これはなに?
本記事は、インターン先の論文読み会で発表した内容「ABテストする前に機械学習モデルの性能を確度高く評価したいけど、皆どうやってるんだろう?について色々調べている話」を、n週連続推薦システム系 論文読んだシリーズ25週目 (番外編)としてまとめなおしたものです!
↑のlinkの発表資料ではスライド形式になっているので、スライド形式が好きな方はそちらの方が読みやすいと思います!

参考文献:
- usaitoさんの資料: Off-Policy Evaluationの基礎とOpen Bandit Dataset & Pipelineの紹介
- 大規模行動空間におけるOPEの論文: Off-Policy Evaluation for Large Action Spaces via Embeddings
- 複数のオフラインmetricsからオンライン性能を予測する論文: Predicting Online Performance of News Recommender Systems Through Richer Evaluation Metrics
- netflixのtechブログ: Innovating Faster on Personalization Algorithms at Netflix Using Interleaving
- naiveだけど有効なオフライン評価方法をしてた contextual bandit の論文: A contextual-bandit approach to personalized news article recommendation
- 宿泊予約サービスbooking.comの機械学習モデルの開発運用で得た教訓をまとめた論文(KDD2019) 150 Successful Machine Learning Models: 6 Lessons Learned at Booking.com
今回のテーマを選んだ経緯
- ビジネス上のタスクに機械学習を適用する上で、オフライン評価とオンライン評価の結果が乖離しがち問題。(ex. 推薦や検索、広告配信等の意思決定タスク)
- booking.comの論文でも、機械学習モデルの開発運用で得た教訓の1つとして以下の様に言っていた:
A very interesting finding is that increasing the performance of a model, does not necessarily translates to a gain in value.

(booking.comの論文より引用) 図4. Relative difference in a business metric vs relative performance difference between a baseline model and a new one.
「オフラインでのモデル性能の推定値(横軸)」と「RCTで観察されたビジネス指標(縦軸)」に相関がない。
ただやっぱり、"オフライン評価できると嬉しい"...!
ABテストする前に機械学習モデルの性能を確度高く評価できたらどんな点が嬉しい?
できる場合
- ABテスト前に有効そうな施策を絞り込む事ができ、仮説 -> 施策 -> 検証をより高速に回す事ができる。
- ハイパーパラメータチューニングができる。
- ユーザ体験を悪化させ得る施策を、オンライン環境に出す前に検知する事ができる。
できない場合
- 全ての仮説に対してABテストする必要があり、仮説 -> 施策 -> 検証の速度が下がる。(ABテストの運用コストを下げても、どうしてもオフライン実験するよりは時間がかかる。どんなに高速化しても10倍くらいかかる?
 )
) - 誤った基準でハイパーパラメータチューニングしてしまう可能性。
- ユーザ体験を悪化させ得る施策を、オンライン環境に出す可能性。
色々調べたオフライン評価の確度をあげるアプローチ達
- 1 理論的に保証されてる!: Off-Policy Evaluation手法を用いて過去のログデータからオンライン性能を推定(@ ファッションアイテムの推薦)
- 2 力技!: オフライン観測可能なmetricsからオンライン性能の予測モデルを作る(@ ニュース記事の推薦)
- 3 naiveだけど導入しやすさと効果は高そう: 一定期間のみ、一様ランダムなモデルを本番適用してログデータ収集 (@ ニュース記事の推薦)
- 4 より高速なオンライン評価手法 Interleaving をABテストの前に導入する(@ 動画の推薦)
今日は主にアプローチ1について紹介し、アプローチ2 ~ 4はさらっと紹介程度の予定。
調べた方法1. 理論的に保証されてる!: Off-Policy Evaluation手法を用いて過去のログデータからオンライン性能を推定(@ ファッションアイテムの推薦)
- 自分はusaitoさん & wantedlyさんの勉強会に参加してこのOff-Policy Evaluation(以下、OPE) 分野を知った。
- 今回は概要紹介 & 自分の感想を話すので、更に詳しくはusaitoさんの資料やOPE関連の論文を読むと良さそう!
Off-Policy Evaluation(OPE)とは?
OPEは新しいpolicyを製品に導入することなく、その性能を正確に評価する事を目的とした方法論。具体的には、稼働中の意思決定システム logging policy $\pi_{0}$ で得たログを使って、施策 target policy $\pi$ のオンライン性能を推定したい。
OPE文献で用いられるnotation
- $\mathbf{x} \in X$: contextベクトル(モデルに入力する特徴量...!)
