The Feature Store Advanced Guide 2025年ver.を読んだメモ
これは何??
- Feature Storeについて色々ググっていたら、 https://www.featurestore.org/ というサイトを見つけたので、そこに紹介されていた The Feature Store Advanced Guide の2025年ver.を読んでみたメモです。
- refs: Feature Store: The Definitive Guide
- Hopsworksの人が書いたものなのかな? ガイドの内容は Hopsworks Feature Store のみでなく一般的なFeature Storeの話をしてるっぽいですが、若干ポジショントークが含まれる可能性も考慮して読んでみます。
- (一応、本記事はn週連続推薦システム系論文読んだシリーズ 42 週目、という位置付けで書いてます。まあMLを使った推薦システムにおいてFeature Storeは重要なコンポーネントなので...!
 )
)
はじめに: 個人的な気づきポイントまとめ
以下は、ガイドを一通り読んで、個人的に特に気づきだと感じた部分をまとめたものです。
この記事の総括っぽい気づき達
-
Feature Storeの採用による恩恵(i.e. 効果)って、ざっくり以下の3種類に分類できる気がした!
- 1つ目: 様々な特徴量を一元管理することによる恩恵
- 2つ目: FTI Pipelines Architectureに則ったシステムであることによる恩恵
- 3つ目: timestamp付きでとくちょを管理することによる恩恵
-
Feature Storeの役割って、特に推薦タスクとかだと重要そうかも...!
- 特に推薦などの意思決定最適化タスクでは、ユーザ行動に関する特徴量を使うことが多い。また、MLモデルの出力側(正解ラベルや報酬ログ)もタイムスタンプ付きのデータであることが多い。
- このような場合、ユーザ特徴量はstaticではなく非常にdynamicなデータ(=つまりincremental dataset...??
 )になる。関連して、タイムスタンプ付きで特徴量を管理しないと、学習時のデータリークが容易に発生し得る。
)になる。関連して、タイムスタンプ付きで特徴量を管理しないと、学習時のデータリークが容易に発生し得る。 - それを踏まえると、意思決定最適化タスクではFeature Storeを導入するモチベーションは結構あると思った。
- (逆に言えば、特徴量がstaticなタスクだったり、学習時のデータリークが発生しづらいようなタスクだったら、Feature Storeを導入するモチベーションは一定下がりそう...? 前述の恩恵3があまり享受できなさそうなので。)
- (しかしまあ、staticな特徴量を使うタスクでも、Feature Storeを使うことで特徴量の「発見しやすさ」や「再利用しやすさ」が向上するので、MLのいろんなユースケースがあるなら導入するモチベーションは十分にあるかも...! つまり前述の恩恵1と2は十分に享受できる)
- (逆に言えば、特徴量がstaticなタスクだったり、学習時のデータリークが発生しづらいようなタスクだったら、Feature Storeを導入するモチベーションは一定下がりそう...? 前述の恩恵3があまり享受できなさそうなので。
個人的な小さめの気づき達
- Feature Storeによる効果のいくつかは、FTI Pipelines Architectureを採用すること(=特徴量生成/学習/推論を分離すること)によって得られる効果だなって感じ...!
- 必ずしもオンラインストアに全ての特徴量を保存する必要はないっぽい!
- 最初オンラインストアのコストめっちゃ高くなりそうだと思ってた。でもオフラインストアの全てをオンラインに同期する必要はなくて、リアルタイム推論で使う特徴量、かつ最新のversionの特徴量レコードのみで良さそう...!
- 最初オンラインストアのコストめっちゃ高くなりそうだと思ってた。でもオフラインストアの全てをオンラインに同期する必要はなくて、リアルタイム推論で使う特徴量、かつ最新のversionの特徴量レコードのみで良さそう...!
-
Feature Pipelineは必要に応じてbackfillできる必要がある。そのためには無状態 & 冪等性を持つデータパイプラインを意識すべき...!!
- 古すぎる特徴量を学習に使うのもよくない!
- たぶん推論時はもっと最新の特徴量を使うのに学習時はそれよりも古い特徴量を使ってしまうことが問題なんだろうな。未来の情報を使ってしまうのも、古すぎる情報を使ってしまうのも、結局「学習時と推論時で使われる特徴量が異なる」っていうdata skew的なことが問題なのかな...!
- たぶん推論時はもっと最新の特徴量を使うのに学習時はそれよりも古い特徴量を使ってしまうことが問題なんだろうな。未来の情報を使ってしまうのも、古すぎる情報を使ってしまうのも、結局「学習時と推論時で使われる特徴量が異なる」っていうdata skew的なことが問題なのかな...!
以下は、ガイドの内容と付随して思ったことメモの詳細です。
そもそも特徴量とは? なんで専用の保存場所が欲しい??
- 特徴量(feature) = エンティティの数値的な属性で、学習/推論の入力として使うやつ!
- ある対象(entity)の属性(property)を数値化したもので、かつMLに役立つもの。
- 専用の保存場所が必要なモチベーション:
- その1: 「再利用」や「発見しやすさ」が重要だから(=開発効率up)
- 特徴量を保存することの利点の一部は、それらが簡単に発見され、異なるモデルで再利用しやすい状況を作れることである。
- それにより、新しいMLシステムを構築するために必要なコストと時間を削減できることである。
- (この観点は、まさにFeature Storeの役割って感じだ...!!)
- その2: リアルタイム推論時に、今来たリクエストだけじゃなく、事前計算したリッチな情報が必要だから (=モデルの精度up)
- オンラインモデルはlocal stateを持たない傾向があるらしい。
- (これってどういう意味だろ。local stateを持たない傾向、って部分。perplexityに相談してみた感じ、各ユーザやリクエストの履歴・状態をモデル本体やサーバーのメモリ内に溜め込まず、「今来たリクエスト」に含まれる情報だけをそのまま使う傾向がある、みたいな意味合いっぽい...!)
- (これってどういう意味だろ。local stateを持たない傾向、って部分。perplexityに相談してみた感じ、各ユーザやリクエストの履歴・状態をモデル本体やサーバーのメモリ内に溜め込まず、「今来たリクエスト」に含まれる情報だけをそのまま使う傾向がある、みたいな意味合いっぽい...!
- オンラインモデルはlocal stateを持たない傾向があるらしい。
- その1: 「再利用」や「発見しやすさ」が重要だから(=開発効率up)
Feature StoreとMLOps、MLシステムとの関連
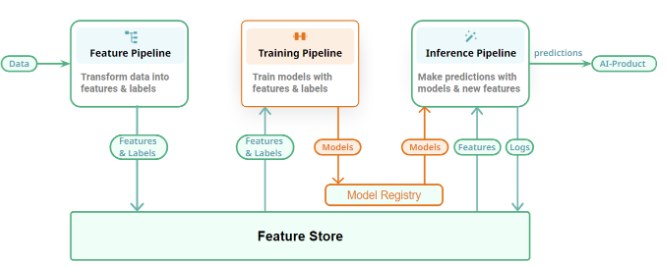
-
MLOpsプラットフォームにおけるFeature Storeは、異なるMLパイプラインを結びつけて完全なMLシステムを作る接着剤の役割を持つ (FTI Pipelines Architectureの発想そのものじゃん...!
)- Feature Pipeline: 特徴量を計算し、特徴量およびlabel/targetをFeature Storeに書き込む。
- Training Pipeline: Feature Storeから特徴量およびlabel/targetを読み込み、MLモデルを学習する(学習されたモデルはmodel registryに書き込まれる)。
- Inference Pipeline: Feature Storeから特徴量を取得し、MLモデルを使って推論する。
- (メモ: 上記の内容って、思いっきりFTI Pipelines architectureの思想! Feature Storeを採用すること = FTI Pipelines Architectureを採用すること、と言って良さそう...!)
- (まあFTI Pipelines Architecture自体がHopsworksの人が提唱してる設計思想なので、ここが整合するのは当然かも...!)
-
MLOpsの主な目標 = モデル試行錯誤のiteractionを短縮し、モデルのパフォーマンスを向上させ、ML資産(特徴、モデル)のガバナンスを確保し、コラボレーションを改善すること。
- (ちなみに「MLOps処方箋本」のMLOpsの定義は「MLの成果をスケールさせるための取り組み」な訳だけど、上記を改善することがMLの成果のスケールに繋がるから、って解釈できそう...!)
