150 Successful Machine Learning Models: 6 Lessons Learned at Booking.com
published date: August, 2019
authors: Lucas Bernardi , Themis Mavridis, Pablo Estevez
url(paper): https://blog.kevinhu.me/2021/04/25/25-Paper-Reading-Booking.com-Experiences/bernardi2019.pdf
(勉強会発表者: morinota)
どんなもの?
- 宿泊予約サービスbooking.comの機械学習モデルの開発運用で得た6つの教訓をまとめた論文(KDD2019で有名だったぽい?
 )
) - 教訓1は、プロダクト開発において機械学習を色んな用途・文脈で活用できている話: 特定のusecaseに特化したspecializedなモデル と 様々なusecaseで活用可能性があるsemanticなモデル。(semanticなモデル良いね...!)
- 教訓2は、機械学習モデルのオフライン評価指標とオンラインでのビジネス指標との間に相関がなかった話。
- 教訓3は、機械学習で解かせるべき問題設定をよく考え続けよう、という話。
- 教訓4は、レイテンシー大事という話。
- 教訓5は、モデルの推論結果の品質のモニタリングの話。(応答分布分析良いね...!)
- 教訓6は、RCTの実験デザイン頑張ってる話。
先行研究と比べて何がすごい?
- 機械学習に関する文献のほとんどは、アルゴリズムや数学的な側面に焦点を当てている。
- しかし、商業的な利益が最優先される産業分野において、機械学習がどのように有意義なインパクトをもたらすことができるかについては、あまり発表されていない。
- 機械学習を通じてビジネスとユーザの価値を得るための製品開発とテストの全体的なプロセスを研究した先行研究はない。
- 本論文では、Booking.comの何十ものチームによって開発され、世界中の何億人ものユーザに公開され、厳密なランダム化比較試験によって検証された、機械学習アプリケーションの成功例約150件の分析を行い、そこで得られた教訓を発表している。(まず機械学習サービスを開発するチームがいくつもある(?)の凄いな...!)
- 本論文の貢献:
- 商業製品における機械学習の影響に関する大規模な調査。
- 機械学習プロジェクトの全段階を網羅した「教訓集」
- プロジェクトの各段階で見つかった課題に対処するための一連のテクニック
技術や手法の肝は?
以下に6つの各教訓で、個人的に気になった点をまとめていく。
教訓1: 機械学習は、プロダクト開発におけるスイスナイフである(=多機能で色んな用途に使える例え)
- 機械学習は、多くの異なるプロダクトの開発や改善の為に、大きく異なる文脈(ex. 特定のusecaseに特化したspecializedなモデル、様々なusecaseで活用可能性があるsemanticなモデル)で利用する事ができる。
- 特定のusecaseに特化したspecializedなモデル:
- 様々なusecaseで活用可能性があるsemanticなモデル(=意味モデル?):
-
理解しやすい概念をモデル化する
- (定量化できていないユーザの特徴を、MLモデルを使ってモデル化する、みたいな??)
- ex) 「ユーザが旅行の目的地に対してどの程度フレキシブルであるか」を定量化するモデルを作り、プロダクトチーム全体にdestination-flexibilityの概念を与えることで、プロダクトの改善に役立てることができる。(MLチーム以外も理解・活用できる汎用的な特徴量を作る、みたいなイメージ...めちゃいいね!)
- (定量化できていないユーザの特徴を、MLモデルを使ってモデル化する、みたいな??
- semanticモデルにより、商品開発に携わる全ての人がモデルの出力に基づいて、新機能やパーソナライゼーション、説得力のある意思決定などに導入できるようになる。(semanticなモデルいいなぁ...)
