こんにちは、ソーシャル経済メディア「NewsPicks」のアルゴチームインターンの森田( @moritama7431 )です!
この記事は NewsPicks アドベントカレンダー 2023 の14日目の記事です。
昨日は高山周太郎さんによる『5000万件のDynamoDBテーブルをダウンタイム無しで移行した話』でした!
本日の記事は、ざっくりニュースメディアと推薦システムに関するお話です!少し具体的には、メディアのミッションによって"良い"ニュース推薦システムの性質が異なるかもしれなくて(パート1)、メディアに合った推薦システムをどのように選ぼうか(パート2)、という話になります。
先月の推薦システム勉強会 (資料はこちら)にて共有させてもらった内容 + 時間なくて喋れなかった内容をカジュアルに記事にまとめてみました!
なお、本記事の読者層としては、ニュースメディアに関わる方、もしくは推薦システムに関わる方を想定しています。パート2は推薦システムに関わる方向けの内容になります!
もし感想や疑問や指摘などコメントしたいことあれば、ぜひぜひ気軽に絵文字をつけて書いていただけたら嬉しいです! ![]()
ちなみに、n週連続推薦システム系 論文読んだシリーズの前回の記事はこちらでした:「31週目: (番外編) FTI Pipelines Architectureってなんだ? MLOps勉強会で推薦システム関連の発表を聞いて知らない用語を調べた」
本記事の目次は以下の通りです。
本記事の内容は、主に以下の論文を読んでいた際に個人的にNewsPicksでの活用可能性について思いを馳せた話になります...!
- RADio – Rank-Aware Divergence Metrics to Measure Normative Diversity in News Recommendations
- Recommenders with a Mission: Assessing Diversity in News Recommendations
はじめに
そもそも推薦システムってなんだっけ?
まず推薦システムって何なんでしたっけ?
パッと思いつくのは、Amazonで買い物をした時に出てくる「閲覧履歴に基づくおすすめ商品」や、Netflixで映画を見た時に出てくる「おすすめ作品」でしょうか。

(上画像は、自分のAmazonの「閲覧履歴に基づくおすすめ商品」の表示結果です。技術書読んでる感がありますね...!)
推薦システムの定義として、よく「推薦システム実践入門」の以下の記述が引用されてます。
複数の候補からユーザにとって価値のあるものを選び出し、意思決定を支援するシステム
いやー、素敵な定義ですね...!
ちなみに、この定義から考えると検索システムも広義の推薦システムに含まれる感じがしますね。検索システムと推薦システムの違いは、ユーザからのクエリ(検索語)をシステムが受け取るか否かだと思っていたのですが、近年の言語モデルの発展によって対話型の推薦システムみたいな話もあるので、徐々に両者の境界が無くなってきている印象もあるなぁ。
ニュースメディアにおける推薦システムの役割ってなんだっけ?
さて、推薦システムの定義がなんとなく定まったところで、ニュースメディアと推薦システムの関連について考えてみます。
参考文献3では、ニュース推薦システムの役割を以下のように定義しています。
ニュース推薦システムの仕事は、増え続けるオンライン情報をフィルタリングすること
要するに、メディア側が何も考えずに得た情報全てを垂れ流すと、ニュース・情報が多すぎてユーザが困ってしまうので、何らかの方法で良い感じにユーザに届く情報を絞り込みましょうってことでしょうか...!
そう考えると、アルゴリズムによってユーザの閲読履歴から表示記事をパーソナライズすることも、多くのユーザが読んでいる人気記事を表示することも、情報元が怪しいフェイクニュースを除外することも、編成記者の方が1面に載せる記事を選ぶことも、いずれも情報をフィルタリングしているわけなので、全てニュース推薦システムですね...!