- Feature Storeを採用すること(i.e. FTI Pipelines Architectureを採用すること)によって、この目標の達成につながるよ〜みたいな話かな
- (ちなみに「MLOps処方箋本」のMLOpsの定義は「MLの成果をスケールさせるための取り組み」な訳だけど、上記を改善することがMLの成果のスケールに繋がるから、って解釈できそう...!
Feature Store が解決する課題
Feature Storeが解決する課題として以下の11個が挙げられてた:
-
MLシステムのcollaborativeな開発を促進! (一元管理されてるので「発見」しやすいし、取得方法が統一されてるので「再利用」しやすいよね、って話か...!
) -
特徴量データのincrementalな管理 (本番MLシステムにおける特徴量は、一回作って終わりじゃなくて、incrementalに変化していくものなので...!
) -
特徴量のbackfillingと学習データのbackfilling (これは、Feature Storeは特徴量をevent_timeと一緒に管理するから実現できるよね、って話かな...?
) -
ステートレスなリアルタイム推論モデルにリッチな特徴量を供給 (これは前述してたlocal stateを持たない傾向、みたいな話!)
-
特徴量の再利用がしやすくなる (これは一元管理してるから
) -
特徴量の様々な計算パターンへの対応 (これも一元管理してるから? オンライン/オフラインストアを持つからか
) -
特徴量データのvalidationやドリフト監視がしやすくなる! (これは、feature pipelineが独立するからかな...!
) -
学習時と推論時の特徴量の計算方法のズレ(data skew)を防げる!
-
point-in-time consistency (時点整合性) を持つ学習データを作りやすくなる! (これはFeature Storeがevent_timeを元に特徴量を管理するから!
) -
リアルタイム推論時に、事前計算した特徴量を低レイテンシー提供 (これはオンラインストアを含むFeature Storeの話! 非対応のものもある印象...!
) -
埋め込みベクトルを使用したsimilarity search (これはFeature Storeがベクトル検索をサポートしてる場合! similarity search機能はサポートしてない場合も全然ありそう!
)
シナリオ別のFeature Storeの役立ちポイント例:
- バッチMLシステムの本番稼働シナリオ(2, 3, 7, 8, 9)
- リアルタイムMLシステムの本番稼働シナリオ(上記に加えて、4, 6, 10, 11)
- 大規模なML展開シナリオ(上記に加えて、1, 5)
補足1: Feature Storeがcollaborativeな開発をどう支えるか??
- 1点目: チームごと・開発者ごとの役割分担を可能にする。
- Feature Storeがあることで(i.e. FTI Pipelines Architectureであることで)、MLシステムの構築・運用をパイプライン単位に分解できるようになる。
- ex.)
- Feature Pipeline: データエンジニア・データサイエンティスト
- Training Pipeline: データサイエンティスト
- Inference Pipeline: ソフトウェアエンジニア、MLOpsエンジニア
- ex.)
- これによって、
- 各種パイプラインでやるべきことが明確化される
- Feature Storeをハブにして各パイプラインが独立して開発・運用できる
- したがって、チーム間・チーム内でスムーズに役割分担・連携しやすくなる!
- (メモ: 特徴量 x ルールベースによる推論だったら、Inference Pipelineを非MLチームのソフトウェアエンジニアが担当することも全然あり得るよね。...! 欲しい特徴量の取得方法が統一された方法でわかりやすければ...!)
- (メモ: 特徴量 x ルールベースによる推論だったら、Inference Pipelineを非MLチームのソフトウェアエンジニアが担当することも全然あり得るよね。...! 欲しい特徴量の取得方法が統一された方法でわかりやすければ...!
- Feature Storeがあることで(i.e. FTI Pipelines Architectureであることで)、MLシステムの構築・運用をパイプライン単位に分解できるようになる。
- 2点目: 共通言語が生まれる
- Feature Storeを中心に据えることで、チーム間で「Feature Pipeline」「Training Pipeline」「Inference Pipeline」っていう共通の言葉・設計思想を持てる!
- ex.) チームが構築しているのがバッチMLだろうとリアルタイムMLだろうと、開発者たちが「どうやって特徴量を管理してるか」を共通理解できるようになる! だから、チーム内・チーム間のコミュニケーションコストが下がる!
- (hogeパイプラインの入り口or出口は、まあFeature Storeだよね〜みたいな共通認識を持ちやすい、みたいな??:)
- (hogeパイプラインの入り口or出口は、まあFeature Storeだよね〜みたいな共通認識を持ちやすい、みたいな??:
- ML資産の共有とチーム内およびチーム間のコミュニケーションの改善が可能になる!
Feature Storeの各種データの保存場所について:
- historicalな特徴量データ(i.e. event_timeを持つバージョニングされた特徴量データ??)は、オフラインストア(通常は列指向データストア)に保存される。
- リアルタイム推論で使用される最新バージョン(i.e. event_timeが最新)の特徴量データは、オンラインストア(通常は行指向データストア or key-valueストア)に保存される。
- 個人的気づき: あ、オンラインストアに全ての特徴量を保存する必要はなくて、リアルタイム推論で使うもの、かつ最新のversionの特徴量レコードのみで良さそう...!!
- 最初オンラインストアのコストめっちゃ高くなりそうだと思ってた。でもオフラインストアの全てをオンラインに同期する必要はなくて、リアルタイム推論で使う特徴量、かつ最新のversionの特徴量レコードのみで良いんだよな...!
- 最初オンラインストアのコストめっちゃ高くなりそうだと思ってた。でもオフラインストアの全てをオンラインに同期する必要はなくて、リアルタイム推論で使う特徴量、かつ最新のversionの特徴量レコードのみで良いんだよな...!
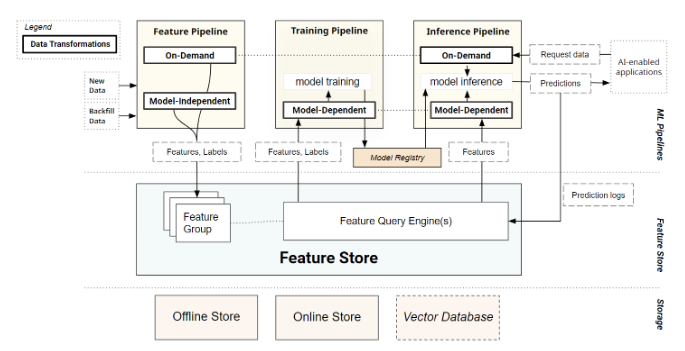
ストレージ層におけるデータストアの選択について:
- 一部のFeature Storeサービスは、プラットフォームの一部としてストレージ層を提供し、一部は部分的または完全にpluggableなストレージ層を持つ。
- 前者の例: Sagemaker Feature Store, Google Cloud Vertex AI Feature Store, Snowflake Feature Storeなどのベンダー提供のマネージドサービス。
- 例えばSagemaker Feature Storeは、オフラインストアはS3上のParquet、オンラインストアはAWS Aurora(MySQL)で多分固定。
- 後者の例: FeastやHopsworks Feature StoreなどOSS系。
- Feastは、オフラインストアとしてBigQueryやSnowflakeやS3など、オンラインストアとしてRedisやDynamoDBなどをpluggableに取り替えできる感じ。
- 前者の例: Sagemaker Feature Store, Google Cloud Vertex AI Feature Store, Snowflake Feature Storeなどのベンダー提供のマネージドサービス。
また、予測ラベル(=もしくは報酬ログ的なもの。MLの出力側のデータ...!)もFeature Storeに保存するといいよ的なことも書いてあった!(特徴量/モデルの監視とデバッグしやすさの観点で!)
補足2: Feature Storeが特徴量のincrementalな管理をどう支えるか??
- feature pipelineは、MLシステムが稼働してる限り、特徴量を追加・更新し続ける (incremental dataset)
- Feature Storeがなければ、複数データストアへの整合性管理が大変になる。
- オフライン・オンライン・ベクトルDBが別々に存在してる場合、それぞれ認証・接続方法などが異なり、incremental datasetである特徴量について、それぞれのデータ同期を保つのは大変。
- Feature Storeはこれらをwrapして、統一的なCRUD(create/read/update/delete)インターフェースを提供してくれるので、可変な特徴量データセットの管理を容易にする役割を果たす。
- 同じfeature groupをストリーム処理クライアント(streaming feature pipeline)を使用して更新することもできる。(同じ特徴量グループを、バッチでもストリームでも更新できるよ、って話か。まあそりゃそうな気がする...!)
