一、はじめに
Google Docsで同僚と同時にドキュメントを編集したり、Figmaでデザイナーと共同でインターフェースを調整したりする際、ふと考えたことはありませんか。「なぜ二人が同じ位置に同時に文字を入力しても、最終的な結果が上書きされたり文字化けしたりしないのだろうか?」と。
その背後には、分散システムにおいて最も挑戦的な問題の一つである並行衝突(Concurrent Conflict)が隠されています。複数のユーザーが同じデータを同時に編集し、それらの編集を異なるデバイス間で同期させる必要があるとき、どのようにして全員が最終的に同じ結果を見られるように保証するのでしょうか?
本記事では、リアルタイム共同編集を支えるアルゴリズムの進化を解説します。
古典的な操作変換(OT)から、伝統的なCRDTsアルゴリズムであるRGA、そして現代的なEG-Walkerまでを解説します。アルゴリズムの原理を説明するだけでなく、MoonBitを用いてアルゴリズムのコアロジックを実装し、最終的にそれを利用して、オフライン後の再接続時にマージ可能なシンプルな共同編集エディタを構築する方法を展示します。
二、リアルタイム共同編集の核心的な課題
多人数共同編集テキストエディタを構築すると仮定しましょう。各ユーザーは自分のデバイスにドキュメントのコピーを持っており、ユーザーが編集を行うと、その操作はネットワークを通じて他のユーザーに同期されます。スムーズな編集体験を保証するため、ユーザーの入力はサーバーの確認を待つことなく、即座に反映されるべきです。
ここで問題が発生します。二人のユーザーが同時に編集すると何が起こるでしょうか?以下のシナリオを考えてみましょう。

これが並行衝突の本質です。「同じ操作のシーケンスでも、適用される順序が異なると、異なる結果が生じる可能性がある」 ということです。
ここで求められるのは、操作の到達順序に関わらず、最終的に全員が同じ結果を得られ、かつ各編集者の貢献が正しく反映される仕組みです。
この性質を結果整合性(Eventual Consistency)と呼びます。
三、解決策一:操作変換(OT)
原理と簡単な実装
操作変換(Operational Transformation, OT) は、リアルタイム共同編集の衝突を解決するために1989年に誕生した最初期のアルゴリズムです。Google DocsやEtherpadなどの初期の共同編集ツールはこのスキームを採用していました。OTの基本的な考え方は、「操作同士が互いに影響を与えるのであれば、操作を適用する前に、既に行われた操作に基づいてその操作を『変換』し、現在の状態に適応させる」というものです。

OTがどのように衝突を解決するか:
-
初期のドキュメントは
ABです。Aliceが位置1にXを挿入し、ローカルではAXBになります。Bobは位置1にYを挿入し、ローカルではAYBになります。ここで双方は相手の操作を同期する必要があります。 -
AliceがBobの操作
insert(1, 'Y')を受信したとき、彼女はそれを直接実行することはできません。なぜなら、彼女はすでに位置1にXを挿入しており、後続の文字はすべて右に1つずれているからです。OTはBobの挿入位置(1)がAliceの挿入位置より前ではないことを検知し、位置を +1 してinsert(2, 'Y')に変換します。Aliceがこれを実行するとAXYBになります。 -
同様に、BobはAliceの
insert(1, 'X')を受信します。しかしAliceの挿入位置(1)はBobの(1)より大きくないため、調整は行われません。Bobは直接実行し、位置1にXを挿入して、同じくAXYBを得ます。
MoonBitで簡単に実装してみましょう:
enum Op {
Insert(Int, Char) // Insert(位置, 文字)
Delete(Int) // Delete(位置)
}
/// 変換関数:op1を、op2が既に実行された後の等価な操作に変換する
fn transform(op1 : Op, op2 : Op) -> Op {
match (op1, op2) {