ちなみに推薦システムの方法論の名前には、Collaborative filtering や Content-based filtering など〇〇フィルタリングという名前がちょくちょく出てくるんですよね。情報とかアイテムを絞り込む、選び出す、みたいなニュアンスでしょうか。推薦システムに機械学習を適用する際は、よくアイテムをユーザにとって価値のある順に並び替える「ランキング問題」として扱う印象が強いのですが、そういえば本来やりたいことは価値のある一部のアイテムをフィルタリングすることなんだよなぁ![]() 、って少ししみじみしました...!
、って少ししみじみしました...!
(パート1)メディアのミッションによって"良い"ニュース推薦システムって違うかも
さて、ここからが本記事のメインの話題になります。
ニュース推薦システムの役割が「情報をフィルタリングすること」だとすると、フィルタリングの方針ってニュースメディアがユーザに提供したいサービスや社会の中で果たしたいミッションによって異なるよね、という話です。
例えば、「我々のメディアは、とにかく正確な真実のニュースをユーザに届けたいんだ!」というフェイクニュース絶対殺すマン的なミッションを掲げるメディアの場合を考えてみましょう。この場合、望まれるフィルタリング方針は「フェイクニュースを検知し、信頼性の高いニュースを絞り込む」ことであり、それが実現できればそのメディアにとって"良い"ニュース推薦システムになるんじゃないでしょうか![]()
情報のフィルタリングの方針って色々あるよね:4種類のメディアモデル
参考文献3では、メディアのミッションや社会での役割について語る際によく使われる4種類のメディアモデルに焦点を当てて、それぞれのモデルにおいてニュース推薦がどうあるべきかを検討しています。
- 自由主義モデル(The Liberal model): コンテンツもスタイルも、ユーザの好みに合わせて提供する
- 参加主義モデル(The Participatory model): ユーザが社会で活動するために必要な共通認識を、各ユーザに分かりやすい形で提供する
- 議論主義モデル(The Deliberative model): 現在、社会的な議論の中心にあるトピックを選び、異なる意見や多様な視点を提供する
- 批判主義モデル(The Critical model): 少数派なコミュニティの意見や主張を積極的に提供する
上2つがパーソナライズされたフィルタリング方針(i.e. 推薦システム)。下2つが非パーソナライズのフィルタリング方針ですね。
(ちなみに論文中では、メディアモデル間に優劣はないよ、と強調されています)
自由主義モデル(The Liberal model)
1つ目の自由主義モデルは、ユーザが選択した特定の分野での専門性を高められるような情報を提供することを目的としています。
期待される推薦システムの性質(i.e. フィルタリングの方針)は、推薦するニュースのトピックも専門性も、ユーザの好みや能力に合わせてガンガンパーソナライズしていくことです。
例えば、AI関連のニュースをよく読みその専門性を高めていきたいユーザに対しては、AI関連でそのユーザの理解度に合致したニュースばかりをどんどんフィルタリングしていく様なイメージですね。基本的には世の中の多くのメディアがこの自由主義モデル的なニュース推薦システムを採用しているように思いますし、「ニュース推薦」という言葉を聞いて真っ先に思い浮かべるのもこれな気がしますね。
参加主義モデル(The Participatory model)
2つ目の参加主義モデルは、ユーザが社会で積極的に参加し活動できるように共通認識を提供することを目的としています。
期待される推薦システムの性質(i.e. フィルタリングの方針)は、ユーザが社会で活動するために必要な共通認識的な情報を、各ユーザに分かりやすい形で提供することです。
自由主義モデルも参加主義モデルもパーソナライズしたニュース推薦を必要とする点で共通していますが、推薦するニュースのトピックをパーソナライズすべきか否かが異なります。
参加主義モデルにおいて、異なるユーザに必ずしも同一のニュース記事を読ませる必要はありませんが、同一のトピックのニュース記事を読ませることは必要です。一方で、推薦するニュースの複雑さに関しては、その共通認識的なトピックに対するユーザの理解度に合わせてパーソナライズすることが求められます。
例えば、メディア側が「生成AI」というトピックを社会活動する上で必要な共通認識だと判断した場合を想像してみます。
