はじめに
機械学習の分類とそれらのアルゴリズムのライブラリを用いた簡単な実装をまとめました。
各アルゴリズムのコードはサンプルデータまで含めているので、そのまま実行することができます。
必要最低限のパラメータしか設定していないので、細かい設定は公式ドキュメントなど参照して設定してください。
それぞれのアルゴリズムについては、簡単な説明は載せてますが、詳しい説明はしていません。
対象読者
- 機械学習アルゴリズムの分類を知りたい
- 機械学習アルゴリズムを実装して動かしたい
ゴール
- 機械学習のアルゴリズムの分類がわかる
- 機械学習アルゴリズムの実装ができる
機械学習の分類
機械学習は以下のように分類されます。
- 教師あり学習
- 回帰
- 分類
- 教師なし学習
- 強化学習
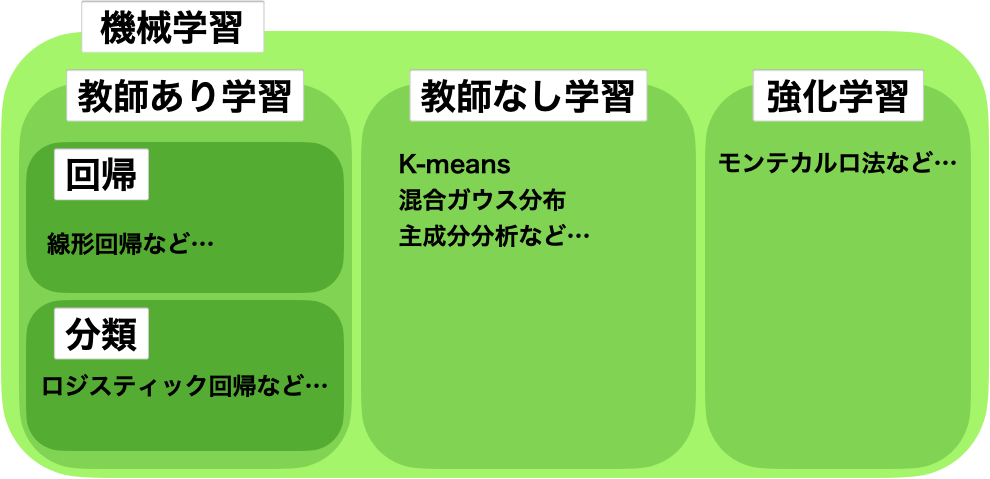
今回は、強化学習の実装は扱いません。
教師あり学習
教師あり学習は、特徴を表すデータ(特徴量、説明変数)と答えとなるデータ(ラベル、目的変数)から問題の答えを学習させる手法です。
教師あり学習は、以下の2つに分類されます。
- 回帰:連続した数値を予測
- 身長の予測など
- 分類:順番のないラベルを予測
- 性別の予測など
利用データ
実装で利用するデータについて、簡単に説明します。
ここでは、scikit-learnのサンプルデータを利用します。
利用するデータは、回帰と分類で以下の通りです。
アルゴリズム
教師あり学習のアルゴリズムについて、紹介していきます。
それぞれのアルゴリズムで、回帰と分類どちらに適用できるか記載しています。
線形回帰
- 回帰
特徴量が大きくなるほど、目的変数が大きく(小さく)なる関係をモデル化する手法。
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# データの読み込み
boston = load_boston()
X = boston['data']
y = boston['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
model = LinearRegression()
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
print('score is', score)
ロジスティック回帰
- 分類
ある事象が起こる確率を学習する手法。
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# データの読み込み
wine = load_wine()
X = wine['data']
y = wine['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
model = LogisticRegression()
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
print('score is', score)
ランダムフォレスト
- 回帰
- 分類
複数の決定木から多数決で予測する手法。
回帰版
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
# データの読み込み
boston = load_boston()
X = boston['data']
y = boston['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
model = RandomForestRegressor(random_state=0)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
print('score is', score)
分類版
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
# データの読み込み
wine = load_wine()
X = wine['data']
y = wine['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
model = RandomForestClassifier(random_state=0)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
print('score is', score)
サポートベクターマシン
マージンを最大化することでより良い決定境界を得る手法。
- 回帰
- 分類
回帰版
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
# データの読み込み
boston = load_boston()
X = boston['data']
y = boston['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
model = SVR(kernel='linear', gamma='auto')
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
print('score is', score)
分類版
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
# データの読み込み
wine = load_wine()
X = wine['data']
y = wine['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
model = SVC(gamma='auto')
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
print('score is', score)
kNN
学習データを全て覚えて、予測したいデータと距離の近いk個のデータから多数決をする手法。
- 回帰
- 分類
回帰版
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsRegressor
# データの読み込み
boston = load_boston()
X = boston['data']
y = boston['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
model = KNeighborsRegressor(n_neighbors=3)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
print('score is', score)
分類版
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
# データの読み込み
wine = load_wine()
X = wine['data']
y = wine['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
print('score is', score)
ニューラルネットワーク
入力層、隠れ層、出力層からなる構造をもつ人間の脳の神経回路を模倣した手法。
- 回帰
- 分類
回帰版
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from tensorflow.keras import models
