概要
論文メモでは、読んだ論文の概要をゆるーくまとめていきます。
今回読んだ論文は、Robust Video Super-Resolution with Learned Temporal Dynamics(2017)という、
動画像における超解像手法の提案論文です。
深層学習を用いた動画像超解像手法としては大体3番目くらいに古い提案手法です。
ここらへんの論文から急に複雑な構造になってます...
タイトルだけを見ると???という感じなので、内容を以下にまとめていきます。
目次
- 研究の出発点
- 研究手法
- アルゴリズムの流れ
- 結果
- 読んだ感想
- 参考文献
1. 研究の出発点
①動画像の超解像には、空間軸と時間軸の両方の関係が必要である。
これに関しては例を挙げると分かりやすいと思います。
空間軸でいうと、どこの位置にどんな物体が映っているかとかです。
時間軸は、$t$秒後と$t+1$秒後での変化はどんな感じかとかです。
これを画像処理の世界では各画素の画素値で把握しています。
②人間の視覚システムが動きに敏感なので、時間軸における関係が動画像の超解像でもより重要である。
これは、空間軸よりも時間軸がより重要であると著者らは考えてたということです。
動きに敏感なのは、日常生活とかでもなんとなーく想像できるのではないかと思います。
カフェで近くの席の人が席を立ったらそっち見ちゃうみたいなやつです。笑
だから、超解像ではオプティカルフローを求めたり動き補償を求めたりすることが多いということですね。
2. 研究手法
時間軸における関係性を適切に選択でき、なおかつ精細な映像を出力する超解像手法の開発、および実験。
もう少し具体的に言うと、様々な種類の映像に対して連続するフレームの情報を上手く使用してより精細な映像を出力できるようにするということです。
ニューラルネットワークを用いて実装を行っています。
3. アルゴリズムの流れ
アルゴリズムの流れは以下の図の通りです。(図は論文から引用)

主にSpatial alignment netとTemporal adaptive netの2つのアルゴリズムから構成されています。
Spatial alignment netは、画像の前処理のアルゴリズム、Temporal adaptive netは画像を高解像度化させるアルゴリズムと考えると分かりやすいかと思います。
また、 LR reference frameは、高解像度化したいLRフレーム、LR source frameは、LRフレームと同時に入力する近傍フレームを示しています。
以下で、それぞれのアルゴリズムについて触れていきます。
①Spatial alignment net
Spatial alignment netの構成は先ほどの図にも示されている通り、点線で囲まれた箇所です。
以下の図では、点線箇所だけを切り取って表示しています。(図は論文から引用)

