第1章:メッセージキューの歴史
現代の分散システムやマイクロサービスにおいて、メッセージキュー(MQ)は欠かせないインフラ要素です。しかし、その起源は40年以上前に遡ります。なぜMQが必要とされ、どのように進化してきたのか、その歴史を紐解いていきましょう。
1.1 ソフトウェア・バスの発想と誕生 (1983年)
1983年、マサチューセッツ工科大学(MIT)で働いていた当時26歳の青年、ヴィヴェク・ラナディベ(Vivek Ranadive)は、当時のソフトウェア通信のあり方に革命的な疑問を抱きました。
当時のソフトウェア同士の通信は、すべて「ポイント・ツー・ポイント(点対点)」で行われており、双方が同じプロトコルを個別に実装する必要がありました。
ヴィヴェクの閃き:
「マザーボードのバス(BUS)のように、異なるソフトウェアを自由に統合できる通信専用のミドルウェアは作れないだろうか?」
彼はテクネクロン(Teknekron)社を設立し、世界初のメッセージキューソフトウェア 「The Information Bus (TIB)」 を開発しました。これが、現代のメッセージングシステムの先駆けです。
1.2 Pub/Subモデルの確立と業界への波及
TIBはまず、ゴールドマン・サックスなどの大手金融機関において、金融取引システムに採用されました。TIBが実現した「パブリッシュ/サブスクライブ(Publish/Subscribe)」モデルには、それまでの通信概念を覆す特徴がありました。
- 完全なる疎結合(Decoupling): 情報の「生産者(Producer)」と「消費者(Consumer)」が互いの存在を知らなくても通信が可能。
- 業界の注目: この「データのリアルタイムな再配布」という特性は、速報性が命であるニュース機関の目に留まり、1994年にはロイター通信がテクネクロン社を買収するに至りました。
1.3 ベンダーの乱立と「独自仕様」の壁
TIBの成功を受け、IBMは IBM MQ (WebSphere MQ) を、Microsoftは MSMQ を開発し、メッセージキュー市場は急速に拡大しました。しかし、ここで新たな問題が発生します。
当時の製品はすべてベンダーごとの「独自仕様」でした。
- 相互運用の欠如: IBM MQを利用しているアプリケーションがMSMQとも通信しようとした場合、プロトコルやAPIが異なるため、それぞれに対して個別に実装を繰り返さなければなりませんでした。技術的な壁が、システムの柔軟性を阻害していたのです。
1.4 Java標準「JMS」の功罪 (2001年)
データベースの世界におけるJDBCのように、MQの世界でも標準化の動きが始まりました。2001年、SUNマイクロシステムズは JMS (Java Message Service) 規範を発表します。
- JMSの狙い: Javaの世界において共通のAPIを定義し、背後にあるMQ製品の種類に関わらず同じコードで操作できるようにすること。
- 残された課題: JMSはあくまでJava言語に依存したAPI標準でした。言語の垣根を越えたクロスプラットフォームな通信プロトコルの解決には至りませんでした。
1.5 真の標準「AMQP」とRabbitMQの躍進 (2006年〜)
2006年、ついに言語やプラットフォームを問わない真の標準プロトコル AMQP (Advanced Message Queuing Protocol) が発表されました。これがメッセージキューのエコシステムを爆発的に普及させる起爆剤となります。
RabbitMQの登場
2007年、Rabbit技術会社がErlang言語を用いて、AMQP規範に完全に準拠した RabbitMQ 1.0 をリリースしました。
