Physical/Logical plan って何?
Apache Spark ではデータを分散処理するために Spark SQL を実行することができます。
Spark SQL では SQL のクエリと DataFrame/Dataset API を使って任意の処理を記述できます。
この SQL のクエリや DataFrame/Dataset は、Spark の内部では Catalyst Optimizer というフレームワークによって次のように処理されます。
- Logical Plan を解析 (参照を解決): Parsed Logical Plan -> Analyzed Logical Plan
- Logical Plan を最適化: Analyzed Logical Plan -> Optimized Logical Plan
- Physical Plan を生成: Optimized Logical Plan -> Physical Plan
- Java バイトコードを生成: Physical Plan -> Java bytecode
Apache Spark には Lazy Evaluation という特徴があり、Dataset/DataFrame は遅延評価され、実際の処理は Action が実行されたときのみ実行されます。(Transformation では実行されません。)
内部的には Dataset/DataFrame はデータ処理のための Logical Plan を表現することになります。
Action が実行されたとき、Spark のクエリオプティマイザである Catalist は、Logical Plan を最適化し、並列・分散処理を効率的に実行するための Physical Plan を生成します。
何に使うの?
Physical/Logical Plan はデバッグやトラブルシューティングのために役立ちます。
例えば、手元にある Dataset/DataFrame にどんな処理が適用されるのか整理して確認できます。
他にも、意図した JOIN オペレータが使用されているか、パーティション済のテーブルのうち意図したカラムのみがフィルタされているか等を確認できて便利です。
どうやって確認するの?
Dataset/DataFrame の explain メソッドまたは Spark Web UI から確認できます。
void explain() : Physical Plan をコンソールに表示します。
void explain(true): Logical Plan と Physical Plan の両方をコンソールに表示します。
1. Spark クラスタの用意
今回は EMR 5.19.0 (Spark 2.3.2) を使います。
2. 入力データの用意
今回は Spark The Definitive Guide のサンプルデータを流用します。
$ git clone https://github.com/databricks/Spark-The-Definitive-Guide.git
$ cd Spark-The-Definitive-Guide/
$ hdfs dfs -put data /data
3. REPL の起動
今回は spark-shell で Scala で試してみます。
マスターノードで spark-shell コマンドを実行します。
$ spark-shell
4. クエリの実行
とりあえず、入力の JSON ファイルを適当な条件でクエリしてみます。
scala> val df = spark.read.json("/data/flight-data/json/2015-summary.json")
scala> df.where("dest_country_name = 'Japan'").show()
+-----------------+-------------------+-----+
|DEST_COUNTRY_NAME|ORIGIN_COUNTRY_NAME|count|
+-----------------+-------------------+-----+
| Japan| United States| 1548|
+-----------------+-------------------+-----+
5. explain による Plan の表示
Physical Plan
さきほど実行したクエリの Physical Plan を explain() メソッドで出力してみましょう。
scala> df.where("dest_country_name = 'Japan'").explain()