この場合にニュース推薦システムに望まれる振る舞いとしては、普段「生成AI」に関する記事をよく読むユーザにもそうでないユーザにも、同じように「生成AI」のトピックに関するニュースを推薦します。そして、「生成AI」に対する理解度が低めのユーザに対しては「生成AI」に関する初心者向けのニュース記事を推薦し、「生成AI」に対する理解度が高いユーザに対しては「生成AI」に関してより専門的なニュース記事を推薦します。
議論主義モデル(The Deliberative model)
3つ目の議論主義モデルは、社会におけるさまざまな意見や価値観を提示し、共通の合意を得る、あるいは異なる価値観を受け入れられるような情報をユーザに提供することを目的としています。
期待される推薦システムの性質は、現在社会的な議論の中心となっているトピックに焦点を当てること、そのトピックの中で複数の視点や意見を提示することです。
例えば、メディア側が「気候変動と環境問題」を社会的な議論の中心となっているトピックであるとみなした場合、ニュース推薦システムに期待される振る舞いは、途上国側や先進国側の視点だったり、適応・緩和のための各種アプローチへのpositiveな意見とnegativeな意見だったり、特定の視点に偏らないように多様な情報を推薦記事に含めること、のような感じかなと思います。
(ちなみに自分は元々、都市環境学の分野にいたのですが、こういったトピックでは多様な視点を提供することは重要だよなぁと思ったりしてます...!)
批判主義モデル(The Critical model)
4つ目の批判主義モデルは、普段は届きづらい少数派なコミュニティの意見や主張を、ユーザに積極的に提供することを目的としています。
期待される推薦システムの性質は、多数派や社会的強者の視点からの情報に偏らず、少数派や社会的弱者の視点からの情報を積極的に提供することです。
例えば、「白人か否かの人種差別」や「富裕層と貧困層の格差」に関するトピックのニュースをユーザに提供したい場合、通常のオンライン情報は多くが多数派や社会的に力を持つ立場の人々の意見で占められています。しかし、この批判主義モデルでは、少数派だったり社会的な力が弱い方の視点を重視してユーザに提供する様な推薦システムが期待されます。
NewsPicksの場合はどんなニュース推薦が望ましいんだろう?
さて、メディアの社会における役割にいくつか種類があって、期待されるニュース推薦システムの性質もそれによって異なるよね、という考えが得られました。
ここでは、NewsPicksの場合について考えてみます。
NewsPicksのミッションとメディアモデル
NewsPicksのカンパニーミッションは「新しい視点を集めて、経済の未来をひらく」であり、「経済情報の力で、誰もがビジネスを楽しめる世界をつくる」という目的を持っています。
このミッションを踏まえると、必ずしも特定の一つのメディアモデルに当てはまるというよりは、複数のメディアモデルの要素を含んだ上でやっと達成できるようなミッションなのかもと思います。「新しい視点を集めて」みたいな観点は議論主義モデル的な要素だと思いますし、「経済の未来をひらく」だったり「ビジネスを楽しむ」ためには自由主義モデル的にユーザ自身の専門性を高められるような情報を提供していくことも重要だと思います。また、「誰もがビジネスを楽しめる」という観点では、参加主義モデル的に全ユーザに必要な共通認識的な情報を分かりやすい形で提供することも必要な気がします...!
じゃあどんな推薦システムを目指せば良いんだろ?
では、NewsPicksにおいて期待されるニュース推薦システムの性質はどんなものなんでしょう。時にはユーザの専門性に関わるトピックを推薦して、時には経済を楽しむのに必要な共通認識を各ユーザに分かりやすい形式で提供して、また時には特定の視点に偏らないように多様な情報を提供してあげる...。正直、とても単一のニュース推薦システムで全ての性質を満たすのは、困難に感じます。
しかし安心してください。現在のNewsPicksは、「今日のニュース」や「話題をまとめよみ」、「金融・経済」「ビジネス」などの各カテゴリセクション、「あなたへのおすすめ」など、コンテンツを表示するための複数のセクションが共存するようなUIを採用しています。個人的にはこのUIは、各セクションが異なる役割を担ってくれているような印象を持っていて、NewsPicksのミッションを達成するためには非常に重要なんじゃないかなと思っています。例えば「今日のニュース」や「話題をまとめよみ」は議論主義モデルの要素、各カテゴリセクションは参加主義モデルの要素、そして「あなたへのおすすめ」は自由主義モデルの要素を担っているような感じがします...!