当初は金融業界での利用がメインでしたが、その汎用性と信頼性から、現在では世界中のあらゆる企業のインフラにおいてデファクトスタンダードの一つとして採用されています。
ご提示いただいた資料の 3.1.2 MQ 定义 セクションに基づき、内容を省略することなく、正確かつ論理的に整理した「第2章」の内容を作成しました。
第2章:メッセージキュー(MQ)の定義
2.1 分散システムにおけるデータ転送の課題
分散型シナリオにおいて、大量のユーザーリクエストを処理する場合、システム内部の機能ホスト間や機能モジュール間などでやり取りされるデータ量は、想像を絶するものになります。なぜなら、一人のユーザーのリクエストであっても、その裏側では内部的な様々な業務ロジックの遷移(ジャンプ)や操作が複雑に絡み合うからです。
このような大量のユーザーを抱えるビジネスシーンにおいて、全ての内部業務ロジックのリクエストが、いかにして「安定」かつ「迅速」なデータ伝送を維持できるか。この要求を満たすための技術こそが、メッセージキュー(Message Queue、以下MQ)です。
2.2 メッセージキューの基礎概念
メッセージキュー(MQ)は、分散型インターネットアプリケーションを構築するための基礎インフラストラクチャです。MQを通じて実現される「疎結合(松耦合)」なアーキテクチャ設計は、システムの可用性および拡張性を向上させることができ、現代のアプリケーションにおける最適な設計ソリューションと言えます。
2.3 通信メカニズムと特徴
メッセージキューは、サーバーレスおよびマイクロサービスアーキテクチャに適した、非同期のサービス間通信方式です。その主な動作メカニズムと特徴は以下の通りです。
- データの永続性: メッセージは、実際に処理され削除されるまでの間、常にキュー上に保存され続けます。
- 1回限りの処理: 各メッセージは、ただ一人のユーザー(コンシューマー)によって一度だけ処理されることが保証されます。
- 主な役割:
- 重量級の処理(負荷の高い処理)の切り離し(分離)
- バッファリング(緩衝)やバッチ処理の実現
- ピーク時におけるワークロード(作業負荷)の緩和
2.4 メッセージキューの利用シーン (MQ 使用场合)
メッセージキューは高アクセスシステムの核心コンポーネントの一つであり、業務システムの構造を最適化することで、開発効率とシステムの安定性を向上させます。主な応用シナリオは以下の通りです。
1. ピークカットと平滑化(削峰填谷)
ECサイトの秒殺(フラッシュセール)、お年玉配布、大規模なキャンペーンなどは、短時間に極めて高いトラフィック・パルス(流量パルス)をもたらします。
- 課題: 適切な保護がない場合、システムが過負荷で崩壊したり、制限が厳しすぎて大量のリクエストが失敗し、ユーザー体験を損なうことがあります。
- 解決: MQがバッファとして機能し、トラフィックの山を削り、谷を埋めることで、下流システムを過負荷から守りつつ着実に処理を継続させます。
2. 非同期通信と疎結合化(异步解耦)
淘宝(タオバオ)のような巨大なECシステムにおいて、取引システムは核心です。1つの注文データが発生すると、物流、カート、ポイント、ストリーム計算分析など、数百もの下流システムがその情報を必要とします。
- 課題: 全てを直接連携させると、全体が巨大で複雑になりすぎ、1箇所の不具合がメインサイトの停止を招くリスクがあります。
- 解決: MQによる非同期通信を実現することで、メインサイトはメッセージを送るだけで業務を継続でき、各下流システムはそれぞれのタイミングで情報を処理する「疎結合」な状態を作れます。
