構成し、$X = {[CLS],T_i}$ をモデル入力として、そのsequence表現 $h_{[CLS]}$ をアイテム表現 $\mathbf{h}_{i}$ として取得する。
Recformerの推論
ユーザのinteraction sequence $s$ のsequence表現 $\mathbf{h}{s}$ と、アイテム $i$ のアイテム表現 $\mathbf{h}{i}$ のcosine similarityに基づいてnext-itemを予測する。
具体的には以下の様にスコアを計算する:
r_{i, s} = \frac{\mathbf{h}_{i}^T \mathbf{h}_{s}}{|\mathbf{h}_{i}| \cdot |\mathbf{h}_{s}|}
\tag{5}
ここで、$r_{i, s} \in \mathbb{R}$ は、$s$ が与えられたとき、item $i$ がnext itemであることのrelevance(関連度合い)である。
next-item predictionの為に、itemセット $I$ のすべてのitemについて relevance を計算し、最も高い relevance を持つitemをnext-item $\hat{i}_{s}$ として選択する:
\hat{i}_{s} = argmax_{i \in I} (r_{i, s})
\tag{6}
Recformerの学習: 事前学習と2段階のfine-tuning
sequential推薦のための効果的で効率的な言語モデルを得る為に、論文では、事前学習と2段階のfine-tuningを含む学習手法を提案している。
事前学習:
- 目的: 下流タスクの為の高品質なパラメータ初期値を得る事。
- 注意点: 推薦のみを考慮した従来のsequential推薦の事前学習とは異なり、言語理解と推薦の両方を考慮した事前学習タスクである必要がある。
- Recformerでは2つの事前学習タスクを採用した: Masked Language Modeling(MLM) と Item-Item Contrastive(IIC)
-
Masked Language Modeling(MLM):
- NLPの事前学習タスクとして一般的らしい。(たぶんBERTのmasked-token predictionタスクと同義)
- BERT論文の方法に従い、訓練データはtokenの15%を予測用にランダムに選択。選択されたtokenを、(1)80%の確率で[MASK]、(2) 10%の確率でランダムなtoken、(3) 10%の確率で変更前のtokenに置き換える。
- NLPの事前学習タスクとして一般的らしい。(たぶんBERTのmasked-token predictionタスクと同義
- **Item-Item Contrastive(IIC)**タスク:
- sequential推薦で一般的に使われる事前学習タスク(=next-item-predictionタスクそのもの??)
- 有名なself-attention型sequential推薦の先行研究達に従い、ground-truthであるnext-itemをpositive exampleとして使用する。
- negative exampleについては、in-batch next itemsを採用する。
- in-batch next-items = 同じbatch内の他のtraining examplesのground truthの事。false negativeになる可能性はあるが、事前学習データセットのサイズが大きければ可能性は低いからOK!との事。(それに、正確な学習はfine-tuningで行うからOK!との事。)
- sequential推薦で一般的に使われる事前学習タスク(=next-item-predictionタスクそのもの??
-
Masked Language Modeling(MLM):
- なお事前学習では、multi-task学習戦略を用いてRecformerを共同最適化する。
以下は、事前学習タスクの1つ目=MLMの損失関数:
$$
\mathbf{m} = LayerNorm(GELU(\mathbf{W}_h \mathbf{h}_w + \mathbf{b}_h))
\tag{7}
$$
$$
p = Softmax(\mathbf{W}_0 \mathbf{m} + \mathbf{b}_0)
\tag{8}
$$
$$
L_{MLM} = - \sum_{i=0}^{|V|} y_{i} \log(p_{i})
\tag{9}
$$
ここで、$\mathbf{W}_h \in \mathbb{R}^{d \times d}$, $\mathbf{b}_h \in \mathbb{R}^{d}$ , $\mathbf{W}_0 \in \mathbb{R}^{|V| \times d}$, $\mathbf{b}_0 \in \mathbb{R}^{|V|}$ である。
$GELU$ はGELU活性化関数(し、知らない...!![]() )。
)。
$V$ は言語モデルで使用されるvocabulary。
また、以下は、事前学習タスクの2つ目=IICの損失関数:
$$
L_{IIC} = - \log \frac{
e^{sim(h_s, h_{i}^{+}) / \tau}
}{
\sum_{i \in \mathcal{B}} e^{sim(h_s, h_{i}) / \tau}
}
\tag{10}
$$
ここで、 $sim$ は式(5)で導入された類似度。
$h_{i}^{+}$ はground-truthのnext-item表現。
$\mathcal{B}$ は1 batch内で設定された ground-truth item集合。
$\tau$ はtemperatureパラメータ(=softmax関数の??)。
そして以下は、multi-task学習戦略でRecformerを共同最適化する為の損失関数:
$$
L_{pre-training} = L_{IIC} + \lambda L_{MLM}
\tag{11}
$$
ここで、$\lambda$ はMLMタスクlossの重みを制御するハイパーパラメータ。
事前学習されたモデルは、新しい各usecaseの為にfine-tuningされる。
fine-tuning:
- fine-tuningでは、IICタスクによってRecformerのパラメータを更新する。
- (タスク自体は事前学習と同じなんだ...!)