またNewsPicksは、ニュースを選んで整理する「Curation」、オリジナル記事やオリジナル動画などの「Contents」、専門家からの「Comment」の3つの軸によるサービスを提供しているので、3つの軸もそれぞれ異なる役割を担ってくれているように思います。
というわけで、NewsPicksは複数のセクションが共存するようなUIを通じてニュース推薦システムに求められる性質をセクション毎に役割分担できたことで、より推薦システムの開発・改善の方向が明確になっているのかなと感じています:)
ちなみに自分は現在、各カテゴリセクションや「あなたへのおすすめ」の推薦システムの開発・運用・改善に関わっているので、それぞれ参加主義モデルと自由主義モデルで期待される性質を頭に留めつつ、システム改善に取り組めないかなと思ったりしました...!
(パート2)メディアに合った推薦システムをどのように選択しようかって話
さてここからは、主に推薦システムを開発する方向けの内容になります。
といっても、パーソナライズ推薦で採用する機械学習モデルそのものの話ではなく、metricsの話になります。
各メディアが求めるフィルタリング方針と合致した、"良い"ニュース推薦システムをどのように選ぼうか、みたいな話ですね。
主に RADioの論文を読んでの概要と、実務での活用可能性に思いを馳せた話になります。
多様性指標群 RADio
推薦システムの性能を評価する際にはrecallやprecision、NDCG等のaccuracy-basedな指標がよく用いられ、最近では多様性や新規性を考慮したbeyond-accuracy指標の分野も研究が進んでいます。
しかし、様々な分野で汎用的に使用可能な既存のbeyond-acurracy指標では、各メディアモデルに期待されるような推薦システムの性質を評価しづらいです。
論文では、4種類のメディアモデルが推薦システムに期待する性質から導出した、ニュース推薦システムの評価のための5つの多様性指標群 RADio (Rank-Aware Divergence metrics, ioはよく分からず...!![]() ) を提案しています。
) を提案しています。
- Calibration: 「推薦結果がユーザの好みとどの程度合っているか」を表す指標。
- Fragmentation:「共通したトピックの記事を提供できているか」を表す指標。
- Activation: 「推薦結果のactiveness(感情的な記事か, 理知的な記事か)の多様性」を表す指標。
- Representation: 「推薦結果の視点の多様性」を表す指標。
- Alternative Voices: 「推薦結果の意見の持ち主(Minority/Majority)の多様性」を表す指標。
RADioの全metricsに共通する性質は以下です。
- distance metric(同一性, 対称性, 三角形の不等式が成立する)。
- 2つの離散分布間のJS-Divergence。
- 値域が $[0; 1]$。(0に近いほど2つの分布の距離が近い)
- 異なる推薦モデル間や異なるmetric間で比較したやすい
- rank情報を持った離散分布に適用可能。(rank-awareな指標)
RADioは下の画像のように、推薦結果の分布と何かしら別の分布を比較して評価する様な指標になります。
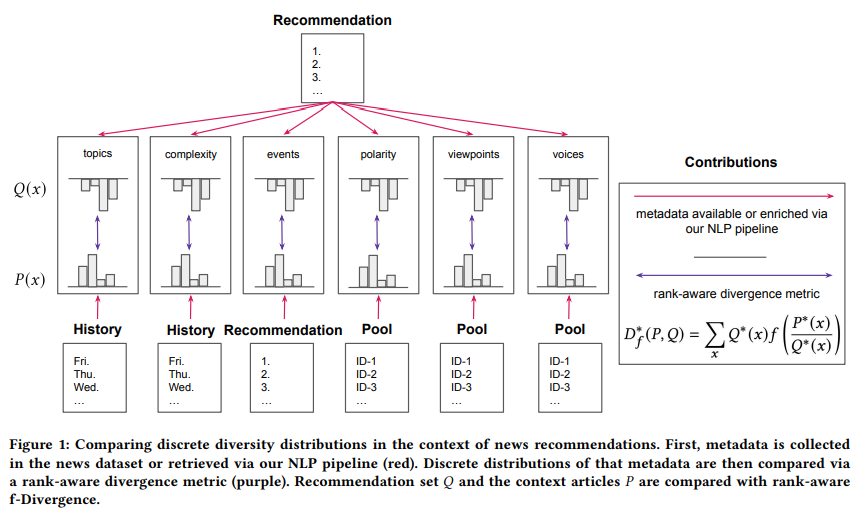
(論文より引用)