- semanticモデルは、プロダクトチームが使用したいすべてのcontextで有効な、解釈可能なシグナル(=出力?)を提供する。
-
理解しやすい概念をモデル化する
- 論文の分析では、各semanticモデルは平均して、specializedなモデルよりも2倍のusecaseを生成していたとのこと。
教訓2: モデルのオフライン評価は健康診断に過ぎない
- 非常に興味深い発見: モデルの性能(=オフラインで測定できるやつ!)を上げても、必ずしもユーザとビジネスへの価値を向上できるとは限らない。なのでBooking.comにおけるオフライン評価は、アルゴリズムが我々の望むことを行っているかどうかを確認するための、健康診断に過ぎない。
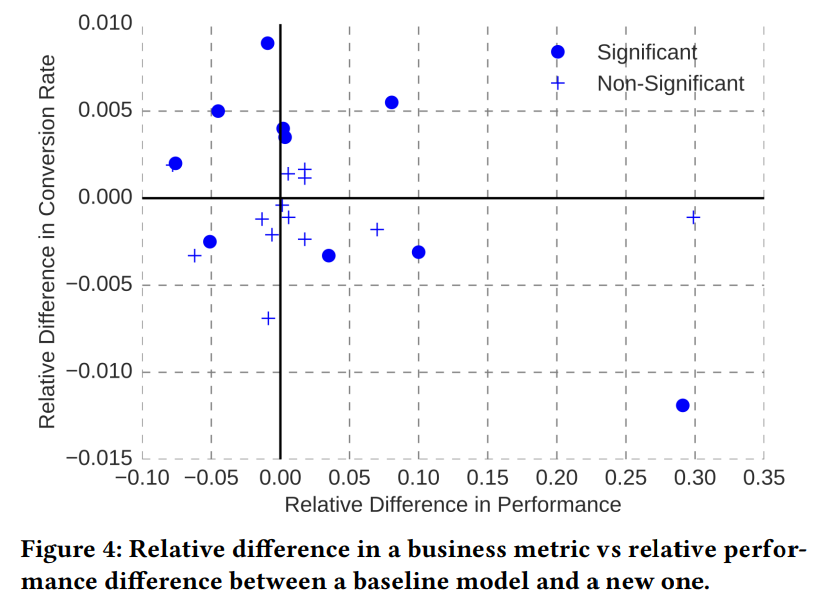
- 図4を見ると、「オフラインでのモデル性能の推定値(横軸)」と「RCTで観察されたビジネス指標(縦軸)」に相関がない。(ピアソン相関は-0.1、スピアマン相関は-0.18)
- 論文では、この相関性の欠如は、「オフラインとオンラインの性能差」ではなく、「オフラインでのパフォーマンス向上とビジネス価値向上の差」にあることを強調している。
- また、この結果は特定のusecase、特定のcontext、特定のビジネス指標を対象にしたものなので、必ずしもこの結果の一般性を主張しているわけではない。
- あくまで特定のusecaseにおける分析結果だと言いつつも、Booking.comの他のusecaseも調査したところ、一貫して同じパターンが観測されたとのこと。
-
オフライン指標がビジネス指標とほぼ一致する場合のみ、相関関係が観察される。(ex. オフライン評価ではnDCGを評価してて、ビジネス指標ではCTRを見ている場合は、どうなんだろう?)
教訓3: 問題を解かせる前に、解かせるべき問題をデザインする
- 目の前のusecaseの解決に貢献できる機械学習モデルを作る上で基本的な最初のステップは、機械学習問題を「設定」することであり、このステップに集中することが重要。
- 問題デザイン手順は、usecaseやconceptを入力とし、明確に定義されたモデリング問題(ex. 教師あり機械学習問題)を決定する。
- しかしusecaseやconceptの内容によっては目的変数が観測されないケースもあるので、注意深くデザインする必要あり。(場合によっては最適化したい値が観測できず、代理学習問題を設計する必要がある、みたいな??)
- ex) ユーザの"日付の柔軟性"を出力するsemanticモデルの問題デザイン:
- "日付の柔軟性"の定義によって、異なる学習問題が検討される
- "日付の柔軟性" = ユーザが一般的なユーザよりも多くの代替日を検討する度合い -> ユーザがいくつの代替日を検討するを予測する学習問題,
- "日付の柔軟性" = 最終的に予約する日程が今見ている日程と異なる度合い -> 日付を変更する確率を推定する学習問題
- "日付の柔軟性"の定義によって、異なる学習問題が検討される
- しかしusecaseやconceptの内容によっては目的変数が観測されないケースもあるので、注意深くデザインする必要あり。(場合によっては最適化したい値が観測できず、代理学習問題を設計する必要がある、みたいな??