- $a \in A$: 意思決定タスクにおいて選択される行動(action)。基本的には離散変数。$A$ は行動空間。
- $\pi(a|\mathbf{x})$: 意思決定policyが context $\mathbf{x}$ を受け取って行動 $a$ を選択する確率。
- $r \sim p(r|\mathbf{x}, a)$: 選択された行動に基づいて得られる報酬(reward)(ex. click, 購入, 翌週も継続利用してくれる)
強化学習っぽいnotation...!Off-Policy Learningという分野もあるっぽいし、 contextual banditを想定したOPE論文が多い印象...!![]()
OPEが解きたい問題:
まず、任意の意思決定policyの性能を以下の様に定義(=要は報酬の期待値!![]() ):
):
V(\pi)
:= \mathbb{E}_{p(\mathbf{x})\pi(a|\mathbf{x})p(r|\mathbf{x},a)}[r]
= \mathbb{E}_{p(\mathbf{x})\pi(a|\mathbf{x})}[q(\mathbf{x},a)]
ここで $q(\mathbf{x}, a) := \mathbb{E}[r|\mathbf{x}, a]$ は、あるcontext $\mathbf{x}$ において行動 $a$ を選択した場合の報酬 $r$ の期待値。
(ex. 報酬 $r$ をclickするか否かと定義した場合は、$V(\pi)$ はCTRになる![]() )
)
OPEでは、$\pi_{0}$ で得られた過去の $n$ 個のログデータ $D := {(\mathbf{x}_i, a_i , r_i)}_{i=1}^{n}$ のみを用いて、($\pi_{0}$ とは異なる) $\pi$ の性能 $V(\pi)$ を高い精度で推定したい。その為にOPE推定量 $\hat{V}(\pi)$ を開発したい。
そしてOPE推定量の精度は、MSE(平均二乗誤差)によって定量化される:
$$
MSE(\hat{V}(\pi)) = \mathbb{E}_{D} [(V(\pi) - \hat{V}(\pi;D))^2]
$$
各OPE推定量を比較する為の視点: biasとvariance
OPE推定量の評価に用いるMSE(平均二乗誤差)は、以下の様に $(推定量のbias)^2$ と $(推定量のvariance)$ に分解できる。
MSE(\hat{V}(\pi)) = \mathbb{E}_{D} [(V(\pi) - \hat{V}(\pi;D))^2]
\\
= Bias[\hat{V}(\pi)]^2 + \mathbb{V}_{D}[\hat{V}(\pi;D)]
よって、各OPE推定量の良し悪しを比較する際はbiasとvarianceに注目すると良いらしい。
(ex. 推定量Aは biasは小さいがvarianceが大きい。推定量Bはbiasは大きいがvarianceが小さい)
代表的な3つのOPE推定量
基本的にこれら3つのOPE推定量が、OPE研究の基礎になっているらしい:
- DM(Direct Method)推定量
- IPS(Inverse Propensity Scoring)推定量
- DR(Doubly Robust)推定量
この3つのOPE推定量さえ抑えておけば、他の多くのOPE論文が読みやすいはず...!

