はじめに
OpenAIから公開されているAgentKitは皆さんお使いでしょうか。
AgentKitとは、マルチエージェントワークフローの構築からデプロイまでを容易に行うことが出来るフレームワークです。
AgentKitの登場により簡単にマルチエージェントワークフローをWebフロントに組み込むことが出来るようになりました。
AgentKitの不便な点
現在業務でAgentKitを活用している私ですが、AgentKitで不便に思っている箇所があります。
それは生成AIが作成したファイルをチャット上からダウンロードできない点です。
例えば、生成AIにPower Pointのファイルを作成させるとします。一般的な手法だとToolにCode Interpreterを付与し、生成AIが内部でPythonを使いPower Pointファイルを作成すると思います。その場合、作成されたPower PointのファイルはCode Interpreter内のコンテナという仮想フォルダに格納されてしまい、特定の手法を用いないとダウンロードできなくなります。
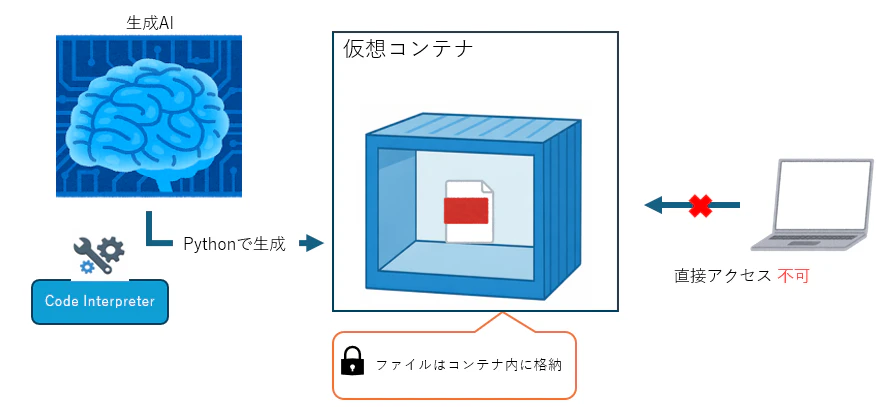
とても不便ではないでしょうか?少なくとも私は不便に感じました。
そこで、ChatKit widgetsを使って生成AIが作成したファイルをダウンロードする仕組みを作成してみたいと考えました。
生成AIが作成するファイルのダウンロード方法
現在生成AIが作成したファイルをダウンロードする方法は2つある認識です。
1.APIを用いてコールする方法
GET https://api.openai.com/v1/containers/{container_id}/files/{file_id}
2.OpenAI API Platformからダウンロードする方法
ただし OpenAI API Platform からダウンロードする方法は、ひとつのWebアプリ上で完結しません。今回やりたかったことはWebアプリのチャット画面内でダウンロードまで完了させることなので、APIをコールする方式を採用しました。
ファイル取得のイメージは以下です。
GET https://api.openai.com/v1/containers/{container_id}/files/{file_id}
ですが、AgentKit ではここでひとつ問題があります。APIコールに必要な container_id や file_id が、そのままでは分からないことです。
対策方針と実行結果
一般的には、モデルが Code Interpreter を使ったときのレスポンスに container_id が含まれるので取得しやすいのですが、今回使っている AgentKit ではレスポンスの詳細が見えにくく、その方法が取りづらい状態でした。
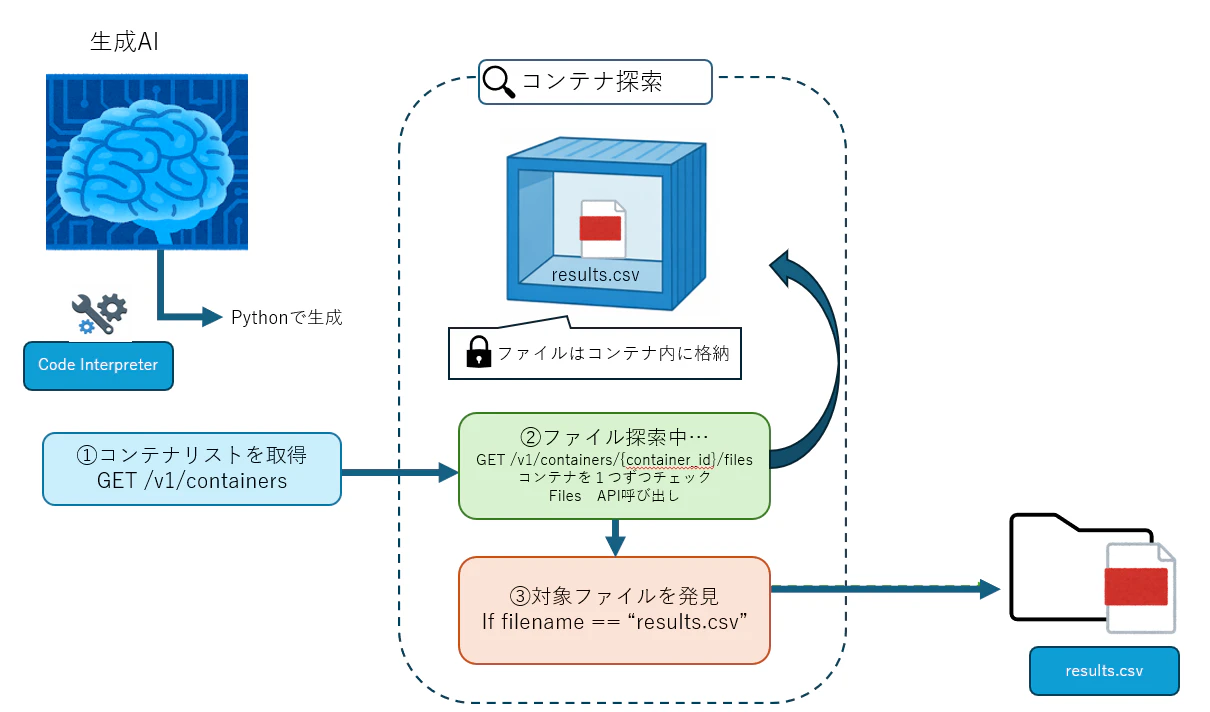
そこでリファレンスを確認してみると、以下の API を使えばコンテナ一覧とコンテナ内ファイル一覧を取得できることが分かりました。
GET https://api.openai.com/v1/containers
GET https://api.openai.com/v1/containers/{container_id}/files
これを見て、ファイル名さえ分かれば以下の流れでダウンロードできそうだと考えました。
- コンテナ一覧を取得する
- 各コンテナのファイル一覧を取得する
- ファイル名で目的のファイルを探す
- 一致した
container_idとfile_idで実ファイルを取得する
後は、生成AIが出力したファイル名を把握し、トリガーとして動くJavaScriptを用意するだけで良さそうです。
そこで活躍するのが ChatKit widgets になります。
ChatKit widgets は、OpenAI が提供するチャットUIに対して、カードやフォームなどの UI を埋め込める仕組みです。今回はWidgets Builder(自然言語からチャットUIを作ってくれるサービス)を使い、簡単なダウンロードボタンを作成しました。
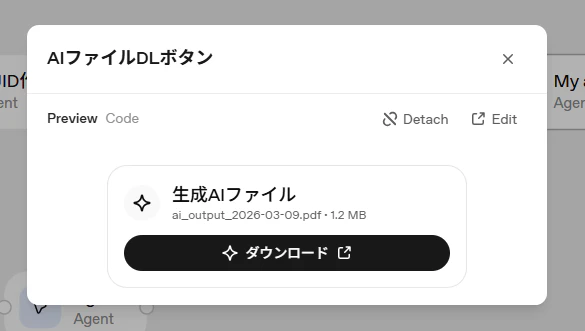