3. 順序保証の送受信(顺序收发)
実務において、順序保証が必要なシナリオは非常に多く存在します。
- 具体例: 証券取引の「時間優先原則」、取引システムにおける「注文作成 → 支払 → 退職(返金)」のフロー、フライトにおける旅客の搭乗メッセージ処理など。
- 解決: FIFO(First In First Out / 先入れ先出し)の原理に基づき、MQはメッセージを送信された順序通りに受信側へ提供することを保証します。
4. 分散トランザクションの一貫性(分布式事务一致性)
取引システムや支払システムでは、データの最終的な一貫性を確保する必要があります。
- 解決: 分散トランザクションにMQを大量に導入することで、システム間の結合を解きつつ、データの最終的な一致を保証します。
5. ビッグデータ分析(大数据分析)
データは「流動」の中で価値を生みます。
- 課題: 伝統的な分析はバッチ計算モデルに基づいており、リアルタイムな分析が困難でした。
- 解決: MQとストリーム計算エンジンを組み合わせることで、業務データのリアルタイム分析を容易に実現できます。
6. 分散キャッシュの同期(分布式缓存同步)
ECの大型セールなどでは、各会場の商品価格の変化をリアルタイムで感知する必要があります。
- 課題: 大量の同時アクセスがデータベースに集中するとレスポンスが低下し、集中型キャッシュでは帯域がボトルネックになります。
- 解決: MQを通じて商品データの変化をリアルタイムに通知し、分散キャッシュを同期させることで、高速なレスポンスを維持します。
7. メッセージ蓄積による負荷テスト(蓄流压测)
本番環境の特定の経路では、直接的な負荷テスト(ストレステスト)が困難な場合があります。
- 解決: MQ内に一定量のメッセージを意図的に蓄積させ、その後一気に解放することで、下流システムに対して精度の高い負荷テストを実施できます。
2.5 主要なメッセージキュー製品 (主流 MQ)
現在、IT業界で広く利用されている主要なMQソフトウェアおよび、特定の用途で使われる製品は以下の通りです。
1. 主流のMQ製品
- Kafka: 分散ストリーミングプラットフォームのデファクトスタンダード。高スループットに特化。
- RabbitMQ: AMQP準拠。高い信頼性と柔軟なルーティング。
- RocketMQ: Alibaba製。金融・取引レベルの信頼性とスケーラビリティ。
- ActiveMQ: 歴史が長く、JMSに準拠。
2. 特定用途・マイナーな製品
- ZeroMQ: 極めて高速な非同期メッセージングライブラリ。
- Apache Qpid: AMQPをサポートするApacheプロジェクトの製品。
第3章:Apache Kafka — 次世代の分散ストリーミングプラットフォーム
前章ではメッセージキュー(MQ)全般の定義と利用シーンについて触れましたが、本章ではいよいよ、本連載の主役である Apache Kafka について詳しく紹介します。
3.1 主要なメッセージキュー(MQ)の比較 (Common MQ Comparison)
Kafkaの詳細に入る前に、現在主流となっている他のメッセージキュー製品とKafkaの違いを整理しておきましょう。各製品にはそれぞれの得意分野があり、要件に応じて選択する必要があります。
資料に基づき、主要な4つのMQを比較します。
| 項目 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| 開発言語 | Java | Erlang | Java | Scala / Java |