(usaitoさんの資料より引用)横軸=観測データ数 $n$, 縦軸=各OPE推定量の真の値とのMSE(bias^2 + variance)の図
代表的なOPE推定量① DM(Direct Method)
過去の観測データから事前に報酬期待値 $q(\mathbf{x}, a) := \mathbb{E}[r|\mathbf{x}, a]$ の予測モデル $\hat{q}(\mathbf{x}, a)$ を学習しておき、それをOPEに用いる。
\hat{V}_{DM}(\pi;D) = \frac{1}{n} \sum_{i=1}^{n} \mathbb{E}_{\pi}[\hat{q}(\mathbf{x}_{i}, a)]
- 特徴: OPEの精度が報酬予測モデル $\hat{q}$ に大きく依存する為、biasは大きい。一方でvarianceは小さい。
- ただそもそも精度の良い報酬予測モデル $\hat{q}$ を作れる時点で、それを使った意思決定policyを運用すれば良いので、OPEとしての実用性は低め。
代表的なOPE推定量② IPS(Inverse Propensity Scoring)
観測された各報酬 $r_i$ を、logging policy による行動の選ばれやすさ(=propensity score) の逆数で観測報酬を重み付けしたOPE推定量。
\hat{V}_{IPS}(\pi;D)
= \frac{1}{n} \sum_{i=1}^{n} \frac{\pi(a_i|\mathbf{x}_i)}{\pi_{0}(a_i|\mathbf{x}_i)} r_{i}
- biasは小さい(=仮定を満たせば不偏: $\mathbb{E}_{D} [\hat{V}_{IPS}(\pi)] = V(\pi)$) 。
- データ数nが小さい時は分散が大きく不安定だが、nが大きくなるにつれ真の値に収束。
- 先進的なOPE推定量の多くがこのIPS推定量に基づいており、重要なOPE推定量。
- $\frac{\pi(a_i|\mathbf{x}_i)}{\pi_{0}(a_i|\mathbf{x}_i)}$ を重要度重みと呼ぶ。
(usaitoさんの資料より引用)横軸=観測データ数 $n$, 縦軸=真の値とのMSE(bias^2 + variance)の図
代表的なOPE推定量③ DR(Doubly Robust)
DMとIPSを組み合わせた推定量。
DM推定量をベースラインとしつつ、報酬期待値予測モデル $\hat{q}$ の誤差をIPS重み付けで補正している。
\hat{V}_{DR}(\pi;D) = \hat{V}_{DM}(\pi;D)
\\
+ \frac{1}{n} \sum_{i=1}^{n} (r_{i} - \hat{q}(\mathbf{x}_i, a_i)) \frac{\pi(a_i|\mathbf{x}_i)}{\pi_{0}(a_i|\mathbf{x}_i)}
- 特徴: DM推定量の性質により $n$ が小さい時のvarianceを抑えつつ、IPS推定量の性質(=仮定を満たせば不偏)を受けて真の値に収束していく。
(usaitoさんの資料より引用)横軸=観測データ数 $n$, 縦軸=真の値とのMSE(bias^2 + variance)の図
大規模行動空間を持つ意思決定タスクでOPEが難しい問題
行動空間が小さい(=行動の選択肢が少ない)場合、IPS推定量に基づく信頼性の高い手法が多く登場した。
しかしこれらの手法は、行動空間が大きい程、真のpolicy性能に対する Bias と Variance がどんどん増える可能性がある。(=後述するIPSの仮定を満たせなくなるから!)
(論文読んでた感じでは、行動数が1000を超えたくらいから"大規模行動空間"と言えるのかな![]() )
)
よって、大規模行動空間に耐えうるOPE推定量は最近のOPE研究の主要なトピックらしい。
先日の勉強会でusaitoさんが紹介されてた「大規模行動空間に耐えうるOPE推定量の開発」の論文を読み、概要と感想を紹介します..!
IPS推定量が不偏推定量になる為の仮定
IPS推定量 $\hat{V}_{IPS}(\pi;D)$ は、以下のCommon Support Assumptionを満たした場合に真の性能 $V(\pi)$ に対して不偏になる:
$$
\pi(a|\mathbf{x}) > 0 \rightarrow \pi_{0}(a|\mathbf{x}) > 0, \forall a \in A, \mathbf{x} \in X
$$
つまり、「target policy $\pi$ がsupportする(=選択し得る)全ての行動を、logging policy $\pi_{0}$ もsupportしていてくれ!」という仮定...!
大規模行動空間であるほどこの仮定が成立しづらくなり、IPS推定量の bias & variance が増大していく。
この仮定って、 $\pi_{0}$ が決定論的な意思決定policyの場合(= context $\mathbf{x}$ が定まると選択する行動 $a$ が一意に定まるpolicy)、基本的には成立できないよなぁ![]()
逆に、 $\pi_{0}$ が全てのcontext $\mathbf{x}$ に対して全ての行動 $a$ を選び得る場合(ex. 一様ランダムに行動を選ぶpolicy)は仮定が成立するので、観察データさえ増やせばIPS推定量で真の性能を確度高く推定できるはず...!![]()
大規模行動空間に耐えうるOPE推定量: MIPS推定量の提案
論文では、大規模行動空間に耐えうるOPE推定量として、IPS推定量の行動 $a$ を action embedding $\mathbf{e}$ (i.e. 行動の特徴量みたいな!![]() ) で置き換えた Marginalized IPS(MIPS)推定量を提案。
) で置き換えた Marginalized IPS(MIPS)推定量を提案。
\hat{V}_{MIPS}(\pi:D)
= \frac{1}{n} \sum_{i=1}^{n} \frac{p(e_i|x_i, \pi)}{p(e_i|x_i, \pi_{0})} r_{i}
(IPSではlogging policy $\pi_{0}$ が行動 $a$ を選ぶ確率で重み付けしていたが、MIPSでは 行動の特徴 $\mathbf{e}$ を選ぶ確率で重み付けする...!)