以下作成したWidgetsのコードになります。
{
"version": "1.0",
"name": "AIファイルDLボタン",
"template": "{\"type\":\"Card\",\"size\":\"sm\",\"children\":[{\"type\":\"Col\",\"gap\":3,\"children\":[{\"type\":\"Row\",\"gap\":3,\"align\":\"center\",\"children\":[{\"type\":\"Box\",\"background\":\"surface-elevated-secondary\",\"radius\":\"full\",\"padding\":2,\"children\":[{\"type\":\"Icon\",\"name\":\"sparkle\",\"size\":\"xl\"}]},{\"type\":\"Col\",\"gap\":0,\"children\":[{\"type\":\"Title\",\"value\":\"生成AIファイル\",\"size\":\"sm\"},{\"type\":\"Caption\",\"value\":{{ ((fileName ~ \" • \" ~ fileSize)) | tojson }}}]}]},{\"type\":\"Button\",\"label\":{{ (ctaLabel) | tojson }},\"style\":\"primary\",\"iconStart\":\"sparkle\",\"iconEnd\":\"external-link\",\"block\":true,\"onClickAction\":{\"type\":\"file.download\",\"handler\":\"client\",\"payload\":{\"url\":{{ (fileUrl) | tojson }},\"filename\":{{ (fileName) | tojson }}}}}]}]}",
"jsonSchema": {
"$schema": "https://json-schema.org/draft/2020-12/schema",
"type": "object",
"properties": {
"fileName": {
"type": "string"
},
"fileSize": {
"type": "string"
},
"fileUrl": {
"type": "string"
},
"ctaLabel": {
"type": "string"
}
},
"required": [
"fileName",
"fileSize",
"fileUrl",
"ctaLabel"
],
"additionalProperties": false
},
"outputJsonPreview": {
"type": "Card",
"size": "sm",
"children": [
{
"type": "Col",
"gap": 3,
"children": [
{
"type": "Row",
"gap": 3,
"align": "center",
"children": [
{
"type": "Box",
"background": "surface-elevated-secondary",
"radius": "full",
"padding": 2,
"children": [
{
"type": "Icon",
"name": "sparkle",
"size": "xl"
}
]
},
{
"type": "Col",
"gap": 0,
"children": [
{
"type": "Title",
"value": "生成AIファイル",
"size": "sm"
},
{
"type": "Caption",
"value": "sample-document.pdf • 123 KB"
}
]
}
]
},
{
"type": "Button",
"label": "ダウンロード",