- 事前学習のIICタスクと異なる点: negative exampleの作り方!
- 事前学習では、in-batch negative手法を採用した。しかし、これはデータサイズが大きいことが前提とした手法であり、fine-tuning用の小さなデータセットでは偽陽性が発生しやすくなってしまうのでイマイチ。
- よってfine-tuningでは、fully softmax手法(=negative exampleを得る為の別の手法??)を採用している。
- (タスク自体は事前学習と同じなんだ...!
fine-tuningにおけるIICタスクの損失関数は以下:
L_{fine-tuning} = - \log \frac{e^{sim(\mathbf{h}_s, \mathbf{I}_{i}^{+}) / \tau}}{\sum_{i \in \mathcal{I}} e^{sim(\mathbf{h}_s, \mathbf{I}_{i}) / \tau}}
\tag{12}
ここで、$\mathbf{I}{i}$ はitem $i$ のitem featureである。(Recformerによってencodeされたアイテム表現 $\mathbf{h}{i}$ という認識であってる?![]() )
)
fine-tuningでは、以下の図のような2段階のfine-tuningを提案している。
(ただ2段階にしてる理由が良く理解できてない。fine-tuning時の推論コストを下げる為なのかな![]() in-batch negative手法だとそんなに推論コストを樹にする必要がなかったけど、fully softmax手法だとそこが問題になってくる、みたいな??
in-batch negative手法だとそんなに推論コストを樹にする必要がなかったけど、fully softmax手法だとそこが問題になってくる、みたいな??![]() )
)

- この2段階のfine-tuningの重要なアイデアは、item featureg行列 $\mathbf{I} \in \mathbb{R}^{|I| \times d}$ を維持する事。
- アイテム埋め込みテーブルとは異なり、item featureg行列 $\mathbf{I}$ は学習可能ではなく、すべてのitem featureはRecformerからencode(i.e. 推論と言っても良い)される。(item featureって $\mathbf{h}_{i}$ の事だよね?)
- 1段階目では $\mathbf{I}$ はepochごとに更新される(4行目)。
- しかし2段階目では、$\mathbf{I}$ を凍結し、Recformerモデルのパラメータ $M$ のみを更新する。
- アイテム埋め込みテーブルとは異なり、item featureg行列 $\mathbf{I}$ は学習可能ではなく、すべてのitem featureはRecformerからencode(i.e. 推論と言っても良い
- 基本的な考え方は、モデルはすでに事前学習されているが、事前学習されたモデルから得られるitem表現は、下流のデータセットでさらに訓練することで改善できるということ。(??)
- batchごとに全itemを再encodeするのはコストがかかるので(うんうん、わかる)、epochごとに全itemを再encodeして $\mathbf{I}$ を更新し(4行目)、$\mathbf{I}$ をitem-item contrastive学習のsupervision(=教師ラベル的な意味??)として使用する(5行目)
- (supervisionって何?)
- (supervisionって何?
- batchごとに全itemを再encodeするのはコストがかかるので(うんうん、わかる
-
最適なアイテム表現が得られたら、対応するパラメータでモデルを再初期化し(12行目)、2段階目を開始する。
- すでに1段階目で更新を繰り返しているので、fine-tuningのためのsupervision(=教師ラベル?)も変わってきている。
- この場合、bestな性能を持つようにモデルを最適化するのは難しい。(supervision=正解がその都度変わるから??)
- そこで、$\mathbf{I}$ を凍結し、検証データセットで最高の性能を達成するまでモデルの訓練を続ける。
どうやって有効だと検証した?