- 補足: Feature Storeでは、特徴量の論理グループを「feature group」や「Feature View」などと呼んでセットで管理することが多い。(ex. ユーザに関する特徴量は「user_feature_group」みたいな感じで)
- 同じfeature groupをストリーム処理クライアント(streaming feature pipeline)を使用して更新することもできる。(同じ特徴量グループを、バッチでもストリームでも更新できるよ、って話か。まあそりゃそうな気がする...!
補足3: Feature Storeが特徴量のbackfilling(および学習データのbackfilling)をどう支えるか??
(この章を読んで思ったこと: feature pipelineはbackfillできる必要がある。そのためには無状態 & 冪等性を持つパイプラインを意識すべき...!! ![]() )
)
(単一の実装をバッチでもストリームでも実行できるようにしておくのが運用上最強ってことでは..!![]() )
)
-
backfillingは、生の履歴データからデータセット(=特徴量や学習データセット...!)を再計算するプロセス。
-
これには、ユーザがbackfillするデータの範囲のためにstart_timeとend_timeを提供する必要がある。(feature pipelineを作るときは、無状態 & 冪等なデータパイプラインを意識すべき...!
)- 思ったことメモ:
- 毎回全ユーザ分の特徴量を作る系のfeature pipelineだったら、backfillはあくまで学習用データセットを作るため、という用途になりそう...!
- 特定期間内に追加・更新されたアイテムだけの特徴量を作る系(=streamingっぽい)のfeature pipelineだったら、学習用だけじゃなくて推論用のデータを作る目的でもbackfillしそう。
- まあすでに既存の特徴量パイプライン達が運用されてる状況だったらbackfillってのはあんまりする必要はなくて、どちらにせよ、特徴量グループに新しい特徴量を追加したり既存特徴量の作り方を変更した場合などにbackfillすることになるはず
-
backfill可能なデータパイプラインである為には、やはり無状態 & 冪等性を持つパイプラインを意識する必要がありそう...!
- 毎回全ユーザ分の特徴量を作る系のfeature pipelineだったら、backfillはあくまで学習用データセットを作るため、という用途になりそう...!
- 思ったことメモ:
-
また、ある特徴量のbackfillに使用されるfeature pipelineは、"live"データも処理できる必要がある
- そのための方法はシンプルで、単にfeature pipelineを、データソースとデータの範囲を指定できるようにすればOK。(要するに、わざわざ「backfill用の特別なパイプライン」を別で作るのはやめようね、って話だと思ってる! backfill時は、対象データ期間を「過去データの範囲に切り替えて」動かすだけ! )
- そのための方法はシンプルで、単にfeature pipelineを、データソースとデータの範囲を指定できるようにすればOK。(要するに、わざわざ「backfill用の特別なパイプライン」を別で作るのはやめようね、って話だと思ってる! backfill時は、対象データ期間を「過去データの範囲に切り替えて」動かすだけ!
-
バッチとストリーミングのfeature pipelineの両方が、特徴量をbackfillできる必要がある。
- (ストリーミングパイプラインもbackfillできるようにしておこうね、という話か...!ストリームのreplay設計っていうらしい...!)
- (でも結局、大量の期間のデータをbackifillする際には、バッチというかバルクで一気に処理できる設計になってた方がいいよな...単一のbackfill可能な実装をバッチでもストリームでも実行できるようにしておくのが運用上最強ってことでは...!)
- (ストリーミングパイプラインもbackfillできるようにしておこうね、という話か...!ストリームのreplay設計っていうらしい...!
-
特に学習データを作るという観点で、特徴量をbackfillできることは重要:
- 逆に、もし特徴量をbackfillできないと、既存特徴量の定義を変更したり新しい特徴量を追加した場合に、本番システムリリース後に特徴量ログを集め始めて学習データが十分に集まるのを待つ必要が出てきてしまう。
補足4: Point-in-time correctな学習データについて

- 時系列の特徴量データから未来のデータリークなしに学習データを作りたい場合、時点正確な結合(point-in-time correct join)と呼ばれる結合を行う必要がある。
- point-in-time correctな学習データじゃないと、推論時にモデル性能が悪化するし、その悪化の根本原因の特定も難しくなる。
- ちなみにブログ内では、以下の2種類をデータリークと呼んでた。
- 予測したい教師ラベルや報酬ログのtimestampよりも、未来の情報を含む特徴量を学習データに含めてしまうこと
- (こっちはThe データリークって感じだ...!)
- (こっちはThe データリークって感じだ...!
- 予測したい教師ラベルや報酬ログのtimestampよりも、古すぎる特徴量を使ってしまうこと。
- (これもデータリークって言うんだ...! 結局これって、推論時はもっと最新の特徴量を使うのに学習時はそれよりも古い特徴量を使ってしまってて、そこに差分というかdata skewが発生してしまってるのが問題、ってことかな...!!)
- (これもデータリークって言うんだ...! 結局これって、推論時はもっと最新の特徴量を使うのに学習時はそれよりも古い特徴量を使ってしまってて、そこに差分というかdata skewが発生してしまってるのが問題、ってことかな...!!
- 予測したい教師ラベルや報酬ログのtimestampよりも、未来の情報を含む特徴量を学習データに含めてしまうこと
- 思ったことメモ:
- 多くのFeature Storeは、特徴量をevent_time(=特徴量作成時のtimestamp)と一緒に管理することで、point-in-time correctな学習データを作れるようにしてる認識...!
- まあ自前で実装してもいいが、既存のFeature Storeサービスに任せられるなら楽だよなぁ...
- まあ自前で実装してもいいが、既存のFeature Storeサービスに任せられるなら楽だよなぁ...
- ちなみに推論時は、現在時刻を指定してpoint-in-time correct join(=最新のバージョンの特徴量を取得することになるはず!)して、推論用データを作ればよさそう!
- 多くのFeature Storeは、特徴量をevent_time(=特徴量作成時のtimestamp)と一緒に管理することで、point-in-time correctな学習データを作れるようにしてる認識...!
補足5: Feature Storeがリアルタイム推論をどうrichにするか??
- リアルタイム推論はstatelessなケースも多い。
- モデルはユーザリクエストだけを受け取り、その情報のみを元に、即時に推論を返す(状態は持たない)
- (まあ推薦タスクとかだと、ユーザの過去の履歴情報などを使いまくって推論することが多いから、あんまりステートレスなモデルはない気がするけど...!)
- (まあ推薦タスクとかだと、ユーザの過去の履歴情報などを使いまくって推論することが多いから、あんまりステートレスなモデルはない気がするけど...!
- 履歴や文脈情報(トレンドなど)を表す特徴量を事前計算してFeature Storeに保存しておくことで、リアルタイム推論モデルはオンラインストアから即座にrichな特徴量を取得して使用できる。
- 例: Tiktokでは、最近見た10本の動画に関する特徴(カテゴリ、視聴時間、友達の行動など)をオンラインストアに保持してるらしい。
- モデルはユーザリクエストだけを受け取り、その情報のみを元に、即時に推論を返す(状態は持たない)
- entityが単純とは限らない話(複合キーのサポートも必要?)
- (ここで"entity"って言ってるのは、特徴量の対象の概念。ex. ユーザやアイテムなど)
- 多くのケースでは単一のentity(user_idやitem_id)で十分。
- より高度な推薦やランキングタスクでは、(user_id, item_id)のタプルのような**複数カラムの主キー(複合キー)**が必要になる場合もある。
- ちなみに軽く触ってみた感じ、SageMaker Feature Storeは現時点では、特徴量を管理する上で複合キーは非対応っぽい...!
- feature groupを作成する際に、主キーを1つしか指定できないので。
- なので(user_id,item_id)単位の特徴量を管理したい場合は、
user_id|item_idのように文字列結合で擬似複合キーを作る工夫が必要になりそう...! - まあこれはどこもそうなのかも?
- ちなみに軽く触ってみた感じ、SageMaker Feature Storeは現時点では、特徴量を管理する上で複合キーは非対応っぽい...!
補足6: Feature Storeが特徴量の再利用をどう支えるか??
学習-推論間の特徴量の再利用の話:
-
最初のMLモデル構築では、特徴量作成が「場当たり的」になりがち。結果として、学習用と推論用で別々に特徴量作成処理を作ってしまいがち...!
- 学習用にCSVやDB直クエリなど、特注のスクリプトやETLで特徴量を作ることが多い。
- そのあと本番運用に入ると「推論のためにリアルタイムで同じ特徴量作る必要あるじゃん…」となって、別のパイプラインが作られがち。
- ex.)