"style": "primary",
"iconStart": "sparkle",
"iconEnd": "external-link",
"block": true,
"onClickAction": {
"type": "file.download",
"handler": "client",
"payload": {
"url": "/files/sample-document.pdf",
"filename": "sample-document.pdf"
}
}
}
]
}
]
},
"encodedWidget": "eyJpZCI6IjExMTExMTExLTExMTEtNDExMS04MTExLTExMTExMTExMTExMSIsIm5hbWUiOiJBSeODleOCoeOCpOODq0RM44Oc44K/44OzIiwidmlldyI6Ilx1MDAzY0NhcmQgc2l6ZT1cInNtXCJcdTAwM2VcbiAgXHUwMDNjQ29sIGdhcD17M31cdTAwM2VcbiAgICBcdTAwM2NSb3cgZ2FwPXszfSBhbGlnbj1cImNlbnRlclwiXHUwMDNlXG4gICAgICBcdTAwM2NCb3ggYmFja2dyb3VuZD1cInN1cmZhY2UtZWxldmF0ZWQtc2Vjb25kYXJ5XCIgcmFkaXVzPVwiZnVsbFwiIHBhZGRpbmc9ezJ9XHUwMDNlXG4gICAgICAgIFx1MDAzY0ljb24gbmFtZT1cInNwYXJrbGVcIiBzaXplPVwieGxcIiAvXHUwMDNlXG4gICAgICBcdTAwM2MvQm94XHUwMDNlXG4gICAgICBcdTAwM2NDb2wgZ2FwPXswfVx1MDAzZVxuICAgICAgICBcdTAwM2NUaXRsZSB2YWx1ZT1cIueUn+aIkEFJ44OV44Kh44Kk44OrXCIgc2l6ZT1cInNtXCIgL1x1MDAzZVxuICAgICAgICBcdTAwM2NDYXB0aW9uIHZhbHVlPXtgJHtmaWxlTmFtZX0g4oCiICR7ZmlsZVNpemV9YH0gL1x1MDAzZVxuICAgICAgXHUwMDNjL0NvbFx1MDAzZVxuICAgIFx1MDAzYy9Sb3dcdTAwM2VcbiAgICBcdTAwM2NCdXR0b25cbiAgICAgIGxhYmVsPXtjdGFMYWJlbH1cbiAgICAgIHN0eWxlPVwicHJpbWFyeVwiXG4gICAgICBpY29uU3RhcnQ9XCJzcGFya2xlXCJcbiAgICAgIGljb25FbmQ9XCJleHRlcm5hbC1saW5rXCJcbiAgICAgIGJsb2NrXG4gICAgICBvbkNsaWNrQWN0aW9uPXt7XG4gICAgICAgIHR5cGU6IFwiZmlsZS5kb3dubG9hZFwiLFxuICAgICAgICBoYW5kbGVyOiBcImNsaWVudFwiLFxuICAgICAgICBwYXlsb2FkOiB7IHVybDogZmlsZVVybCwgZmlsZW5hbWU6IGZpbGVOYW1lIH0sXG4gICAgICB9fVxuICAgIC9cdTAwM2VcbiAgXHUwMDNjL0NvbFx1MDAzZVxuXHUwMDNjL0NhcmRcdTAwM2UiLCJkZWZhdWx0U3RhdGUiOnsiZmlsZU5hbWUiOiJzYW1wbGUtZG9jdW1lbnQucGRmIiwiZmlsZVNpemUiOiIxMjMgS0IiLCJmaWxlVXJsIjoiL2ZpbGVzL3NhbXBsZS1kb2N1bWVudC5wZGYiLCJjdGFMYWJlbCI6IuODgOOCpuODs+ODreODvOODiSJ9LCJzdGF0ZXMiOltdLCJzY2hlbWEiOiJpbXBvcnQgeyB6IH0gZnJvbSBcInpvZFwiXG5cbmNvbnN0IFdpZGdldFN0YXRlID0gei5zdHJpY3RPYmplY3Qoe1xuICBmaWxlTmFtZTogei5zdHJpbmcoKSxcbiAgZmlsZVNpemU6IHouc3RyaW5nKCksXG4gIGZpbGVVcmw6IHouc3RyaW5nKCksXG4gIGN0YUxhYmVsOiB6LnN0cmluZygpLFxufSlcblxuZXhwb3J0IGRlZmF1bHQgV2lkZ2V0U3RhdGUiLCJqc29uU2NoZW1hIjp7fSwic2NoZW1hTW9kZSI6InpvZCIsInNjaGVtYVZhbGlkaXR5IjoidmFsaWQiLCJ2aWV3VmFsaWRpdHkiOiJ2YWxpZCIsImRlZmF1bHRTdGF0ZVZhbGlkaXR5IjoidmFsaWQifQ=="
}
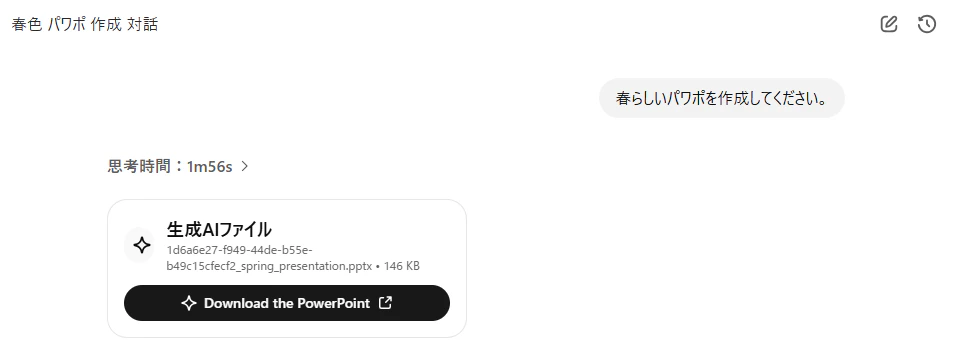
以下実際のチャット画面になります。
ボタン押下時は onAction でイベントを拾い、バックエンドのダウンロード処理につなぎます。最小構成だと、フロント側は次のようなイメージです。
chatkit.setOptions({
widgets: {
async onAction(action, widgetItem) {
if (action?.type !== "file.download") {
return chatkit.sendCustomAction(action, widgetItem?.id);
}
const payload = action?.payload ?? {};
if (typeof payload.url === "string" && payload.url.trim()) {
return downloadFromPayloadUrl(payload);
}
return downloadContainerFileViaApiMinimal({
payload: {
filename: payload.filename,
container_name: payload.container_name,
},
});
},
},
});
バックエンド側は次のようなイメージです。
@app.post("/api/download-container-file")
async def download_container_file(request: Request) -> Response:
body = await read_json_body(request)
filename = extract_required_string(body, "filename")
container_name = extract_optional_string(body, "container_name", "containerName")
async with httpx.AsyncClient(
base_url=chatkit_api_base(),
timeout=OPENAI_TIMEOUT_SECONDS,
verify=chatkit_tls_verify(),
) as client:
match, lookup_summary = await find_container_file(
client=client,
api_key=api_key,
filename=filename,
container_name=container_name,
created_after=None,
created_before=None,
max_containers=50,
max_files_per_container=100,
request_id="article",
)
if not match:
return respond({"error": "No matching file found", "lookup": lookup_summary}, 404)
content_response = await client.get(
f"/v1/containers/{match['container_id']}/files/{match['file_id']}/content",