ここでは、3つの処理を経てデータ前処理を行い、モデルに入力する画像を生成します。
順番としては、
- Localization net: $\hat{\theta}_{st}$を計算。
- MSE Loss:最小となる $\hat{\theta}_{st}$を計算。
- ST Layer:画像に処理を行い、入力データの生成
こんな感じの流れになります。
それぞれの流れについてもう少し詳しく説明していきます。
Localozation net
Localozation netでは、ニューラルネットワークを用いて、
LR reference frameとLR source frameから時間における移動量のパラメータ $\hat{\theta_{st}}$を求めます。
オプティカルフローみたいなのをイメージすると分かりやすいと思います。
実際に、$\theta_{st}$はオプティカルフローを計算して出力したパラメータです。
Localozation netの意図としては、今まで人力で求めてきたオプティカルフローのような移動量をニューラルネットワークに任せてしまおう!というようなことだと思います。(結局 $\hat{\theta_{st}}$を求めるのに計算してるので意味ない気もしますが...)
MSE Loss
$\hat{\theta_{st}}$をニューラルネットワークで求めるので、MSE Lossで$\hat{\theta_{st}}$の値をチューニングしています。
MSE Lossは、Mean Square Errorの略称で、平均二乗誤差を計算します。
ニューラルネットワークの損失関数として最も使用されており、深層学習ではこの損失関数の値が小さくなるように学習されます。
MSE Lossの式は、
$E=\frac{1}{N}\sum_{i=0}^{N} ( \hat{\theta_{st}}- \theta_{st})^2 $
で表すことができ、$N$は学習に使用したデータ数、$\hat{\theta_{st}}$はニューラルネットワークで求めた予測値、$\theta_{st}$はオプティカルフローなどで求めた正解値となります。
ST Later
ここでは、LR source frame(LRフレームと同時に入力する近傍フレーム)に計算して求めた$\hat{\theta_{st}}$を適応させます。
これは、全ての入力画像に対して処理を行います。
②Temporal adaptive net
ここで、やっと超解像のアルゴリズムに突入します。
超解像のアルゴリズムの概要図は以下の通りです。(図は論文から引用)
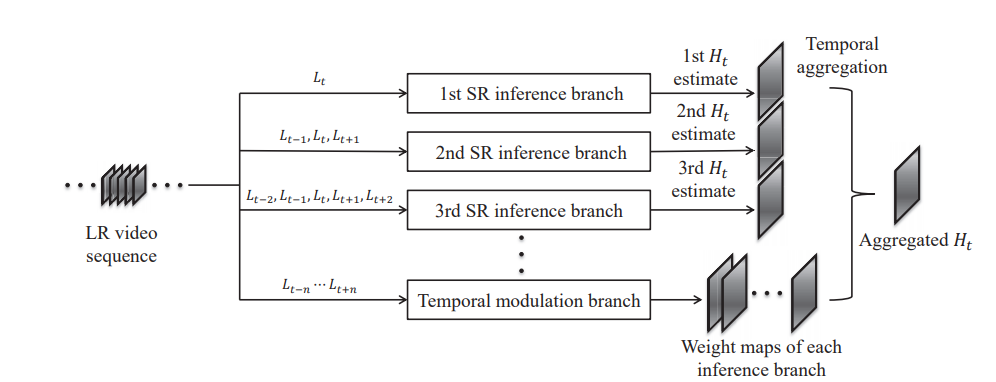
こちらも3つのパートに分かれています。
- SR inference branch:高解像度画像の候補を出力。
- Temporal modulation branch:weight mapの出力。
- Temporal aggregation:最終的な結果の出力。
こんな感じの流れになります。
それぞれの流れについてもう少し詳しく説明していきます。
SR inference branch
高解像度画像の候補を出力するパートです。
入力するフレーム数に応じて、複数のbranchを生成します。
入力フレーム数を $N$ 枚とすると、$2x - 1 = N$ となる $x$ の数だけbranchを生成します。
例えば、入力画像が5枚だと、branchの数は3つです。
ただし、入力フレームは必ず奇数になるようにします。
ここはニューラルネットワークを用いて高解像度化させています。
モデルはESPCNを使用しています。
入力フレームが複数なので、それに対応できるように少し調整をしていますが、ほとんど同じです。
ESPCNについては、以前実装記事 (超解像手法/ESPCNの実装) を書いていますのでよければそちらもご覧ください。
Temporal modulation branch
weight mapを出力するパートです。
weight mapとは、各画素における重みを集約したものとなります。(いい説明思いつかないですね...)
ここの構造もニューラルネットワークを用います。
ESPCNと似たモデルを用いると書いていますが、詳細は書かれていなかったような気がします。
weight mapは、SR inference branchの数だけ出力します。
つまり、高解像度化された画像のそれぞれにこのweight mapを適応させるということです。
Temporal aggregation
SR inference branchで生成した高解像度画像の候補と、Temporal modulation branchで生成したweight mapをそれぞれ乗算します。
最後に乗算するので、Temporal modulation branchのweight mapの数はbranchの数と同じにしたということです。
最後に、乗算した結果を全て足し合わせたものを最終的な結果とします。
これで全ての処理が終わりです。長かった!
4. 結果
この手法では、既存の超解像手法よりも精細な画像の出力に成功しています。
以下は、他手法との比較図です。(図は論文から引用)

一番右のProposedが提案手法です。
視覚的に見てもかなり高周波成分が復元されているのが分かります。
5. 読んだ感想
高解像度化 = モデルの複雑化 という関係が成立しているなという印象が残りました。
VSRnetやESPCNは、3層のCNNから構成されていて(ESPCNはPixel shuffleもある)、かなりモデルとしてはシンプルです。
しかし、動き補償のような時間関係を結果に結びつけるために色々な処理を施しているため、提案手法では複雑になってしまっています。
シンプルで高解像度化を図れるモデルを作ることがこの分野の永遠の課題ですね...