(Insert(pos1, ch), Insert(pos2, _)) =>
Insert(if pos1 <= pos2 { pos1 } else { pos1 + 1 }, ch)
(Insert(pos1, ch), Delete(pos2)) =>
Insert(if pos1 <= pos2 { pos1 } else { pos1 - 1 }, ch)
// ... 他のケースも同様
}
}
OTが存在する問題
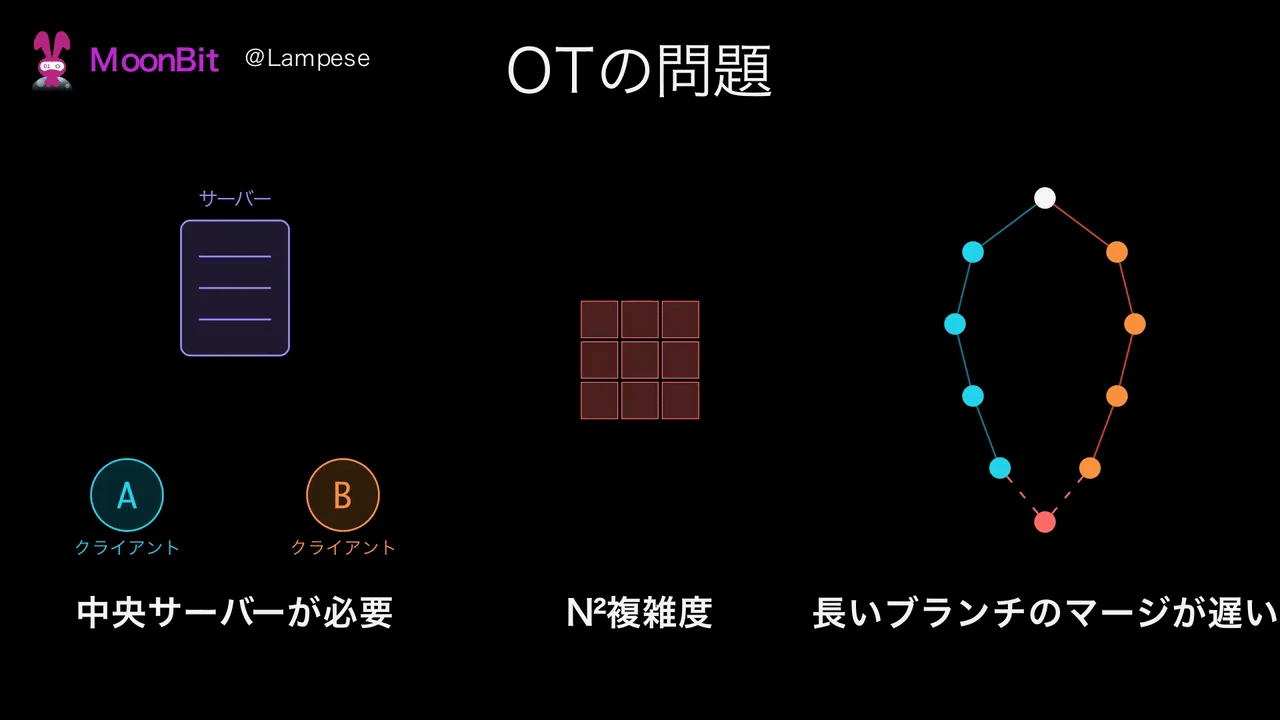
OTは業界で広く応用されていますが(Google DocsはOTに基づいています)、いくつか根本的な問題を抱えています。
-
中央サーバーが必要:OTは操作のグローバルな順序を決定するために権威あるサーバーを必要とします。サーバーがなければ、誰の操作が「先に」発生したかを確定できません。
-
変換ルールの複雑性の爆発:N種類の操作タイプがある場合、$N^2$ 個の変換ルールを定義する必要があります。操作タイプが増える(リッチテキストの太字、斜体、リンクなど)と、複雑性は急激に上昇します。
-
長いブランチのマージが極めて遅い:二人のユーザーが長時間オフラインで編集した場合、再接続時に大量の操作を変換する必要があり、パフォーマンスが悪くなります。
四、解決策二:RGA:古典的なシーケンスCRDT
CRDT(Conflict-free Replicated Data Type)は全く異なるアプローチをとります。「受信した操作を変換するのではなく、操作がどのような順序で適用されても結果が同じになるようなデータ構造を設計する」 というものです。これは特殊な「足し算」を設計するようなもので、どのような順番で数字を足しても結果は同じになります。数学的には、操作が交換法則と結合法則を満たすことが求められます。
RGA:古典的なシーケンスCRDT
RGA(Replicated Growable Array)は2011年に提案されたシーケンスCRDTの一種で、共同テキスト編集における衝突問題を解決するために特化しています。そのアイデアは非常にシンプルです。**「絶対位置の代わりに相対位置を使用する」ことです。

再びAliceとBobの例を使います。初期ドキュメントは AB で、AliceとBobが同時に位置1に文字を挿入します。Aliceは X を、Bobは Y を挿入します。
OTの手法は座標位置を調整することでした。しかしRGAは考え方を変え、**「数値的な位置ではなく、『誰の後ろに挿入するか』で挿入ポイントを記述する」**ようにしました。
具体的には:
-
Aliceの操作は「位置1にXを挿入」ではなく、「Aの後ろにXを挿入」になります。
-
Bobの操作は「Aの後ろにYを挿入」になります。
二つの操作が共にAの後ろに挿入しようとした場合、どうすればよいでしょうか?RGAは各文字にグローバルに一意なIDを割り当てます。このIDは二つの部分から構成されます:
-
ユーザーID:各ユーザーが持つ一意の識別子(例:Aliceは
A、BobはB) -
ローカルカウンタ:各ユーザーが保持するインクリメンタルなカウンタ。新しい文字を挿入するたびに +1 される。
したがって、 A@1 は「Aliceの1番目の操作」、 B@1 は「Bobの1番目の操作」を表します。二つの文字が同じ位置に挿入されようとした場合、IDを比較して順序を決定します。まずローカルカウンタを比較し、カウンタが同じ場合はユーザーIDをタイブレーカーとして比較します。ここでは両方のカウンタが1なので、ユーザーIDを比較します。 B > A なので、 B@1 が A@1 の前に配置され、結果は A → Y → X → B、つまり AYXB となります。
MoonBitで実装する場合、まず各ノードの型とその compare ルールを定義できます:
/// 一意の識別子
struct ID {
peer : UInt64 // ユーザー ID
counter : Int // ローカルカウンタ
} derive(Eq)
/// 二つのIDを比較し、並行挿入の衝突を解決するために使用する