Calibration
「推薦記事がユーザの好みとどの程度合っているか」を反映したもので、推薦記事リストの分布とユーザの閲読履歴の分布のJSダイバージェンスを意味しています。
Calibration = D_{JS}(P^*(c|H), Q^*(c|R))
\\
= \sum_{c} Q^*(c|R) f(\frac{P^*(c|H)}{Q^*(c|R)})
ここで、$P$ と $Q$ は異なる2つの離散確率関数。添字 $*$ は、推薦記事の順位で重み付けされた確率関数である事を意味しています。(順位による重み付け方法は論文へ!) $H$ はあるユーザの閲読履歴の記事集合。$R$ は推薦モデルによって得られた推薦記事リスト。確率変数 $c$ は記事の属性情報(論文中では、記事のカテゴリやトピック、専門性のCalibrationを採用していました!)。
Fragmentation
「共通したトピックの記事を提供できているか」の度合いを反映したもので、複数ユーザの推薦記事リストの分布のJSダイバージェンスを意味します。
二人のユーザ $u$ と $v$ の推薦記事リストを比較して算出されます。
Fragmentation = D_{JS}(P^*(e|R^{u}), Q^*(e|R^{v}))
\\
= \sum_{e} Q^*(e|R^v) f(\frac{P^*(e|R^u)}{Q^*(e|R^v)})
ここで、$P$ と $Q$ は異なる2つの離散確率関数。添字 $*$ は 順位で重み付けされた確率関数である事を意味しています。 $R^{u}, R^{v}$ は、任意のユーザ $u$ と $v$ の推薦記事リスト。$e$ は記事のトピックを表す確率変数。
Activation
「肯定的な記事ばかり推薦してしまってないか、逆に否定的な記事ばかり推薦してしまってないか」の度合いを反映したものです。推薦可能な記事プール $S$ と、推薦記事リスト $R$ のactivation score(=positiveかnegativeか)の分布間のJSダイバージェンスを意味します。
Activation = D_{JS}(P(k|S), Q^*(k|R))
\\
= \sum_{k} Q^*(k|R) f(\frac{P(k|S)}{Q^*(k|R)})
ここで、$P$ と $Q$ は異なる2つの離散確率関数。添字 $*$ は、順位で重み付けされた確率関数である事を意味しています。 $k$ は記事のactivation score(=positiveかnegativeか)を表す離散変数 (論文ではテキストのsentiment analysisで得る事を想定していました!)。
Representation
「推薦結果の視点の多様性(ex. 政治的トピックや政党の言及など)」の度合いを反映したものです。
記事プール $S$ と、推薦記事リスト $R$ のviewpoint(離散値を想定) の分布間のJSダイバージェンスを意味します。
Representation = D_{JS}(P(p|S), Q^*(p|R))
\\
= \sum_{p} Q^*(p|R) f(\frac{P(p|S)}{Q^*(p|R)})
ここで、$P$ と $Q$ は異なる2つの離散確率関数。添字 $*$ は順位で重み付けされた確率関数を意味しています。 $p$ は記事のviewpointを表す離散変数。(具体的にどうやって記事のviewpointを表す属性情報を得るかはよく分かってない...!)