== Physical Plan ==
*(1) Project [DEST_COUNTRY_NAME#6, ORIGIN_COUNTRY_NAME#7, count#8L]
+- *(1) Filter (isnotnull(dest_country_name#6) && (dest_country_name#6 = Japan))
+- *(1) FileScan json [DEST_COUNTRY_NAME#6,ORIGIN_COUNTRY_NAME#7,count#8L] Batched: false, Format: JSON, Location: InMemoryFileIndex[hdfs://ip-172-31-19-68.ap-northeast-1.compute.internal:8020/data/flight-data/js..., PartitionFilters: [], PushedFilters: [IsNotNull(DEST_COUNTRY_NAME), EqualTo(DEST_COUNTRY_NAME,Japan)], ReadSchema: struct<DEST_COUNTRY_NAME:string,ORIGIN_COUNTRY_NAME:string,count:bigint>
Logical Plan
今度は引数に true を与えて、explain(true) で Physical Plan と Logical Plan の両方を出力してみましょう。
scala> df.where("dest_country_name = 'Japan'").explain(true)
== Parsed Logical Plan ==
'Filter ('dest_country_name = Japan)
+- AnalysisBarrier
+- Relation[DEST_COUNTRY_NAME#6,ORIGIN_COUNTRY_NAME#7,count#8L] json
== Analyzed Logical Plan ==
DEST_COUNTRY_NAME: string, ORIGIN_COUNTRY_NAME: string, count: bigint
Filter (dest_country_name#6 = Japan)
+- Relation[DEST_COUNTRY_NAME#6,ORIGIN_COUNTRY_NAME#7,count#8L] json
== Optimized Logical Plan ==
Filter (isnotnull(dest_country_name#6) && (dest_country_name#6 = Japan))
+- Relation[DEST_COUNTRY_NAME#6,ORIGIN_COUNTRY_NAME#7,count#8L] json
== Physical Plan ==
*(1) Project [DEST_COUNTRY_NAME#6, ORIGIN_COUNTRY_NAME#7, count#8L]
+- *(1) Filter (isnotnull(dest_country_name#6) && (dest_country_name#6 = Japan))
+- *(1) FileScan json [DEST_COUNTRY_NAME#6,ORIGIN_COUNTRY_NAME#7,count#8L] Batched: false, Format: JSON, Location: InMemoryFileIndex[hdfs://ip-172-31-19-68.ap-northeast-1.compute.internal:8020/data/flight-data/js..., PartitionFilters: [], PushedFilters: [IsNotNull(DEST_COUNTRY_NAME), EqualTo(DEST_COUNTRY_NAME,Japan)], ReadSchema: struct<DEST_COUNTRY_NAME:string,ORIGIN_COUNTRY_NAME:string,count:bigint>
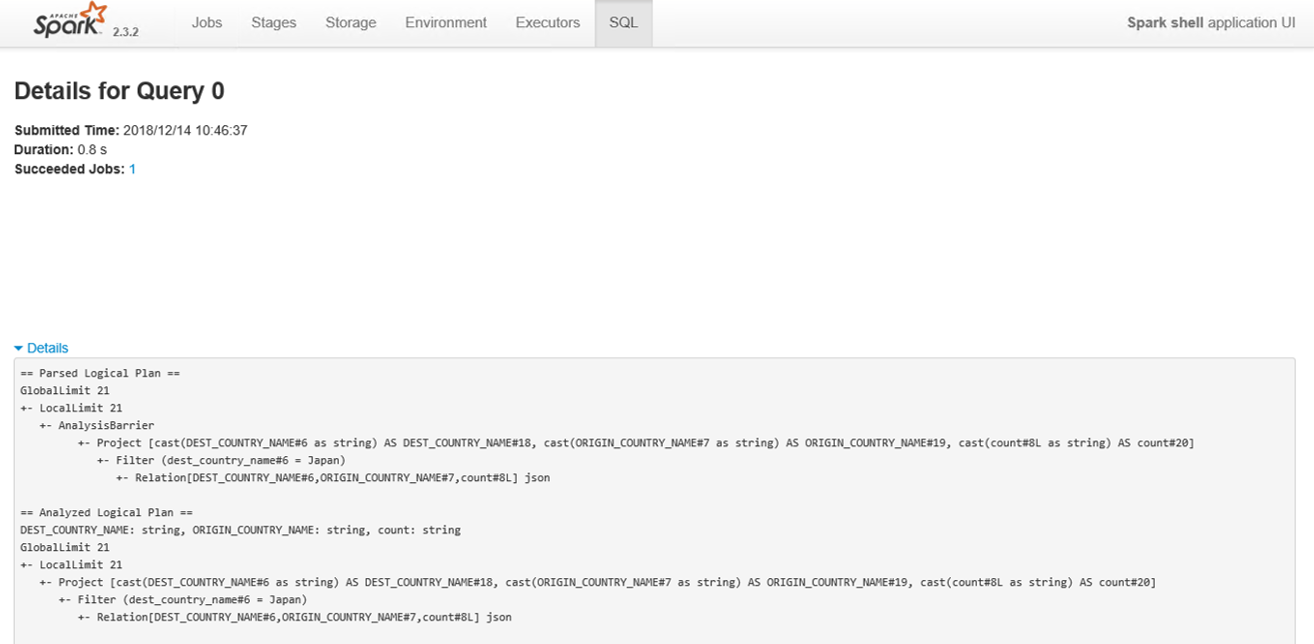
6. Spark Web UI による Plan の表示
Spark Application を選択して SQL タブから対象のクエリを開き、"Details" を開くと Physical/Logical Plan が表示されます。
explain(true) で表示されるものと同一です。
どう読むの?
