第1章:ZooKeeper クラスターの構造と役割
ZooKeeperを本番環境で運用する際は、単一のサーバーではなく、複数台のサーバーを組み合わせた「クラスター(Ensemble)」を構築するのが一般的です。 これにより、一部のサーバーが故障してもシステム全体が停止しない高可用性を実現します。
1.1 システムの構成要素(System Components)
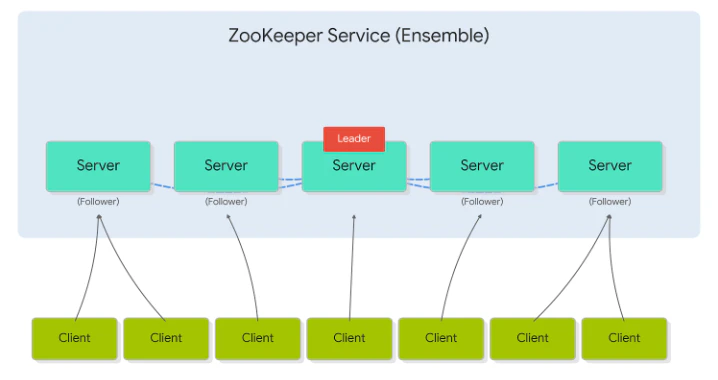
サービス全体を俯瞰した際の登場人物は、大きく以下の3つに分類されます。
| 要素 | 説明 |
|---|---|
| Client (クライアント) | ZooKeeperを利用するアプリケーション。データの読み書きやノードの監視(Watcher)を依頼します。 |
| Server (サーバー) | ZooKeeperのプロセスが動作する個々のノード。データを保持し、リクエストに応答します。 |
| Ensemble (アンサンブル) | 複数のサーバーが連携して形成する「クラスター全体」の呼称です。 |
1.2 クラスター内部の役割(Internal Roles)
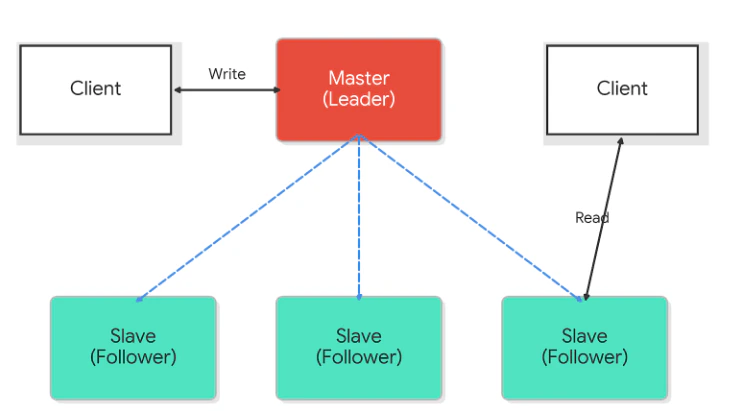
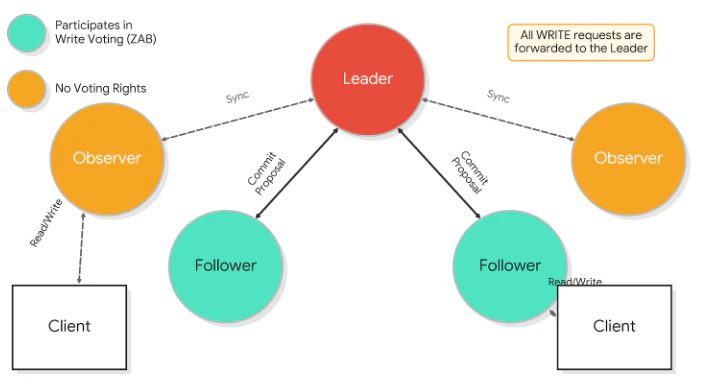
アンサンブル内では、データの整合性を守るために各サーバーへ明確な役割(Role)が割り振られます。
- Leader (リーダー): クラスターに1台のみ存在。全ての書き込み操作を統括し、トランザクションの順序を決定する司令塔です。
- Follower (フォロワー): リーダーと共に合意形成(投票)に参加し、データの複製を保持する「正社員」のような存在です。
- Observer (オブザーバー): 読み取り専用ノード。投票権を持たず、書き込みのオーバーヘッドを抑えながらクラスターの参照性能を向上させます。
- Learner (ラーナー): Follower と Observer の総称です。リーダーから最新のデータ状態を「学ぶ」立場にあるノードを指します。
1.3 可用性を支える「過半数合意」の原則
ZooKeeper クラスターが正常に動作し続けるためには、Quorum(クォーラム) と呼ばれる過半数のノードが生存している必要があります。
クラスター全体のノード数を $n$ とすると、必要な生存ノード数は以下の式で表されます。
$$\text{Quorum} \ge \lfloor n/2 \rfloor + 1$$
なぜ奇数(3, 5, 7台)構成なのか?