実験方法
オンライン実験ではなく、オフラインデータセットを用いた評価のみだった。
データの準備:
- Amazonレビューデータセットの異なるカテゴリに対して事前学習とfine-tuningが行われた。
- 事前学習:
- 学習データ = 「自動車」「携帯電話・アクセサリー」「衣類・靴・宝飾品」「電子機器」「食料品・グルメ食品」「家庭・台所」「映画・テレビ」の7カテゴリ
- 検証データ = 「CD・レコード」の1カテゴリ
- 計8カテゴリをsource domain datasetsとする。
- fine-tuning:
- 「工業・科学」「楽器」「美術・工芸・裁縫」「オフィス用品」「ビデオゲーム」「ペット用品」の6つのカテゴリーをtarget domain datasetsとする。
- データセットに対して、ユーザ毎にinteractionをグループ化し、タイムスタンプの昇順でソート (=sequentialデータを作成)
- 先行研究(?)に従い、アイテムのタイトル、カテゴリ、ブランドの属性をアイテムのkey-valueペアとして選択。
以下の3つのグループをベースラインとして比較:
- (1) ID-Only methods: アイテムIDのみを使用する方法
- GRU4Rec [11], SASRec [14], BERT4Rec [27], RecGURU [16]
- (2) ID-Text methods: アイテムIDを使用しアイテムテキストを補足情報として扱う方法
- FDSA [37], S3-Rec [38]
- (3) Text-Only methods: アイテムテキストのみを入力として使用する方法。
- ZESRec [7], UniSRec [12], Recformer(提案手法)
モデル性能の評価方法:
- NDCG@N、Recall@N、MRRの3つを採用。
- fine-tuningデータセットを学習用と評価用に分割する方法: leave-one-out戦略
- つまり、interaction sequenceの中で最も新しいitemが評価用に、2番目に新しいitemがvalidation用に、そして残りのデータが学習用。(なるほど、わかりやすい...!)
- つまり、interaction sequenceの中で最も新しいitemが評価用に、2番目に新しいitemがvalidation用に、そして残りのデータが学習用。(なるほど、わかりやすい...!
- 各sequenceのground-truthアイテムを全アイテムの中でランク付けして評価し、テストデータに含まれる全sequenceの平均スコアを報告。
ベストな状態でのsequential推薦の性能
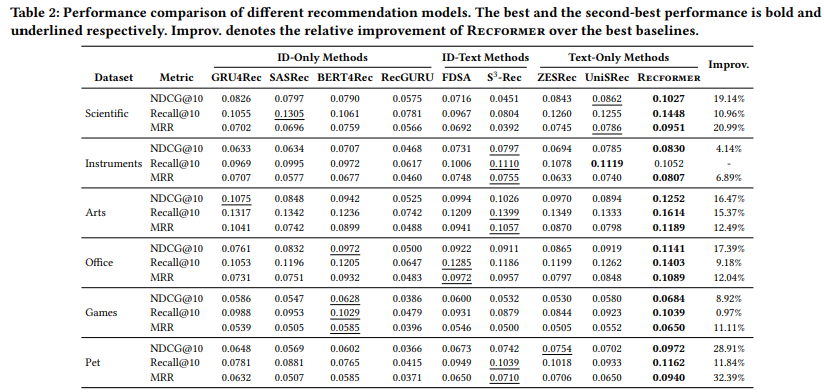
- 表2の結果:
- 一般的にID-Text法は、ID-Only法やText-Only法よりも良い結果を達成する。
- ID-Text法は、アイテムIDとコンテンツ特徴量の両方を含むため、コンテンツベースの情報と、fine-tuningによるsequentialパターンの両方を学習できる。
- ID-Only法やText-Only法を比較すると、「科学」「機器」「ペット」のデータセットではText-Only法が優勢。