| プロトコル | JMS, OpenWire, STOMP | AMQP | 独自プロトコル | 独自バイナリ (TCP) |
| スループット | 普通(万単位/秒) | 普通(万単位/秒) | 高(十万単位/秒) | 極めて高(百万単位/秒以上) |
| 遅延 (Latency) | ミリ秒 | マイクロ秒 | ミリ秒 | ミリ秒 |
| 可用性 | 主従(Master-Slave) | 主従(Master-Slave) | 分散型(Distributed) | 分散型(Distributed) |
| メッセージ信頼性 | 高(損失が少ない) | 高 | 高 | 非常に高(レプリケーション) |
| 適合シーン | 伝統的なJMS連携 | リアルタイム・高信頼 | 金融・取引レベル | ビッグデータ・ログ集約・リアルタイム分析 |
3.2 Apache Kafka とは? (Introduction to Kafka)
Apache Kafka は、「次世代の分散メッセージングシステム」と呼ばれ、Scala と Java で記述されています。
非営利団体である Apache Software Foundation (ASF) のオープンソースプロジェクトの一つです。ASFには、HTTP Server、Tomcat、Hadoop、ActiveMQといった著名なソフトウェアが属していますが、Kafkaもその強力なエコシステムの一部です。
3.2.1 Kafka の主要な目的
Kafka は主に以下の2つの目的のために設計されています。
- リアルタイムデータパイプラインの構築: システム間でのデータの移動を低遅延かつ確実に実行します。
- ストリームアプリケーションの構築: 流れてくるデータに対してリアルタイムに処理を行います。
3.2.2 Kafka の核心的な強み
Kafka は世界中の数千もの組織で採用されており、本番環境での実績が豊富です。その強みは主に以下の3点に集約されます。
- 水平スケーラビリティ (Horizontal Scalability): サーバー(Broker)を追加することで、処理能力を容易に拡張できます。
- 耐障害性 (Fault Tolerance): データは複数のサーバーに複製(レプリケーション)されるため、一部のサーバーが故障してもデータが失われません。
- 高速性 (High Speed): ディスクへのシーケンシャル書き込みを活用することで、毎秒数百万件という驚異的なスループットを実現します。
公式リソース
詳細なドキュメントや最新情報は、公式サイトを参照してください。
- 公式サイト: http://kafka.apache.org/
3.3 Kafkaの主要な特長と圧倒的な優位性 (Features and Advantages)
Kafkaがビッグデータ処理やリアルタイムストリーミングにおいてデファクトスタンダードとなった理由は、その独自の設計思想にあります。ここでは、Kafkaを構成する「特長」と、それによってもたらされる「実務上の優位性」を解説します。
3.3.1 Kafkaの主要な特長 (Core Features)
Kafkaは単一のサーバーで動かすことを想定せず、最初から大規模なクラスタリングを前提に設計されています。
-
分散型アーキテクチャ (Distributed):
複数台のサーバー(Broker)によるクラスタ構成を前提としています。単一障害点(SPOF)を排除し、高い拡張性を備えています。 -
パーティショニング (Partitioning):
1つのメッセージ(Topic)を複数の「パーティション」に分割し、異なる場所に分散して保存できます。これにより、データの並列処理が可能になります。 -