たとえば3台構成の場合、1台が故障しても残り2台(過半数)で稼働可能です。しかし4台構成にしたとしても、2台故障すると残り2台(過半数を超えない)となり稼働できません。つまり、4台構成は3台構成と耐障害性が変わらないため、コスト効率の面から奇数台での構築が推奨されます。
1.4 ZooKeeperのリーダー選挙プロセス(Leader Election)
ZooKeeperクラスター(アンサンブル)が起動した際、または稼働中のリーダーがダウンした際、クラスターは自動的にリーダー選挙を開始します。このプロセスにより、常に一貫性を持った1台のリーダーが選出されます。
1.4.1 選挙が発生するタイミング
- クラスター起動時: サーバーが順次起動し、過半数(クォーラム)に達するまでリーダーを決定します。
- リーダーの障害時: 現在のリーダーが停止したり、ネットワークから孤立したりした場合、残りのサーバーで即座に新しいリーダーを選び直します。
1.4.2 選挙の基本ルール:比較の優先順位
各サーバーは自分の情報(投票券)を他サーバーへ送ります。投票を受け取ったサーバーは、以下の優先順位でどちらがリーダーにふさわしいかを判断します。
-
ZXID (Transaction ID) が大きい方:
最も新しいデータを持っているサーバーを最優先します。これによりデータの消失を防ぎます。 -
SID (Server ID / myid) が大きい方:
データの鮮度(ZXID)が同じ場合は、設定ファイルmyidで指定されたIDが大きいサーバーを優先します。
1.4.3 選挙の4つの状態(States)
選挙中、各サーバーは以下のいずれかの状態にあります。
- LOOKING: リーダーを探している状態(選挙中)。
- LEADING: 自身がリーダーとして動作している状態。
- FOLLOWING: リーダーに従い、同期を行っている状態。
- OBSERVING: 選挙権を持たず、結果のみを受け取る状態。
1.4.4 選挙の流れ(例:3台構成の場合)
- 自薦: サーバー1と2が起動すると、まず自分自身をリーダーとして投票します。
- 交換: 互いに投票内容を交換し、比較します。
- 決定: サーバー2の方がIDが大きいため、サーバー1は自分の投票をサーバー2に変更します。
- 確定: サーバー2は「自分への投票が過半数(2票/3台)」に達したことを確認し、LEADERを宣言します。サーバー1はFOLLOWERになります。
複数台のサーバーで「誰が接続しても同じデータが見える」状態を作るため、ZAB (ZooKeeper Atomic Broadcast) プロトコルが採用されています。 リーダーが書き込みを決定し、フォロワーへ伝播させるこの仕組みにより、分散環境下での強力なデータ一貫性が守られています。
第2章:ZooKeeper クラスターデプロイ
公式ガイド:
https://zookeeper.apache.org/doc/r3.6.2/zookeeperAdmin.html#sc_zkMulitServerSetu
本章では、高可用性を担保するための標準的な構成である「3台構成」のクラスターを構築します。
2.1 環境準備(Environment Preparation)
クラスター構築をスムーズに進めるため、まずは各サーバーのネットワーク設定と、共通の事前準備を行います。
1. サーバー構成
今回は以下の3台のノードを使用します。あらかじめ /etc/hosts に書き込み、互いに名前解決ができる状態にしておきます。
| ホスト名 | IP アドレス | 役割 (Role) |
|---|---|---|
| zookeeper1 | 10.0.0.101 | Leader / Follower |
| zookeeper2 | 10.0.0.102 | Leader / Follower |
| zookeeper3 | 10.0.0.103 | Leader / Follower |
2. Java 環境のインストール(全ノード共通)
ZooKeeper の実行には JDK が必須です。全てのノードで Java 8 をインストールします。
# Ubuntu/Debian 系の例
sudo apt update
sudo apt -y install openjdk-8-jdk
2.2 ZooKeeper パッケージのダウンロードと展開
次に、全てのノードで ZooKeeper 本体のバイナリパッケージを取得し、配置します。
1. パッケージのダウンロード
/usr/local/src にパッケージをダウンロードします。
# 3台全てのノードで実行
sudo wget -P /usr/local/src https://archive.apache.org/dist/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
2. 解凍とインストールディレクトリの作成
ダウンロードしたファイルを /usr/local に展開し、管理を容易にするためにシンボリックリンクを作成します。
# 全ノードで実行
# 解凍
sudo tar xf /usr/local/src/apache-zookeeper-3.6.3-bin.tar.gz -C /usr/local/