impl Compare for ID with compare(self, other) {
// まず counter を比較し、次に peer を比較する(タイブレーク)
if self.counter != other.counter {
other.counter - self.counter
} else if self.peer > other.peer { -1 }
else if self.peer < other.peer { 1 }
else { 0 }
}
挿入時には、ターゲット位置の後に正しい挿入ポイントを見つけます。自分より大きなIDを持つノードをすべてスキップします:
/// target の後に挿入し、挿入位置を返す
fn find_insert_pos(order : Array[ID], target_pos : Int, new_id : ID) -> Int {
let mut pos = target_pos + 1
while pos < order.length() && new_id.compare(order[pos]) > 0 {
pos = pos + 1 // new_id の方が小さいため、さらに後ろを探す
}
pos
}
先ほどは挿入の場合のみを想定しましたが、削除の問題に対してRGAは トゥームストーン(Tombstone、墓標) 戦略を採用します。文字を削除する際、実際には削除せず、「削除済み」としてマークを付けるだけです。
なぜ実際に削除できないのでしょうか?このシナリオを考えてみてください。AliceがBを削除し、同時に(削除をまだ受け取っていない)BobがBの後ろにXを挿入したとします。もしBが本当に消えてしまったら、Bobの「Bの後ろに挿入」という操作は参照先を見失ってしまいます。トゥームストーンによってBをデータ構造内に保持し、レンダリング時にのみスキップさせることで、Bobの操作は依然として有効であり続けます。
/// RGA ノード
struct RGANode {
id : ID
char : Char
mut deleted : Bool // トゥームストーンフラグ
}
/// 削除:トゥームストーンとしてマーク
fn RGANode::delete(self : RGANode) -> Unit {
self.deleted = true
}
/// レンダリング:トゥームストーンをスキップ
fn render(nodes : Array[RGANode]) -> String {
let sb = StringBuilder::new()
for node in nodes {
if !node.deleted { sb.write_char(node.char) }
}
sb.to_string()
}
上記の簡単な実装では、簡潔で分かりやすくするために配列を使用してRGAのノードを格納しています。データ構造に詳しい読者なら、RGAでは頻繁に挿入が発生するため、連結リストの方がこのアルゴリズムに適していることに気づくでしょう。実際のエンジニアリングでは、B+ Treeやスキップリストのような、より堅牢で効率的な構造がよく使われます。
RGAの問題
RGAは並行衝突の問題を解決し、中央サーバーを必要とせず、P2P同期をサポートしますが、顕著な欠点もあります。
-
メタデータの肥大化:各文字にID(実務上は簡単に16バイト以上に達します)と先行参照を保存する必要があります。10万文字のドキュメントでは、メタデータが内容そのものより大きくなる可能性があります。
-
トゥームストーンの累積:削除された文字は永遠にメモリ内に残ります。何度も編集されたドキュメントでは、データの90%がトゥームストーンである可能性もあり、リッチテキストのような他の次元が加わると、この欠点による影響がさらに深刻化します。
-
読み込みの遅さ:ディスクからドキュメントを読み込む際、データ構造全体を再構築する必要があり、これは $O(n)$ あるいは $O(n \log n)$ の操作になります。

五、Event Graph Walker:より優れたスキーム