マルチレプリケーション (Multi-replica):
データの紛失を防ぐため、複数のコピー(レプリカ)を作成し、異なるBrokerに保持します。 -
マルチサブスクライバー (Multi-subscriber):
多くのアプリケーションが同時にKafkaに接続し、同じデータをそれぞれの目的(ログ保存、分析、リアルタイム処理など)で個別に購読できます。 -
ZooKeeperへの依存関係の変化:
初期バージョンのKafkaはZooKeeperに依存していましたが、2021年4月19日リリースのKafka 2.8.0より、ZooKeeperを必要としない「自己管理型メタデータクォーラム(KRaft)」が導入されました。これにより、Kafka単体での管理が可能となり、運用が大幅に簡素化されました。
3.3.2 実務における優位性 (Key Advantages)
Kafkaは、従来のメッセージキューでは対応困難だった「データ量」と「速度」の課題を解決します。
-
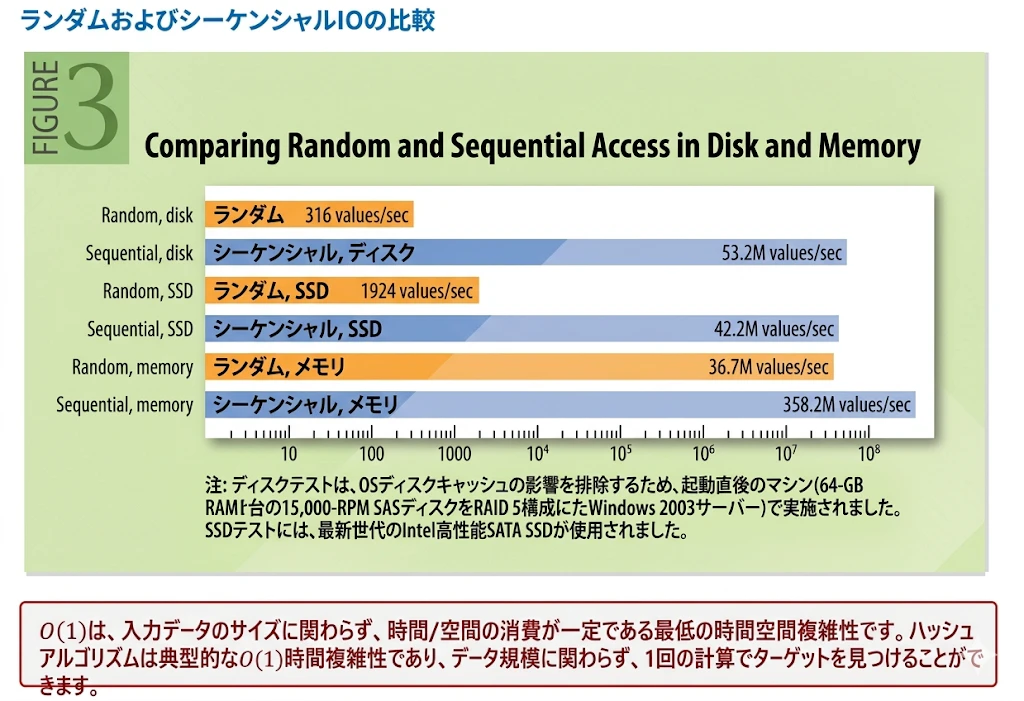
O(1) のデータ構造による永続化:
Kafkaは O(1)(定数時間) で動作するディスクデータ構造を採用しています。これにより、蓄積されるデータがテラバイト(TB)級に達しても、読み書きのパフォーマンスが低下せず、長期間にわたって安定した性能を維持できます。 -
圧倒的な高スループット:
一般的なハードウェア構成であっても、秒間数百万件のメッセージ処理をサポートします。これは、メッセージをパーティションに分割してサーバー間で分散処理する仕組みによって実現されています。 -
分散型による高可用性と耐障害性:
分散クラスタに基づいたフォールトトレラント(容認性)メカニズムにより、自動フェイルオーバー(故障転送)を実現します。一部のノードがダウンしても、システム全体は止まりません。 -
順序性の保証:
多くの業務シナリオ(金融取引やステータス変更など)では、データの処理順序が極めて重要です。Kafkaは「同一パーティション内」でのメッセージの順序性を保証します。
Note: パーティション間を跨ぐデータの順序は保証されません。厳格な順序性が必要な場合は、トピック作成時にパーティション数を「1」に設定する必要があります。
-
Hadoop 等との強力な並列連携:
Hadoopへの並列データロードをサポートしており、データレイクの構築に最適です。 -
大規模データへの適性(vs RabbitMQ):
通常、Kafkaは大規模なデータやログの転送に使用され、単一メッセージのサイズが比較的大きい場合にも対応します。対して、RabbitMQは主に業務上の「制御命令データ」の転送に使われることが多く、単一メッセージのサイズは小さい傾向にあります。
3.4 Kafka のアーキテクチャと構成要素
Kafka の高いスループットと可用性を支えるのは、その洗練された「ロール(役割)」と「論理構造」の設計です。本章では、Kafka エコシステムを構成する主要なキャラクターと、データがどのように管理されているかを詳しく解説します。

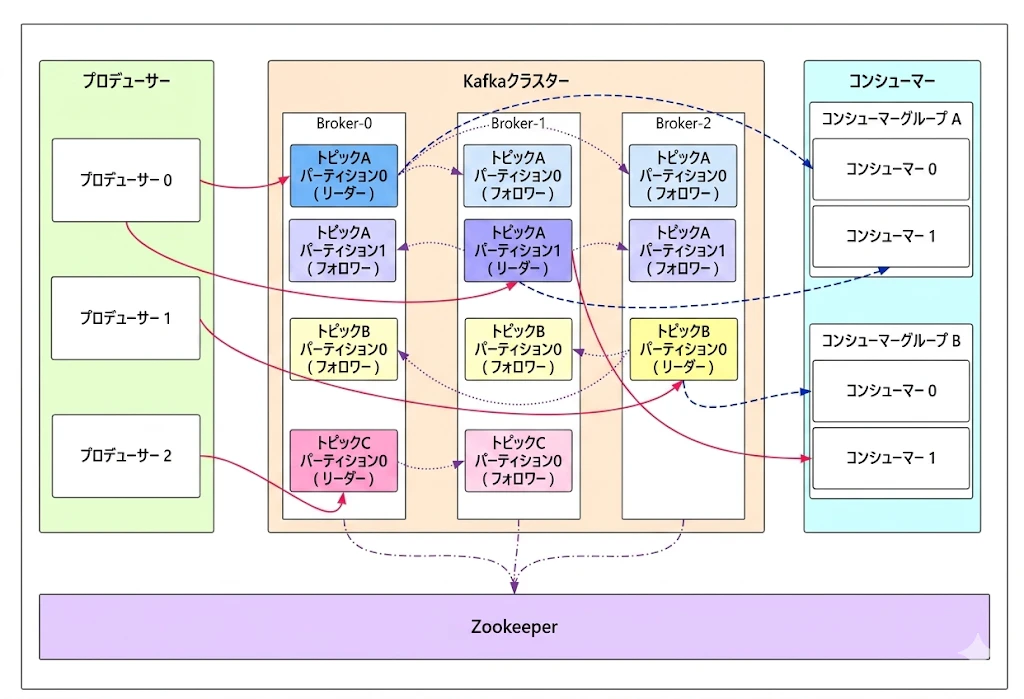
1. Kafka における主要なロール (Core Roles)
Kafka クラスターと対話するエンティティは、大きく以下の 4 つに分類されます。
1.1 Producer(プロデューサー / 生産者)
メッセージの発生源であり、Kafka へのデータの入り口です。特定の Topic に対してメッセージをパブリッシュ(送信)する役割を担います。
1.2 Consumer(コンシューマー / 消費者)