- 最初にMLモデルを作るとき...「アプリケーションDBやDWHから直接データ引っこ抜いて…」「CSVこねくり回して…」「学習用の特徴量作った〜!やった〜!」
- その後にモデルを本番運用するとき...「あれ、リアルタイムで同じ特徴量を作る必要あるじゃん…」「推論時に必要な特徴量を作るために本番の別のパイプライン作らなきゃ…」
- Feature Storeがあると、特徴量の作成がfeature pipelineとして分離されることで、学習時に用意した特徴量をそのまま推論時にも再利用しやすくなる。
MLモデル間での特徴量の再利用の話:
-
MLモデルを使うユースケースが増えると、「同じ特徴量を何度も再計算」するようになる。
- 計算リソース・ストレージの無駄。また、コードが重複して非DRY(Don't Repeat Yourself)になり、保守が地獄になる。
- Feature Storeがあると、モデル間での特徴量の再利用が簡単になる!
- 一度作った特徴量はFeature Groupとして保存し一元管理 → 他モデルでもすぐ使える!
- Metaの事例: 「最も人気な100特徴量が100以上のモデルで再利用されてる」
- よって、特徴量を使い回す前提でシステムを設計した方が良い...!!
- よって、特徴量を使い回す前提でシステムを設計した方が良い...!!
- 「同じ特徴量を何度も再計算」に関連して思ったこと:
- 最近のNetflixさんのブログで、推薦基盤モデルの話があったけど、あれもモチベーションが近い気がした...! ユーザ行動履歴の学習を各MLモデルがそれぞれやってるので、その部分を共通の1つの基盤モデルが担うようにして、その成果物を下流モデルの初期パラメータや特徴量として使う、みたいな話だった。結局あれって、ユーザ行動履歴から興味を抽出する部分をfeature pipelineとして抜き出して、複数の下流モデルで再利用できるようにした、みたいな解釈もできそう...??
- 最近のNetflixさんのブログで、推薦基盤モデルの話があったけど、あれもモチベーションが近い気がした...! ユーザ行動履歴の学習を各MLモデルがそれぞれやってるので、その部分を共通の1つの基盤モデルが担うようにして、その成果物を下流モデルの初期パラメータや特徴量として使う、みたいな話だった。結局あれって、ユーザ行動履歴から興味を抽出する部分をfeature pipelineとして抜き出して、複数の下流モデルで再利用できるようにした、みたいな解釈もできそう...??
特徴量の再利用によって得られる恩恵:
- 恩恵1: 特徴量の品質が向上。多くのモデルで使われることで、レビューや改善が進む。
- (これはTeem Geekの「隠すとダメになる」的な話だ...!)
- (これはTeem Geekの「隠すとダメになる」的な話だ...!
- 恩恵2: ストレージと計算コストの削減。
- 恩恵3: パイプラインや本番コードの数が減る(DRYになるので)。結果としてメンテしやすくなる。
- 結果:Feature Storeは、本番環境で実行するモデルの数と、維持しなければならないfeature pipelineの数を切り離す。
- (この観点大事だ...! 言い換えるとFTI Pipelines Architectureの利点でもある!)
- 結果:Feature Storeは、本番環境で実行するモデルの数と、維持しなければならないfeature pipelineの数を切り離す。
- 恩恵4: 工数の削減
- Feature Storeが十分に整備されていれば、必要な特徴量がすでにFeature Storeにあるなら、新しいMLモデルのためにfeature pipelineを書く必要はなくなる。
補足7: Feature Storeは特徴量データのvalidation & ドリフト監視をどう支えるか??
- 前提:
- 「Garbage In, Garbage Out」はMLにも完全に当てはまり、モデルの性能は入力データの品質に大きく依存する。よって、特徴量の品質チェックは必須である。
- 特徴量のvalidation = Feature Storeに書き込む前のチェック
- 特徴量パイプラインの出口 or Feature Storeへの書き込み時に実行する。
- (feature pipelineの最後のstepでvalidationを実行すれば良さそう...!)
- 特徴量の監視 = 保存後の変化・異常の検知
- Feature monitoringは、多くのFeature Storeが提供する便利な機能の一つ
- バッチMLシステムを構築する場合でもオンラインMLシステムを構築する場合でも、システムのモデルに対する推論データを監視し、それがモデルの学習データと統計的に有意に異なるかどうか(data drift)を確認できる必要がある。
- もし異なる場合は、ユーザ(=開発者)にアラートを通知し、理想的にはより最近の学習データを使用してモデルの再学習を開始するべき。
- ちなみに...Hopsworks Feature Storeの例:
- ドリフト検知のバッチが1日一回実行されるようになってるみたい。
- 推論時の特徴量の統計量が、学習時の同じ値から50%以上逸脱してた場合に、データドリフトが発生したとみなし、アラートをtriggerするような仕組みらしい。
- なるほどこの場合のデータドリフトの監視はバッチで行われるのか。こちらのブログで理想的にはこれもストリーミング的に実行される方が良いって見た覚えがある...!
補足8: 特徴量に関する3種類のデータ変換とdata skew防止について
特徴量に関するデータ変換の3分類
特徴量に関するデータ変換(data transformation)の分類(Taxonomy)は3つある。
- 1つ目: model-independent transformation(モデル非依存変換)
- 2つ目: model-dependent transformation(モデル依存変換)
- 3つ目: on-demand transformation(オンデマンド変換)
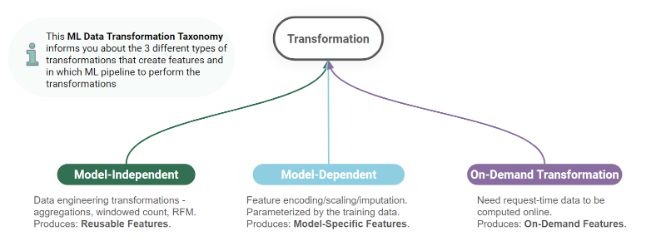
それぞれの分類の特徴は以下の通り:
- 1つ目: model-independent transformation(モデル非依存変換)
- どのモデルでも再利用可能な、汎用的な特徴量を作る処理。
- 実行場所: feature pipeline (batch / streaming)
- モデル非依存変換は、feature pipelineの中でのみ実行されるべき(i.e. つまり学習 & 推論パイプラインには含まれるべきではない...!)
- 2つ目: model-dependent transformation(モデル依存変換)
- 各モデルの最適化に調整するような、モデル固有の前処理(ex. one-hot encoding, 欠損値補完, 0~1スケーリングなど)。
- (カテゴリ変数をone-hot encodingしたり、数値特徴量を標準化したり、欠損値を埋めたり...は、各モデルの精度を上げるために個別に細かくチューニングするもの...!)
- (カテゴリ変数をone-hot encodingしたり、数値特徴量を標準化したり、欠損値を埋めたり...は、各モデルの精度を上げるために個別に細かくチューニングするもの...!
- 実行場所: training pipeline / inference pipeline
- 各モデルの最適化に調整するような、モデル固有の前処理(ex. one-hot encoding, 欠損値補完, 0~1スケーリングなど)。
- 3つ目: on-demand transformation(オンデマンド変換)
- リアルタイム推論時、リクエストで受け取った情報からリアルタイムに特徴量を計算する処理。
- 実行場所: (real-time) inference pipeline / feature pipeline
- あれ、なんでfeature pipelineも含まれるんだっけ??
-
過去のデータから特徴量をbackfillして再学習などする場合は、オンデマンド変換もfeature pipelineで実行できる必要があるので...!
- (学習時にon-demand変換による特徴量も用意する必要があるからか。特徴量定義が変わらない限りは、on-demand変換したタイミングでfeature storeに保存しておけばそれで良いが、特徴量定義を変えたい場合はbackfillする必要がある、って話か...!)
-
過去のデータから特徴量をbackfillして再学習などする場合は、オンデマンド変換もfeature pipelineで実行できる必要があるので...!
- あれ、なんでfeature pipelineも含まれるんだっけ??
各種データ変換分類とdata skew防止
3種類全てのデータ変換について、異なるpipelineで同等の変換が実行できる必要があったりする。
- 具体的には...
- モデル非依存変換の場合は、batch/streamingのfeature pipeline。
- モデル依存変換の場合は、training/inference pipeline。
- オンデマンド変換の場合は、feature pipelineとreal-time inference pipeline。
- なので、複数のpipelineで同等の変換が実行されることを保証する必要がある。
- 変換方法に違いがある場合、モデルの性能バグが発生し、特定やデバッグも非常に困難になる。
- つまり、この辺りが整合するようにシステムを設計できてないと...data skew問題発生!