原理の紹介
Event Graph Walker(略称 Eg-walker)は、Joseph GentleとMartin Kleppmannによって2024年に提案された新しいCRDTアルゴリズムです。
これまで見てきたように、OTは操作がシンプル(位置インデックスのみ)ですが中央サーバーを必要とし、CRDTはP2Pをサポートしますがメタデータの肥大化が深刻です。Eg-walkerの核心的な洞察は、「両者を組み合わせることができる。すなわち、保存時にはシンプルなインデックスを用い、マージ時に一時的にCRDTを構築する」 という点にあります。
操作はOTのように軽量で、 insert(pos, char) と delete(pos) だけを記録します。並行操作をマージする必要があるときだけ、履歴を一時的に再生してCRDTの状態を構築し、衝突を解決します。マージが終わればそれは破棄します。
この「一時的にCRDTを構築して問題を解決する方式」のパフォーマンスに懸念を抱く読者もいるかもしれませんが、一時的な構築にオーバーヘッドがあることは認めざるを得ません。しかし、ほとんどの時間はCRDTが編集に関与する必要はなく、並行編集を同期するときだけ必要になります。また、Eg-Walkerの性質上、増分構築や局所的な構築をサポートしていることは明らかで、スナップショットから構築するか、衝突領域のみでCRDTを構築して衝突を解決すれば十分です。また、操作履歴が複雑になればなるほど、増え続ける構造を維持するよりも、一時的な構築の方がより堅牢で効率的になることが予想されます。

コード実装
基礎データ構造
まず操作の定義です。RGAが使用する「あるIDの後ろに挿入する」という相対的な位置指定とは異なり、Eg-walkerはOTのようにシンプルに数値的な位置インデックスを直接使用します:
enum SimpleOp {
Insert(Int, String) // Insert(位置, 内容)
Delete(Int, Int) // Delete(位置, 長さ)
}
次にイベント(Event) の定義です。イベントは操作をパッケージングしたもので、因果関係の情報が追加されています:
struct Event {
id : ID // 一意の識別子
deps : Array[ID] // 依存するイベント(親ノード)
op : SimpleOp // 実際の操作内容
lamport : Int // Lamport タイムスタンプ(順序付け用)
}
これらに基づいて、イベントグラフ(Event Graph)を定義できます:
struct EventGraph {
events : Map[ID, Event] // すべての既知のイベント
frontiers : Array[ID] // 現在の最新イベント ID 集合
}
ここでの定義における frontiers は「現在のバージョン」、つまり他のどのイベントからも依存されていないイベントの集合を記録します。読者が Git の概念に詳しければ、Git における現在の全ブランチの HEAD ポインタ集合のようなものだと理解してください。
イベントの追加と Frontier の維持
新しいイベントを受信したとき、イベントを現在のイベントテーブルに保存するだけでなく、frontier を更新する必要があります。frontier は「後続イベントのないイベント」を記録しているため、新しいイベントが特定の古い head に依存している場合、その古い head には後続ができたことを意味し、もはや「最新」ではなくなります。そのため、それを frontier から削除し、新しいイベントを frontier に追加します。
fn EventGraph::add_event(self : EventGraph, event : Event) -> Unit {
self.events[event.id] = event
self.frontiers = self.heads.retain(frontier => !event.deps.contains(frontier))