# シンボリックリンクの作成
sudo ln -s /usr/local/apache-zookeeper-3.6.3-bin /usr/local/zookeeper
3. 環境変数の設定
bin ディレクトリを PATH に追加し、どのディレクトリからでも ZooKeeper コマンド(zkServer.sh 等)を実行できるようにします。
echo 'PATH=/usr/local/zookeeper/bin:$PATH' | sudo tee /etc/profile.d/zookeeper.sh
source /etc/profile.d/zookeeper.sh
ここまでは、各ノードでの「横並び」の作業でした。次はクラスター構成の肝となる、個別の識別子設定に進みます。
2.3 設定ファイル(zoo.cfg)の準備
ZooKeeper の動作を制御する心臓部が zoo.cfg です。デフォルトではサンプルファイルしか存在しないため、これをコピーして編集を開始します。
2.3.1 設定ファイルの作成
全てのノードで以下の操作を行い、設定ファイルを作成します。
# 全ノードで実行
cd /usr/local/zookeeper/conf
sudo cp zoo_sample.cfg zoo.cfg
2.3.2 共通パラメータの設定
zoo.cfg を開き、以下の基本パラメータを確認・修正します。
# 基本的な時間単位(ミリ秒)
tickTime=2000
# リーダーへの初期接続タイムアウト(tickTimeの倍数)
initLimit=10
# リーダーとの同期タイムアウト(tickTimeの倍数)
syncLimit=5
# データの保存ディレクトリ(※事前に作成が必要)
dataDir=/usr/local/zookeeper/data
# クライアント接続用ポート
clientPort=2181
2.3.3 クラスターノードの定義
ファイルの末尾に、クラスターに参加する全てのサーバーのリストを追記します。ここが単機構成との最大の違いです。
####################### Cluster Setup #######################
server.1=10.0.0.101:2888:3888
server.2=10.0.0.102:2888:3888
server.3=10.0.0.103:2888:3888
💡 アーキテクトの視点:server.A=B:C:D の意味
この 1 行には、ZooKeeper の分散アルゴリズムを支える重要な情報が詰まっています。
-
A (Server ID): 各サーバーを識別する一意の数字(1, 2, 3...)。次の工程で作成する
myidファイルの内容と一致させる必要があります。 - B (Address): サーバーの IP アドレスまたはホスト名。
- C (Quorum Port): 2888。フォロワーがリーダーに接続し、データを同期するためのポートです。
- D (Election Port): 3888。リーダー選挙(Election)の投票プロセスで使用されるポートです。
Note: クラウド環境(AWS等)で構築する場合は、IP アドレスを直接書くよりも、プライベート DNS やホスト名を使用することを推奨します。インスタンスの再作成などで IP が変わった際、設定ファイルの修正を最小限に抑えられるからです。
2.4 各ノードの識別子(myid)の設定
zoo.cfg に記述した server.1, server.2, server.3 という番号と、実際のサーバーを紐付ける作業です。これを忘れると、ZooKeeper は自分がどの設定に従えばよいか判断できず、起動に失敗します。
2.4.1 myid ファイルの作成
各サーバーの dataDir(前節で設定した /usr/local/zookeeper/data)に、自身の ID 番号だけを記したテキストファイルを作成します。
【zookeeper1 (10.0.0.101) で実行】
echo "1" | sudo tee /usr/local/zookeeper/data/myid
【zookeeper2 (10.0.0.102) で実行】
echo "2" | sudo tee /usr/local/zookeeper/data/myid
【zookeeper3 (10.0.0.103) で実行】
echo "3" | sudo tee /usr/local/zookeeper/data/myid
2.5 ZooKeeper サービスの起動
設定が全て完了したので、各ノードでサービスを起動します。
2.5.1 サービスの開始
全てのノードで以下のコマンドを実行してください。
zkServer.sh start
#注意:初回目のノード起動はできるだけ早めに一緒に起動しておいてください
💡 アーキテクトの注意点
1台目のノードを起動した直後にログを確認すると、エラー(Connection refused など)が出ていることがあります。これは ZooKeeper の仕様 です。クラスター構成の場合、過半数(Quorum)のノードが立ち上がるまで、他ノードを探し続けるためです。2台目を起動すれば、選挙が成立し、エラーは収まります。落ち着いて全台起動させましょう。
2.6 クラスター状態の確認