- これらのdomainではsequentialパターンとアイテムのテキスト(タイトルやブランドなど)との関連性が高い。
- 提案手法Recformerは、「機器」のRecall@10を除く全てのデータセットで最高の総合性能を達成した。NDCG@10を15.83%改善し、MRRを15.99%改善した。
- ベースライン手法達と異なり、Recformerは事前学習した言語モデルやアイテムIDを使わずに、sequential推薦のための言語表現を学習する
- 2段階のfine-tuningによりRecformerは下流タスクのdomainに効果的に適応することができ、事前学習から伝達された知識は下流タスクに一貫して役立つ
- 一般的にID-Text法は、ID-Only法やText-Only法よりも良い結果を達成する。
zero-shotでの性能
Recformerの言語モデルタスクとsequential推薦タスクの共同の事前学習の有効性を示すために、3つのText-Only手法(UniSRec、ZESRec、Recformer)のzero-shot(=fine-tuningなし!)での推薦性能と、下流データセットで学習された3つのID-Only手法の推薦性能を比較。
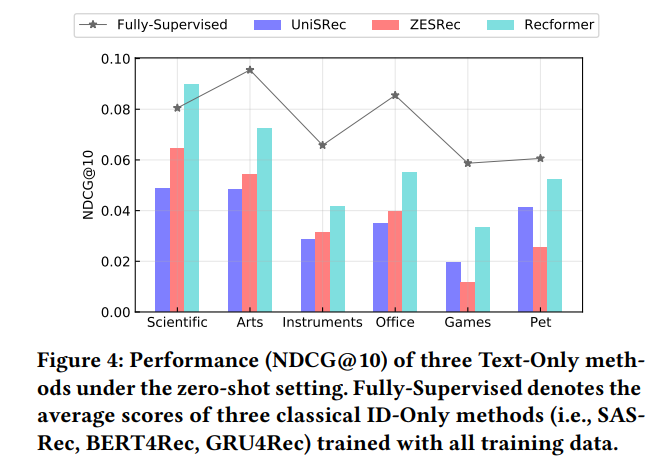
- 結果:
- 6つのデータセットにおいて、Recformerは他のText-only手法と比較してzero-shot推薦の性能を向上させた。
- 一部のデータセットでは、Recformerは、下流データセットで学習された3つのID-Only手法の平均性能よりも優れていた。
- 解釈:
- (1)自然言語が様々な推薦シナリオに渡る一般的なitem表現として有望
- (2)Recformerは事前学習から知識を効果的に学習し、学習した知識を言語理解に基づいて下流のタスクに転送できる。
学習データが少ない場合での性能
SASRec(ID-Only手法)、UniSRec(Text-Only手法)、Recformer(提案手法)を使った実験を低リソース環境(=学習データが少ない時にどうなるかの話!![]() )で行った。
)で行った。
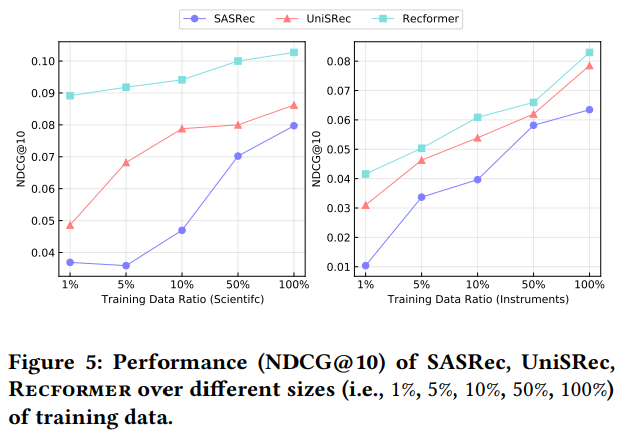
- 結果:
- 特に学習データが少ない場合、アイテムテキストを含む方法(すなわちUniSRecとRecformer)がID-Only手法(SASRec)を上回る。一方で、学習データが増えると、ID-Only手法(SASRec)は急速に性能を向上させることができた。
- (IDベースの手法はどうしても、学習データが少ないというか、sparse性が高いケースでは力を発揮しずらいのかな。ただ後述の様に、sparse性が下がってくると急激に効果が上がる感じ??評価行列のsparse性を下げる様に、ユーザ & アイテムを調整したら、ID-Onlyの手法でももっと高品質なembeddingを作れるだろうか...??)
- (IDベースの手法はどうしても、学習データが少ないというか、sparse性が高いケースでは力を発揮しずらいのかな。ただ後述の様に、sparse性が下がってくると急激に効果が上がる感じ??評価行列のsparse性を下げる様に、ユーザ & アイテムを調整したら、ID-Onlyの手法でももっと高品質なembeddingを作れるだろうか...??