from tensorflow.keras import layers
# データの読み込み
boston = load_boston()
X = boston['data']
y = boston['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(X_train.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
model.fit(X_train, y_train)
mse, mae = model.evaluate(X_test, y_test)
print('MSE is', mse)
print('MAE is', mae)
分類版
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from tensorflow.keras import models
from tensorflow.keras import layers
from tensorflow.keras import utils
# データの読み込み
boston = load_wine()
X = boston['data']
y = utils.to_categorical(boston['target'])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(X_train.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(3, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train)
crossentropy, acc = model.evaluate(X_test, y_test)
print('Categorical Crossentropy is', crossentropy)
print('Accuracy is', acc)
勾配ブースティング
複数のモデルを学習させるアンサンブル学習の1つ。
一部のデータを繰り返し抽出し、逐次的に複数の決定木モデルを学習させる手法。
- 回帰
- 分類
回帰版
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import lightgbm as lgb
import numpy as np
# データの読み込み
wine = load_boston()
X = wine['data']
y = wine['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test)
params = {
'objective': 'regression',
'metric': 'mse',
}
num_round = 100
model = lgb.train(
params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=num_round,
)
y_pred = model.predict(X_test)
score = mean_squared_error(y_test, y_pred)
print('score is', score)
分類版
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import lightgbm as lgb
import numpy as np
# データの読み込み
wine = load_wine()
X = wine['data']
y = wine['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test)
params = {
'objective': 'multiclass',
'num_class': 3,
}
num_round = 100
model = lgb.train(
params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=num_round,
)
pred = model.predict(X_test)
y_pred = []
for p in pred:
y_pred.append(np.argmax(p))
score = accuracy_score(y_test, y_pred)
print('score is', score)
教師なし学習
教師なし学習は、答えとなるデータがなく、特徴を表すデータのみから学習させる手法です。
利用データ
教師なし学習の利用では、教師あり学習で使用したワインの品質のデータです。
-
ワインの品質
- 特徴量は13個
- 分類するクラスは3
アルゴリズム
教師なし学習のアルゴリズムについて、紹介していきます。
K-means
クラスタリング手法の1つ。
k個のクラスにデータをまとめる手法。
from sklearn.datasets import load_wine
from sklearn.cluster import KMeans
# データの読み込み
wine = load_wine()
X = wine['data']
model = KMeans(n_clusters=3, random_state=0)
model.fit(X)
print("labels: \n", model.labels_)
print("cluster centers: \n", model.cluster_centers_)
print("predict result: \n", model.predict(X))
混合ガウス分布
クラスタリング手法の1つ。
データが複数のガウス分布から生成されたとみなし、どのガウス分布に属するかで分類する手法。
from sklearn.datasets import load_wine
from sklearn.mixture import GaussianMixture
# データの読み込み
wine = load_wine()
X = wine['data']
model = GaussianMixture(n_components=4)
model.fit(X)
print("means: \n", model.means_)
print("predict result: \n", model.predict(X))
主成分分析
次元削減手法の1つ。
多数の変数から、データの特徴を保ちながらより少ない変数(主成分)でデータを表現する手法。
from sklearn.datasets import load_wine
from sklearn.decomposition import PCA
# データの読み込み
wine = load_wine()
X = wine['data']
model = PCA(n_components=4)
model.fit(X)
print('Before Transform:', X.shape[1])
print('After Transform:', model.transform(X).shape[1])
まとめ
- 教師あり学習は回帰と分類に分けられる
- 教師なし学習はいくつか種類がある
- 試すぐらいであれば少しのコードで機械学習ができる
- パラメータはいくつかあるため必要に応じて公式ドキュメントを参照する
教師なし学習、強化学習についてはまだまだ勉強不足だったので、これから勉強していきます。