最後に、クラスターが正しく形成され、誰がリーダー(Leader)で誰がフォロワー(Follower)になっているかを確認します。
2.6.1 ステータスの確認
各ノードで以下のコマンドを実行します。
zkServer.sh status
2.6.2 実行結果の例
正常に構築できている場合、以下のようなレスポンスが返ってきます。
**zookeeper1 の場合:**
#follower会监听3888/tcp端口
[root@zookeeper-node1 ~]#zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@zookeeper-node1 ~]#ss -ntl |grep 888
LISTEN 0 50 [::ffff:10.0.0.101]:3888 *:*
**zookeeper2 の場合(例):**
#只有leader监听2888/tcp端口
[root@zookeeper-node2 ~]#zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
[root@zookeeper-node2 ~]#ss -ntl|grep 888
LISTEN 0 50 [::ffff:10.0.0.102]:3888 *:*
LISTEN 0 50 [::ffff:10.0.0.102]:2888 *:*
**zookeeper3 の場合:**
[root@zookeeper-node3 ~]#zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@zookeeper-node3 ~]#ss -ntl|grep 888
LISTEN 0 50 [::ffff:10.0.0.103:3888 *:*
検証のポイント:
- 全てのノードで
Modeがleaderまたはfollowerと表示されていること。- 1台だけが
leaderであり、残りがfollowerであること。Mode: standaloneと表示されている場合は、zoo.cfgの同期設定やmyidに不備がある可能性があるため、設定を見直しましょう。
第3章:クライアントによるアクセス
ZooKeeper クラスターとの対話には、Java API や各種言語のライブラリを使用するのが一般的ですが、構築後の検証やデータの確認には、標準で用意されている コマンドラインインターフェース(CLI) が非常に強力です。
3.1 CLI クライアントによる操作(zkCli.sh)
ZooKeeper クラスターでは、どのノードからでも同じようにデータを操作・確認できます。標準コマンドの zkCli.sh を使って、クラスター内の任意のノードに接続し、データツリーの基本操作をマスターしましょう。
3.1.1 クラスターへの接続
zkCli.sh はデフォルトでローカルマシンに接続しますが、-server オプションを使うことでリモートのノードを指定できます。
# 10.0.0.103 の ZooKeeper ノードに接続する例
zkCli.sh -server 10.0.0.103:2181
接続に成功するとプロンプトが表示されます。ここで [TAB] キーを2回 押すと、利用可能な全てのコマンドが表示されます。
addWatch, addauth, close, config, connect, create, delete, deleteall, delquota, get, getAcl, getAllChildrenNumber, getEphemerals, history, listquota, ls, printwatches, quit, reconfig, redo, removewatches, set, setAcl, setquota, stat, sync, version など。
3.1.2 ZNode(ノード)の基本操作
ZooKeeper 内のデータ単位である「ZNode」を操作する一連のフローです。
1. リスト表示とノードの作成
# ルート直下のノードを確認
[zk: 10.0.0.103:2181(CONNECTED) 0] ls /
[zookeeper]
# 持久ノード(Persistent Node)の作成
# デフォルトで作成され、セッション終了後も消えません
[zk: 10.0.0.103:2181(CONNECTED) 2] create /app1 "hello,zookeeper"
Created /app1
# 臨時ノード(Ephemeral Node)の作成(参考)
# "create -e" を使うと、接続を終了(quit)した際に自動消滅します
注意点:
- 持久ノードのみ子ノード(例:
/app1/subapp1)を持つことができます。臨時ノードは子ノードを持つことができません。- ノードの作成は再帰的には行えません(
/app1が無い状態で/app1/subapp1は作成不可)。
2. データの取得と更新
# データの読み取り
[zk: 10.0.0.103:2181(CONNECTED) 4] get /app1
hello,zookeeper
# データの更新
[zk: 10.0.0.103:2181(CONNECTED) 5] set /app1 "hello,linux"
# 更新後の確認
[zk: 10.0.0.103:2181(CONNECTED) 6] get /app1