メッセージを購読(サブスクライブ)し、実際にデータを処理する側です。
1.3 Consumer Group(コンシューマーグループ)
複数のコンシューマーを論理的にまとめた単位です。
- 排他制御: 同一トピックを購読する場合、グループ内のコンシューマー間でメッセージが分散されます。つまり、トピック内の特定のメッセージは、同一グループ内では一人のコンシューマーのみが処理します(High Level API 使用時)。
- 並列処理: 複数の異なるコンシューマーグループが、同時に同じトピックのメッセージを個別に消費することは可能です。
1.4 Broker(ブローカー)
Kafka のインスタンス本体です。通常、1 台のサーバーに 1 つ以上のブローカーが稼働します。
- クラスター内では
broker-0,broker-1のように重複しない ID で管理されます。
2. データの論理・物理構造
Kafka がどのようにデータを分類し、保存しているかを定義する重要な概念です。
2.1 Topic(トピック)
メッセージのカテゴリ分け(分類)です。Redis の Key や Elasticsearch の Index に相当します。
- 論理的側面: ユーザーはデータの保存先を意識せず、トピック名を指定するだけで読み書きが可能です。
- 物理的側面: トピックごとのメッセージは、物理的には異なるフォルダに分けて保存されます。
2.2 Partition(パーティション)
1 つのトピックを物理的に分割した単位です。
- 負荷分散: トピックを「切り分ける」ことで、複数のブローカーに負荷を分散し、スループットを向上させます。
- 順序性: 同一パーティション内のデータは順序が保証されますが、異なるパーティション間では順序は保証されません。
- 構成: 物理的にはフォルダとして表現され、その中にデータファイルとインデックスファイルが格納されます。通常、パーティション数はノード数を超えないように設計するのが一般的です。
3. 高可用性を支えるレプリケーション構造
Kafka はデータの安全性を確保するため、パーティションのコピー(レプリカ)を複数のブローカーに分散させます。
3.1 Replication(レプリケーション)
データの複製です。可用性を担保するため、少なくとも「2」以上に設定することが推奨されます(Leader と Follower の合計数)。
3.2 副本(レプリカ)の状態管理
パーティションには Leader(読み書きを担当)と Follower(Leader から同期)が存在します。これらの状態は以下の指標で管理されます。
-
AR (Assigned Replicas): そのパーティションに割り当てられた全レプリカの総称。(
AR = ISR + OSR) - ISR (In-Sync Replicas): Leader と同期が取れているレプリカの集合(Leader 自身を含む)。可用性の生命線です。
- OSR (Out-of-Sync Replicas): 遅延などにより、Leader との同期が遅れているレプリカの集合。
4. パーティショニングの優位性 (Advantages of Partitioning)
なぜパーティションを分ける必要があるのでしょうか?そこには 3 つの大きなメリットがあります。
- 水平スケーラビリティ: 複数のサーバーのストレージ容量を統合して利用できます。
- パフォーマンス向上: 複数のサーバーに対して同時に読み書き(並列 I/O)が可能です。
- 高可用性の実現: Leader を異なるサーバーに分散させることで、特定のサーバーがダウンしても影響を最小限に抑えます。