headers=openai_headers(api_key),
)
return Response(content=content_response.content, status_code=200)
async def find_container_file(...):
while remaining_containers > 0:
response = await client.get(
"/v1/containers",
headers=openai_headers(api_key),
params=params,
)
payload = parse_json(response)
containers = payload.get("data") or []
for container in containers:
container_id = extract_mapping_string(container, "id")
if not container_id or is_container_expired_from_metadata(container):
continue
container_scan = await find_matching_file_in_container(
client=client,
api_key=api_key,
container_id=container_id,
match_criteria=match_criteria,
max_files=max_files_per_container,
request_id=request_id,
)
if container_scan.get("match"):
return {
"container_id": container_id,
"file_id": container_scan["match"]["file_id"],
"file_name": container_scan["match"]["file_name"],
}, {"matched": True}
return None, {"matched": False}
async def find_matching_file_in_container(...):
while remaining_files > 0:
response = await client.get(
f"/v1/containers/{container_id}/files",
headers=openai_headers(api_key),
params=params,
)
payload = parse_json(response)
files = payload.get("data") or []
for file_obj in files:
file_id = extract_mapping_string(file_obj, "id")
file_path = extract_mapping_string(file_obj, "path")
if not file_id or not file_path:
continue
file_name = PurePosixPath(file_path).name
score = score_filename_match(file_name, match_criteria)
if score >= 0:
return {
"match": {
"file_id": file_id,
"file_name": file_name,
}
}
return {"match": None}
実際にダウンロードボタンを押してみると、無事ファイルをダウンロードできました。
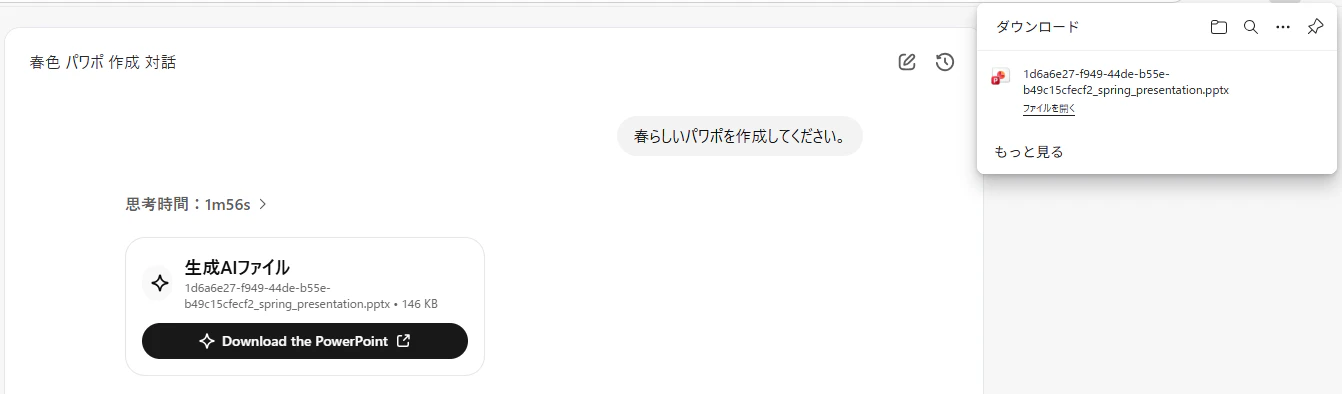
まとめ
ChatKit widgetsとJavaScriptを駆使し、無事生成AIが作成したファイルをダウンロードすることが出来ました。
今回は AgentKit を入口にしたため少し回りくどい実装となりましたが、やりたいこと自体は実現できたと思います。
P.S. GPT-5.4 が作成した PowerPoint ですが、少しイケてるデザインに仕上がっていました。