Alternative Voices
「意見の声の持ち主(Minority/Majority)の多様性」の度合いを反映したものです。
Representationは意見の中身の多様性であり、Alternative Voicesは意見の声の持ち主の多様性を表すという点で異なります。
(Minority/Majorityの例: 非白人/白人, 非男性/男性, etc.)
記事プール $S$ と、推薦記事リスト $R$ のviewpointの持ち主の分布間のJSダイバージェンスを意味します。
AlternativeVoices = D_{JS}(P(m|S), Q^*(m|R))
\\
= \sum_{m} Q^*(m|R) f(\frac{P(m|S)}{Q^*(m|R)})
ここで、$P$ と $Q$ は異なる2つの離散確率関数。添字 $*$ は順位で重み付けされた確率関数を意味しています。 $m$ は記事の意見の持ち主を表す離散変数。
メディアモデルとRADioの関係
各メディアモデルとRADioの関係は以下の通りです。
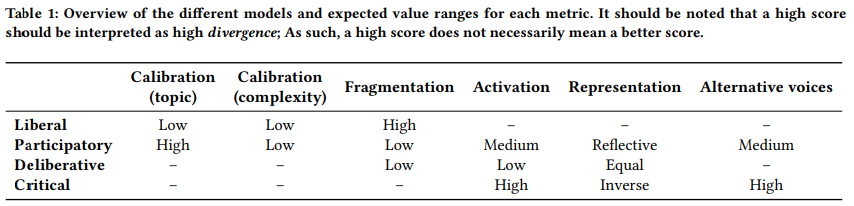
(論文より引用)
異なるアルゴリズムから得られた推薦結果のRADioの各値を比較することで、開発者はどの手法が各メディアが求める機能に適しているか定量的に評価できる、という話ですね。
- 自由主義モデルはユーザの好みに合わせた情報を提供したい -> 低いCalibrationと高いFragmentationの性質が望ましい
- 参加主義モデルは社会で必要な共通認識を各ユーザに分かりやすい形で提供したい -> 高いCalibration(complexity)と低いFragmentationの性質が望ましい
ちなみに論文中では、RADioを活用する上での今後の課題として以下のようなことが挙げられています。
- RADioに関連する多くの特徴量の抽出が難しいこと(ここはLLMの普及で多少なりとも難易度低下?
 )
) - 現状のRADioはpost-hocな評価指標である点。機械学習モデルの損失関数として活用可能なもののほうが良いよね...!
RADio のニュース推薦システム内での活用可能性に思いを馳せてみた
最後に、RADioフレームワークを現在の業務上の課題解決に活用できないかなぁ、と思いを馳せてみました。
1つ目: 推論結果の品質の監視
最近読んだMLOps Maturity Assessmentの項目4や Booking.comの論文の教訓5でも主張されていますが、バッチ推論でもオンライン推論でも推論結果の品質をモニタリングすることは重要だと思っています。
本番環境で推薦システムを運用する際、各種データの分布の変化や特徴量作成・学習・推論パイプラインへのバグの混入などによって、エラーやレイテンシーの悪化等には現れない推論結果の品質の低下にいち早く気づきたいという気持ちがありまして...!
特に推薦システムなど、ユーザからのフィードバックを教師ラベルとして使用するような機械学習システムの場合は、Incomplete (不完全) feedback や Delayed(遅延) feedback の問題があるため、precisionやrecallなどの教師ラベルに依存した指標では、推論結果の品質悪化を即座に検知するのが難しいです。
よって、教師ラベルに依存しない評価指標を用いて推論結果の品質を監視したい、というモチベーションが生まれるんですね。
ちなみにBooking.comの論文では、教師ラベルに依存しない方法として応答分布分析を採用してました。これは「推論結果が正常の場合は、推論結果の分布がこうなるはずだ」という仮定をおき、実際の分布と仮定した分布の差異を監視し、品質悪化を検知する方法でした。
そこで今回、RADioの各指標はいずれも教師ラベルに依存しないので活用可能では?と思ったわけですね。
ちなみにRADioの各指標はいずれも、推薦結果の分布を他の分布と比較して評価してるので、広義の応答分布分析と言えるのかもしれません![]()
特に自由主義モデルや参加主義モデルの文脈では、Calibrationは使いやすいんじゃないかなと思ったりしてました
(ex. 自由主義モデルの場合、金融の記事を良く読むユーザAに対しては、金融の記事をたくさん推薦してあげたい。batch推論にしろonline推論にしろ、ユーザAに対する推薦結果を作成した時点で、Calibration(topic)を算出 -> 値が閾値を超えていたら品質低下として検知、みたいな...?)