MIPS推定量が不偏推定量になる為の仮定
MIPS推定量が不偏になる為の条件として、以下の "Common Embedding Support Assumption" を満たす必要がある:
p(e|x, \pi) > 0 → p(e|x, \pi_{0}) > 0, \forall e \in E, x \in X
大規模行動空間では、前述のcommon support assumption よりも common embedding support assumption の方が遥かに成立させやすい。
(全く同じ行動をsupportしてなくても、特徴が似た行動をsupportしていればOK!)
(MIPSが不偏推定量になる為の条件はもう一つあるが割愛:No Direct Effect仮定)
(ただ結局この仮定も、logging policy $\pi_{0}$ が決定論的なモデルの場合はかなり厳しいんだよなぁ...。OPEの観点では決定論的な推薦モデルはご法度というか、かなり扱いづらそうな印象![]() )
)
(ぼやき)決定論的なモデルはなぁ...
決定論的なモデル用のIPS推定量の式もあるので無理じゃないんだろうけど、logging policy $\pi_{0}$ とtarget policy $\pi$ が相当似てる場合を除いて、IPSが不偏推定量になる仮定を満たせないよなぁ。。。
(以下は、$\pi$ が決定論的モデルver.の各種OPE推定量の式。元の式の特殊なケース)
\hat{V}_{DM}(\pi;D)
= \frac{1}{n} \sum_{i=1}^{n} \hat{q}(\mathbf{x}_{i}, \pi(\mathbf{x}_{i}))
\hat{V}_{IPS}(\pi;D)
= \frac{1}{n} \sum_{i=1}^{n} \frac{\mathbb{I}[\pi(\mathbf{x}_{i}) = a_i]}{\pi_{0}(a_i|\mathbf{x}_i)} r_{i}
\hat{V}_{DR}(\pi;D) = \hat{V}_{DM}(\pi;D)
\\
+ \frac{1}{n} \sum_{i=1}^{n} (r_{i} - \hat{q}(\mathbf{x}_i, a_i)) \frac{\mathbb{I}[\pi(\mathbf{x}_{i}) = a_i]}{\pi_{0}(a_i|\mathbf{x}_i)}
ちなみにOPEの実験はこんなデータがあればいいらしい!
(再掲)
OPEは、logging policy $\pi_{0}$ で収集した過去の $n$ 個のログデータ $D := {(\mathbf{x}_i, a_i , r_i)}_{i=1}^{n}$ のみを用いて、($\pi_{0}$ とは異なる) target policy $\pi$ の性能を推定する。
- → policy A で収集した $D_{A}$ と policy B で収集した $D_{B}$ さえ用意できれば、推定値 = $\hat{V}(\pi_{A}; D_{B})$ と真の値= $V(\pi_{A};D_{A})$ を比較してOPE推定量の実験ができる!
- → ABテストの際に得られるログデータを使えば、自社の環境に適したOPE推定量を探したりできそう!
- ちなみに、オープンソースのOPE実験用データセットにはOpen Bandit Datasetがある: ZOZOTOWNの推薦枠で収集されたオンライン実験データ
調べた方法2. 力技!: オフライン観測可能なmetricsからオンライン性能を予測する回帰モデルを作る(@ ニュース記事の推薦)
オフライン指標 -> オンライン性能の予測モデルを作る
- 推薦タスクでは、MAPやnDCG等のランキング精度指標に加えて、beyond-accuracyな指標も多く提案される(ex. Diversity, Coverage, Novelty)
- 上記のオフライン指標郡からオンライン性能(ex. CTR)の予測モデルを作るオフライン評価方法を提案。
- オンライン性能の予測と、対象製品においてオンライン性能の向上に寄与するオフライン指標(i.e. どんな性質を持つ推薦結果を出してあげたらユーザは嬉しいの?) の探索を目的とする。

オンライン性能予測モデルを用いた最良アルゴリズム選択ワークフロー(論文より引用)
- 力技でシンプル。決定論的な推薦モデルでも適用しやすい気はする
調べた方法3. naiveだけど導入しやすさと効果は高そう: 一定期間のみ、一様ランダムなモデルを本番適用してログデータ収集 (@ ニュース記事の推薦)
- 2011年のyahooさんの論文。(自分のまとめ記事)
- 論文の内容はOPE関連ではないが、実験方法がオフライン評価方法としてnaiveだが効果的だと思い紹介。
一定期間、一様ランダムなモデルを本番適用
- 推薦枠の内の1箇所に、選択ロジックとして一様ランダムなpolicyを適用し(=logging policy $\pi_{0}$)、評価用データを収集してた。
- オフライン評価難しい問題の、一番シンプルな解決策かも??複数の推薦枠のうち、1つだけ一様ランダムにしてもユーザへの悪影響は大きくない気がするし...!