- 特定のusecaseの機械学習モデルの価値を向上させる為に、モデルを改善するのが最も明白な方法だけど、問題設定そのものを変える事もあり。
- Booking.comでの成功例
- 滞在時間の長さを予測する回帰問題 -> 多クラス分類問題 (=ユーザが長期旅行しがち度合いを出力するsemanticモデル??)
- クリックデータに基づくユーザ嗜好モデル -> 宿泊客のレビューデータに関する自然言語処理問題 (このusecaseはユーザの嗜好を予測する事?)
- Booking.comでの成功例
- 一般的に、最良の問題設定はすぐに思い浮かぶものではなく、問題設定を変えることが価値を引き出す非常に効果的な方法だった。
教訓4: 時は金なり!
- レイテンシーが遅いとユーザとビジネスに悪影響だったという話。
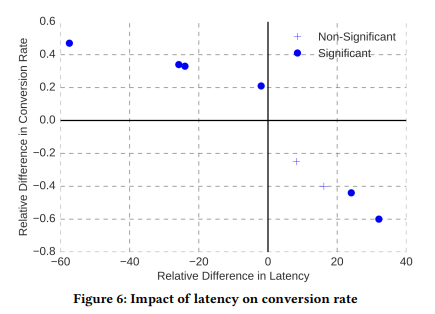
- 論文では、各群に割り当てられたユーザがsynthetic latency(=実験用の疑似的な応答時間??)にさらされる多群RCTを実行し、booking.comでレイテンシーがビジネス指標に与える影響を定量化してた。(結果は図6)
- レイテンシーが約30%増加すると、コンバージョン率が0.5%以上(私たちのビジネスに関連するコスト)低下するという明確な傾向が見られた。
- -> 仮説: 待ち時間を短くすることでコンバージョンを向上させることができる
- 機械学習モデルは推論時に多大な計算資源を必要とする(=入力する特徴量の前処理も含む)ため、これ(=time is money問題!)は特に機械学習モデルに関連する。
- モデル由来の待ち時間を最小化するための工夫:
- モデルのコピーをクラスタに分散させる。(i.e. 推論処理を並列化させる?)
- 自社開発の線形予測エンジン(i.e. 推論処理をラフにする手法??)
- 事前計算とキャッシュ
- 最小限の特徴量変換(=推論時の前処理を減らす工夫??)
- Sparse models
教訓5: モデルの出力の質をモニターすることは極めて重要
-
モデル出力の質をモニタリングすることは極めて重要だが、これには少なくとも2つの課題がある:
-
Incomplete feedback: 多くの状況では、完全な正解ラベルを観察することはできない。
- ex.) あるユーザに2つのプッシュ通知A&Bのどちらかを送るかを選択するモデルの場合、タップしたか否かの正解ラベルは、実際に送信した片方のみ観測できる。送信しなかった方の正解ラベルは観測されない。
-
Delayed feedback: 推論時から何日も、あるいは何週間も経ってから、真のラベルが観測される場合もある。
- ex.) あるユーザに2つのプッシュ通知A&Bのどちらかを送るかを選択するモデルの場合、実際にユーザがプッシュ通知を見るのは、推論してから1日後かもしれない。
-
Incomplete feedback: 多くの状況では、完全な正解ラベルを観察することはできない。
- これらの課題がある状況では、precisionやrecallなどの教師ラベルに依存した指標は不適切 -> 教師ラベルに依存しない指標でモデル出力の質を監視したい...!
- 「モデルの品質について、それがサービスを提供するときに行う予測を見るだけで、何が言えるのだろうか?」 -> booking.comでは**応答分布分析(=Response Distribution Analysis)**を適用してるとの事。
- 応答分布図(Response Distribution Chart, RDC)に基づいた手法。(RDCはかくあるべき、という仮定をヒューリスティックに用意しておく必要がある)
- 応答分布分析は、モデルの欠陥を早期に発見できる非常に有用なツール。
- 応答分布図(Response Distribution Chart, RDC)に基づいた手法。(RDCはかくあるべき、という仮定をヒューリスティックに用意しておく必要がある
- 「モデルの品質について、それがサービスを提供するときに行う予測を見るだけで、何が言えるのだろうか?」 -> booking.comでは**応答分布分析(=Response Distribution Analysis)**を適用してるとの事。
教訓6: 洗練された実験計画が功を奏す
- RCTによる実験は、Booking.comの文化に根付いている(いいね!)