hello,linux
3. ノードの削除
# 子ノードを持たないノードを削除(Unixのrmdir相当)
[zk: 10.0.0.103:2181(CONNECTED) 7] delete /app1
# ノードとその配下全てのデータを一括削除(rm -rf相当)
# 子ノードが存在する場合は "deleteall" を使用します
[zk: 10.0.0.103:2181(CONNECTED) 8] deleteall /app1
3.1.3 ノードのメタデータ確認(stat)
ノードの状態を詳しく確認するには stat コマンド(または get -s)を使用します。表示される情報の意味を理解しておくことは、デバッグや監視において非常に重要です。
[zk: 10.0.0.103:2181(CONNECTED) 9] stat /zookeeper
| フィールド名 | 説明 |
|---|---|
| zxid | ノード作成時のトランザクションID(0x0は初期状態) |
| ctime | ノードが作成された時間 |
| mzxid | ノードが最後に更新された時の zxid |
| mtime | ノードが最後に更新された時間 |
| pzxid | そのノードまたは子ノードの作成・削除に関わる zxid |
| cversion | 子ノードのデータ更新回数 |
| dataVersion | 本ノードのデータ更新回数 |
| aclVersion | ノードのACL(権限情報)の更新回数 |
| ephemeralOwner | 臨時ノードの場合は所有者のセッションID。持久ノードは 0x0
|
| dataLength | ノードに保存されているデータの長さ(バイト) |
| numChildren | 直下にある子ノードの数 |
作業が終わったら、quit コマンドで CLI を終了します。
💡 アーキテクトの視点:CLI で見る「分散の恩恵」
クラスター環境を構築した今、ぜひ試してほしいのが 「書き込みの同期」 の確認です。
-
Node1 に接続して
create /test_cluster "data"を実行。 -
Node1 を抜けて Node3 に接続し、
get /test_clusterを実行。 - データが即座に同期されていることが確認できます。
この「どのノードに接続しても同じ最新データが見える」という特性が、マイクロサービスにおける サービスディスカバリ(サービス登録・発見) や 分散ロック の基盤となります。
CLIでのコマンド操作に続き、最後は「視覚的」にクラスターの状態を確認・管理できる便利なツールをご紹介して、このブログシリーズを締めくくりましょう。
3.2 グラフィカルクライアント:ZooInspector
コマンドライン(CLI)は強力ですが、大規模なマイクロサービス環境などで ZNode の数が増えてくると、全体の階層構造を把握するのが難しくなります。そんな時に便利なのが、Java ベースの GUI ツール ZooInspector です。
https://github.com/zzhang5/zooinspector
3.2.1 ZooInspector とは?
ZooKeeper のデータツリーをエクスプローラー形式で表示し、データの作成・更新・削除、さらにはメタデータ(ACL や Stat)の確認をマウス操作で行えるツールです。
3.2.2 起動と接続方法
ZooInspector は通常、ZooKeeper のソースパッケージの contrib ディレクトリに含まれているか、個別に JAR ファイルをダウンロードして使用します。
-
起動:
Java がインストールされているローカル PC で、以下のコマンドを実行します。
java -jar zookeeper-dev-ZooInspector.jar
-
接続設定:
左上の「Connect」アイコンをクリックし、接続文字列(例:10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181)を入力します。 -
確認:
接続に成功すると、左側に ZNode のツリー構造、右側に選択したノードの詳細データが表示されます。
3.2.3 主なメリット
- 階層構造の可視化: サービス登録状況などを一目で把握できます。
- 直感的な編集: テキストエディタ形式で値を書き換え、「Save」ボタンで即座に反映可能です。
- ACLの確認: 複雑な権限設定も、GUI 上でリストとして確認できるため、ミスを防げます。
🏛️ おわりに
全3回にわたり、Apache ZooKeeper の基本概念からクラスター(Ensemble)の堅牢な構築、そしてクライアントからのアクセス方法までを解説してきました。
分散システムの「守護神」である ZooKeeper をマスターすることは、可用性の高いマイクロサービスや Cloud Native なインフラを設計する上で大きな武器になります。
今回のまとめ:
- 理論: Leader/Follower の役割と Quorum(過半数合意)を理解する。
- 実践:
myidとzoo.cfgを正しく設定し、3台以上の奇数構成で構築する。- 運用: CLI と GUI(ZooInspector)を使い分け、データツリーを効率的に管理する。