- モデル依存変換の場合は学習パイプラインと推論パイプラインで、on-demand変換の場合は推論パイプラインとfeature pipelineで、特徴量作成ロジックにズレが生じうる...!
- 学習時と推論時で data skew問題が発生する...!
- (モデル依存変換やオンデマンド変換の場合は、まあ特徴量生成処理をモジュール化して同じ関数を呼び出せるようにすると良いんだろうか...!)
- 例えばHopsworksだと、何らかこの辺りの実装の同等性をサポートする機能があるみたい。
Feature StoreとベクトルDBの違いは何??
- 両者の共通点:
- どちらもMLシステムで使われるデータ基盤
- ともに特徴量ベクトルを扱うが、目的や構造が異なる。
- Feature Storeの役割と構成
- 目的:
- 特徴量データの保存・再利用・取得(トレーニング・推論の両方)
- 主な機能:
- Point-in-timeな特徴量のクエリ
- オフライン&オンラインストアの分離
- モニタリング・バリデーション・バージョニング
- ストレージ構成:
- オフラインストア(列指向)
- オンラインストア(行指向, key-value store)
- 目的:
- ベクトルDBの役割と構成
- 目的:
- 類似ベクトル検索 (主に近似近傍探索、ANN)
- 主な機能:
- 類似アイテム・ユーザの検索
- 高次元空間における距離ベースの探索
- ストレージ構成:
- ベクトルインデックス(FAISS, ScaNNなど)
- → 高速なANN探索のために最適化された専用データ構造を使用
- 目的:
- 両者を統合したプラットフォームの例: Hopsworks
- Feature Store + Vector DB を統合的に提供
- Feature Groupにembedding列を含めて、ベクトルインデックスとして登録可能
- フィルタ付きのANN検索もサポート
- (ちなみにパッと見た感じ、Sagemaker Feature Storeは、特徴量定義としてベクトル型はあるが、ANNの機能はなさそう...??)
Feature Storeは必要か??
- 過去の特徴量ストアは...
- Uberの Michelangelo のような ビッグデータMLプラットフォームの一部
- 特徴ロジックの指定からパイプライン構築・運用までを含む、フルMLワークフロー管理ツール
- 最近の特徴量ストアは...
- オープンソース化が進み、Python / Spark / Flink / SQL など 既存のMLパイプラインとの統合が容易
- Serverless feature stores も登場し、小規模なチームでも採用しやすくなっている。
- ほとんどのMLチームが必要とする、Feature Storeの主要な機能(役割):
-
Point-in-time consistencyを保証した、統一された特徴量データの読み書きAPI
-
特徴量のバリデーション・監視
-
特徴量の「発見しやすさ」と「再利用しやすさ」(統一されたインターフェースで、一元管理されてることによる...!
) -
特徴量データのバージョン管理 / 時間軸でのトラッキング
-
それを踏まえると、意思決定最適化タスクではFeature Storeを導入するモチベーションは結構あると思った。
- (逆に言えば、特徴量がstaticなタスクだったり、学習時のデータリークが発生しづらいようなタスクだったら、Feature Storeを導入するモチベーションは一定下がりそう...?)
- (まあでもstaticな特徴量を使うタスクでも、Feature Storeを使うことで特徴量の「発見しやすさ」や「再利用しやすさ」が向上するので、MLのいろんなユースケースがあるなら導入するモチベーションはあるかも...!)
- (逆に言えば、特徴量がstaticなタスクだったり、学習時のデータリークが発生しづらいようなタスクだったら、Feature Storeを導入するモチベーションは一定下がりそう...?
-
以下は、ガイドの内容と付随して思ったことメモの詳細です。
そもそも特徴量とは? なんで専用の保存場所が欲しい??
- 特徴量(feature) = エンティティの数値的な属性で、学習/推論の入力として使うやつ!
- ある対象(entity)の属性(property)を数値化したもので、かつMLに役立つもの。
- 専用の保存場所が必要なモチベーション:
- その1: 「再利用」や「発見しやすさ」が重要だから(=開発効率up)
- 特徴量を保存することの利点の一部は、それらが簡単に発見され、異なるモデルで再利用しやすい状況を作れることである。
- それにより、新しいMLシステムを構築するために必要なコストと時間を削減できることである。
- (この観点は、まさにFeature Storeの役割って感じだ...!!)
- その2: リアルタイム推論時に、今来たリクエストだけじゃなく、事前計算したリッチな情報が必要だから (=モデルの精度up)
- オンラインモデルはlocal stateを持たない傾向があるらしい。
- (これってどういう意味だろ。local stateを持たない傾向、って部分。perplexityに相談してみた感じ、各ユーザやリクエストの履歴・状態をモデル本体やサーバーのメモリ内に溜め込まず、「今来たリクエスト」に含まれる情報だけをそのまま使う傾向がある、みたいな意味合いっぽい...!)
- (これってどういう意味だろ。local stateを持たない傾向、って部分。perplexityに相談してみた感じ、各ユーザやリクエストの履歴・状態をモデル本体やサーバーのメモリ内に溜め込まず、「今来たリクエスト」に含まれる情報だけをそのまま使う傾向がある、みたいな意味合いっぽい...!
- オンラインモデルはlocal stateを持たない傾向があるらしい。
- その1: 「再利用」や「発見しやすさ」が重要だから(=開発効率up)
Feature StoreとMLOps、MLシステムとの関連
-
MLOpsプラットフォームにおけるFeature Storeは、異なるMLパイプラインを結びつけて完全なMLシステムを作る接着剤の役割を持つ (FTI Pipelines Architectureの発想そのものじゃん...!
)- Feature Pipeline: 特徴量を計算し、特徴量およびlabel/targetをFeature Storeに書き込む。
- Training Pipeline: Feature Storeから特徴量およびlabel/targetを読み込み、MLモデルを学習する(学習されたモデルはmodel registryに書き込まれる)。
- Inference Pipeline: Feature Storeから特徴量を取得し、MLモデルを使って推論する。
- (メモ: 上記の内容って、思いっきりFTI Pipelines architectureの思想! Feature Storeを採用すること = FTI Pipelines Architectureを採用すること、と言って良さそう...!)
- (まあFTI Pipelines Architecture自体がHopsworksの人が提唱してる設計思想なので、ここが整合するのは当然かも...!)
-
MLOpsの主な目標 = モデル試行錯誤のiteractionを短縮し、モデルのパフォーマンスを向上させ、ML資産(特徴、モデル)のガバナンスを確保し、コラボレーションを改善すること。
- (ちなみに「MLOps処方箋本」のMLOpsの定義は「MLの成果をスケールさせるための取り組み」な訳だけど、上記を改善することがMLの成果のスケールに繋がるから、って解釈できそう...!)
- Feature Storeを採用すること(i.e. FTI Pipelines Architectureを採用すること)によって、この目標の達成につながるよ〜みたいな話かな
- (ちなみに「MLOps処方箋本」のMLOpsの定義は「MLの成果をスケールさせるための取り組み」な訳だけど、上記を改善することがMLの成果のスケールに繋がるから、って解釈できそう...!
Feature Store が解決する課題
Feature Storeが解決する課題として以下の11個が挙げられてた:
-
MLシステムのcollaborativeな開発を促進! (一元管理されてるので「発見」しやすいし、取得方法が統一されてるので「再利用」しやすいよね、って話か...!
) -
特徴量データのincrementalな管理 (本番MLシステムにおける特徴量は、一回作って終わりじゃなくて、incrementalに変化していくものなので...!
) -
特徴量のbackfillingと学習データのbackfilling (これは、Feature Storeは特徴量をevent_timeと一緒に管理するから実現できるよね、って話かな...?
) -
ステートレスなリアルタイム推論モデルにリッチな特徴量を供給 (これは前述してたlocal stateを持たない傾向、みたいな話!)
-
特徴量の再利用がしやすくなる (これは一元管理してるから
) -
特徴量の様々な計算パターンへの対応 (これも一元管理してるから? オンライン/オフラインストアを持つからか
) -
特徴量データのvalidationやドリフト監視がしやすくなる! (これは、feature pipelineが独立するからかな...!
) -
学習時と推論時の特徴量の計算方法のズレ(data skew)を防げる!
-
point-in-time consistency (時点整合性) を持つ学習データを作りやすくなる! (これはFeature Storeがevent_timeを元に特徴量を管理するから!