- Booking.comの開発組織では、実験を民主化する独自の実験プラットフォームを構築し、誰もが実験を実行して仮説を検証し、私たちのアイデアの影響を評価できるようにした(個人的にはこれのオフライン実験ver.を作りたい。"実験を民主化する"って表現いいなぁ...)
- Booking.comの開発組織では、実験を民主化する独自の実験プラットフォームを構築し、誰もが実験を実行して仮説を検証し、私たちのアイデアの影響を評価できるようにした(個人的にはこれのオフライン実験ver.を作りたい。"実験を民主化する"って表現いいなぁ...
- 実験デザインを頑張ってるらしい:
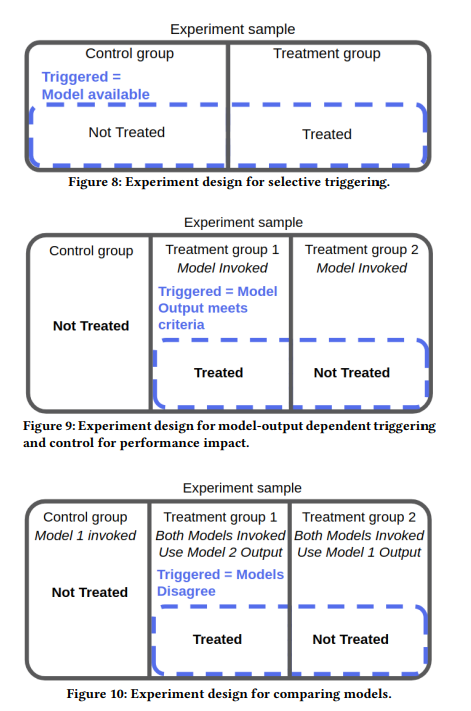
- 特定のモデル(ex. 推論結果の違い)と実装の選択(ex. レイテンシーの違い)がビジネス指標に及ぼす因果効果を分離するために、トリガー分析(?)とtreatments design(?)を組み合わせる。
- トリガー分析: (triggerってなんだ?? fig8を見た感じでは、triggered = model availableって事っぽい!) controll郡/treatment郡のtreatment可能な(またはtriggerされた)ユーザだけを分析する為の手法っぽい
- treatments design: 特定のモデル(ex. 推論結果の違い)と実装の選択(ex. レイテンシーの違い)がビジネス指標に及ぼす因果効果を分離して正しく実験する為のRCTのユーザグループの分け方のデザイン手法??
- ex.) 既存手法よりも精度高いがレイテンシーが遅いモデルを開発し、ABテストする場合、シンプルにcontroll/treatmentの2群だけでは、新モデルの評価が難しい。この場合、ユーザグループをcontroll/treatment_1/treatment_2の3群とし、推論精度の違いによる効果とレイテンシーの違いによる効果を分解して推定できる様にする。
- トリガー分析: (triggerってなんだ?? fig8を見た感じでは、triggered = model availableって事っぽい!
- 特定のモデル(ex. 推論結果の違い)と実装の選択(ex. レイテンシーの違い)がビジネス指標に及ぼす因果効果を分離するために、トリガー分析(?)とtreatments design(?)を組み合わせる。
どうやって有効だと検証した?
今回は手法に関する論文ではないのでパスします!
6つの教訓はbooking.comでの機械学習システムの運用・改善経験から有効性を主張してる感じ。
議論はある?
- (感想)本論文を読んだ感じでは、2019年時点のbooking.comでは色んなusecaseでそれぞれモデルを作って運用している雰囲気だった。Netflixの機械学習モデルの統合の話を読んで、もしかすると近年はbooking.comも複数のusecaseでモデルを統合して、運用・開発しやすくしていたりするんだろうか?
次に読むべき論文は?
- MLOps関連の論文を読んでみたい気持ち...!
- 最近、Netflixの機械学習モデルの統合の話を読んだので、そこで引用している論文とか...!
お気持ち実装
今回はパスです!