構成例(レプリケーションファクター 3 の場合)
- Partition 0: Leader はサーバー A、Follower はサーバー B, C
- Partition 1: Leader はサーバー B、Follower はサーバー A, C
- Partition 2: Leader はサーバー C、Follower はサーバー A, B
このように Leader を分散配置することで、クラスター全体の負荷を最適化します。
5. Kafka メッセージ書き込みのプロセス (Message Write Workflow)
Kafka がどのようにして高いスループットを維持しながら、正確にデータを Broker へ書き込むのか、その内部プロセスを解説します。
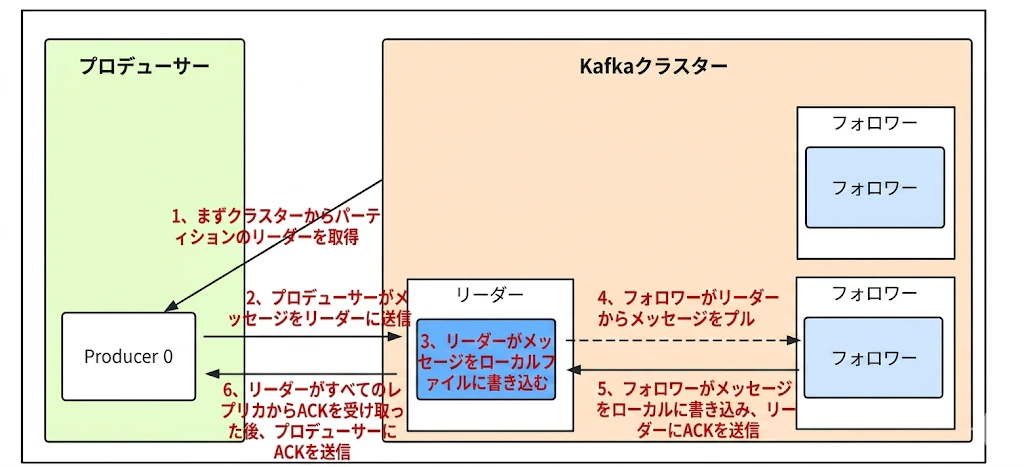
書き込みの 6 ステップ
Producer がメッセージを送信してから、書き込みが完了するまでの流れは以下の通りです。
-
接続先の特定:
Producer がいずれかの Broker に接続し、該当する Topic の Partition Leader がどの Broker に存在するか、メタ情報をリクエストします。 -
Leader への送信:
Producer は、特定した Partition Leader(Broker)に対してメッセージを送信します。 -
Local Log への書き込み:
Leader はメッセージを受け取ると、自身のローカルログ(ディスク上のファイル)にデータを書き込みます。 -
Follower による同期:
Follower たちは定期的に Leader をポーリングしており、新しいメッセージを検知すると、自身のローカルログにコピー(同期)します。 -
ACK の返信 (Follower → Leader):
Follower は自身のログへの書き込みが完了すると、Leader に対して「書き込み完了(ACK)」を返します。 -
完了通知 (Leader → Producer):
Leader は、ISR (In-Sync Replicas) 内の全レプリカから ACK を受け取った後(設定による)、Producer に対して正式に書き込み成功を通知します。
💡 インフラエンジニアの深掘り:ACK 設定の重要性
Kafka の書き込みにおいて、信頼性とパフォーマンスのバランスを決定するのが acks 設定です。
- acks=0: Leader の受信確認を待たずに送信完了とする。最速だがデータ紛失のリスクが高い。
- acks=1: Leader が自身のログに書き込んだ時点で成功とする。Leader 故障時に未同期データが消えるリスクがある。
- acks=-1 (all): ISR 内の全レプリカが書き込みを完了するまで待機する。最も安全だが、レイテンシは増加する。
6. Kafka メッセージ保存の仕組み (Storage Mechanism)
Kafka は、メモリ上だけでなく物理ディスクにデータを保存することで永続性を確保しています。
-
トピックとパーティション: 物理的には、Broker 上に
トピック名-パーティション番号という形式のフォルダが作成されます。 -
セグメントファイル: パーティションフォルダの中には、
.log(データ本体)と.index(索引)ファイルが生成されます。 - シーケンシャル書き込み: Kafka はディスクに対して「追記型(Sequential Write)」でデータを書き込みます。これはランダムアクセスに比べて圧倒的に高速であり、Kafka の高スループットを支える最大の要因です。