self.frontiers.push(event.id)
}
LCA(最近共通祖先)とトポロジカルソート
二つのバージョンをマージするには、二つの問題を解決する必要があります:
-
分岐点を見つける(Event Graph上でLCAを見つける):どこから再生を開始するかを決定する。
-
再生順序を確定する(Lamport トポロジカルソートに基づき):因果関係に従ってイベントを並べ替える。
これら二つの部分は基本的なグラフ理論の問題であり、資料を調べればすぐに実装できるはずです。ただし、実務で Eg-Walker アルゴリズムを実装する場合、通常は一般的な LCA アルゴリズムを使用するのではなく、データ構造を改良し、キャッシュメカニズムを適用して効率を高めます。
マージアルゴリズム
これで全コンポーネントが揃いました。完全なマージアルゴリズムを実装できます:
fn EventGraph::merge(
self : EventGraph,
local_frontiers : Array[ID],
remote_frontiers : Array[ID], // リモート peer の frontiers。イベントと共に送信される
remote_events : Array[Event]
) -> String {
// ステップ 1:リモートイベントをイベントグラフに追加
for event in remote_events {
self.add_event(event)
}
// ステップ 2:ローカルバージョンとリモートバージョンの LCA を見つける(VersionVector で積集合を取る)
let lca = self.find_lca(local_frontiers, remote_frontiers)
// ステップ 4:LCA から二つのブランチまでの全イベントを収集
let events_to_replay = self.collect_events_after(lca)
// ステップ 5:Lamport タイムスタンプでトポロジカルソート
let sorted = self.topological_sort(events_to_replay)
// ステップ 6:一時的な RGA を作成し、全イベントを再生
let temp_rga = RGA::new()
for event in sorted {
self.apply_to_rga(temp_rga, event)
}
// ステップ 7:最終的なテキストを返し、一時的な RGA を破棄
temp_rga.to_string()
}
マージのプロセスは三つの段階にまとめられます:
-
Retreat(後退):LCAを見つけ、再生が必要なイベントの範囲を確定する。
-
Collect(収集):二つのブランチ上の全イベントを収集し、Lamport タイムスタンプでトポロジカルソートする。
-
Advance(前進):一時的な RGA を作成し、順序通りにイベントを再生して、CRDT で衝突を解決する。
六、さらに一歩先へ:Lomo と共同編集テキストエディタの開発
Loro/Lomo とは何か
Loro は Eg-walker アルゴリズムに基づいた、Rust 実装の高性能な CRDT ライブラリです。複数のデータ型(テキスト、リスト、Map、移動可能リスト、木構造など)をサポートし、豊富な共同編集機能を提供し、リアルタイム共同編集アプリケーションの構築に利用されています。そして Lomo は Loro の MoonBit 移植版であり、Loro の Rust 版とバイナリ互換を保っています。これは、lomo で生成されたドキュメントを Loro で読み取ることができ、その逆も可能であることを意味します。
Lomo のコア API は非常に簡潔です:
let doc = LoroDoc::new()
doc.set_peer_id(1UL)
// テキストコンテナを取得して編集
let text = doc.get_text("content")
doc.text_insert(text, 0, "Hello, World!")