例として適当なデータを JOIN して Physical Plan を見てみましょう。
scala> val df_2014 = spark.read.json("/data/flight-data/json/2014-summary.json")
scala> val df_2013 = spark.read.json("/data/flight-data/json/2013-summary.json")
scala> df_join.explain(true)
== Parsed Logical Plan ==
Join Inner, ((origin_country_name#142 = origin_country_name#130) && (dest_country_name#141 = dest_country_name#129))
:- Relation[DEST_COUNTRY_NAME#141,ORIGIN_COUNTRY_NAME#142,count#143L] json
+- Relation[DEST_COUNTRY_NAME#129,ORIGIN_COUNTRY_NAME#130,count#131L] json
== Analyzed Logical Plan ==
DEST_COUNTRY_NAME: string, ORIGIN_COUNTRY_NAME: string, count: bigint, DEST_COUNTRY_NAME: string, ORIGIN_COUNTRY_NAME: string, count: bigint
Join Inner, ((origin_country_name#142 = origin_country_name#130) && (dest_country_name#141 = dest_country_name#129))
:- Relation[DEST_COUNTRY_NAME#141,ORIGIN_COUNTRY_NAME#142,count#143L] json
+- Relation[DEST_COUNTRY_NAME#129,ORIGIN_COUNTRY_NAME#130,count#131L] json
== Optimized Logical Plan ==
Join Inner, ((origin_country_name#142 = origin_country_name#130) && (dest_country_name#141 = dest_country_name#129))
:- Filter (isnotnull(dest_country_name#141) && isnotnull(origin_country_name#142))
: +- Relation[DEST_COUNTRY_NAME#141,ORIGIN_COUNTRY_NAME#142,count#143L] json
+- Filter (isnotnull(origin_country_name#130) && isnotnull(dest_country_name#129))
+- Relation[DEST_COUNTRY_NAME#129,ORIGIN_COUNTRY_NAME#130,count#131L] json
== Physical Plan ==
*(2) BroadcastHashJoin [origin_country_name#142, dest_country_name#141], [origin_country_name#130, dest_country_name#129], Inner, BuildRight
:- *(2) Project [DEST_COUNTRY_NAME#141, ORIGIN_COUNTRY_NAME#142, count#143L]
: +- *(2) Filter (isnotnull(dest_country_name#141) && isnotnull(origin_country_name#142))
: +- *(2) FileScan json [DEST_COUNTRY_NAME#141,ORIGIN_COUNTRY_NAME#142,count#143L] Batched: false, Format: JSON, Location: InMemoryFileIndex[hdfs://ip-172-31-19-68.ap-northeast-1.compute.internal:8020/data/flight-data/js..., PartitionFilters: [], PushedFilters: [IsNotNull(DEST_COUNTRY_NAME), IsNotNull(ORIGIN_COUNTRY_NAME)], ReadSchema: struct<DEST_COUNTRY_NAME:string,ORIGIN_COUNTRY_NAME:string,count:bigint>
+- BroadcastExchange HashedRelationBroadcastMode(List(input[1, string, true], input[0, string, true]))
+- *(1) Project [DEST_COUNTRY_NAME#129, ORIGIN_COUNTRY_NAME#130, count#131L]
+- *(1) Filter (isnotnull(origin_country_name#130) && isnotnull(dest_country_name#129))
+- *(1) FileScan json [DEST_COUNTRY_NAME#129,ORIGIN_COUNTRY_NAME#130,count#131L] Batched: false, Format: JSON, Location: InMemoryFileIndex[hdfs://ip-172-31-19-68.ap-northeast-1.compute.internal:8020/data/flight-data/js..., PartitionFilters: [], PushedFilters: [IsNotNull(ORIGIN_COUNTRY_NAME), IsNotNull(DEST_COUNTRY_NAME)], ReadSchema: struct<DEST_COUNTRY_NAME:string,ORIGIN_COUNTRY_NAME:string,count:bigint>
Plan 上に表示されている各行の先頭のキーワードは Logical/Physical Operator です。