- Recformerは、学習データが少なくても最高の性能を発揮した。
- 一部のデータセットでは、Recformerは1%と5%の学習データ(=下流タスクのデータがめっちゃ少ない状況)で他の手法に大きな差をつけた。
- 特に学習データが少ない場合、アイテムテキストを含む方法(すなわちUniSRecとRecformer)がID-Only手法(SASRec)を上回る。一方で、学習データが増えると、ID-Only手法(SASRec)は急速に性能を向上させることができた。
コールドスタートアイテムへの対応力
- データセットを2つに分割した実験: in-setデータセットとcold-startデータセット。
- in-setデータセットでは全てのテストitemが学習データに現れる
- cold-startデータセットでは全てのテストitemが学習データに現れない。
- in-setデータセットでモデルを学習し、in-setデータセットとcold-startデータセットの両方でテストする。
- SASRec(ID-Only手法)、UniSRec(Text-Only手法のベースライン)、Recformer(提案手法)を比較。
- UniSRecでは、コールドスタートitemはitemテキストで表現され、BERTで符号化される
- Recformerは、コールドスタートのアイテムを表現するために、アイテムのテキストを直接encodeする。
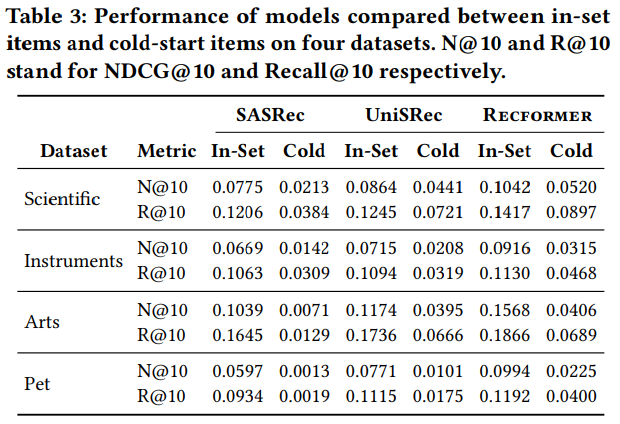
- 結果:
- 特にサイズの大きいデータセットではText-Only手法がID-Only手法を大きく上回る。
- ID-Only手法の性能は、インセットitemsと比較してコールドスタートitemsで大きく低下する。(そりゃそうだよなぁ...)
- ->IDのみの方法ではコールドスタートのアイテムを扱うことができず、テキストを適用することが有望な方向性である
- RecformerはUniSRecと比較して、インセットとコールドスタートの両方のデータセットでパフォーマンスを大幅に向上させる。
- これは、推薦のためのテキスト特徴量を得るよりも、言語表現を学習する方が優れていることを示している。
- (学習済みのテキストembeddingを単に特徴量として使うよりも、推薦モデルの一部として言語表現を学習させる方がよりrichで効果的な表現になる、ってこと??)
議論はある?
次に読むべき論文は?
- Text-Only手法のベースライン(UniSRec, ZESRec)
お気持ち実装
2段階のfine-tuningをお気持ち実装した。
from dataclasses import dataclass
from typing import Any
import numpy as np
@dataclass
class ItemFeatureTable:
array: np.ndarray
d: int
I_length: int
@dataclass
class RecformerParams:
params: np.ndarray
@dataclass
class Item:
item_sequence: list[str] # T_{i}
class TwoStageFinetune:
def __init__(self, epoch_num: int) -> None:
self.epoch_num = epoch_num
pass
def train(
self,
D_train,
D_valid,
items: set[Item],
M: RecformerParams,
) -> tuple[ItemFeatureTable, RecformerParams]:
p = 0.0 # metrics are initialized with 0
# stage1
for n in range(self.epoch_num):
I = self._encode(M, items)
M = self._train(M, I, D_train)
p_prime = self._evaluate(M, I, D_valid)
if p_prime > p:
M_prime, I_prime = M, I
p = p_prime
# stage2
M = M_prime
for n in range(self.epoch_num):
M = self._train(M, I_prime, D_train)
p_prime = self._evaluate(M, I_prime, D_valid)
if p_prime > p:
M_prime = M
p = p_prime
return M_prime, I_prime
def _encode(self, M: RecformerParams, items: set[Item]) -> ItemFeatureTable:
# Recformerで 各itemのアイテム表現 h_{i} を取得する(推論する)
pass
def _train(self, M: RecformerParams, I: ItemFeatureTable, D_train: Any) -> RecformerParams:
# item-item contractice(next-item prediction)タスクを学習させる
pass
def _evaluate(self, M: RecformerParams, I: ItemFeatureTable, D_valid: Any) -> float:
# 精度指標(損失関数の逆数?)を検証用データで算出?
pass