- 1週間とか1ヶ月とかのみ、推薦枠の1箇所のみ、であれば実際に適用可能性あるのでは...? その試用期間で得られたログデータをオフライン評価で使い続ければ良いし。
- $\pi_{0}$ が全ての行動を一様ランダムに選択するならば、IPSもMIPSも不偏推定量になる仮定を満たせるし、そもそもこれらのOPE推定量でbiasを取り除く必要すらない
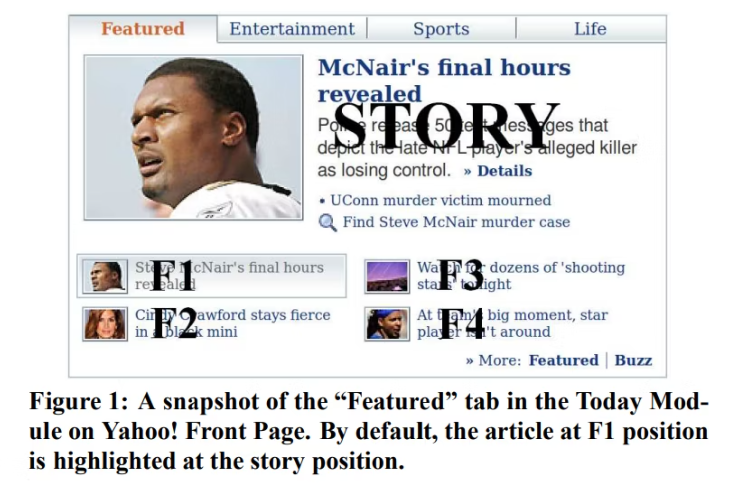
(論文より引用, 図2)4つの推薦枠の内、一箇所(F1)のみに一様ランダムな意思決定policyを適用
調べた方法4. より高速なオンライン評価手法 Interleaving をABテストの前に導入する(@ 動画の推薦)
Interleaving をABテストの前に導入する
- Netflixの推薦システムでは、ABテスト前にInterleavingによる初期絞り込みオンライン実験を採用してる話。
- 本内容はオフライン評価ではないが、「短期間で多くのモデル候補の中から、ABテストするに値するモデルを絞り込む(刈り込む)」という点が共通しているので紹介。
- Interleavingは、推薦や検索などのランキングモデルに対するオンライン評価方法の一種。複数のモデルが出力したランキングを Interleaveする(交互に混ぜ合わせる)。同一ユーザに対して複数のモデルの比較が可能で、性能を相対評価する。

(ブログより引用, 図2)Interleavingによるアルゴリズム改善の高速化

(ブログより引用, 図3)ABテストとInterleavingの比較
まとめ
- ABテストする前に機械学習モデルの性能を確度高く評価できたら色々嬉しいけど、皆どうやってるんだろう?について色々調べている。
- OPE推定量を使う -> logging policy が確率的なモデルだったらかなり効果的そう...!!
- 逆に、logging policyが決定論的なモデルの場合は、OPE推定量の活用はむずそう...?
- 検索や推薦タスクの場合は、ABテスト前にInterleavingの導入もあり。
- 今後論文を読む上で思ったこと。
- 論文のオフライン実験結果を過信しない方がいいかも。
- オンライン実験の結果が載っていたとしても、それはその会社のビジネスの特定のusecaseにおいて良い結果だった、というだけなので、自社への適用可能性はまた別の話。
- 結局は、自社のusecaseのデータを用いてシミュレーションしたりオンライン実験したりして、自社にとって良いモデルを作り上げていくしかないよなぁ...。
- 高速にモデルを評価できる基盤と、有効そうな手法を取捨選択できる嗅覚がほしい...!