今回登場した Logical/Physical Operator の一部を次にて説明します。
BroadcastHashJoin
Broadcast Hash Join (BHJ) は JOIN 対象のテーブルに、ひとつのマシンのメモリに収まる程度に十分小さいテーブル ("Broadcastable" なテーブル)が存在する場合に選択されます。
"Broadcastable" なテーブルとは、データサイズが spark.sql.autoBroadcastJoinThreshold の設定値 (デフォルトで 10MB) を下回るものを指します。
Broadcast Hash Join が選択された場合は、テーブルはすべてのコンピュートノードにブロードキャストされます。
ちなみに、BroadcastHashJoin が選択されない場合、ShuffleHashJoin などが選択されます。
Project
Project は Logical Operator のひとつで、カラムを Projection します。
例えば、特定のカラムを select した場合、この部分に出現します。
Filter
Filter は Logical Operator のひとつで、条件が指定されている場合に出現します。
FileScan
PartitionFilters
PartitionFilters はパーティションキーによって DataSource をフィルタリングする際に使用されます。
PushedFilters
PushedFilters は PushdownPredicate によって DataSource にフィルタリングする際に使用され、プッシュダウンされた条件句を表示します。
Note: Pushdown と DataSource
先日の NTTデータ テクノロジーカンファレンス2018 の "Spark SQL - The internal -" というセッションでも触れられていましたが、DataSource がこの条件句を使用して最適化をするかどうかは DataSource 側の実装依存とのことです。
例えば、JSON を対象にしたデータで explain した場合にも以下のように PushedFilter は表示されます。
val df = spark.read.json("s3://sample_bucket/people.json")
df.printSchema()
df.filter($"age" > 20).explain()
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
== Physical Plan ==
*Project [age#47L, name#48]
+- *Filter (isnotnull(age#47L) && (age#47L > 20))
+- *FileScan json [age#47L,name#48] Batched: false, Format: JSON, Location: InMemoryFileIndex[s3://sample_bucket/people.json], PartitionFilters: [], PushedFilters: [IsNotNull(age), GreaterThan(age,20)], ReadSchema: struct<age:bigint,name:string>
ただし、JSON には PushDown をサポートするような仕組みがないため、実際には PushDown されずファイル全体がフルスキャンされます。
explain() によって最終的に PushDown が適用されたかどうかを知る術はないため注意が必要です。
ちなみに、これに関しては少し思うところがあったので spark-dev メーリングリストで取り上げてディスカッションしてみました。
現在 Spark コミュニティでディスカッションされている DataSourceV2 でもこういった機能を包括的に実現するのは簡単ではなさそうです。部分的にはできそうですが...
- Pushdown in DataSourceV2 question http://apache-spark-developers-list.1001551.n3.nabble.com/Pushdown-in-DataSourceV2-question-td25875.html#a25881
おわりに
今回は Apache Spark の Physical/Logical plan の解説を試みてみました。
公式ドキュメントにこのあたりの記述が少ないからまとめてみようとの気持ちで始めた記事でしたが、意外とブログ等で取り上げられている情報が多いかんじですね。。
何か新しい発見があったら適宜アップデートしていければと思います。
(もし間違い等にお気づきの際は遠慮なくご指摘ください。)
参考
- DataSet / Spark 2.4.0 JavaDoc https://spark.apache.org/docs/latest/api/java/org/apache/spark/sql/Dataset.html
- Catalyst Optimizer / databricks https://databricks.com/glossary/catalyst-optimizer
- Optimizing Apache Spark SQL Joins / SlideShare https://www.slideshare.net/databricks/optimizing-apache-spark-sql-joins
- Broadcast Hash Joins in Apache Spark / Sujith Jay Nair https://sujithjay.com/spark-sql/2018/02/17/Broadcast-Hash-Joins-in-Apache-Spark/
- Shuffle Hash and Sort Merge Joins in Apache Spark / Sujith Jay Nair https://sujithjay.com/spark-sql/2018/06/28/Shuffle-Hash-and-Sort-Merge-Joins-in-Apache-Spark/
- The Internals of Spark SQL (Apache Spark 2.4.0) https://jaceklaskowski.gitbooks.io/mastering-spark-sql/