) -
リアルタイム推論時に、事前計算した特徴量を低レイテンシー提供 (これはオンラインストアを含むFeature Storeの話! 非対応のものもある印象...!
) -
埋め込みベクトルを使用したsimilarity search (これはFeature Storeがベクトル検索をサポートしてる場合! similarity search機能はサポートしてない場合も全然ありそう!
)
シナリオ別のFeature Storeの役立ちポイント例:
- バッチMLシステムの本番稼働シナリオ(2, 3, 7, 8, 9)
- リアルタイムMLシステムの本番稼働シナリオ(上記に加えて、4, 6, 10, 11)
- 大規模なML展開シナリオ(上記に加えて、1, 5)
補足1: Feature Storeがcollaborativeな開発をどう支えるか??
- 1点目: チームごと・開発者ごとの役割分担を可能にする。
- Feature Storeがあることで(i.e. FTI Pipelines Architectureであることで)、MLシステムの構築・運用をパイプライン単位に分解できるようになる。
- ex.)
- Feature Pipeline: データエンジニア・データサイエンティスト
- Training Pipeline: データサイエンティスト
- Inference Pipeline: ソフトウェアエンジニア、MLOpsエンジニア
- ex.)
- これによって、
- 各種パイプラインでやるべきことが明確化される
- Feature Storeをハブにして各パイプラインが独立して開発・運用できる
- したがって、チーム間・チーム内でスムーズに役割分担・連携しやすくなる!
- (メモ: 特徴量 x ルールベースによる推論だったら、Inference Pipelineを非MLチームのソフトウェアエンジニアが担当することも全然あり得るよね。...! 欲しい特徴量の取得方法が統一された方法でわかりやすければ...!)
- (メモ: 特徴量 x ルールベースによる推論だったら、Inference Pipelineを非MLチームのソフトウェアエンジニアが担当することも全然あり得るよね。...! 欲しい特徴量の取得方法が統一された方法でわかりやすければ...!
- Feature Storeがあることで(i.e. FTI Pipelines Architectureであることで)、MLシステムの構築・運用をパイプライン単位に分解できるようになる。
- 2点目: 共通言語が生まれる
- Feature Storeを中心に据えることで、チーム間で「Feature Pipeline」「Training Pipeline」「Inference Pipeline」っていう共通の言葉・設計思想を持てる!
- ex.) チームが構築しているのがバッチMLだろうとリアルタイムMLだろうと、開発者たちが「どうやって特徴量を管理してるか」を共通理解できるようになる! だから、チーム内・チーム間のコミュニケーションコストが下がる!
- (hogeパイプラインの入り口or出口は、まあFeature Storeだよね〜みたいな共通認識を持ちやすい、みたいな??:)
- (hogeパイプラインの入り口or出口は、まあFeature Storeだよね〜みたいな共通認識を持ちやすい、みたいな??:
- ML資産の共有とチーム内およびチーム間のコミュニケーションの改善が可能になる!
Feature Storeの各種データの保存場所について:
- historicalな特徴量データ(i.e. event_timeを持つバージョニングされた特徴量データ??)は、オフラインストア(通常は列指向データストア)に保存される。
- リアルタイム推論で使用される最新バージョン(i.e. event_timeが最新)の特徴量データは、オンラインストア(通常は行指向データストア or key-valueストア)に保存される。
- 個人的気づき: あ、オンラインストアに全ての特徴量を保存する必要はなくて、リアルタイム推論で使うもの、かつ最新のversionの特徴量レコードのみで良さそう...!!
- 最初オンラインストアのコストめっちゃ高くなりそうだと思ってた。でもオフラインストアの全てをオンラインに同期する必要はなくて、リアルタイム推論で使う特徴量、かつ最新のversionの特徴量レコードのみで良いんだよな...!
- 最初オンラインストアのコストめっちゃ高くなりそうだと思ってた。でもオフラインストアの全てをオンラインに同期する必要はなくて、リアルタイム推論で使う特徴量、かつ最新のversionの特徴量レコードのみで良いんだよな...!
ストレージ層におけるデータストアの選択について:
- 一部のFeature Storeサービスは、プラットフォームの一部としてストレージ層を提供し、一部は部分的または完全にpluggableなストレージ層を持つ。
- 前者の例: Sagemaker Feature Store, Google Cloud Vertex AI Feature Store, Snowflake Feature Storeなどのベンダー提供のマネージドサービス。
- 例えばSagemaker Feature Storeは、オフラインストアはS3上のParquet、オンラインストアはAWS Aurora(MySQL)で多分固定。
- 後者の例: FeastやHopsworks Feature StoreなどOSS系。
- Feastは、オフラインストアとしてBigQueryやSnowflakeやS3など、オンラインストアとしてRedisやDynamoDBなどをpluggableに取り替えできる感じ。
- 前者の例: Sagemaker Feature Store, Google Cloud Vertex AI Feature Store, Snowflake Feature Storeなどのベンダー提供のマネージドサービス。
また、予測ラベル(=もしくは報酬ログ的なもの。MLの出力側のデータ...!)もFeature Storeに保存するといいよ的なことも書いてあった!(特徴量/モデルの監視とデバッグしやすさの観点で!)
補足2: Feature Storeが特徴量のincrementalな管理をどう支えるか??
- feature pipelineは、MLシステムが稼働してる限り、特徴量を追加・更新し続ける (incremental dataset)
- Feature Storeがなければ、複数データストアへの整合性管理が大変になる。
- オフライン・オンライン・ベクトルDBが別々に存在してる場合、それぞれ認証・接続方法などが異なり、incremental datasetである特徴量について、それぞれのデータ同期を保つのは大変。
- Feature Storeはこれらをwrapして、統一的なCRUD(create/read/update/delete)インターフェースを提供してくれるので、可変な特徴量データセットの管理を容易にする役割を果たす。
- 同じfeature groupをストリーム処理クライアント(streaming feature pipeline)を使用して更新することもできる。(同じ特徴量グループを、バッチでもストリームでも更新できるよ、って話か。まあそりゃそうな気がする...!)
- 補足: Feature Storeでは、特徴量の論理グループを「feature group」や「Feature View」などと呼んでセットで管理することが多い。(ex. ユーザに関する特徴量は「user_feature_group」みたいな感じで)
- 同じfeature groupをストリーム処理クライアント(streaming feature pipeline)を使用して更新することもできる。(同じ特徴量グループを、バッチでもストリームでも更新できるよ、って話か。まあそりゃそうな気がする...!
補足3: Feature Storeが特徴量のbackfilling(および学習データのbackfilling)をどう支えるか??
(この章を読んで思ったこと: feature pipelineはbackfillできる必要がある。そのためには無状態 & 冪等性を持つパイプラインを意識すべき...!! ![]() )
)
(単一の実装をバッチでもストリームでも実行できるようにしておくのが運用上最強ってことでは..!![]() )
)
-
backfillingは、生の履歴データからデータセット(=特徴量や学習データセット...!)を再計算するプロセス。
-
これには、ユーザがbackfillするデータの範囲のためにstart_timeとend_timeを提供する必要がある。(feature pipelineを作るときは、無状態 & 冪等なデータパイプラインを意識すべき...!
)- 思ったことメモ:
- 毎回全ユーザ分の特徴量を作る系のfeature pipelineだったら、backfillはあくまで学習用データセットを作るため、という用途になりそう...!
- 特定期間内に追加・更新されたアイテムだけの特徴量を作る系(=streamingっぽい)のfeature pipelineだったら、学習用だけじゃなくて推論用のデータを作る目的でもbackfillしそう。
- まあすでに既存の特徴量パイプライン達が運用されてる状況だったらbackfillってのはあんまりする必要はなくて、どちらにせよ、特徴量グループに新しい特徴量を追加したり既存特徴量の作り方を変更した場合などにbackfillすることになるはず
-
backfill可能なデータパイプラインである為には、やはり無状態 & 冪等性を持つパイプラインを意識する必要がありそう...!
- 毎回全ユーザ分の特徴量を作る系のfeature pipelineだったら、backfillはあくまで学習用データセットを作るため、という用途になりそう...!