2つ目: 機械学習モデルのオフライン評価
2つ目は、機械学習モデルのオフライン評価です。これがRADioの本来の用途なのかなと思っています。
ニュース推薦の分野では、metadataとしてテキストが使える事と、ニュースのlifecycleが短く新鮮なcold-start itemを推薦したいusecaseが多い事から、content-based系の手法(i.e. id-onlyでない手法)が多く採用されている印象です。
しかし、content-based手法はオフライン実験においてprecisionやrecallなどでは正確に評価しづらく、一方でid-only手法やmost-popular itemsは過大評価されやすい傾向があるようです(ニュース推薦のサーベイ論文より)。
やっぱりこのあたりの理由としては、人気度バイアスとか、Off-Policy Evaluation分野で言うところのlogging policy由来のバイアスとかが原因なのかな。
前述の通りRADioはいずれも教師ラベルに依存しない指標なので、多少なりともバイアスの影響を受けづらくないだろうか、少なくともid-only手法が過大評価されがち問題は解消できたりしないかな...なんて思ったりしました。
もちろん重み付けサンプリング(例えば参考文献7)や色々なOPE推定量(例えば参考文献8)など、バイアス除去を試みるアプローチも色々あるので、それらと組み合わせてモデルの取捨選択に使用するのが良いのかもしれません。
(例えばCalibrationの算出に使用するユーザの閲読履歴は、人気度やlogging policy由来のバイアスの影響を受けているから、重み付けサンプリング的なアプローチと組み合わせるのはどうだろう...! ![]() )
)
おわりに
今回はNewsPicksアドベントカレンダー14日目として、メディアのミッションによって"良い"ニュース推薦システムの性質が異なるかもしれないこと(パート1)、メディアに合った推薦システムをどのように選ぶべきかの方法論(パート2)に思いを馳せてみました。
4種類のメディアモデルやRADioフレームワークの5つの指標は、パート2にて論じた推論結果の品質モニタリングやオフライン評価に加えて、「自社のサービスをどういう推薦にすべきか」みたいな言語化にも便利そうなので、必要に応じて活用できればなと思いました:)
告知
NewsPicks ではエンジニアを募集中です!ご興味のある方はこちらまで。
今回の記事がおもしろいと思ったら NewsPicks アドベントカレンダーの他の記事もぜひ見てみてください!
明日は高山温さんが書いてくれます。お楽しみに!
参考文献:
- メインの論文: RADio – Rank-Aware Divergence Metrics to Measure Normative Diversity in News Recommendations
- メイン論文の前身的な論文: Recommenders with a Mission: Assessing Diversity in News Recommendations
- (メイン論文の背景にあるやつ!)ニュース推薦の民主的役割のtypologyを提案した論文: On the Democratic Role of News Recommenders
- MLOpsの成熟度を高める為のガイドライン: MLOps Maturity Assessment
- Booking.comの論文: 150 Successful Machine Learning Models: 6 Lessons Learned at Booking.com
- ニュース推薦のサーベイ論文: News Recommender Systems - Survey and Roads Ahead
- 重み付けサンプリングアプローチの論文: Debiased offline evaluation of recommender systems: a weighted-sampling approach
- OPE推定量の1つ MIPS推定量の論文: Off-Policy Evaluation for Large Action Spaces via Embeddings