doc.text_delete(text, 5, 2)
// 更新をエクスポート(同期用)
let updates = doc.export_updates()
// 別の peer が更新をインポート
let doc2 = LoroDoc::new()
doc2.set_peer_id(2UL)
doc2.import_updates(updates) // 両方の内容が自動的に同期される
共同編集テキストエディタを作る
共同編集のニーズはフロントエンドで発生することが多いため、Loro はフロントエンドでもこの優れた CRDTs ライブラリを使用できるよう Wasm API をリリースしています。しかし、Rust でコンパイルされた Wasm はサイズが大きくなりがちで、ユーザーの特定のニーズに合わせて tree-shaking を行うことが難しいため、多くのフロントエンド開発者にとって Loro を使用する際の悩みとなっていました。しかし、もしフロントエンドで MoonBit+Lomo を JavaScript バックエンドで記述すれば、コンパイラは必要な API だけをコンパイルするため、最終的なコンパイル結果は非常に優れたものになります。同時に、MoonBit の Wasm コンパイル結果は往々にしてより小さく、クリーンであり、Wasm バックエンドを使用してリリースする場合でも非常に良い結果が得られます。
そこで、JavaScript バックエンドに基づいて共同編集テキストエディタを作成し、この点を検証してみましょう。以下に大まかな実装方法を示します:
まず MoonBit 側で、JavaScript から呼び出すためのドキュメント操作をカプセル化します:
///| ドキュメントを作成
pub fn create_doc(peer_id : Int) -> Int {
let doc = LoroDoc::new()
doc.set_peer_id(peer_id.to_uint64())
let text = doc.get_text("body")
// ローカルの更新をサブスクライブし、送信待ちデータを自動的に収集
let _ = doc.subscribe_local_update((bytes) => {
pending_updates.push(bytes)
true
}
// ...
}
///| 編集操作を適用
pub fn apply_edit_utf16(doc_id : Int, start : Int, delete_len : Int, insert_text : String) -> Bool {
let doc = docs[doc_id]
let text = texts[doc_id]
if delete_len > 0 { doc.text_delete_utf16(text, start, delete_len)? }
if insert_text.length() > 0 { doc.text_insert_utf16(text, start, insert_text)? }
true
}
JavaScript 側でユーザー入力と同期ロジックを処理します:
// ユーザー入力を処理
function handleInput(side, other) {
const nextText = side.el.textContent;
const change = diffText(side.text, nextText); // 新旧テキストの差分を計算
// CRDT に適用(MoonBit からエクスポートされた関数を呼び出す)
apply_edit_utf16(side.id, change.start, change.deleteCount, change.insertText);
side.text = nextText;
syncFrom(side, other); // もう一方に同期
}
// 同期ロジック
function syncFrom(from, to) {
const updates = drain_updates(from.id); // 送信待ちの更新を取得(MoonBit エクスポート)
if (state.online) {
apply_updates(to.id, updates); // オンライン:即座に適用(MoonBit エクスポート)
} else {
from.outbox.push(...updates); // オフライン:送信箱にキャッシュ
}
}
最終的に、いくつかのスタイル設定やページ作成作業を経て、CRDTs に基づく共同編集エディタが完成します:
![[demo.gif]]
このプロジェクトのソースコードは記事の末尾に記載されています。興味のある読者は参考にしながら、より面白いプロジェクトを開発してみてください。
七、まとめ
本記事では並行衝突の問題から出発し、リアルタイム共同編集アルゴリズムの進化を紹介しました:
-
OT:操作を変換することで衝突を解決するが、中央サーバーが必要。
-
RGA:一意のIDと相対位置を用いて非中心化を実現するが、メタデータが肥大化する。
-
Eg-walker:両者の利点を組み合わせ、シンプルな操作を保存し、マージ時に一時的にCRDTを構築する。
MoonBit を用いて上記のアルゴリズムのコアデータ構造と主要な計算部分を実装し、Loro/lomo ライブラリとその基本的な使用法を紹介し、Lomo を用いてシンプルな共同編集アプリケーションを開発しました。
1989年のOTの誕生から、2011年のRGAなどのCRDTの定式化、そして2024年のEg-walkerによる革新的な融合まで、リアルタイム共同編集アルゴリズムは30年以上の進化を遂げてきました。近年では Local-first の理念の台頭に伴い、CRDT は学術論文から実務の場へと移行しており、Figma や Linear の背後にもその姿があります。将来的には、履歴の圧縮、複雑なデータ構造、エンドツーエンド暗号化などの方向性が依然として急速に推進されています。MoonBit が効率的に WebAssembly へコンパイルできる能力は、ブラウザやエッジデバイスにおける CRDTs の展開に新たな可能性を提供しています。