- 思ったことメモ:
-
また、ある特徴量のbackfillに使用されるfeature pipelineは、"live"データも処理できる必要がある
- そのための方法はシンプルで、単にfeature pipelineを、データソースとデータの範囲を指定できるようにすればOK。(要するに、わざわざ「backfill用の特別なパイプライン」を別で作るのはやめようね、って話だと思ってる! backfill時は、対象データ期間を「過去データの範囲に切り替えて」動かすだけ! )
- そのための方法はシンプルで、単にfeature pipelineを、データソースとデータの範囲を指定できるようにすればOK。(要するに、わざわざ「backfill用の特別なパイプライン」を別で作るのはやめようね、って話だと思ってる! backfill時は、対象データ期間を「過去データの範囲に切り替えて」動かすだけ!
-
バッチとストリーミングのfeature pipelineの両方が、特徴量をbackfillできる必要がある。
- (ストリーミングパイプラインもbackfillできるようにしておこうね、という話か...!ストリームのreplay設計っていうらしい...!)
- (でも結局、大量の期間のデータをbackifillする際には、バッチというかバルクで一気に処理できる設計になってた方がいいよな...単一のbackfill可能な実装をバッチでもストリームでも実行できるようにしておくのが運用上最強ってことでは...!)
- (ストリーミングパイプラインもbackfillできるようにしておこうね、という話か...!ストリームのreplay設計っていうらしい...!
-
特に学習データを作るという観点で、特徴量をbackfillできることは重要:
- 逆に、もし特徴量をbackfillできないと、既存特徴量の定義を変更したり新しい特徴量を追加した場合に、本番システムリリース後に特徴量ログを集め始めて学習データが十分に集まるのを待つ必要が出てきてしまう。
補足4: Point-in-time correctな学習データについて
- 時系列の特徴量データから未来のデータリークなしに学習データを作りたい場合、時点正確な結合(point-in-time correct join)と呼ばれる結合を行う必要がある。
- point-in-time correctな学習データじゃないと、推論時にモデル性能が悪化するし、その悪化の根本原因の特定も難しくなる。
- ちなみにブログ内では、以下の2種類をデータリークと呼んでた。
- 予測したい教師ラベルや報酬ログのtimestampよりも、未来の情報を含む特徴量を学習データに含めてしまうこと
- (こっちはThe データリークって感じだ...!)
- (こっちはThe データリークって感じだ...!
- 予測したい教師ラベルや報酬ログのtimestampよりも、古すぎる特徴量を使ってしまうこと。
- (これもデータリークって言うんだ...! 結局これって、推論時はもっと最新の特徴量を使うのに学習時はそれよりも古い特徴量を使ってしまってて、そこに差分というかdata skewが発生してしまってるのが問題、ってことかな...!!)
- (これもデータリークって言うんだ...! 結局これって、推論時はもっと最新の特徴量を使うのに学習時はそれよりも古い特徴量を使ってしまってて、そこに差分というかdata skewが発生してしまってるのが問題、ってことかな...!!
- 予測したい教師ラベルや報酬ログのtimestampよりも、未来の情報を含む特徴量を学習データに含めてしまうこと
- 思ったことメモ:
- 多くのFeature Storeは、特徴量をevent_time(=特徴量作成時のtimestamp)と一緒に管理することで、point-in-time correctな学習データを作れるようにしてる認識...!
- まあ自前で実装してもいいが、既存のFeature Storeサービスに任せられるなら楽だよなぁ...
- まあ自前で実装してもいいが、既存のFeature Storeサービスに任せられるなら楽だよなぁ...
- ちなみに推論時は、現在時刻を指定してpoint-in-time correct join(=最新のバージョンの特徴量を取得することになるはず!)して、推論用データを作ればよさそう!
- 多くのFeature Storeは、特徴量をevent_time(=特徴量作成時のtimestamp)と一緒に管理することで、point-in-time correctな学習データを作れるようにしてる認識...!
補足5: Feature Storeがリアルタイム推論をどうrichにするか??
- リアルタイム推論はstatelessなケースも多い。
- モデルはユーザリクエストだけを受け取り、その情報のみを元に、即時に推論を返す(状態は持たない)
- (まあ推薦タスクとかだと、ユーザの過去の履歴情報などを使いまくって推論することが多いから、あんまりステートレスなモデルはない気がするけど...!)
- (まあ推薦タスクとかだと、ユーザの過去の履歴情報などを使いまくって推論することが多いから、あんまりステートレスなモデルはない気がするけど...!
- 履歴や文脈情報(トレンドなど)を表す特徴量を事前計算してFeature Storeに保存しておくことで、リアルタイム推論モデルはオンラインストアから即座にrichな特徴量を取得して使用できる。
- 例: Tiktokでは、最近見た10本の動画に関する特徴(カテゴリ、視聴時間、友達の行動など)をオンラインストアに保持してるらしい。
- モデルはユーザリクエストだけを受け取り、その情報のみを元に、即時に推論を返す(状態は持たない)
- entityが単純とは限らない話(複合キーのサポートも必要?)
- (ここで"entity"って言ってるのは、特徴量の対象の概念。ex. ユーザやアイテムなど)
- 多くのケースでは単一のentity(user_idやitem_id)で十分。
- より高度な推薦やランキングタスクでは、(user_id, item_id)のタプルのような**複数カラムの主キー(複合キー)**が必要になる場合もある。
- ちなみに軽く触ってみた感じ、SageMaker Feature Storeは現時点では、特徴量を管理する上で複合キーは非対応っぽい...!
- feature groupを作成する際に、主キーを1つしか指定できないので。
- なので(user_id,item_id)単位の特徴量を管理したい場合は、
user_id|item_idのように文字列結合で擬似複合キーを作る工夫が必要になりそう...! - まあこれはどこもそうなのかも?
- ちなみに軽く触ってみた感じ、SageMaker Feature Storeは現時点では、特徴量を管理する上で複合キーは非対応っぽい...!
補足6: Feature Storeが特徴量の再利用をどう支えるか??
学習-推論間の特徴量の再利用の話:
-
最初のMLモデル構築では、特徴量作成が「場当たり的」になりがち。結果として、学習用と推論用で別々に特徴量作成処理を作ってしまいがち...!
- 学習用にCSVやDB直クエリなど、特注のスクリプトやETLで特徴量を作ることが多い。
- そのあと本番運用に入ると「推論のためにリアルタイムで同じ特徴量作る必要あるじゃん…」となって、別のパイプラインが作られがち。
- ex.)
- 最初にMLモデルを作るとき...「アプリケーションDBやDWHから直接データ引っこ抜いて…」「CSVこねくり回して…」「学習用の特徴量作った〜!やった〜!」
- その後にモデルを本番運用するとき...「あれ、リアルタイムで同じ特徴量を作る必要あるじゃん…」「推論時に必要な特徴量を作るために本番の別のパイプライン作らなきゃ…」
- Feature Storeがあると、特徴量の作成がfeature pipelineとして分離されることで、学習時に用意した特徴量をそのまま推論時にも再利用しやすくなる。
MLモデル間での特徴量の再利用の話:
-
MLモデルを使うユースケースが増えると、「同じ特徴量を何度も再計算」するようになる。
- 計算リソース・ストレージの無駄。また、コードが重複して非DRY(Don't Repeat Yourself)になり、保守が地獄になる。
- Feature Storeがあると、モデル間での特徴量の再利用が簡単になる!
- 一度作った特徴量はFeature Groupとして保存し一元管理 → 他モデルでもすぐ使える!
- Metaの事例: 「最も人気な100特徴量が100以上のモデルで再利用されてる」
- よって、特徴量を使い回す前提でシステムを設計した方が良い...!!
- よって、特徴量を使い回す前提でシステムを設計した方が良い...!!
- 「同じ特徴量を何度も再計算」に関連して思ったこと:
- 最近のNetflixさんのブログで、推薦基盤モデルの話があったけど、あれもモチベーションが近い気がした...! ユーザ行動履歴の学習を各MLモデルがそれぞれやってるので、その部分を共通の1つの基盤モデルが担うようにして、その成果物を下流モデルの初期パラメータや特徴量として使う、みたいな話だった。結局あれって、ユーザ行動履歴から興味を抽出する部分をfeature pipelineとして抜き出して、複数の下流モデルで再利用できるようにした、みたいな解釈もできそう...??
- 最近のNetflixさんのブログで、推薦基盤モデルの話があったけど、あれもモチベーションが近い気がした...! ユーザ行動履歴の学習を各MLモデルがそれぞれやってるので、その部分を共通の1つの基盤モデルが担うようにして、その成果物を下流モデルの初期パラメータや特徴量として使う、みたいな話だった。結局あれって、ユーザ行動履歴から興味を抽出する部分をfeature pipelineとして抜き出して、複数の下流モデルで再利用できるようにした、みたいな解釈もできそう...??
特徴量の再利用によって得られる恩恵:
- 恩恵1: 特徴量の品質が向上。多くのモデルで使われることで、レビューや改善が進む。
- (これはTeem Geekの「隠すとダメになる」的な話だ...!)
- (これはTeem Geekの「隠すとダメになる」的な話だ...!
- 恩恵2: ストレージと計算コストの削減。
- 恩恵3: パイプラインや本番コードの数が減る(DRYになるので)。結果としてメンテしやすくなる。
- 結果:Feature Storeは、本番環境で実行するモデルの数と、維持しなければならないfeature pipelineの数を切り離す。
- (この観点大事だ...! 言い換えるとFTI Pipelines Architectureの利点でもある!)
- 結果:Feature Storeは、本番環境で実行するモデルの数と、維持しなければならないfeature pipelineの数を切り離す。
- 恩恵4: 工数の削減
- Feature Storeが十分に整備されていれば、必要な特徴量がすでにFeature Storeにあるなら、新しいMLモデルのためにfeature pipelineを書く必要はなくなる。
補足: Feature Storeは特徴量データのvalidation & ドリフト監視をどう支えるか??
- 前提:
- 「Garbage In, Garbage Out」はMLにも完全に当てはまり、モデルの性能は入力データの品質に大きく依存する。よって、特徴量の品質チェックは必須である。
- 特徴量のvalidation = Feature Storeに書き込む前のチェック
- 特徴量パイプラインの出口 or Feature Storeへの書き込み時に実行する。
- (feature pipelineの最後のstepでvalidationを実行すれば良さそう...!)
- 特徴量の監視 = 保存後の変化・異常の検知
- Feature monitoringは、多くのFeature Storeが提供する便利な機能の一つ
- バッチMLシステムを構築する場合でもオンラインMLシステムを構築する場合でも、システムのモデルに対する推論データを監視し、それがモデルの学習データと統計的に有意に異なるかどうか(data drift)を確認できる必要がある。
- もし異なる場合は、ユーザ(=開発者)にアラートを通知し、理想的にはより最近の学習データを使用してモデルの再学習を開始するべき。
- ちなみに...Hopsworks Feature Storeの例:
- ドリフト検知のバッチが1日一回実行されるようになってるみたい。
- 推論時の特徴量の統計量が、学習時の同じ値から50%以上逸脱してた場合に、データドリフトが発生したとみなし、アラートをtriggerするような仕組みらしい。
- なるほどこの場合のデータドリフトの監視はバッチで行われるのか。こちらのブログで理想的にはこれもストリーミング的に実行される方が良いって見た覚えがある...!
補足: 特徴量に関する3種類のデータ変換とdata skew防止について
特徴量に関するデータ変換の3分類
特徴量に関するデータ変換(data transformation)の分類(Taxonomy)は3つある。
- 1つ目: model-independent transformation(モデル非依存変換)
- 2つ目: model-dependent transformation(モデル依存変換)
- 3つ目: on-demand transformation(オンデマンド変換)
それぞれの分類の特徴は以下の通り:
- 1つ目: model-independent transformation(モデル非依存変換)
- どのモデルでも再利用可能な、汎用的な特徴量を作る処理。
- 実行場所: feature pipeline (batch / streaming)
- モデル非依存変換は、feature pipelineの中でのみ実行されるべき(i.e. つまり学習 & 推論パイプラインには含まれるべきではない...!)
- 2つ目: model-dependent transformation(モデル依存変換)
- 各モデルの最適化に調整するような、モデル固有の前処理(ex. one-hot encoding, 欠損値補完, 0~1スケーリングなど)。
- (カテゴリ変数をone-hot encodingしたり、数値特徴量を標準化したり、欠損値を埋めたり...は、各モデルの精度を上げるために個別に細かくチューニングするもの...!)
- (カテゴリ変数をone-hot encodingしたり、数値特徴量を標準化したり、欠損値を埋めたり...は、各モデルの精度を上げるために個別に細かくチューニングするもの...!
- 実行場所: training pipeline / inference pipeline
- 各モデルの最適化に調整するような、モデル固有の前処理(ex. one-hot encoding, 欠損値補完, 0~1スケーリングなど)。
- 3つ目: on-demand transformation(オンデマンド変換)
- リアルタイム推論時、リクエストで受け取った情報からリアルタイムに特徴量を計算する処理。
- 実行場所: (real-time) inference pipeline / feature pipeline
- あれ、なんでfeature pipelineも含まれるんだっけ??
-
過去のデータから特徴量をbackfillして再学習などする場合は、オンデマンド変換もfeature pipelineで実行できる必要があるので...!
- (学習時にon-demand変換による特徴量も用意する必要があるからか。特徴量定義が変わらない限りは、on-demand変換したタイミングでfeature storeに保存しておけばそれで良いが、特徴量定義を変えたい場合はbackfillする必要がある、って話か...!)
-
過去のデータから特徴量をbackfillして再学習などする場合は、オンデマンド変換もfeature pipelineで実行できる必要があるので...!
- あれ、なんでfeature pipelineも含まれるんだっけ??
各種データ変換分類とdata skew防止
3種類全てのデータ変換について、異なるpipelineで同等の変換が実行できる必要があったりする。
- 具体的には...
- モデル非依存変換の場合は、batch/streamingのfeature pipeline。
- モデル依存変換の場合は、training/inference pipeline。
- オンデマンド変換の場合は、feature pipelineとreal-time inference pipeline。
- なので、複数のpipelineで同等の変換が実行されることを保証する必要がある。
- 変換方法に違いがある場合、モデルの性能バグが発生し、特定やデバッグも非常に困難になる。
- つまり、この辺りが整合するようにシステムを設計できてないと...data skew問題発生!
- モデル依存変換の場合は学習パイプラインと推論パイプラインで、on-demand変換の場合は推論パイプラインとfeature pipelineで、特徴量作成ロジックにズレが生じうる...!
- 学習時と推論時で data skew問題が発生する...!
- (モデル依存変換やオンデマンド変換の場合は、まあ特徴量生成処理をモジュール化して同じ関数を呼び出せるようにすると良いんだろうか...!)
- 例えばHopsworksだと、何らかこの辺りの実装の同等性をサポートする機能があるみたい。
Feature StoreとベクトルDBの違いは何??
- 両者の共通点:
- どちらもMLシステムで使われるデータ基盤
- ともに特徴量ベクトルを扱うが、目的や構造が異なる。
- Feature Storeの役割と構成
- 目的:
- 特徴量データの保存・再利用・取得(トレーニング・推論の両方)
- 主な機能:
- Point-in-timeな特徴量のクエリ
- オフライン&オンラインストアの分離
- モニタリング・バリデーション・バージョニング
- ストレージ構成:
- オフラインストア(列指向)
- オンラインストア(行指向, key-value store)
- 目的:
- ベクトルDBの役割と構成
- 目的:
- 類似ベクトル検索 (主に近似近傍探索、ANN)
- 主な機能:
- 類似アイテム・ユーザの検索
- 高次元空間における距離ベースの探索
- ストレージ構成:
- ベクトルインデックス(FAISS, ScaNNなど)
- → 高速なANN探索のために最適化された専用データ構造を使用
- 目的:
- 両者を統合したプラットフォームの例: Hopsworks
- Feature Store + Vector DB を統合的に提供
- Feature Groupにembedding列を含めて、ベクトルインデックスとして登録可能
- フィルタ付きのANN検索もサポート
- (ちなみにパッと見た感じ、Sagemaker Feature Storeは、特徴量定義としてベクトル型はあるが、ANNの機能はなさそう...??)
Feature Storeは必要か??
- 過去の特徴量ストアは...
- Uberの Michelangelo のような ビッグデータMLプラットフォームの一部
- 特徴ロジックの指定からパイプライン構築・運用までを含む、フルMLワークフロー管理ツール
- 最近の特徴量ストアは...
- オープンソース化が進み、Python / Spark / Flink / SQL など 既存のMLパイプラインとの統合が容易
- Serverless feature stores も登場し、小規模なチームでも採用しやすくなっている。
- ほとんどのMLチームが必要とする、Feature Storeの主要な機能(役割):
- Point-in-time consistencyを保証した、統一された特徴量データの読み書きAPI
- 特徴量のバリデーション・監視
- 特徴量の「発見しやすさ」と「再利用しやすさ」(統一されたインターフェースで、一元管理されてることによる...!)
- 特徴量データのバージョン管理 / 時間軸でのトラッキング